 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflection Anchors for Propagation-Aware Visual Retention in Long-Chain Multimodal Reasoning
May 10, 2026Long chain-of-thought (CoT) reasoning improves large vision--language models, but visual information often fades during generation, limiting long-horizon multimodal reasoning. Existing methods either re-inject vision at inference or train policies for stronger grounding, but where to intervene relies on perception heuristics rather than principled gain analysis, and how local visual influence propagates remains implicit. We study this problem from an information-theoretic standpoint and derive a lower bound on the downstream visual gain of a one-step intervention, which suggests two factors: local branching room (token entropy) and downstream visual propagation potential (suffix divergence from a vision-marginalized reference). Guided by this analysis, we propose reflection-anchor policy optimization (RAPO), a GRPO-based policy optimization method that selects high-entropy reflection anchors and optimizes a chain-masked finite-window KL surrogate for downstream visual dependence. Experiments on reasoning-intensive and general-domain benchmarks show that RAPO delivers substantial gains over strong baselines across multiple LVLM backbones. Mechanism analyses further indicate that reflection anchors are enriched for visually sensitive decision points and that RAPO increases contrastive visual-dependence signals along generated trajectories.
TableVision: A Large-Scale Benchmark for Spatially Grounded Reasoning over Complex Hierarchical Tables
Apr 04, 2026Structured tables are essential for conveying high-density information in professional domains such as finance, healthcare, and scientific research. Despite the progress in Multimodal Large Language Models (MLLMs), reasoning performance remains limited for complex tables with hierarchical layouts. In this paper, we identify a critical Perception Bottleneck through quantitative analysis. We find that as task complexity scales, the number of involved discrete visual regions increases disproportionately. This processing density leads to an internal "Perceptual Overload," where MLLMs struggle to maintain accurate spatial attention during implicit generation. To address this bottleneck, we introduce TableVision, a large-scale, trajectory-aware benchmark designed for spatially grounded reasoning. TableVision stratifies tabular tasks into three cognitive levels (Perception, Reasoning, and Analysis) across 13 sub-categories. By utilizing a rendering-based deterministic grounding pipeline, the dataset explicitly couples multi-step logical deductions with pixel-perfect spatial ground truths, comprising 6,799 high-fidelity reasoning trajectories. Our empirical results, supported by diagnostic probing, demonstrate that explicit spatial constraints significantly recover the reasoning potential of MLLMs. Furthermore, our two-stage decoupled framework achieves a robust 12.3% overall accuracy improvement on the test set. TableVision provides a rigorous testbed and a fresh perspective on the synergy between perception and logic in document understanding.
A Survey on Federated Learning and its Applications for Accelerating Industrial Internet of Things
Apr 21, 2021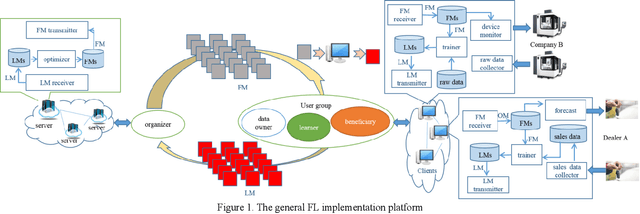
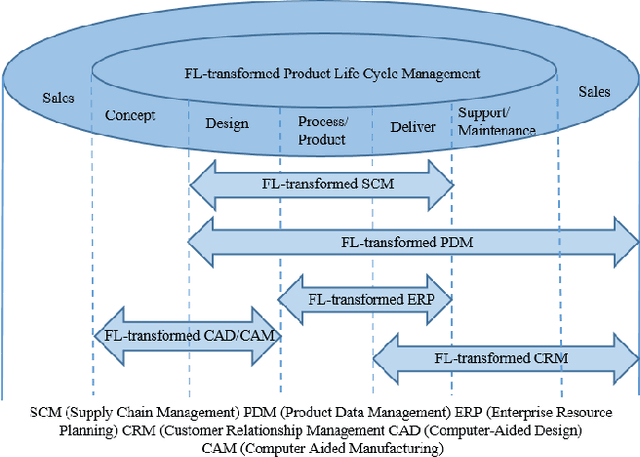

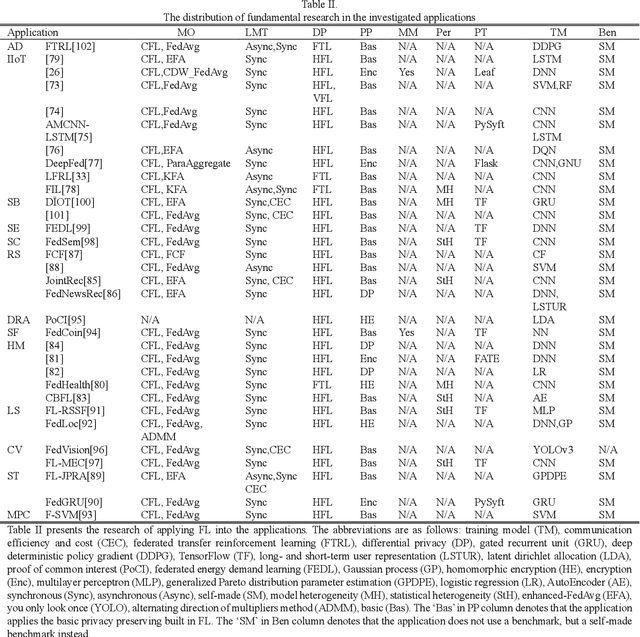
Federated learning (FL) brings collaborative intelligence into industries without centralized training data to accelerate the process of Industry 4.0 on the edge computing level. FL solves the dilemma in which enterprises wish to make the use of data intelligence with security concerns. To accelerate industrial Internet of things with the further leverage of FL, existing achievements on FL are developed from three aspects: 1) define terminologies and elaborate a general framework of FL for accommodating various scenarios; 2) discuss the state-of-the-art of FL on fundamental researches including data partitioning, privacy preservation, model optimization, local model transportation, personalization, motivation mechanism, platform & tools, and benchmark; 3) discuss the impacts of FL from the economic perspective. To attract more attention from industrial academia and practice, a FL-transformed manufacturing paradigm is presented, and future research directions of FL are given and possible immediate applications in Industry 4.0 domain are also proposed.