 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-Motion: Motion-Aware Calibration-Free Monocular SLAM for Long-Range Consistency
Feb 05, 2026Despite recent progress in calibration-free monocular SLAM via 3D vision foundation models, scale drift remains severe on long sequences. Motion-agnostic partitioning breaks contextual coherence and causes zero-motion drift, while conventional geometric alignment is computationally expensive. To address these issues, we propose VGGT-Motion, a calibration-free SLAM system for efficient and robust global consistency over kilometer-scale trajectories. Specifically, we first propose a motion-aware submap construction mechanism that uses optical flow to guide adaptive partitioning, prune static redundancy, and encapsulate turns for stable local geometry. We then design an anchor-driven direct Sim(3) registration strategy. By exploiting context-balanced anchors, it achieves search-free, pixel-wise dense alignment and efficient loop closure without costly feature matching. Finally, a lightweight submap-level pose graph optimization enforces global consistency with linear complexity, enabling scalable long-range operation. Experiments show that VGGT-Motion markedly improves trajectory accuracy and efficiency, achieving state-of-the-art performance in zero-shot, long-range calibration-free monocular SLAM.
DRMOT: A Dataset and Framework for RGBD Referring Multi-Object Tracking
Feb 04, 2026Referring Multi-Object Tracking (RMOT) aims to track specific targets based on language descriptions and is vital for interactive AI systems such as robotics and autonomous driving. However, existing RMOT models rely solely on 2D RGB data, making it challenging to accurately detect and associate targets characterized by complex spatial semantics (e.g., ``the person closest to the camera'') and to maintain reliable identities under severe occlusion, due to the absence of explicit 3D spatial information. In this work, we propose a novel task, RGBD Referring Multi-Object Tracking (DRMOT), which explicitly requires models to fuse RGB, Depth (D), and Language (L) modalities to achieve 3D-aware tracking. To advance research on the DRMOT task, we construct a tailored RGBD referring multi-object tracking dataset, named DRSet, designed to evaluate models' spatial-semantic grounding and tracking capabilities. Specifically, DRSet contains RGB images and depth maps from 187 scenes, along with 240 language descriptions, among which 56 descriptions incorporate depth-related information. Furthermore, we propose DRTrack, a MLLM-guided depth-referring tracking framework. DRTrack performs depth-aware target grounding from joint RGB-D-L inputs and enforces robust trajectory association by incorporating depth cues. Extensive experiments on the DRSet dataset demonstrate the effectiveness of our framework.
ReaMOT: A Benchmark and Framework for Reasoning-based Multi-Object Tracking
May 26, 2025Referring Multi-object tracking (RMOT) is an important research field in computer vision. Its task form is to guide the models to track the objects that conform to the language instruction. However, the RMOT task commonly requires clear language instructions, such methods often fail to work when complex language instructions with reasoning characteristics appear. In this work, we propose a new task, called Reasoning-based Multi-Object Tracking (ReaMOT). ReaMOT is a more challenging task that requires accurate reasoning about objects that match the language instruction with reasoning characteristic and tracking the objects' trajectories. To advance the ReaMOT task and evaluate the reasoning capabilities of tracking models, we construct ReaMOT Challenge, a reasoning-based multi-object tracking benchmark built upon 12 datasets. Specifically, it comprises 1,156 language instructions with reasoning characteristic, 423,359 image-language pairs, and 869 diverse scenes, which is divided into three levels of reasoning difficulty. In addition, we propose a set of evaluation metrics tailored for the ReaMOT task. Furthermore, we propose ReaTrack, a training-free framework for reasoning-based multi-object tracking based on large vision-language models (LVLM) and SAM2, as a baseline for the ReaMOT task. Extensive experiments on the ReaMOT Challenge benchmark demonstrate the effectiveness of our ReaTrack framework.
Perception-R1: Pioneering Perception Policy with Reinforcement Learning
Apr 10, 2025



