 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPSeg: Auto-Prompt Network for Cross-Domain Few-Shot Semantic Segmentatio
Jun 12, 2024Few-shot semantic segmentation (FSS) endeavors to segment unseen classes with only a few labeled samples. Current FSS methods are commonly built on the assumption that their training and application scenarios share similar domains, and their performances degrade significantly while applied to a distinct domain. To this end, we propose to leverage the cutting-edge foundation model, the Segment Anything Model (SAM), for generalization enhancement. The SAM however performs unsatisfactorily on domains that are distinct from its training data, which primarily comprise natural scene images, and it does not support automatic segmentation of specific semantics due to its interactive prompting mechanism. In our work, we introduce APSeg, a novel auto-prompt network for cross-domain few-shot semantic segmentation (CD-FSS), which is designed to be auto-prompted for guiding cross-domain segmentation. Specifically, we propose a Dual Prototype Anchor Transformation (DPAT) module that fuses pseudo query prototypes extracted based on cycle-consistency with support prototypes, allowing features to be transformed into a more stable domain-agnostic space. Additionally, a Meta Prompt Generator (MPG) module is introduced to automatically generate prompt embeddings, eliminating the need for manual visual prompts. We build an efficient model which can be applied directly to target domains without fine-tuning. Extensive experiments on four cross-domain datasets show that our model outperforms the state-of-the-art CD-FSS method by 5.24% and 3.10% in average accuracy on 1-shot and 5-shot settings, respectively.
Question-Answer Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Jan 18, 2024Class Activation Map (CAM) has emerged as a popular tool for weakly supervised semantic segmentation (WSSS), allowing the localization of object regions in an image using only image-level labels. However, existing CAM methods suffer from under-activation of target object regions and false-activation of background regions due to the fact that a lack of detailed supervision can hinder the model's ability to understand the image as a whole. In this paper, we propose a novel Question-Answer Cross-Language-Image Matching framework for WSSS (QA-CLIMS), leveraging the vision-language foundation model to maximize the text-based understanding of images and guide the generation of activation maps. First, a series of carefully designed questions are posed to the VQA (Visual Question Answering) model with Question-Answer Prompt Engineering (QAPE) to generate a corpus of both foreground target objects and backgrounds that are adaptive to query images. We then employ contrastive learning in a Region Image Text Contrastive (RITC) network to compare the obtained foreground and background regions with the generated corpus. Our approach exploits the rich textual information from the open vocabulary as additional supervision, enabling the model to generate high-quality CAMs with a more complete object region and reduce false-activation of background regions. We conduct extensive analysis to validate the proposed method and show that our approach performs state-of-the-art on both PASCAL VOC 2012 and MS COCO datasets. Code is available at: https://github.com/CVI-SZU/QA-CLIMS
Activating the Discriminability of Novel Classes for Few-shot Segmentation
Dec 02, 2022Despite the remarkable success of existing methods for few-shot segmentation, there remain two crucial challenges. First, the feature learning for novel classes is suppressed during the training on base classes in that the novel classes are always treated as background. Thus, the semantics of novel classes are not well learned. Second, most of existing methods fail to consider the underlying semantic gap between the support and the query resulting from the representative bias by the scarce support samples. To circumvent these two challenges, we propose to activate the discriminability of novel classes explicitly in both the feature encoding stage and the prediction stage for segmentation. In the feature encoding stage, we design the Semantic-Preserving Feature Learning module (SPFL) to first exploit and then retain the latent semantics contained in the whole input image, especially those in the background that belong to novel classes. In the prediction stage for segmentation, we learn an Self-Refined Online Foreground-Background classifier (SROFB), which is able to refine itself using the high-confidence pixels of query image to facilitate its adaptation to the query image and bridge the support-query semantic gap. Extensive experiments on PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrates the advantages of these two novel designs both quantitatively and qualitatively.
