 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOON3.0: Reasoning-aware Multimodal Representation Learning for E-commerce Product Understanding
Apr 02, 2026With the rapid growth of e-commerce, exploring general representations rather than task-specific ones has attracted increasing attention. Although recent multimodal large language models (MLLMs) have driven significant progress in product understanding, they are typically employed as feature extractors that implicitly encode product information into global embeddings, thereby limiting their ability to capture fine-grained attributes. Therefore, we argue that leveraging the reasoning capabilities of MLLMs to explicitly model fine-grained product attributes holds significant potential. Nevertheless, achieving this goal remains non-trivial due to several key challenges: (i) long-context reasoning tends to dilute the model's attention to salient information in the raw input; (ii) supervised fine-tuning (SFT) primarily encourages rigid imitation, limiting the exploration of effective reasoning strategies; and (iii) fine-grained details are progressively attenuated during forward propagation. To address these issues, we propose MOON3.0, the first reasoning-aware MLLM-based model for product representation learning. Our method (1) employs a multi-head modality fusion module to adaptively integrate raw signals; (2) incorporates a joint contrastive and reinforcement learning framework to autonomously explore more effective reasoning strategies; and (3) introduces a fine-grained residual enhancement module to progressively preserve local details throughout the network. Additionally, we release a large-scale multimodal e-commerce benchmark MBE3.0. Experimentally, our model demonstrates state-of-the-art zero-shot performance across various downstream tasks on both our benchmark and public datasets.
MOON Embedding: Multimodal Representation Learning for E-commerce Search Advertising
Nov 18, 2025We introduce MOON, our comprehensive set of sustainable iterative practices for multimodal representation learning for e-commerce applications. MOON has already been fully deployed across all stages of Taobao search advertising system, including retrieval, relevance, ranking, and so on. The performance gains are particularly significant on click-through rate (CTR) prediction task, which achieves an overall +20.00% online CTR improvement. Over the past three years, this project has delivered the largest improvement on CTR prediction task and undergone five full-scale iterations. Throughout the exploration and iteration of our MOON, we have accumulated valuable insights and practical experience that we believe will benefit the research community. MOON contains a three-stage training paradigm of "Pretraining, Post-training, and Application", allowing effective integration of multimodal representations with downstream tasks. Notably, to bridge the misalignment between the objectives of multimodal representation learning and downstream training, we define the exchange rate to quantify how effectively improvements in an intermediate metric can translate into downstream gains. Through this analysis, we identify the image-based search recall as a critical intermediate metric guiding the optimization of multimodal models. Over three years and five iterations, MOON has evolved along four critical dimensions: data processing, training strategy, model architecture, and downstream application. The lessons and insights gained through the iterative improvements will also be shared. As part of our exploration into scaling effects in the e-commerce field, we further conduct a systematic study of the scaling laws governing multimodal representation learning, examining multiple factors such as the number of training tokens, negative samples, and the length of user behavior sequences.
MOON2.0: Dynamic Modality-balanced Multimodal Representation Learning for E-commerce Product Understanding
Nov 16, 2025The rapid growth of e-commerce calls for multimodal models that comprehend rich visual and textual product information. Although recent multimodal large language models (MLLMs) for product understanding exhibit strong capability in representation learning for e-commerce, they still face three challenges: (i) the modality imbalance induced by modality mixed training; (ii) underutilization of the intrinsic alignment relationships among visual and textual information within a product; and (iii) limited handling of noise in e-commerce multimodal data. To address these, we propose MOON2.0, a dynamic modality-balanced multimodal representation learning framework for e-commerce product understanding. MOON2.0 comprises: (1) a Modality-driven Mixture-of-Experts (MoE) module that adaptively processes input samples by their modality composition, enabling Multimodal Joint Learning to mitigate the modality imbalance; (2) a Dual-level Alignment method to better leverage semantic alignment properties inside individual products; and (3) an MLLM-based Image-text Co-augmentation strategy that integrates textual enrichment with visual expansion, coupled with Dynamic Sample Filtering to improve training data quality. We further introduce MBE2.0, a co-augmented multimodal representation benchmark for e-commerce representation learning and evaluation. Experiments show that MOON2.0 delivers state-of-the-art zero-shot performance on MBE2.0 and multiple public datasets. Furthermore, attention-based heatmap visualization provides qualitative evidence of improved multimodal alignment of MOON2.0.
Creative4U: MLLMs-based Advertising Creative Image Selector with Comparative Reasoning
Aug 18, 2025Creative image in advertising is the heart and soul of e-commerce platform. An eye-catching creative image can enhance the shopping experience for users, boosting income for advertisers and advertising revenue for platforms. With the advent of AIGC technology, advertisers can produce large quantities of creative images at minimal cost. However, they struggle to assess the creative quality to select. Existing methods primarily focus on creative ranking, which fails to address the need for explainable creative selection. In this work, we propose the first paradigm for explainable creative assessment and selection. Powered by multimodal large language models (MLLMs), our approach integrates the assessment and selection of creative images into a natural language generation task. To facilitate this research, we construct CreativePair, the first comparative reasoning-induced creative dataset featuring 8k annotated image pairs, with each sample including a label indicating which image is superior. Additionally, we introduce Creative4U (pronounced Creative for You), a MLLMs-based creative selector that takes into account users' interests. Through Reason-to-Select RFT, which includes supervised fine-tuning with Chain-of-Thought (CoT-SFT) and Group Relative Policy Optimization (GRPO) based reinforcement learning, Creative4U is able to evaluate and select creative images accurately. Both offline and online experiments demonstrate the effectiveness of our approach. Our code and dataset will be made public to advance research and industrial applications.
Visual Encoding and Debiasing for CTR Prediction
May 09, 2022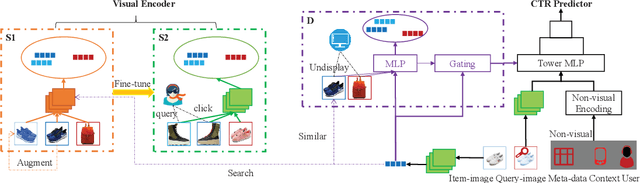
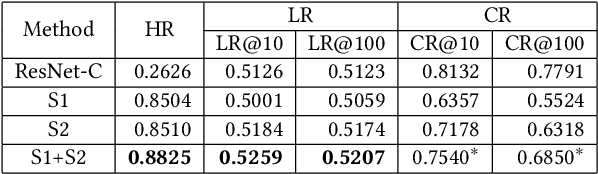

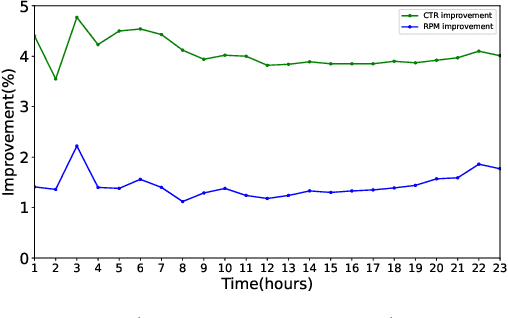
Extracting expressive visual features is crucial for accurate Click-Through-Rate (CTR) prediction in visual search advertising systems. Current commercial systems use off-the-shelf visual encoders to facilitate fast online service. However, the extracted visual features are coarse-grained and/or biased. In this paper, we present a visual encoding framework for CTR prediction to overcome these problems. The framework is based on contrastive learning which pulls positive pairs closer and pushes negative pairs apart in the visual feature space. To obtain fine-grained visual features,we present contrastive learning supervised by click through data to fine-tune the visual encoder. To reduce sample selection bias, firstly we train the visual encoder offline by leveraging both unbiased self-supervision and click supervision signals. Secondly, we incorporate a debiasing network in the online CTR predictor to adjust the visual features by contrasting high impression items with selected items with lower impressions.We deploy the framework in the visual sponsor search system at Alibaba. Offline experiments on billion-scale datasets and online experiments demonstrate that the proposed framework can make accurate and unbiased predictions.