Inspired by the success of DeepSeek-R1, we explore the potential of rule-based reinforcement learning (RL) in MLLM post-training for perception policy learning. While promising, our initial experiments reveal that incorporating a thinking process through RL does not consistently lead to performance gains across all visual perception tasks. This leads us to delve into the essential role of RL in the context of visual perception. In this work, we return to the fundamentals and explore the effects of RL on different perception tasks. We observe that the perceptual complexity is a major factor in determining the effectiveness of RL. We also observe that reward design plays a crucial role in further approching the upper limit of model perception. To leverage these findings, we propose Perception-R1, a scalable RL framework using GRPO during MLLM post-training. With a standard Qwen2.5-VL-3B-Instruct, Perception-R1 achieves +4.2% on RefCOCO+, +17.9% on PixMo-Count, +4.2% on PageOCR, and notably, 31.9% AP on COCO2017 val for the first time, establishing a strong baseline for perception policy learning.
OVTR: End-to-End Open-Vocabulary Multiple Object Tracking with Transformer
Mar 13, 2025



Open-vocabulary multiple object tracking aims to generalize trackers to unseen categories during training, enabling their application across a variety of real-world scenarios. However, the existing open-vocabulary tracker is constrained by its framework structure, isolated frame-level perception, and insufficient modal interactions, which hinder its performance in open-vocabulary classification and tracking. In this paper, we propose OVTR (End-to-End Open-Vocabulary Multiple Object Tracking with TRansformer), the first end-to-end open-vocabulary tracker that models motion, appearance, and category simultaneously. To achieve stable classification and continuous tracking, we design the CIP (Category Information Propagation) strategy, which establishes multiple high-level category information priors for subsequent frames. Additionally, we introduce a dual-branch structure for generalization capability and deep multimodal interaction, and incorporate protective strategies in the decoder to enhance performance. Experimental results show that our method surpasses previous trackers on the open-vocabulary MOT benchmark while also achieving faster inference speeds and significantly reducing preprocessing requirements. Moreover, the experiment transferring the model to another dataset demonstrates its strong adaptability. Models and code are released at https://github.com/jinyanglii/OVTR.
Unhackable Temporal Rewarding for Scalable Video MLLMs
Feb 17, 2025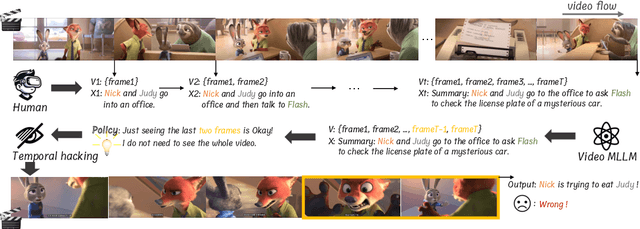
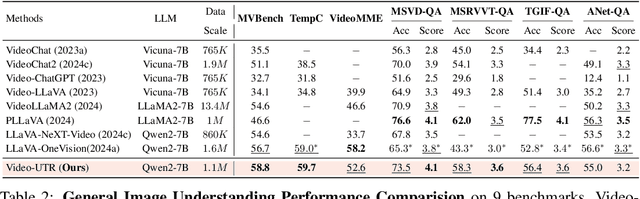
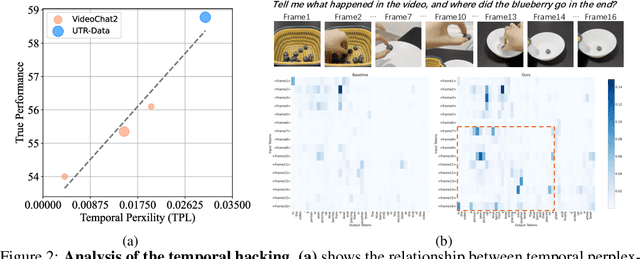

