 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2020 Challenge on Real-World Image Super-Resolution: Methods and Results
May 05, 2020
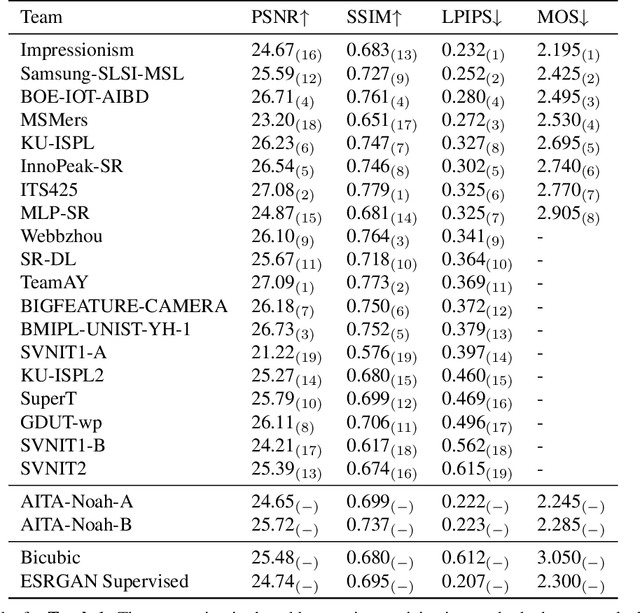
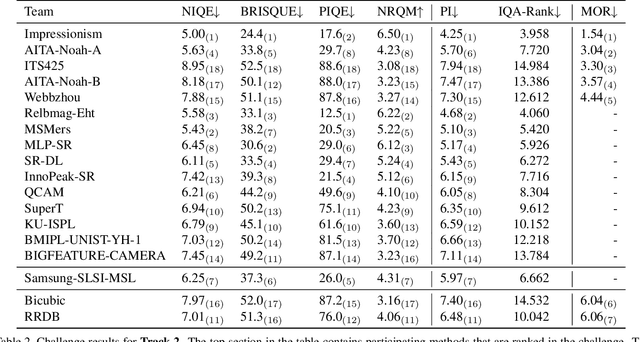

This paper reviews the NTIRE 2020 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided along with a set of unpaired high-quality target images. In Track 1: Image Processing artifacts, the aim is to super-resolve images with synthetically generated image processing artifacts. This allows for quantitative benchmarking of the approaches \wrt a ground-truth image. In Track 2: Smartphone Images, real low-quality smart phone images have to be super-resolved. In both tracks, the ultimate goal is to achieve the best perceptual quality, evaluated using a human study. This is the second challenge on the subject, following AIM 2019, targeting to advance the state-of-the-art in super-resolution. To measure the performance we use the benchmark protocol from AIM 2019. In total 22 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Unsupervised Real Image Super-Resolution via Generative Variational AutoEncoder
Apr 27, 2020
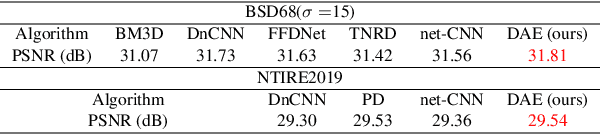
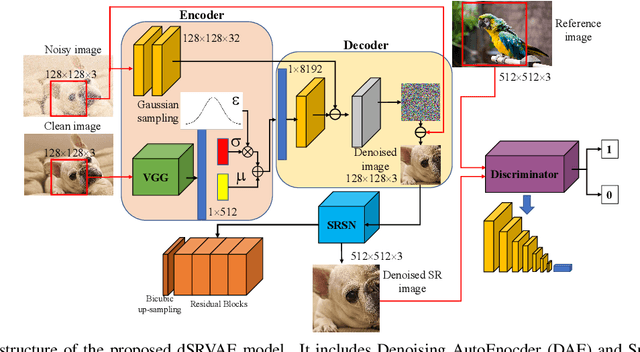
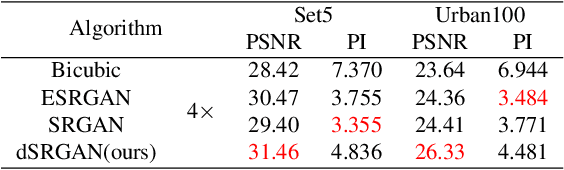
Benefited from the deep learning, image Super-Resolution has been one of the most developing research fields in computer vision. Depending upon whether using a discriminator or not, a deep convolutional neural network can provide an image with high fidelity or better perceptual quality. Due to the lack of ground truth images in real life, people prefer a photo-realistic image with low fidelity to a blurry image with high fidelity. In this paper, we revisit the classic example based image super-resolution approaches and come up with a novel generative model for perceptual image super-resolution. Given that real images contain various noise and artifacts, we propose a joint image denoising and super-resolution model via Variational AutoEncoder. We come up with a conditional variational autoencoder to encode the reference for dense feature vector which can then be transferred to the decoder for target image denoising. With the aid of the discriminator, an additional overhead of super-resolution subnetwork is attached to super-resolve the denoised image with photo-realistic visual quality. We participated the NTIRE2020 Real Image Super-Resolution Challenge. Experimental results show that by using the proposed approach, we can obtain enlarged images with clean and pleasant features compared to other supervised methods. We also compared our approach with state-of-the-art methods on various datasets to demonstrate the efficiency of our proposed unsupervised super-resolution model.
* 9 pages, 7 figures, CVPR2020 NTIRE2020 Real Image Super-Resolution Challenge
Image Super-Resolution via Attention based Back Projection Networks
Oct 10, 2019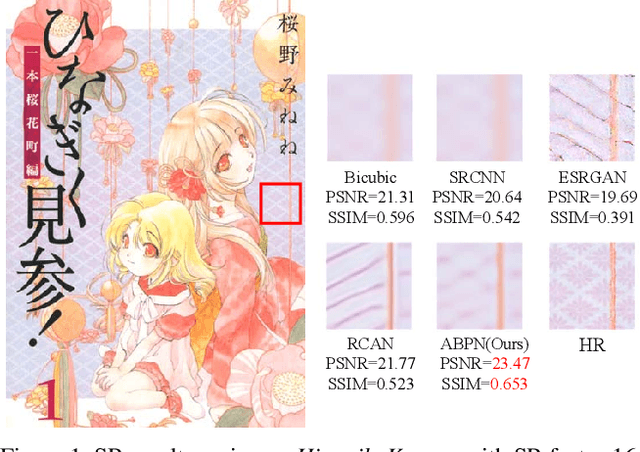
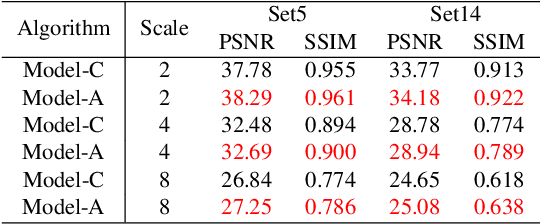
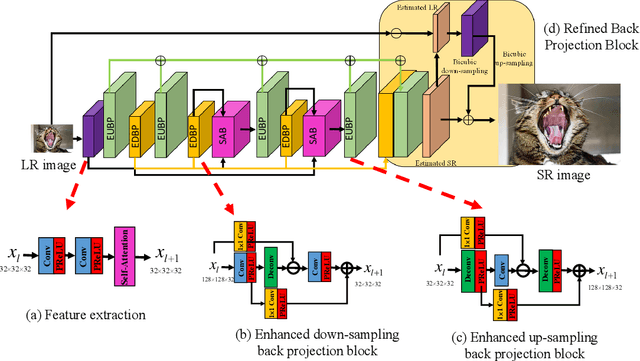
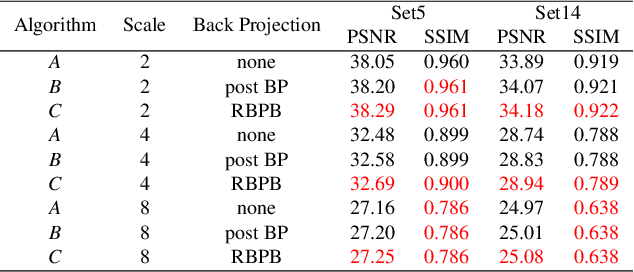
Deep learning based image Super-Resolution (SR) has shown rapid development due to its ability of big data digestion. Generally, deeper and wider networks can extract richer feature maps and generate SR images with remarkable quality. However, the more complex network we have, the more time consumption is required for practical applications. It is important to have a simplified network for efficient image SR. In this paper, we propose an Attention based Back Projection Network (ABPN) for image super-resolution. Similar to some recent works, we believe that the back projection mechanism can be further developed for SR. Enhanced back projection blocks are suggested to iteratively update low- and high-resolution feature residues. Inspired by recent studies on attention models, we propose a Spatial Attention Block (SAB) to learn the cross-correlation across features at different layers. Based on the assumption that a good SR image should be close to the original LR image after down-sampling. We propose a Refined Back Projection Block (RBPB) for final reconstruction. Extensive experiments on some public and AIM2019 Image Super-Resolution Challenge datasets show that the proposed ABPN can provide state-of-the-art or even better performance in both quantitative and qualitative measurements.
* 9 pages, 7 figures, ABPN
Hierarchical Back Projection Network for Image Super-Resolution
Jun 20, 2019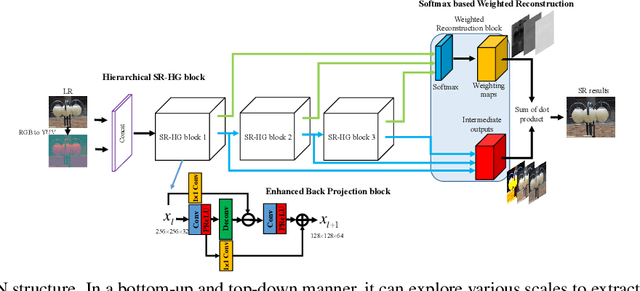
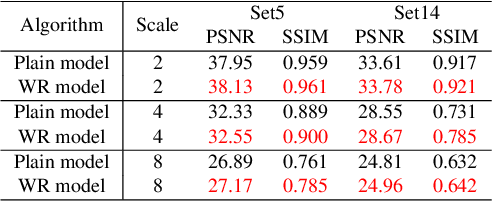
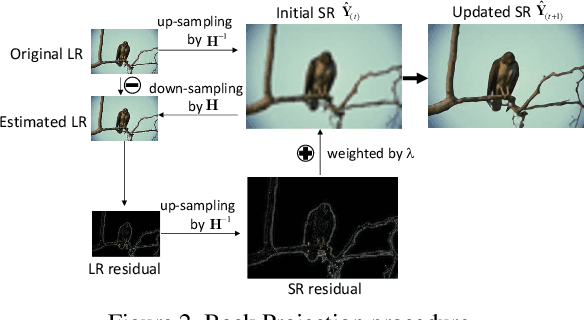
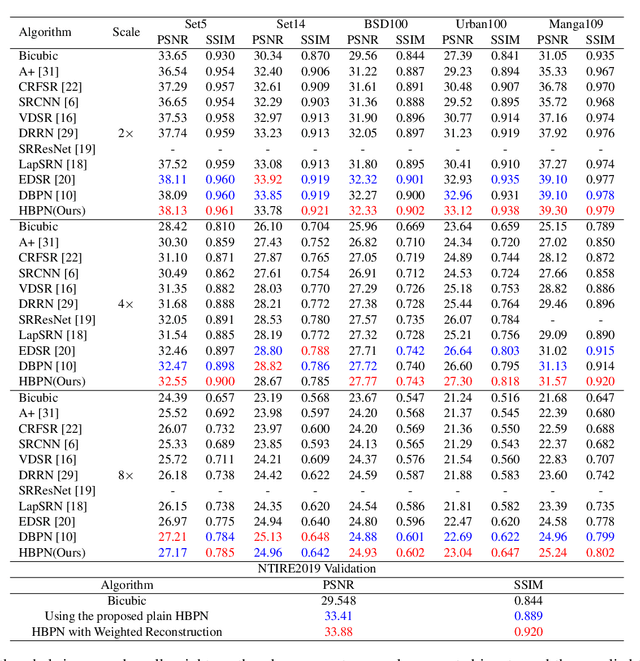
Deep learning based single image super-resolution methods use a large number of training datasets and have recently achieved great quality progress both quantitatively and qualitatively. Most deep networks focus on nonlinear mapping from low-resolution inputs to high-resolution outputs via residual learning without exploring the feature abstraction and analysis. We propose a Hierarchical Back Projection Network (HBPN), that cascades multiple HourGlass (HG) modules to bottom-up and top-down process features across all scales to capture various spatial correlations and then consolidates the best representation for reconstruction. We adopt the back projection blocks in our proposed network to provide the error correlated up and down-sampling process to replace simple deconvolution and pooling process for better estimation. A new Softmax based Weighted Reconstruction (WR) process is used to combine the outputs of HG modules to further improve super-resolution. Experimental results on various datasets (including the validation dataset, NTIRE2019, of the Real Image Super-resolution Challenge) show that our proposed approach can achieve and improve the performance of the state-of-the-art methods for different scaling factors.