 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-Net: From Answer Extraction to Answer Generation for Machine Reading Comprehension
Jan 02, 2018
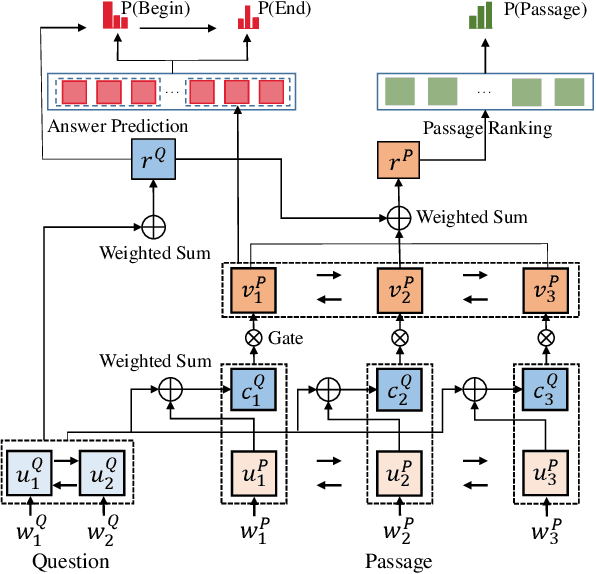
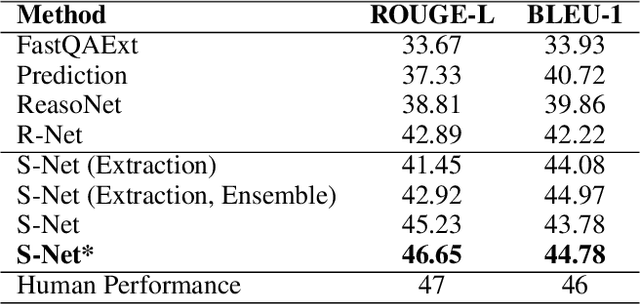
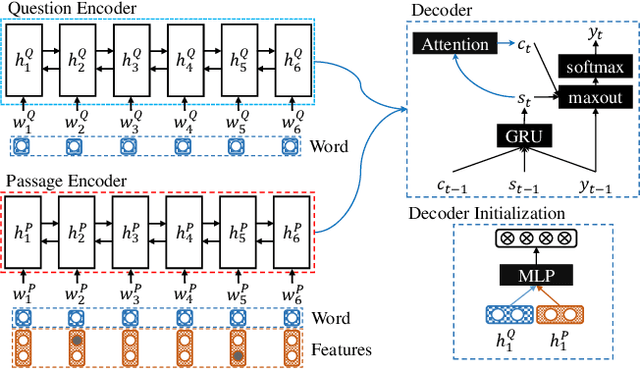
In this paper, we present a novel approach to machine reading comprehension for the MS-MARCO dataset. Unlike the SQuAD dataset that aims to answer a question with exact text spans in a passage, the MS-MARCO dataset defines the task as answering a question from multiple passages and the words in the answer are not necessary in the passages. We therefore develop an extraction-then-synthesis framework to synthesize answers from extraction results. Specifically, the answer extraction model is first employed to predict the most important sub-spans from the passage as evidence, and the answer synthesis model takes the evidence as additional features along with the question and passage to further elaborate the final answers. We build the answer extraction model with state-of-the-art neural networks for single passage reading comprehension, and propose an additional task of passage ranking to help answer extraction in multiple passages. The answer synthesis model is based on the sequence-to-sequence neural networks with extracted evidences as features. Experiments show that our extraction-then-synthesis method outperforms state-of-the-art methods.