Improving Micro-video Recommendation via Contrastive Multiple Interests
May 19, 2022

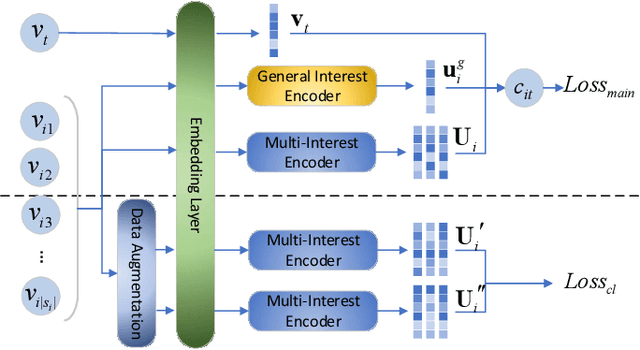
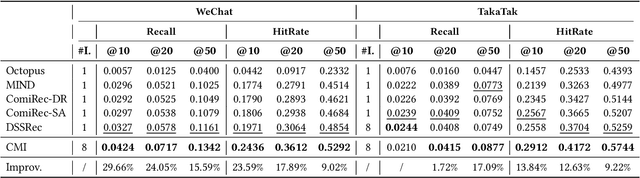
With the rapid increase of micro-video creators and viewers, how to make personalized recommendations from a large number of candidates to viewers begins to attract more and more attention. However, existing micro-video recommendation models rely on expensive multi-modal information and learn an overall interest embedding that cannot reflect the user's multiple interests in micro-videos. Recently, contrastive learning provides a new opportunity for refining the existing recommendation techniques. Therefore, in this paper, we propose to extract contrastive multi-interests and devise a micro-video recommendation model CMI. Specifically, CMI learns multiple interest embeddings for each user from his/her historical interaction sequence, in which the implicit orthogonal micro-video categories are used to decouple multiple user interests. Moreover, it establishes the contrastive multi-interest loss to improve the robustness of interest embeddings and the performance of recommendations. The results of experiments on two micro-video datasets demonstrate that CMI achieves state-of-the-art performance over existing baselines.
Fully Self-Supervised Learning for Semantic Segmentation
Feb 24, 2022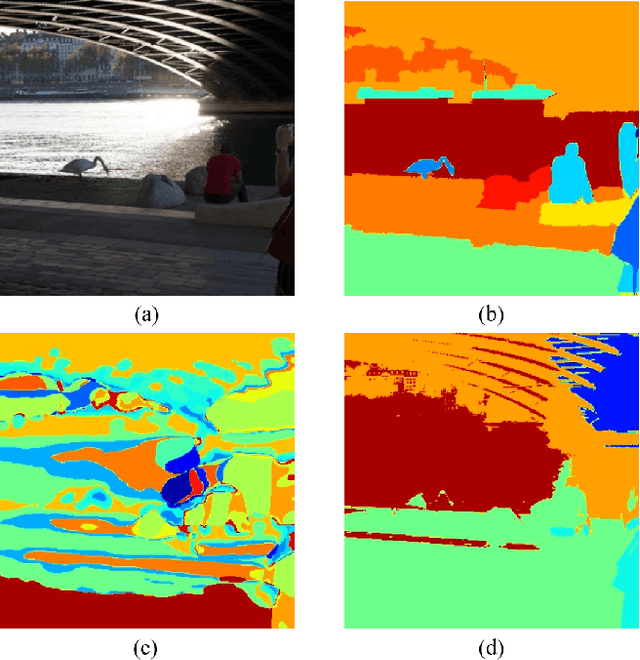
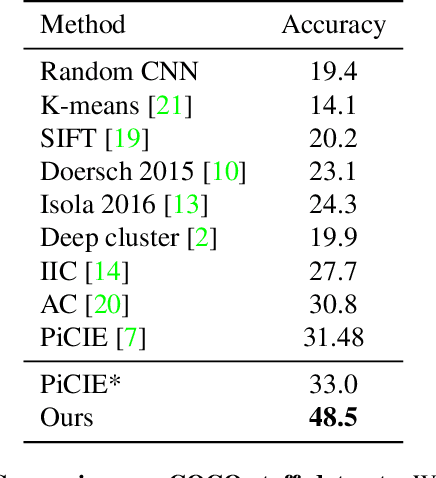
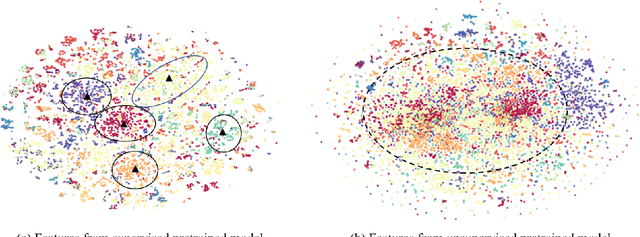
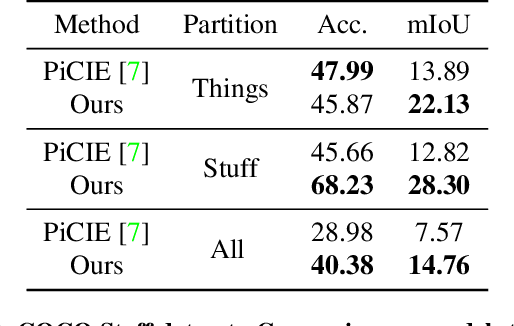
In this work, we present a fully self-supervised framework for semantic segmentation(FS^4). A fully bootstrapped strategy for semantic segmentation, which saves efforts for the huge amount of annotation, is crucial for building customized models from end-to-end for open-world domains. This application is eagerly needed in realistic scenarios. Even though recent self-supervised semantic segmentation methods have gained great progress, these works however heavily depend on the fully-supervised pretrained model and make it impossible a fully self-supervised pipeline. To solve this problem, we proposed a bootstrapped training scheme for semantic segmentation, which fully leveraged the global semantic knowledge for self-supervision with our proposed PGG strategy and CAE module. In particular, we perform pixel clustering and assignments for segmentation supervision. Preventing it from clustering a mess, we proposed 1) a pyramid-global-guided (PGG) training strategy to supervise the learning with pyramid image/patch-level pseudo labels, which are generated by grouping the unsupervised features. The stable global and pyramid semantic pseudo labels can prevent the segmentation from learning too many clutter regions or degrading to one background region; 2) in addition, we proposed context-aware embedding (CAE) module to generate global feature embedding in view of its neighbors close both in space and appearance in a non-trivial way. We evaluate our method on the large-scale COCO-Stuff dataset and achieved 7.19 mIoU improvements on both things and stuff objects
Graph Neural Networks with Feature and Structure Aware Random Walk
Nov 19, 2021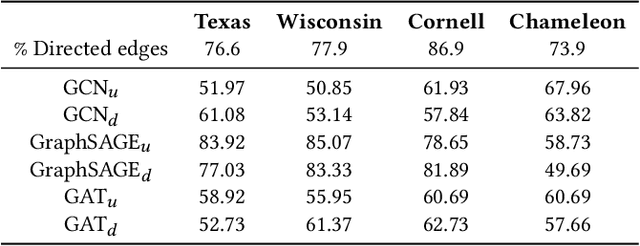
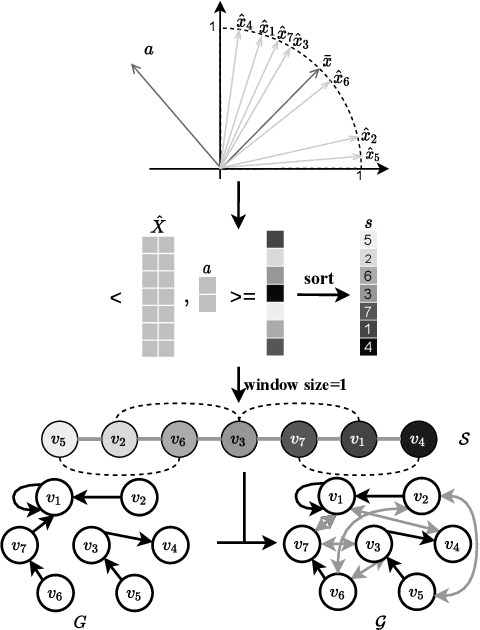
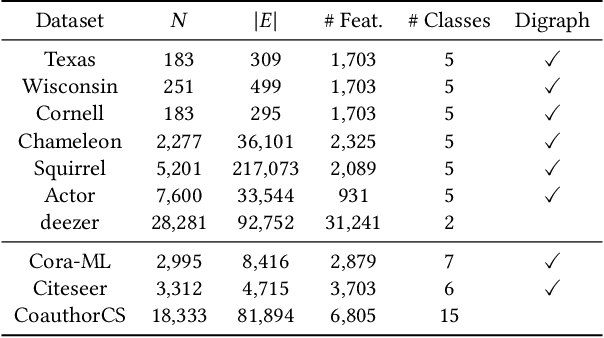
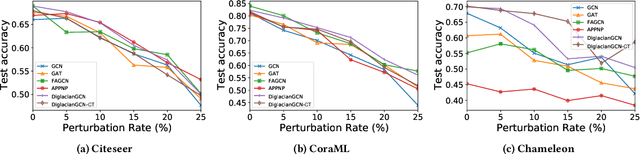
Graph Neural Networks (GNNs) have received increasing attention for representation learning in various machine learning tasks. However, most existing GNNs applying neighborhood aggregation usually perform poorly on the graph with heterophily where adjacent nodes belong to different classes. In this paper, we show that in typical heterphilous graphs, the edges