 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrear: Transformer-based RGB-D Egocentric Action Recognition
Jan 05, 2021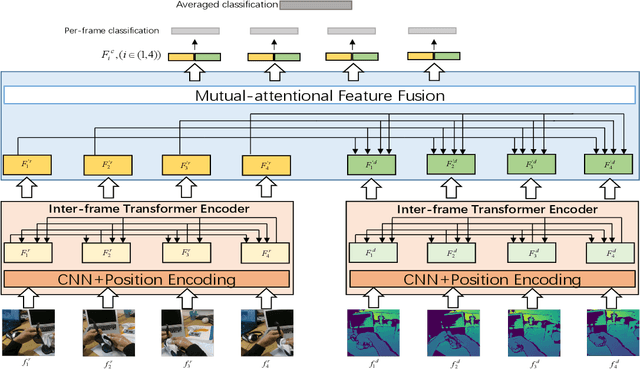
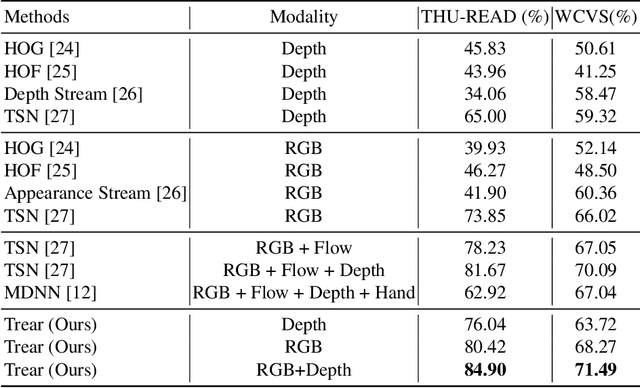
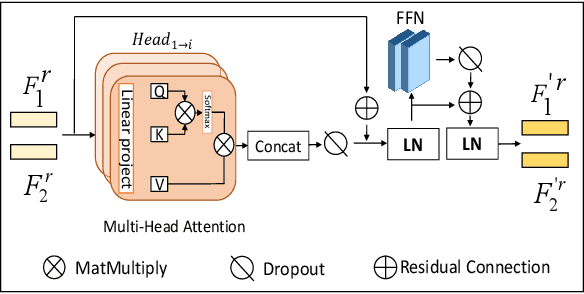
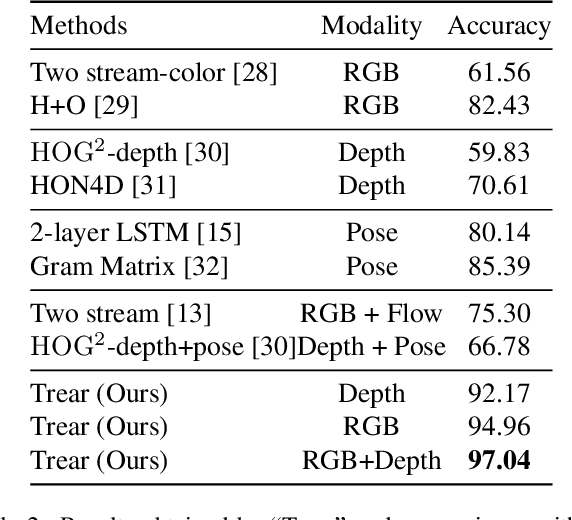
In this paper, we propose a \textbf{Tr}ansformer-based RGB-D \textbf{e}gocentric \textbf{a}ction \textbf{r}ecognition framework, called Trear. It consists of two modules, inter-frame attention encoder and mutual-attentional fusion block. Instead of using optical flow or recurrent units, we adopt self-attention mechanism to model the temporal structure of the data from different modalities. Input frames are cropped randomly to mitigate the effect of the data redundancy. Features from each modality are interacted through the proposed fusion block and combined through a simple yet effective fusion operation to produce a joint RGB-D representation. Empirical experiments on two large egocentric RGB-D datasets, THU-READ and FPHA, and one small dataset, WCVS, have shown that the proposed method outperforms the state-of-the-art results by a large margin.