Entity Linking for Queries by Searching Wikipedia Sentences
May 18, 2017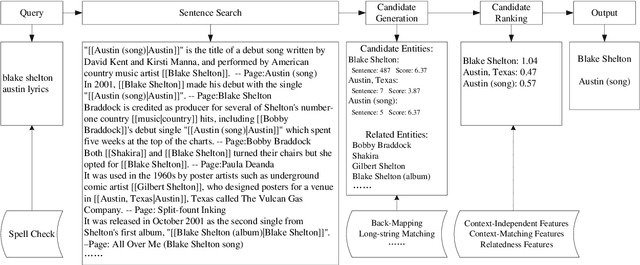
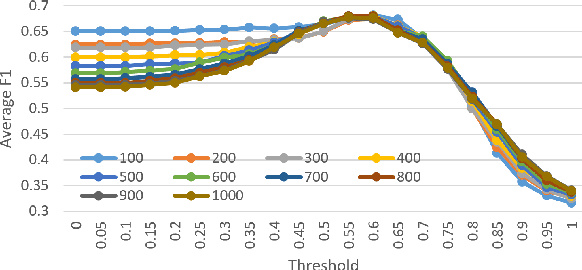

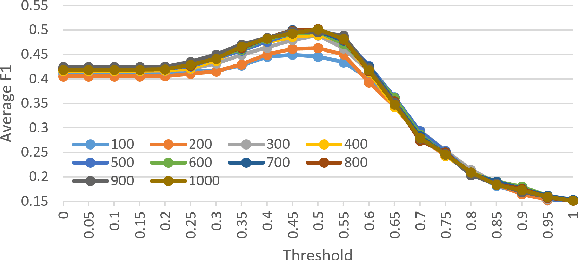
We present a simple yet effective approach for linking entities in queries. The key idea is to search sentences similar to a query from Wikipedia articles and directly use the human-annotated entities in the similar sentences as candidate entities for the query. Then, we employ a rich set of features, such as link-probability, context-matching, word embeddings, and relatedness among candidate entities as well as their related entities, to rank the candidates under a regression based framework. The advantages of our approach lie in two aspects, which contribute to the ranking process and final linking result. First, it can greatly reduce the number of candidate entities by filtering out irrelevant entities with the words in the query. Second, we can obtain the query sensitive prior probability in addition to the static link-probability derived from all Wikipedia articles. We conduct experiments on two benchmark datasets on entity linking for queries, namely the ERD14 dataset and the GERDAQ dataset. Experimental results show that our method outperforms state-of-the-art systems and yields 75.0% in F1 on the ERD14 dataset and 56.9% on the GERDAQ dataset.
Feature Selection Based on Term Frequency and T-Test for Text Categorization
May 03, 2013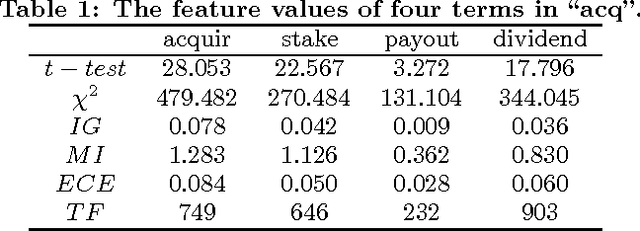
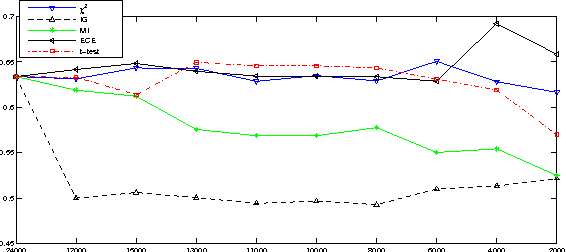
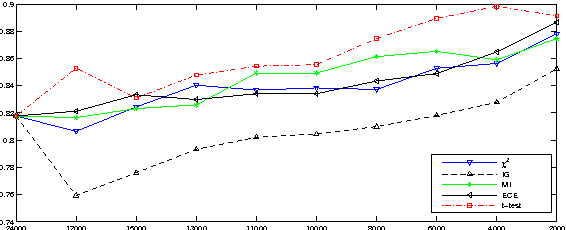
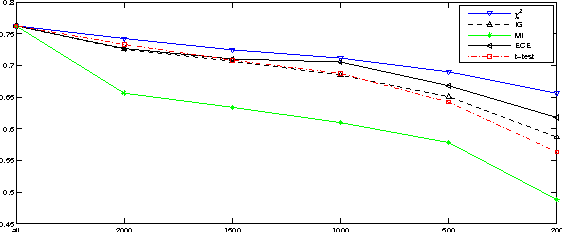
Much work has been done on feature selection. Existing methods are based on document frequency, such as Chi-Square Statistic, Information Gain etc. However, these methods have two shortcomings: one is that they are not reliable for low-frequency terms, and the other is that they only count whether one term occurs in a document and ignore the term frequency. Actually, high-frequency terms within a specific category are often regards as discriminators. This paper focuses on how to construct the feature selection function based on term frequency, and proposes a new approach based on $t$-test, which is used to measure the diversity of the distributions of a term between the specific category and the entire corpus. Extensive comparative experiments on two text corpora using three classifiers show that our new approach is comparable to or or slightly better than the state-of-the-art feature selection methods (i.e., $\chi^2$, and IG) in terms of macro-$F_1$ and micro-$F_1$.