may be directed, and whether to treat the edges as is or simply make them undirected greatly affects the performance of the GNN models. Furthermore, due to the limitation of heterophily, it is highly beneficial for the nodes to aggregate messages from similar nodes beyond local neighborhood.These motivate us to develop a model that adaptively learns the directionality of the graph, and exploits the underlying long-distance correlations between nodes. We first generalize the graph Laplacian to digraph based on the proposed Feature-Aware PageRank algorithm, which simultaneously considers the graph directionality and long-distance feature similarity between nodes. Then digraph Laplacian defines a graph propagation matrix that leads to a model called {\em DiglacianGCN}. Based on this, we further leverage the node proximity measured by commute times between nodes, in order to preserve the nodes' long-distance correlation on the topology level. Extensive experiments on ten datasets with different levels of homophily demonstrate the effectiveness of our method over existing solutions in the task of node classification.
Learning Inner-Group Relations on Point Clouds
Aug 27, 2021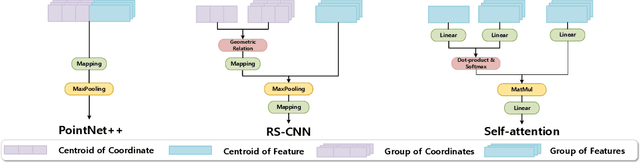
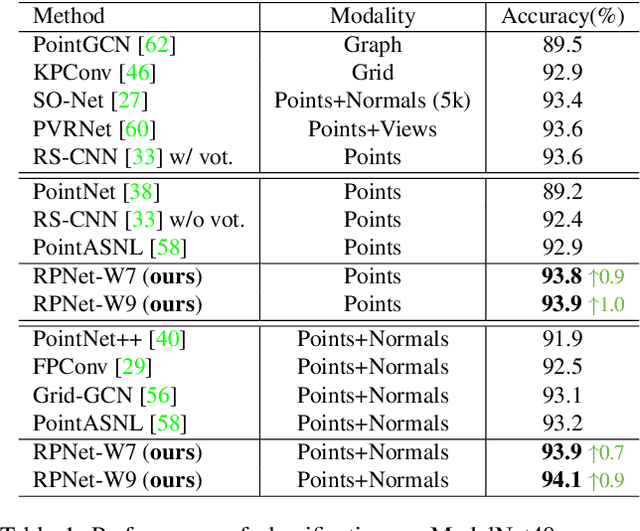
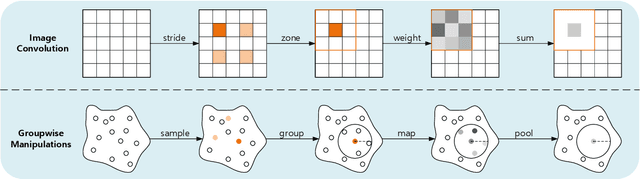
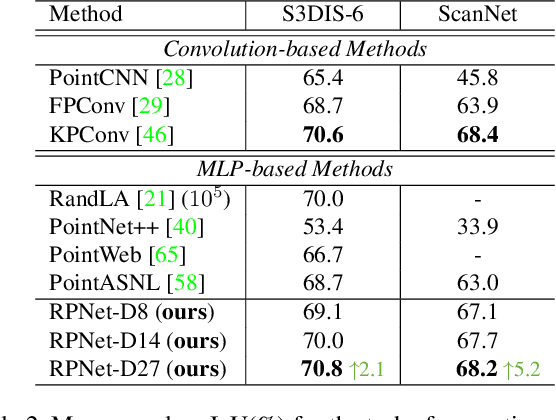
The prevalence of relation networks in computer vision is in stark contrast to underexplored point-based methods. In this paper, we explore the possibilities of local relation operators and survey their feasibility. We propose a scalable and efficient module, called group relation aggregator. The module computes a feature of a group based on the aggregation of the features of the inner-group points weighted by geometric relations and semantic relations. We adopt this module to design our RPNet. We further verify the expandability of RPNet, in terms of both depth and width, on the tasks of classification and segmentation. Surprisingly, empirical results show that wider RPNet fits for classification, while deeper RPNet works better on segmentation. RPNet achieves state-of-the-art for classification and segmentation on challenging benchmarks. We also compare our local aggregator with PointNet++, with around 30% parameters and 50% computation saving. Finally, we conduct experiments to reveal the robustness of RPNet with regard to rigid transformation and noises.
A Behavior-aware Graph Convolution Network Model for Video Recommendation
Jun 27, 2021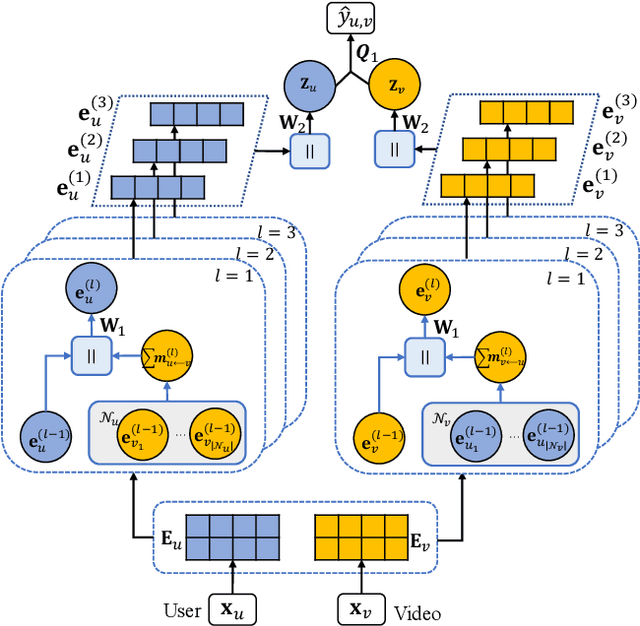
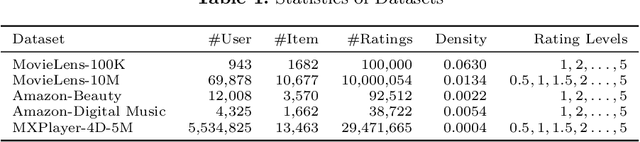
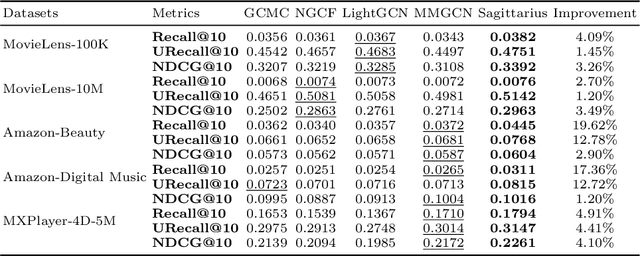
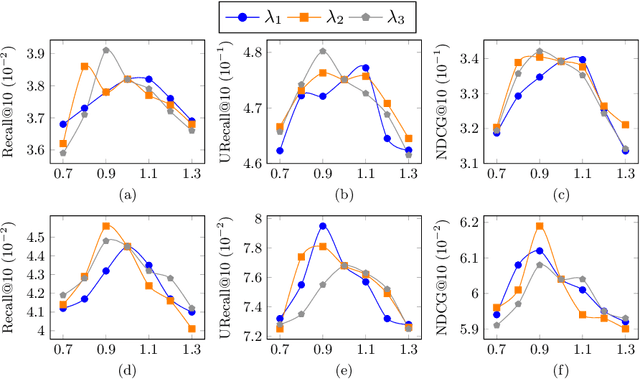
Interactions between users and videos are the major data source of performing video recommendation. Despite lots of existing recommendation methods, user behaviors on videos, which imply the complex relations between users and videos, are still far from being fully explored. In the paper, we present a model named Sagittarius. Sagittarius adopts a graph convolutional neural network to capture the influence between users and videos. In particular, Sagittarius differentiates between different user behaviors by weighting and fuses the semantics of user behaviors into the embeddings of users and videos. Moreover, Sagittarius combines multiple optimization objectives to learn user and video embeddings and then achieves the video recommendation by the learned user and video embeddings. The experimental results on multiple datasets show that Sagittarius outperforms several state-of-the-art models in terms of recall, unique recall and NDCG.
Bootstrap Representation Learning for Segmentation on Medical Volumes and Sequences
Jun 23, 2021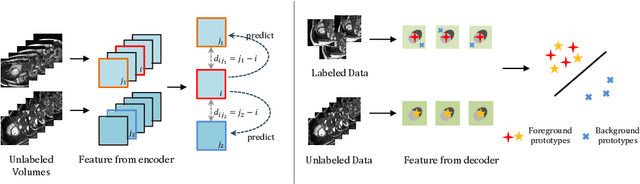
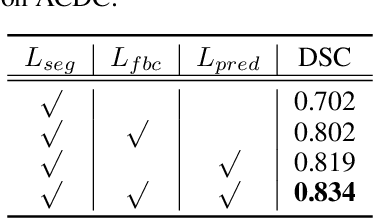
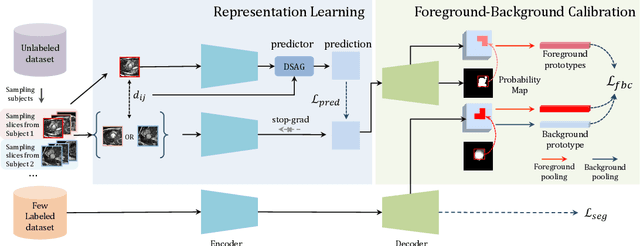
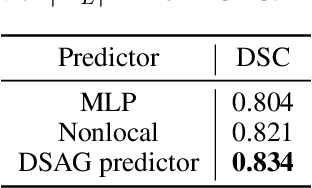
In this work, we propose a novel straightforward method for medical volume and sequence segmentation with limited annotations. To avert laborious annotating, the recent success of self-supervised learning(SSL) motivates the pre-training on unlabeled data. Despite its success, it is still challenging to adapt typical SSL methods to volume/sequence segmentation, due to their lack of mining on local semantic discrimination and rare exploitation on volume and sequence structures. Based on the continuity between slices/frames and the common spatial layout of organs across volumes/sequences, we introduced a novel bootstrap self-supervised representation learning method by leveraging the predictable possibility of neighboring slices. At the core of our method is a simple and straightforward dense self-supervision on the predictions of local representations and a strategy of predicting locals based on global context, which enables stable and reliable supervision for both global and local representation mining among volumes. Specifically, we first proposed an asymmetric network with an attention-guided predictor to enforce distance-specific prediction and supervision on slices within and across volumes/sequences. Secondly, we introduced a novel prototype-based foreground-background calibration module to enhance representation consistency. The two parts are trained jointly on labeled and unlabeled data. When evaluated on three benchmark datasets of medical volumes and sequences, our model outperforms existing methods with a large margin of 4.5\% DSC on ACDC, 1.7\% on Prostate, and 2.3\% on CAMUS. Intensive evaluations reveals the effectiveness and superiority of our method.
ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation
Jun 09, 2021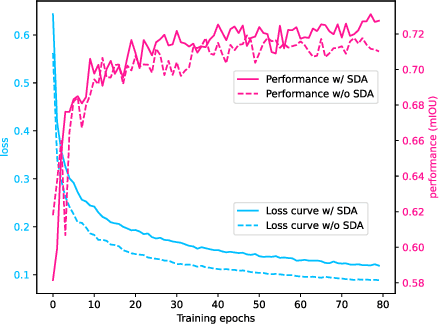
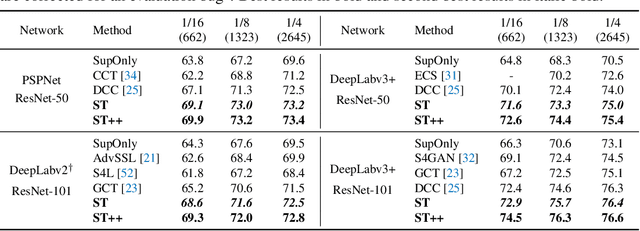
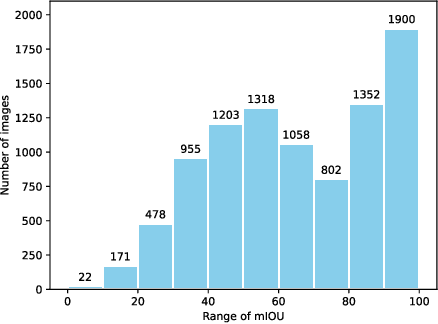
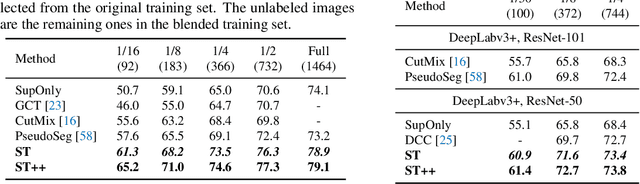
In this paper, we investigate if we could make the self-training -- a simple but popular framework -- work better for semi-supervised segmentation. Since the core issue in semi-supervised setting lies in effective and efficient utilization of unlabeled data, we notice that increasing the diversity and hardness of unlabeled data is crucial to performance improvement. Being aware of this fact, we propose to adopt the most plain self-training scheme coupled with appropriate strong data augmentations on unlabeled data (namely ST) for this task, which surprisingly outperforms previous methods under various settings without any bells and whistles. Moreover, to alleviate the negative impact of the wrongly pseudo labeled images, we further propose an advanced self-training framework (namely ST++), that performs selective re-training via selecting and prioritizing the more reliable unlabeled images. As a result, the proposed ST++ boosts the performance of semi-supervised model significantly and surpasses existing methods by a large margin on the Pascal VOC 2012 and Cityscapes benchmark. Overall, we hope this straightforward and simple framework will serve as a strong baseline or competitor for future works. Code is available at https://github.com/LiheYoung/ST-PlusPlus.