Transformer Guided Geometry Model for Flow-Based Unsupervised Visual Odometry
Dec 08, 2020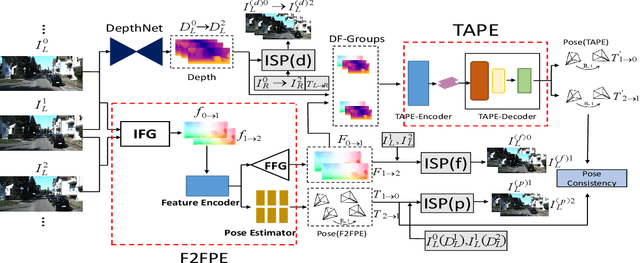
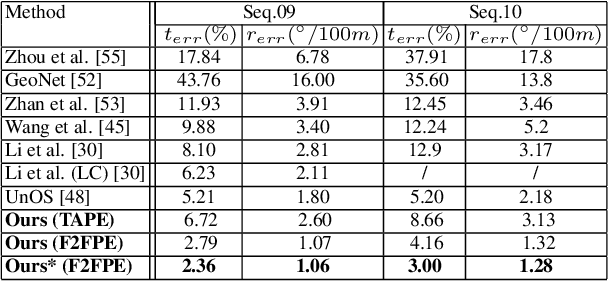
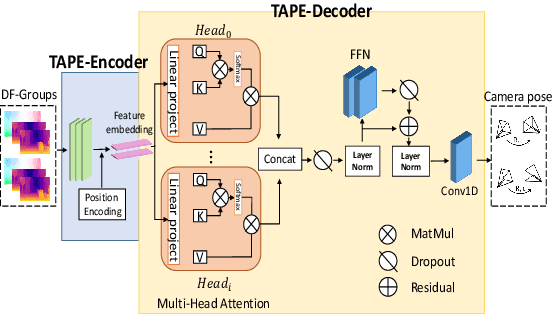
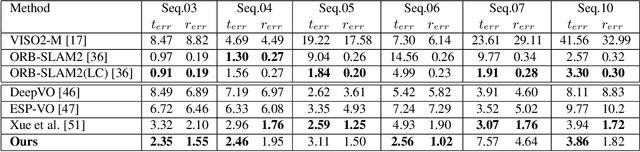
Existing unsupervised visual odometry (VO) methods either match pairwise images or integrate the temporal information using recurrent neural networks over a long sequence of images. They are either not accurate, time-consuming in training or error accumulative. In this paper, we propose a method consisting of two camera pose estimators that deal with the information from pairwise images and a short sequence of images respectively. For image sequences, a Transformer-like structure is adopted to build a geometry model over a local temporal window, referred to as Transformer-based Auxiliary Pose Estimator (TAPE). Meanwhile, a Flow-to-Flow Pose Estimator (F2FPE) is proposed to exploit the relationship between pairwise images. The two estimators are constrained through a simple yet effective consistency loss in training. Empirical evaluation has shown that the proposed method outperforms the state-of-the-art unsupervised learning-based methods by a large margin and performs comparably to supervised and traditional ones on the KITTI and Malaga dataset.
A Framework of Combining Short-Term Spatial/Frequency Feature Extraction and Long-Term IndRNN for Activity Recognition
Nov 06, 2020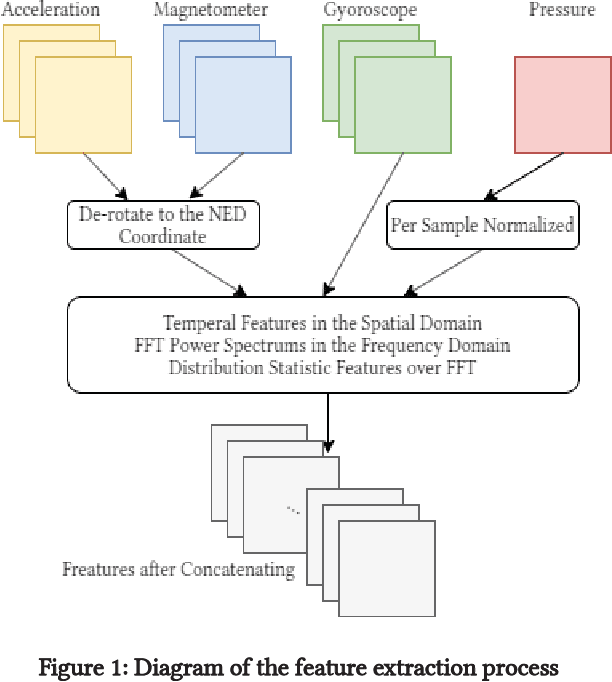
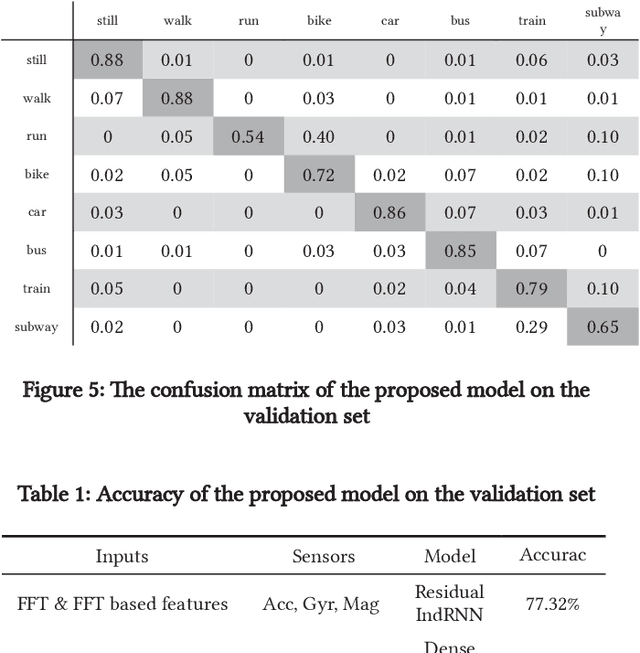
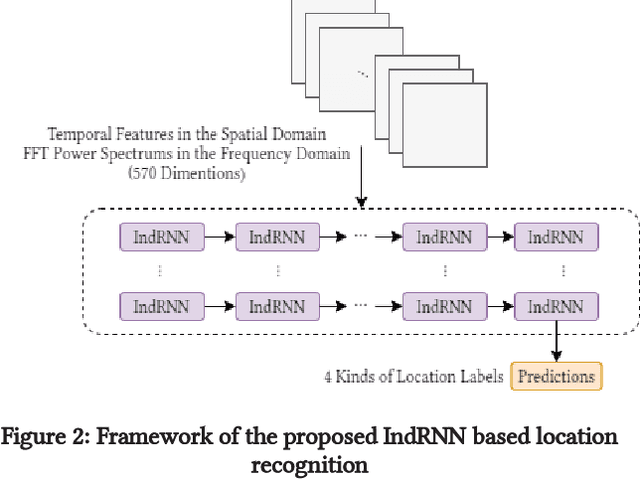

Smartphone sensors based human activity recognition is attracting increasing interests nowadays with the popularization of smartphones. With the high sampling rates of smartphone sensors, it is a highly long-range temporal recognition problem, especially with the large intra-class distances such as the smartphones carried at different locations such as in the bag or on the body, and the small inter-class distances such as taking train or subway. To address this problem, we propose a new framework of combining short-term spatial/frequency