In the pursuit of superior video-processing MLLMs, we have encountered a perplexing paradox: the "anti-scaling law", where more data and larger models lead to worse performance. This study unmasks the culprit: "temporal hacking", a phenomenon where models shortcut by fixating on select frames, missing the full video narrative. In this work, we systematically establish a comprehensive theory of temporal hacking, defining it from a reinforcement learning perspective, introducing the Temporal Perplexity (TPL) score to assess this misalignment, and proposing the Unhackable Temporal Rewarding (UTR) framework to mitigate the temporal hacking. Both theoretically and empirically, TPL proves to be a reliable indicator of temporal modeling quality, correlating strongly with frame activation patterns. Extensive experiments reveal that UTR not only counters temporal hacking but significantly elevates video comprehension capabilities. This work not only advances video-AI systems but also illuminates the critical importance of aligning proxy rewards with true objectives in MLLM development.
Cross-View Referring Multi-Object Tracking
Dec 23, 2024Referring Multi-Object Tracking (RMOT) is an important topic in the current tracking field. Its task form is to guide the tracker to track objects that match the language description. Current research mainly focuses on referring multi-object tracking under single-view, which refers to a view sequence or multiple unrelated view sequences. However, in the single-view, some appearances of objects are easily invisible, resulting in incorrect matching of objects with the language description. In this work, we propose a new task, called Cross-view Referring Multi-Object Tracking (CRMOT). It introduces the cross-view to obtain the appearances of objects from multiple views, avoiding the problem of the invisible appearances of objects in RMOT task. CRMOT is a more challenging task of accurately tracking the objects that match the language description and maintaining the identity consistency of objects in each cross-view. To advance CRMOT task, we construct a cross-view referring multi-object tracking benchmark based on CAMPUS and DIVOTrack datasets, named CRTrack. Specifically, it provides 13 different scenes and 221 language descriptions. Furthermore, we propose an end-to-end cross-view referring multi-object tracking method, named CRTracker. Extensive experiments on the CRTrack benchmark verify the effectiveness of our method. The dataset and code are available at https://github.com/chen-si-jia/CRMOT.
Few-shot NeRF by Adaptive Rendering Loss Regularization
Oct 23, 2024



Novel view synthesis with sparse inputs poses great challenges to Neural Radiance Field (NeRF). Recent works demonstrate that the frequency regularization of Positional Encoding (PE) can achieve promising results for few-shot NeRF. In this work, we reveal that there exists an inconsistency between the frequency regularization of PE and rendering loss. This prevents few-shot NeRF from synthesizing higher-quality novel views. To mitigate this inconsistency, we propose Adaptive Rendering loss regularization for few-shot NeRF, dubbed AR-NeRF. Specifically, we present a two-phase rendering supervision and an adaptive rendering loss weight learning strategy to align the frequency relationship between PE and 2D-pixel supervision. In this way, AR-NeRF can learn global structures better in the early training phase and adaptively learn local details throughout the training process. Extensive experiments show that our AR-NeRF achieves state-of-the-art performance on different datasets, including object-level and complex scenes.
A Comprehensive Survey and Taxonomy on Point Cloud Registration Based on Deep Learning
Apr 22, 2024



Point cloud registration (PCR) involves determining a rigid transformation that aligns one point cloud to another. Despite the plethora of outstanding deep learning (DL)-based registration methods proposed, comprehensive and systematic studies on DL-based PCR techniques are still lacking. In this paper, we present a comprehensive survey and taxonomy of recently proposed PCR methods. Firstly, we conduct a taxonomy of commonly utilized datasets and evaluation metrics. Secondly, we classify the existing research into two main categories: supervised and unsupervised registration, providing insights into the core concepts of various influential PCR models. Finally, we highlight open challenges and potential directions for future research. A curated collection of valuable resources is made available at https://github.com/yxzhang15/PCR.
Delving into the Trajectory Long-tail Distribution for Muti-object Tracking
Mar 07, 2024



Multiple Object Tracking (MOT) is a critical area within computer vision, with a broad spectrum of practical implementations. Current research has primarily focused on the development of tracking algorithms and enhancement of post-processing techniques. Yet, there has been a lack of thorough examination concerning the nature of tracking data it self. In this study, we pioneer an exploration into the distribution patterns of tracking data and identify a pronounced long-tail distribution issue within existing MOT datasets. We note a significant imbalance in the distribution of trajectory lengths across different pedestrians, a phenomenon we refer to as "pedestrians trajectory long-tail distribution". Addressing this challenge, we introduce a bespoke strategy designed to mitigate the effects of this skewed distribution. Specifically, we propose two data augmentation strategies, including Stationary Camera View Data Augmentation (SVA) and Dynamic Camera View Data Augmentation (DVA) , designed for viewpoint states and the Group Softmax (GS) module for Re-ID. SVA is to backtrack and predict the pedestrian trajectory of tail classes, and DVA is to use diffusion model to change the background of the scene. GS divides the pedestrians into unrelated groups and performs softmax operation on each group individually. Our proposed strategies can be integrated into numerous existing tracking systems, and extensive experimentation validates the efficacy of our method in reducing the influence of long-tail distribution on multi-object tracking performance. The code is available at https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT.