 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOON Embedding: Multimodal Representation Learning for E-commerce Search Advertising
Nov 18, 2025We introduce MOON, our comprehensive set of sustainable iterative practices for multimodal representation learning for e-commerce applications. MOON has already been fully deployed across all stages of Taobao search advertising system, including retrieval, relevance, ranking, and so on. The performance gains are particularly significant on click-through rate (CTR) prediction task, which achieves an overall +20.00% online CTR improvement. Over the past three years, this project has delivered the largest improvement on CTR prediction task and undergone five full-scale iterations. Throughout the exploration and iteration of our MOON, we have accumulated valuable insights and practical experience that we believe will benefit the research community. MOON contains a three-stage training paradigm of "Pretraining, Post-training, and Application", allowing effective integration of multimodal representations with downstream tasks. Notably, to bridge the misalignment between the objectives of multimodal representation learning and downstream training, we define the exchange rate to quantify how effectively improvements in an intermediate metric can translate into downstream gains. Through this analysis, we identify the image-based search recall as a critical intermediate metric guiding the optimization of multimodal models. Over three years and five iterations, MOON has evolved along four critical dimensions: data processing, training strategy, model architecture, and downstream application. The lessons and insights gained through the iterative improvements will also be shared. As part of our exploration into scaling effects in the e-commerce field, we further conduct a systematic study of the scaling laws governing multimodal representation learning, examining multiple factors such as the number of training tokens, negative samples, and the length of user behavior sequences.
Creative4U: MLLMs-based Advertising Creative Image Selector with Comparative Reasoning
Aug 18, 2025Creative image in advertising is the heart and soul of e-commerce platform. An eye-catching creative image can enhance the shopping experience for users, boosting income for advertisers and advertising revenue for platforms. With the advent of AIGC technology, advertisers can produce large quantities of creative images at minimal cost. However, they struggle to assess the creative quality to select. Existing methods primarily focus on creative ranking, which fails to address the need for explainable creative selection. In this work, we propose the first paradigm for explainable creative assessment and selection. Powered by multimodal large language models (MLLMs), our approach integrates the assessment and selection of creative images into a natural language generation task. To facilitate this research, we construct CreativePair, the first comparative reasoning-induced creative dataset featuring 8k annotated image pairs, with each sample including a label indicating which image is superior. Additionally, we introduce Creative4U (pronounced Creative for You), a MLLMs-based creative selector that takes into account users' interests. Through Reason-to-Select RFT, which includes supervised fine-tuning with Chain-of-Thought (CoT-SFT) and Group Relative Policy Optimization (GRPO) based reinforcement learning, Creative4U is able to evaluate and select creative images accurately. Both offline and online experiments demonstrate the effectiveness of our approach. Our code and dataset will be made public to advance research and industrial applications.
Homography Decomposition Networks for Planar Object Tracking
Dec 27, 2021
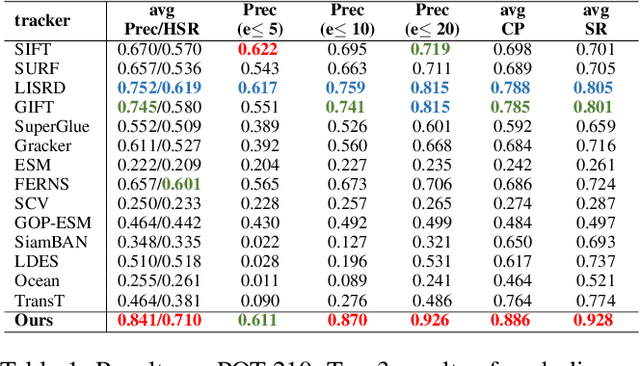
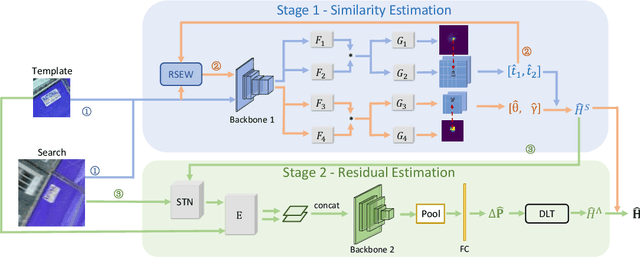
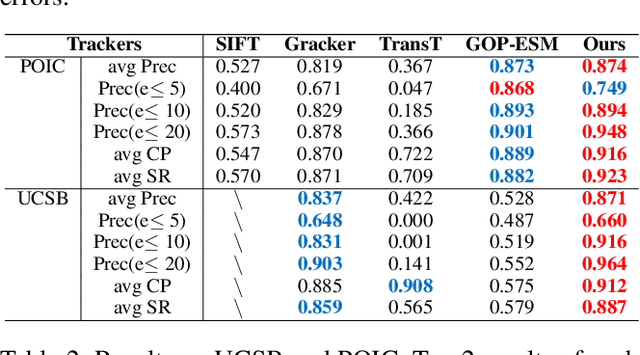
Planar object tracking plays an important role in AI applications, such as robotics, visual servoing, and visual SLAM. Although the previous planar trackers work well in most scenarios, it is still a challenging task due to the rapid motion and large transformation between two consecutive frames. The essential reason behind this problem is that the condition number of such a non-linear system changes unstably when the searching range of the homography parameter space becomes larger. To this end, we propose a novel Homography Decomposition Networks(HDN) approach that drastically reduces and stabilizes the condition number by decomposing the homography transformation into two groups. Specifically, a similarity transformation estimator is designed to predict the first group robustly by a deep convolution equivariant network. By taking advantage of the scale and rotation estimation with high confidence, a residual transformation is estimated by a simple regression model. Furthermore, the proposed end-to-end network is trained in a semi-supervised fashion. Extensive experiments show that our proposed approach outperforms the state-of-the-art planar tracking methods at a large margin on the challenging POT, UCSB and POIC datasets.