feature extraction and a long-term Independently Recurrent Neural Network (IndRNN) for activity recognition. Considering the periodic characteristics of the sensor data, short-term temporal features are first extracted in the spatial and frequency domains. Then the IndRNN, which is able to capture long-term patterns, is used to further obtain the long-term features for classification. In view of the large differences when the smartphone is carried at different locations, a group based location recognition is first developed to pinpoint the location of the smartphone. The Sussex-Huawei Locomotion (SHL) dataset from the SHL Challenge is used for evaluation. An earlier version of the proposed method has won the second place award in the SHL Challenge 2020 (the first place if not considering multiple models fusion approach). The proposed method is further improved in this paper and achieves 80.72$\%$ accuracy, better than the existing methods using a single model.
SAR-NAS: Skeleton-based Action Recognition via Neural Architecture Searching
Oct 29, 2020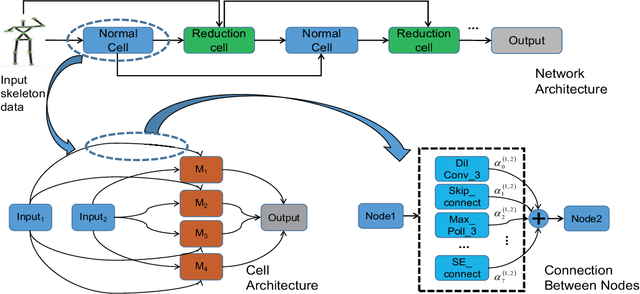
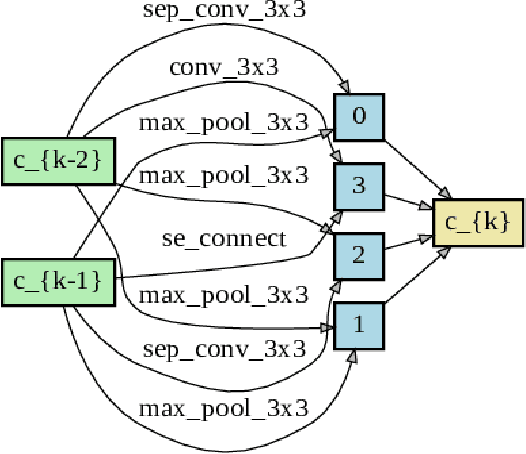
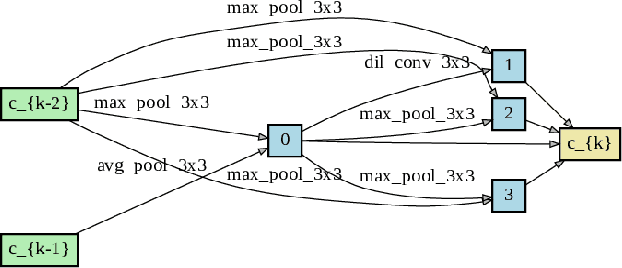

This paper presents a study of automatic design of neural network architectures for skeleton-based action recognition. Specifically, we encode a skeleton-based action instance into a tensor and carefully define a set of operations to build two types of network cells: normal cells and reduction cells. The recently developed DARTS (Differentiable Architecture Search) is adopted to search for an effective network architecture that is built upon the two types of cells. All operations are 2D based in order to reduce the overall computation and search space. Experiments on the challenging NTU RGB+D and Kinectics datasets have verified that most of the networks developed to date for skeleton-based action recognition are likely not compact and efficient. The proposed method provides an approach to search for such a compact network that is able to achieve comparative or even better performance than the state-of-the-art methods.