Intelligent Search of Correlated Alarms for GSM Networks with Model-based Constraints
Apr 29, 2002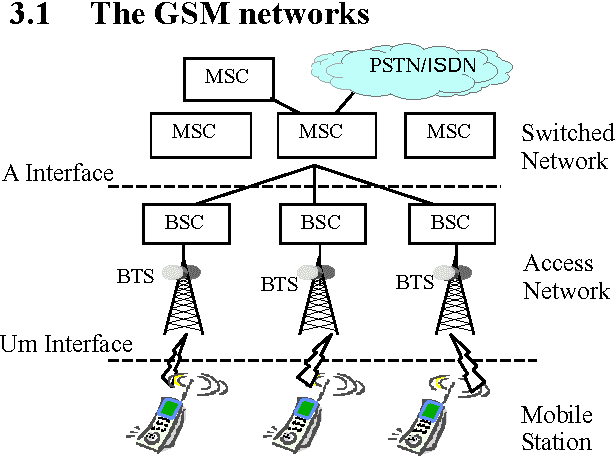

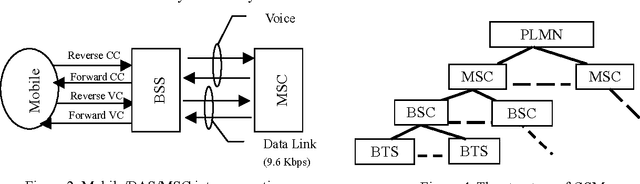
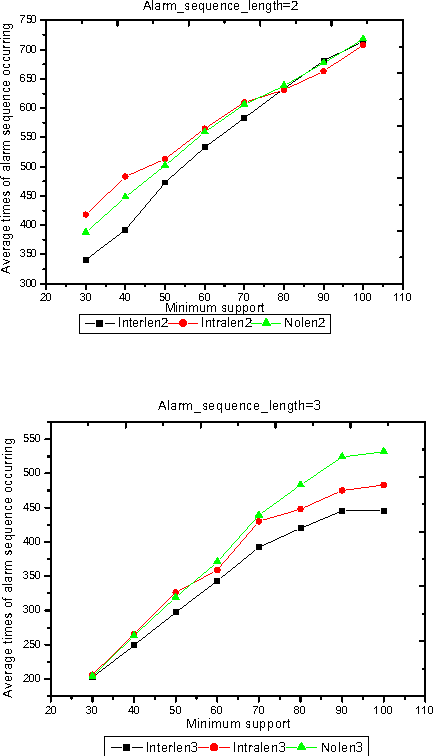
In order to control the process of data mining and focus on the things of interest to us, many kinds of constraints have been added into the algorithms of data mining. However, discovering the correlated alarms in the alarm database needs deep domain constraints. Because the correlated alarms greatly depend on the logical and physical architecture of networks. Thus we use the network model as the constraints of algorithms, including Scope constraint, Inter-correlated constraint and Intra-correlated constraint, in our proposed algorithm called SMC (Search with Model-based Constraints). The experiments show that the SMC algorithm with Inter-correlated or Intra-correlated constraint is about two times faster than the algorithm with no constraints.
* 8 pages, 7 figures
The Algorithms of Updating Sequential Patterns
Mar 27, 2002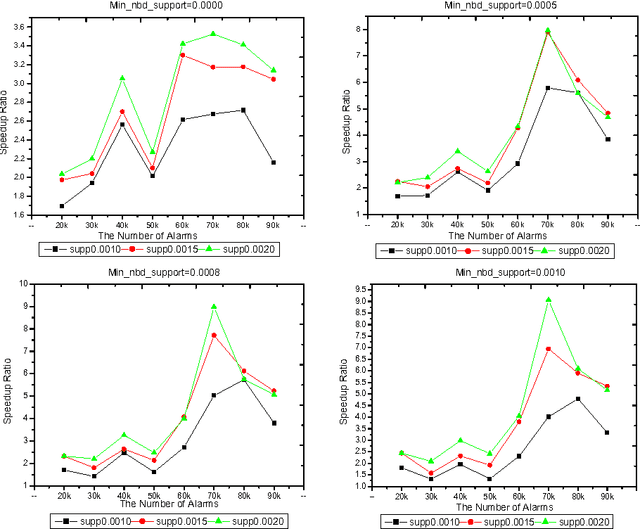
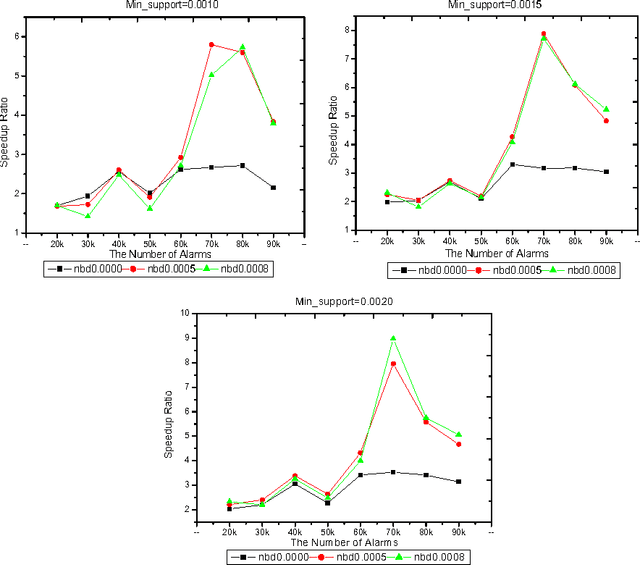
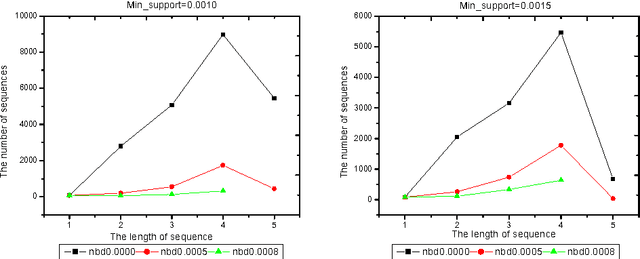
Because the data being mined in the temporal database will evolve with time, many researchers have focused on the incremental mining of frequent sequences in temporal database. In this paper, we propose an algorithm called IUS, using