 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroSim V1.5: Improved Software Backbone for Benchmarking Compute-in-Memory Accelerators with Device and Circuit-level Non-idealities
May 05, 2025



The exponential growth of artificial intelligence (AI) applications has exposed the inefficiency of conventional von Neumann architectures, where frequent data transfers between compute units and memory create significant energy and latency bottlenecks. Analog Computing-in-Memory (ACIM) addresses this challenge by performing multiply-accumulate (MAC) operations directly in the memory arrays, substantially reducing data movement. However, designing robust ACIM accelerators requires accurate modeling of device- and circuit-level non-idealities. In this work, we present NeuroSim V1.5, introducing several key advances: (1) seamless integration with TensorRT's post-training quantization flow enabling support for more neural networks including transformers, (2) a flexible noise injection methodology built on pre-characterized statistical models, making it straightforward to incorporate data from SPICE simulations or silicon measurements, (3) expanded device support including emerging non-volatile capacitive memories, and (4) up to 6.5x faster runtime than NeuroSim V1.4 through optimized behavioral simulation. The combination of these capabilities uniquely enables systematic design space exploration across both accuracy and hardware efficiency metrics. Through multiple case studies, we demonstrate optimization of critical design parameters while maintaining network accuracy. By bridging high-fidelity noise modeling with efficient simulation, NeuroSim V1.5 advances the design and validation of next-generation ACIM accelerators. All NeuroSim versions are available open-source at https://github.com/neurosim/NeuroSim.
DNN+NeuroSim V2.0: An End-to-End Benchmarking Framework for Compute-in-Memory Accelerators for On-chip Training
Mar 13, 2020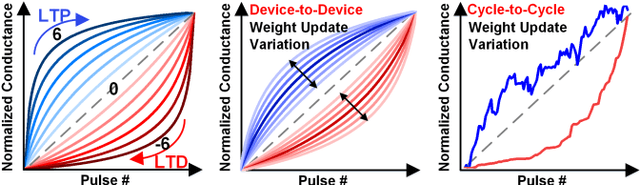
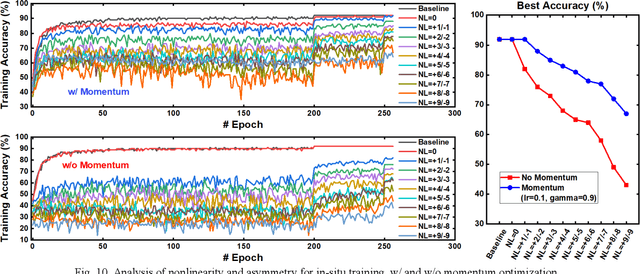
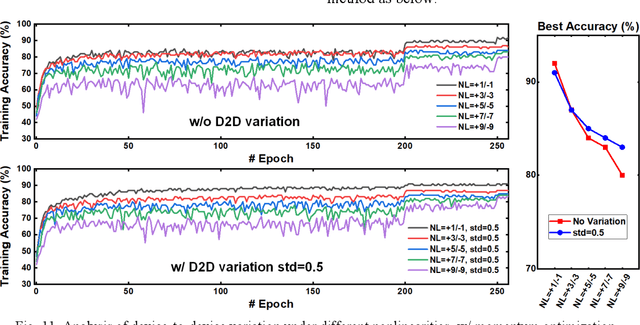
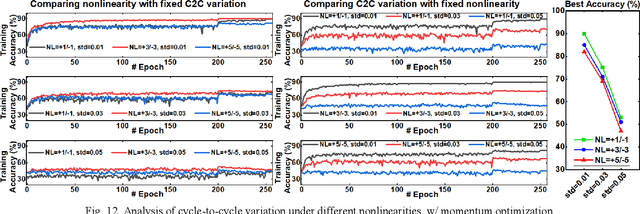
DNN+NeuroSim is an integrated framework to benchmark compute-in-memory (CIM) accelerators for deep neural networks, with hierarchical design options from device-level, to circuit-level and up to algorithm-level. A python wrapper is developed to interface NeuroSim with a popular machine learning platform: Pytorch, to support flexible network structures. The framework provides automatic algorithm-to-hardware mapping, and evaluates chip-level area, energy efficiency and throughput for training or inference, as well as training/inference accuracy with hardware constraints. Our prior work (DNN+NeuroSim V1.1) was developed to estimate the impact of reliability in synaptic devices, and analog-to-digital converter (ADC) quantization loss on the accuracy and hardware performance of inference engines. In this work, we further investigated the impact of the analog emerging non-volatile memory non-ideal device properties for on-chip training. By introducing the nonlinearity, asymmetry, device-to-device and cycle-to-cycle variation of weight update into the python wrapper, and peripheral circuits for error/weight gradient computation in NeuroSim core, we benchmarked CIM accelerators based on state-of-the-art SRAM and eNVM devices for VGG-8 on CIFAR-10 dataset, revealing the crucial specs of synaptic devices for on-chip training. The proposed DNN+NeuroSim V2.0 framework is available on GitHub.