Unsupervised Domain Expansion from Multiple Sources
May 26, 2020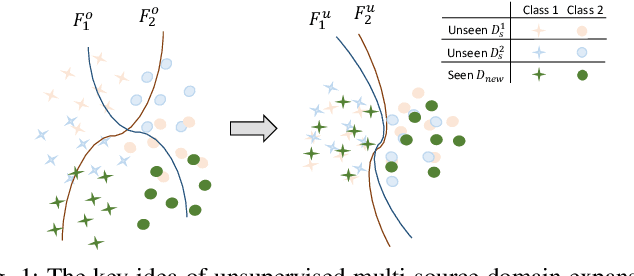
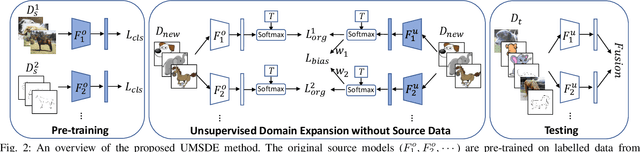
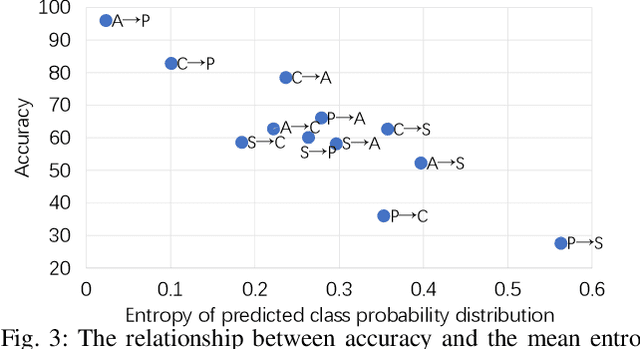
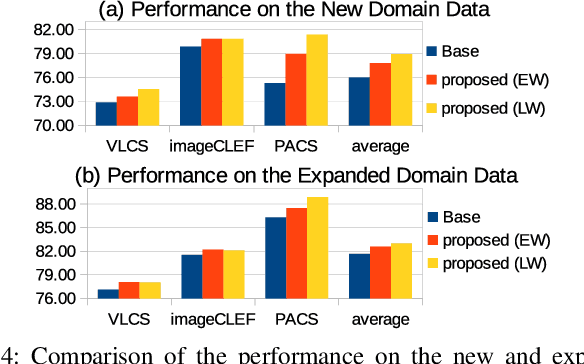
Given an existing system learned from previous source domains, it is desirable to adapt the system to new domains without accessing and forgetting all the previous domains in some applications. This problem is known as domain expansion. Unlike traditional domain adaptation in which the target domain is the domain defined by new data, in domain expansion the target domain is formed jointly by the source domains and the new domain (hence, domain expansion) and the label function to be learned must work for the expanded domain. Specifically, this paper presents a method for unsupervised multi-source domain expansion (UMSDE) where only the pre-learned models of the source domains and unlabelled new domain data are available. We propose to use the predicted class probability of the unlabelled data in the new domain produced by different source models to jointly mitigate the biases among domains, exploit the discriminative information in the new domain, and preserve the performance in the source domains. Experimental results on the VLCS, ImageCLEF_DA and PACS datasets have verified the effectiveness of the proposed method.
Deep Independently Recurrent Neural Network (IndRNN)
Oct 21, 2019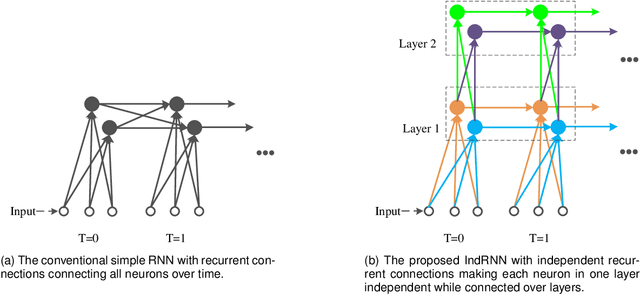

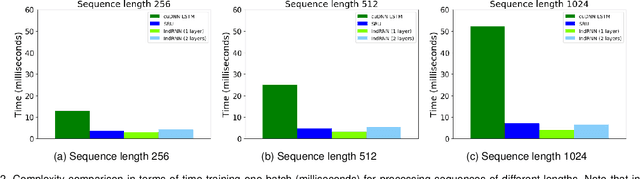
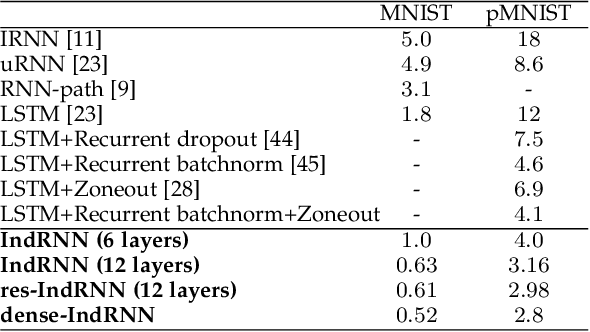
Recurrent neural networks (RNNs) are known to be difficult to train due to the gradient vanishing and exploding problems and thus difficult to learn long-term patterns. Long short-term memory (LSTM) was developed to address these problems, but the use of hyperbolic tangent and the sigmoid activation functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep RNN is challenging. Moreover, training of LSTM is very compute-intensive as the recurrent connection using matrix product is conducted at every time step. To address these problems, this paper proposes a new type of RNNs with the recurrent connection formulated as Hadamard product, referred to as independently recurrent neural network (IndRNN), where neurons in the same layer are independent of each other and connected across layers. The gradient vanishing and exploding problems are solved in IndRNN by simply regulating the recurrent weights, and thus long-term dependencies can be learned. Moreover, an IndRNN can work with non-saturated activation functions such as ReLU and be still trained robustly. Different deeper IndRNN architectures, including the basic stacked IndRNN, residual IndRNN and densely connected IndRNN, have been investigated, all of which can be much deeper than the existing RNNs. Furthermore, IndRNN reduces the computation at each time step and can be over 10 times faster than the LSTM. The code is made publicly available at https://github.com/Sunnydreamrain/IndRNN_pytorch. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (the 21 layers residual IndRNN and deep densely connected IndRNN used in the experiment for example). Better performances have been achieved on various tasks with IndRNNs compared with the traditional RNN and LSTM.
Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
May 22, 2018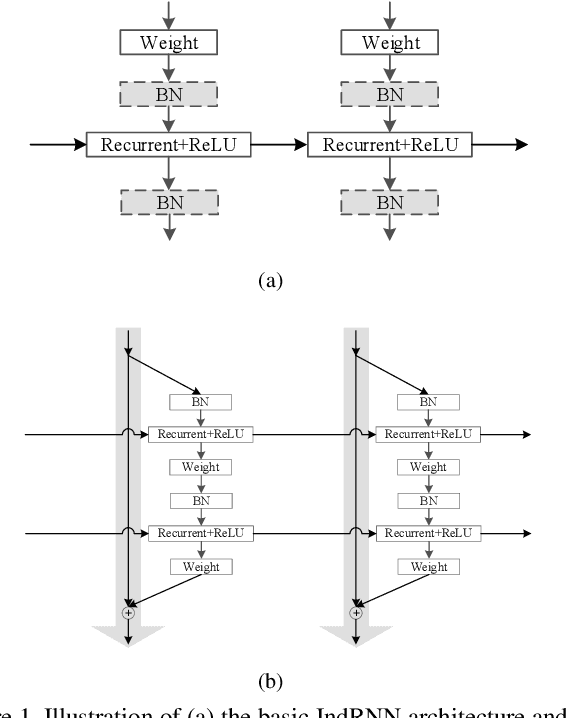
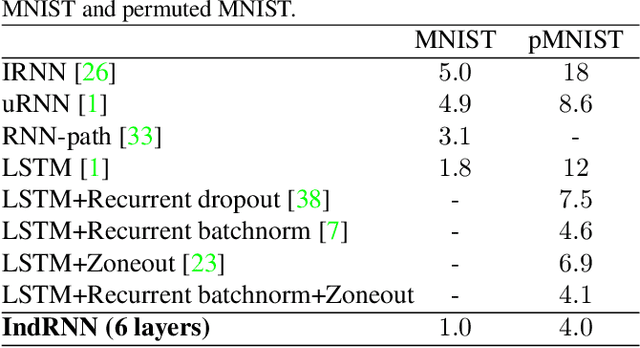
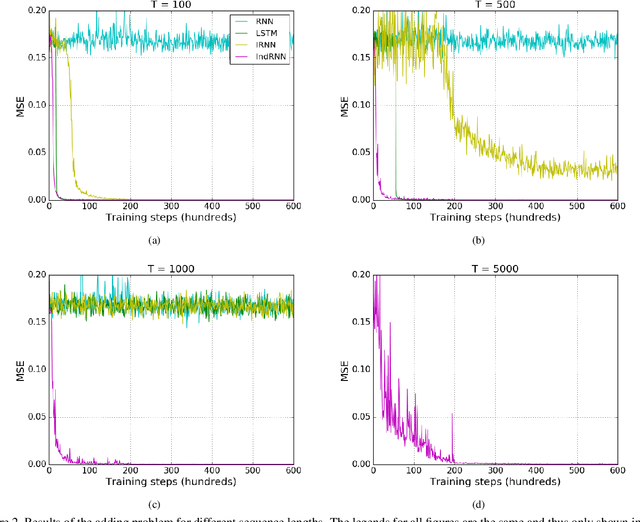
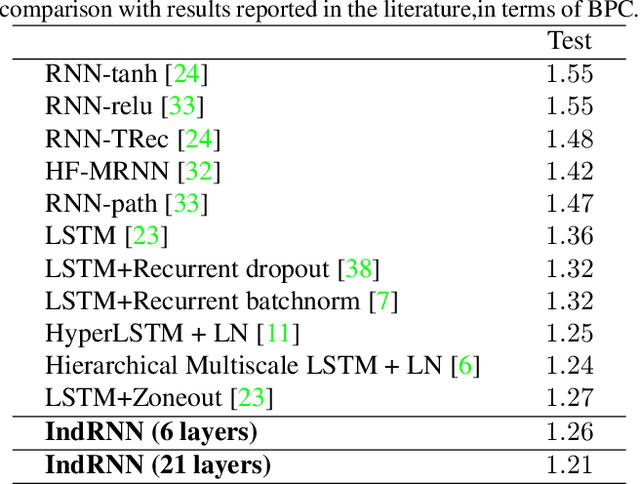
Recurrent neural networks (RNNs) have been widely used for processing sequential data. However, RNNs are commonly difficult to train due to the well-known gradient vanishing and exploding problems and hard to learn long-term patterns. Long short-term memory (LSTM) and gated recurrent unit (GRU) were developed to address these problems, but the use of hyperbolic tangent and the sigmoid action functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep network is challenging. In addition, all the neurons in an RNN layer are entangled together and their behaviour is hard to interpret. To address these problems, a new type of RNN, referred to as independently recurrent neural network (IndRNN), is proposed in this paper, where neurons in the same layer are independent of each other and they are connected across layers. We have shown that an IndRNN can be easily regulated to prevent the gradient exploding and vanishing problems while allowing the network to learn long-term dependencies. Moreover, an IndRNN can work with non-saturated activation functions such as relu (rectified linear unit) and be still trained robustly. Multiple IndRNNs can be stacked to construct a network that is deeper than the existing RNNs. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (21 layers used in the experiment) and still be trained robustly. Better performances have been achieved on various tasks by using IndRNNs compared with the traditional RNN and LSTM. The code is available at https://github.com/Sunnydreamrain/IndRNN_Theano_Lasagne.