the frequent and negative border sequences in the original database for incremental sequence mining. To deal with the case where some data need to be updated from the original database, we present an algorithm called DUS to maintain sequential patterns in the updated database. We also define the negative border sequence threshold: Min_nbd_supp to control the number of sequences in the negative border.
* 12 pages, 4 figures
Intelligent Search of Correlated Alarms from Database containing Noise Data
Dec 26, 2001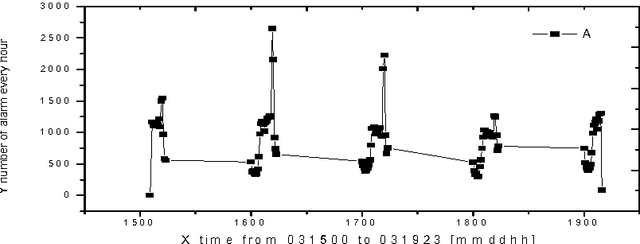
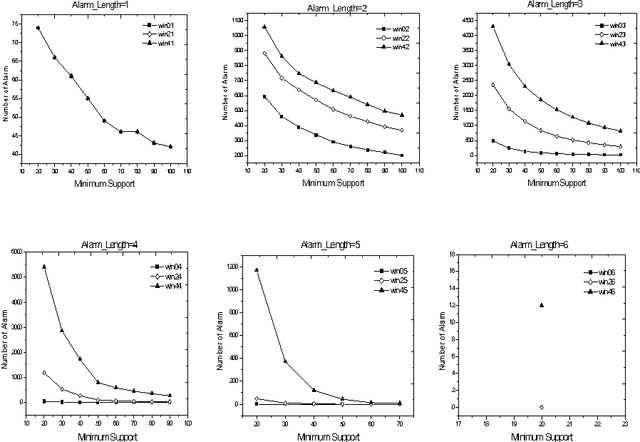
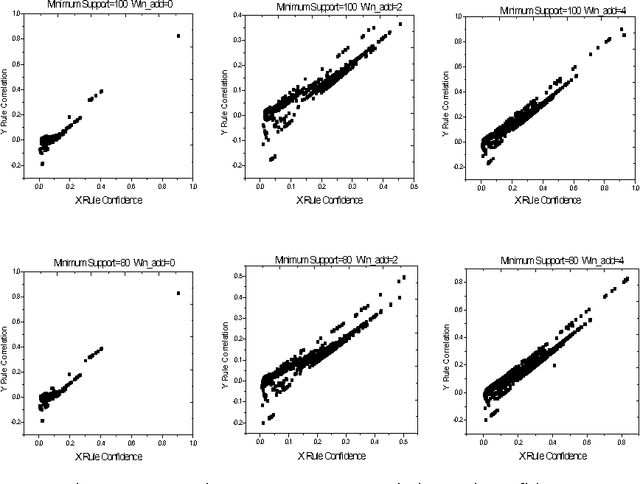
Alarm correlation plays an important role in improving the service and reliability in modern telecommunications networks. Most previous research of alarm correlation didn't consider the effect of noise data in Database. This paper focuses on the method of discovering alarm correlation rules from database containing noise data. We firstly define two parameters Win_freq and Win_add as the measure of noise data and then present the Robust_search algorithm to solve the problem. At different size of Win_freq and Win_add, experiments with alarm data containing noise data show that the Robust_search Algorithm can discover the more rules with the bigger size of Win_add. We also experimentally compare two different interestingness measures of confidence and correlation.