 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPIrigen: MPI Code Generation through Domain-Specific Language Models
Feb 14, 2024



The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
Domain-Specific Code Language Models: Unraveling the Potential for HPC Codes and Tasks
Dec 20, 2023With easier access to powerful compute resources, there is a growing trend in AI for software development to develop larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because these LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need large LMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller LMs for specific domains - we call them domain-specific LMs. Specifically, we start off with HPC as a domain and build an HPC-specific LM, named MonoCoder, that is orders of magnitude smaller than existing LMs but delivers similar, if not better performance, on non-HPC and HPC tasks. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against conventional multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, achieves similar results on normalized-perplexity tests and much better ones in CodeBLEU competence for high-performance and parallel code generations. Furthermore, fine-tuning the base model for the specific task of parallel code generation (OpenMP parallel for pragmas) demonstrates outstanding results compared to GPT, especially when local misleading semantics are removed by our novel pre-processor Tokompiler, showcasing the ability of domain-specific models to assist in HPC-relevant tasks.
Scope is all you need: Transforming LLMs for HPC Code
Aug 18, 2023



With easier access to powerful compute resources, there is a growing trend in the field of AI for software development to develop larger and larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size (e.g., billions of parameters) and demand expensive compute resources for training. We found this design choice confusing - why do we need large LLMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question design choices made by existing LLMs by developing smaller LLMs for specific domains - we call them domain-specific LLMs. Specifically, we start off with HPC as a domain and propose a novel tokenizer named Tokompiler, designed specifically for preprocessing code in HPC and compilation-centric tasks. Tokompiler leverages knowledge of language primitives to generate language-oriented tokens, providing a context-aware understanding of code structure while avoiding human semantics attributed to code structures completely. We applied Tokompiler to pre-train two state-of-the-art models, SPT-Code and Polycoder, for a Fortran code corpus mined from GitHub. We evaluate the performance of these models against the conventional LLMs. Results demonstrate that Tokompiler significantly enhances code completion accuracy and semantic understanding compared to traditional tokenizers in normalized-perplexity tests, down to ~1 perplexity score. This research opens avenues for further advancements in domain-specific LLMs, catering to the unique demands of HPC and compilation tasks.
Silhouette: Toward Performance-Conscious and Transferable CPU Embeddings
Dec 15, 2022



Learned embeddings are widely used to obtain concise data representation and enable transfer learning between different data sets and tasks. In this paper, we present Silhouette, our approach that leverages publicly-available performance data sets to learn CPU embeddings. We show how these embeddings enable transfer learning between data sets of different types and sizes. Each of these scenarios leads to an improvement in accuracy for the target data set.
Rapid Training of Very Large Ensembles of Diverse Neural Networks
Sep 12, 2018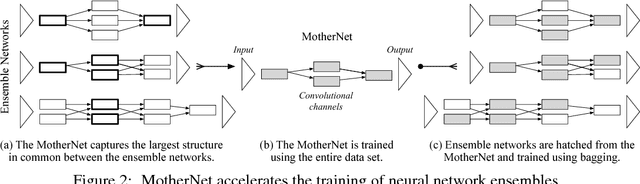
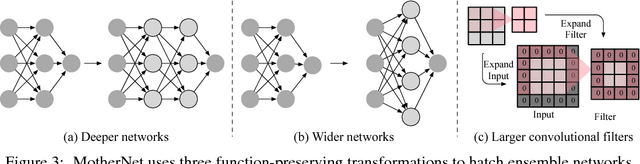
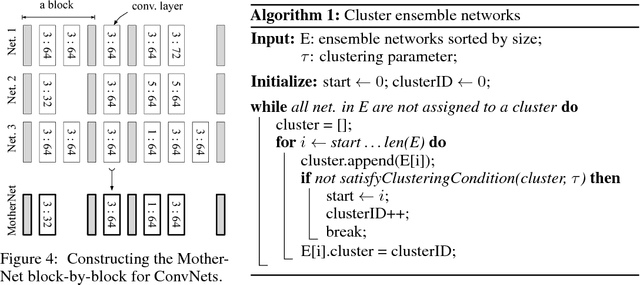
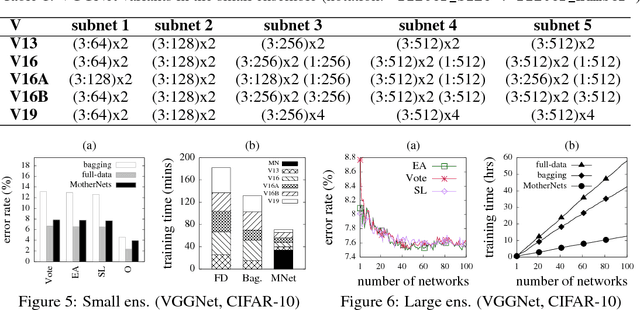
Ensembles of deep neural networks with diverse architectures significantly improve generalization accuracy. However, training such ensembles requires a large amount of computational resources and time as every network in the ensemble has to be separately trained. In practice, this restricts the number of different deep neural network architectures that can be included within an ensemble. We propose a new approach to address this problem. Our approach captures the structural similarity between members of a neural network ensemble and train it only once. Subsequently, this knowledge is transferred to all members of the ensemble using function-preserving transformations. Then, these ensemble networks converge significantly faster as compared to training from scratch. We show through experiments on CIFAR-10, CIFAR-100, and SVHN data sets that our approach can train large and diverse ensembles of deep neural networks achieving comparable accuracy to existing approaches in a fraction of their training time. In particular, our approach trains an ensemble of $100$ variants of deep neural networks with diverse architectures up to $6 \times$ faster as compared to existing approaches. This improvement in training cost grows linearly with the size of the ensemble.