RGB-D-based Human Motion Recognition with Deep Learning: A Survey
Apr 24, 2018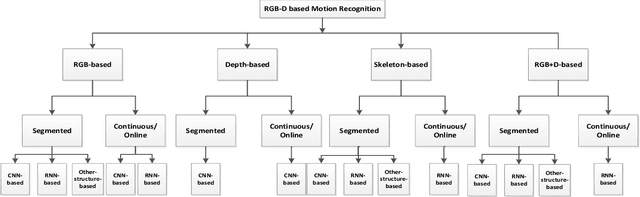
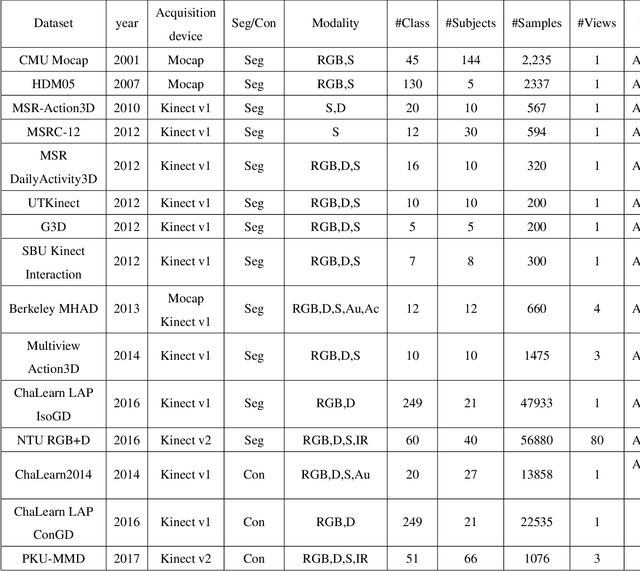

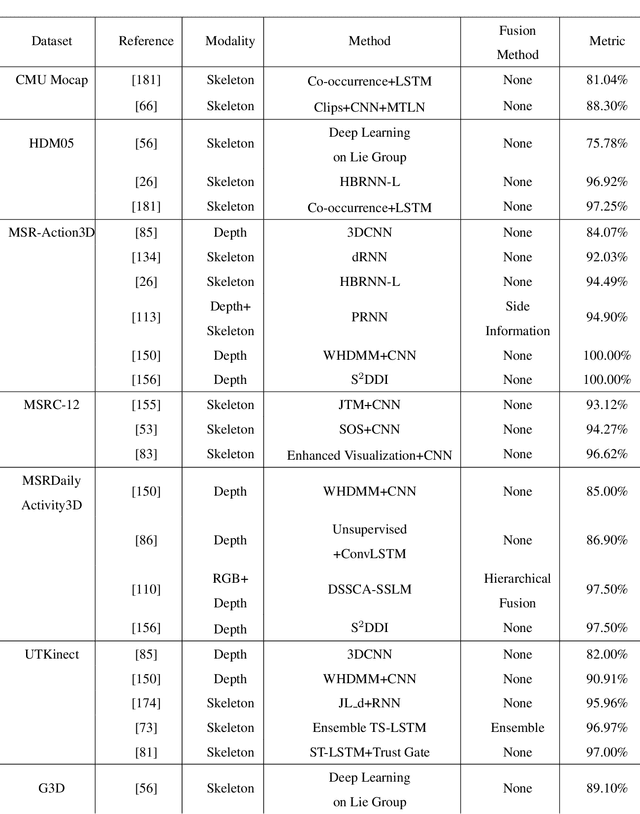
Human motion recognition is one of the most important branches of human-centered research activities. In recent years, motion recognition based on RGB-D data has attracted much attention. Along with the development in artificial intelligence, deep learning techniques have gained remarkable success in computer vision. In particular, convolutional neural networks (CNN) have achieved great success for image-based tasks, and recurrent neural networks (RNN) are renowned for sequence-based problems. Specifically, deep learning methods based on the CNN and RNN architectures have been adopted for motion recognition using RGB-D data. In this paper, a detailed overview of recent advances in RGB-D-based motion recognition is presented. The reviewed methods are broadly categorized into four groups, depending on the modality adopted for recognition: RGB-based, depth-based, skeleton-based and RGB+D-based. As a survey focused on the application of deep learning to RGB-D-based motion recognition, we explicitly discuss the advantages and limitations of existing techniques. Particularly, we highlighted the methods of encoding spatial-temporal-structural information inherent in video sequence, and discuss potential directions for future research.
Depth Pooling Based Large-scale 3D Action Recognition with Convolutional Neural Networks
Apr 17, 2018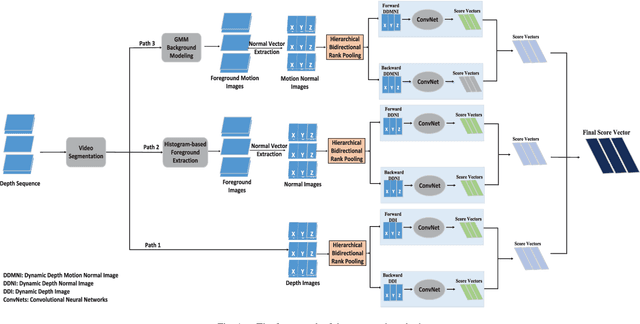
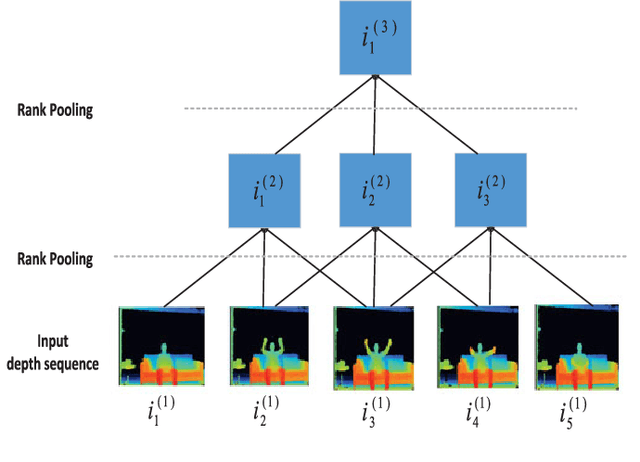
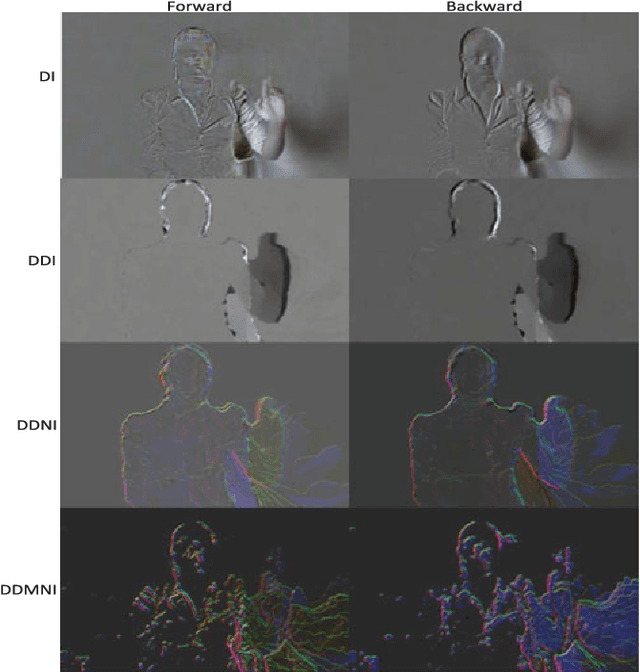
This paper proposes three simple, compact yet effective representations of depth sequences, referred to respectively as Dynamic Depth Images (DDI), Dynamic Depth Normal Images (DDNI) and Dynamic Depth Motion Normal Images (DDMNI), for both isolated and continuous action recognition. These dynamic images are constructed from a segmented sequence of depth maps using hierarchical bidirectional rank pooling to effectively capture the spatial-temporal information. Specifically, DDI exploits the dynamics of postures over time and DDNI and DDMNI exploit the 3D structural information captured by depth maps. Upon the proposed representations, a ConvNet based method is developed for action recognition. The image-based representations enable us to fine-tune the existing Convolutional Neural Network (ConvNet) models trained on image data without training a large number of parameters from scratch. The proposed method achieved the state-of-art results on three large datasets, namely, the Large-scale Continuous Gesture Recognition Dataset (means Jaccard index 0.4109), the Large-scale Isolated Gesture Recognition Dataset (59.21%), and the NTU RGB+D Dataset (87.08% cross-subject and 84.22% cross-view) even though only the depth modality was used.
A Fusion Framework for Camouflaged Moving Foreground Detection in the Wavelet Domain
Apr 16, 2018


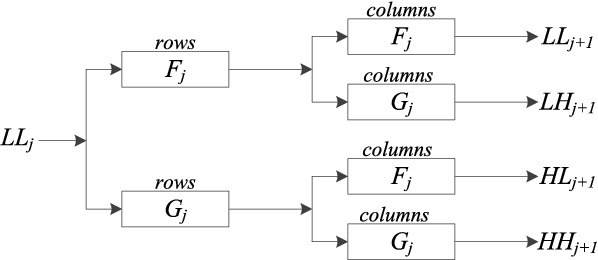
Detecting camouflaged moving foreground objects has been known to be difficult due to the similarity between the foreground objects and the background. Conventional methods cannot distinguish the foreground from background due to the small differences between them and thus suffer from under-detection of the camouflaged foreground objects. In this paper, we present a fusion framework to address this problem in the wavelet domain. We first show that the small differences in the image domain can be highlighted in certain wavelet bands. Then the likelihood of each wavelet coefficient being foreground is estimated by formulating foreground and background models for each wavelet band. The proposed framework effectively aggregates the likelihoods from different wavelet bands based on the characteristics of the wavelet transform. Experimental results demonstrated that the proposed method significantly outperformed existing methods in detecting camouflaged foreground objects. Specifically, the average F-measure for the proposed algorithm was 0.87, compared to 0.71 to 0.8 for the other state-of-the-art methods.