 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotographic Image Synthesis with Cascaded Refinement Networks
Jul 28, 2017

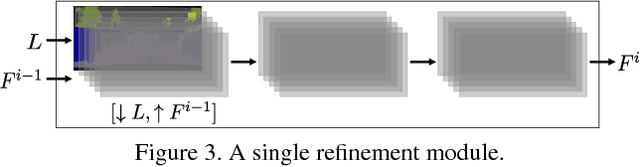
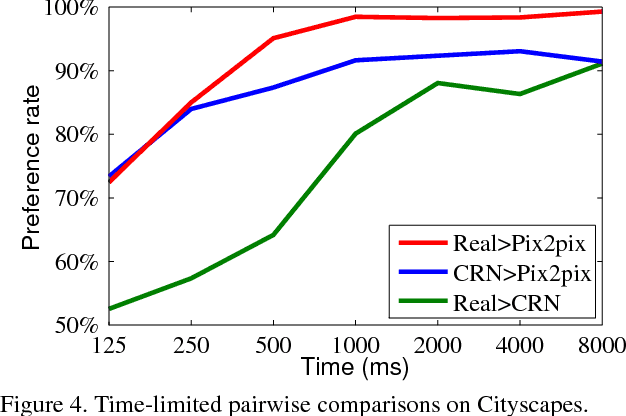
We present an approach to synthesizing photographic images conditioned on semantic layouts. Given a semantic label map, our approach produces an image with photographic appearance that conforms to the input layout. The approach thus functions as a rendering engine that takes a two-dimensional semantic specification of the scene and produces a corresponding photographic image. Unlike recent and contemporaneous work, our approach does not rely on adversarial training. We show that photographic images can be synthesized from semantic layouts by a single feedforward network with appropriate structure, trained end-to-end with a direct regression objective. The presented approach scales seamlessly to high resolutions; we demonstrate this by synthesizing photographic images at 2-megapixel resolution, the full resolution of our training data. Extensive perceptual experiments on datasets of outdoor and indoor scenes demonstrate that images synthesized by the presented approach are considerably more realistic than alternative approaches. The results are shown in the supplementary video at https://youtu.be/0fhUJT21-bs
Dilated Residual Networks
May 28, 2017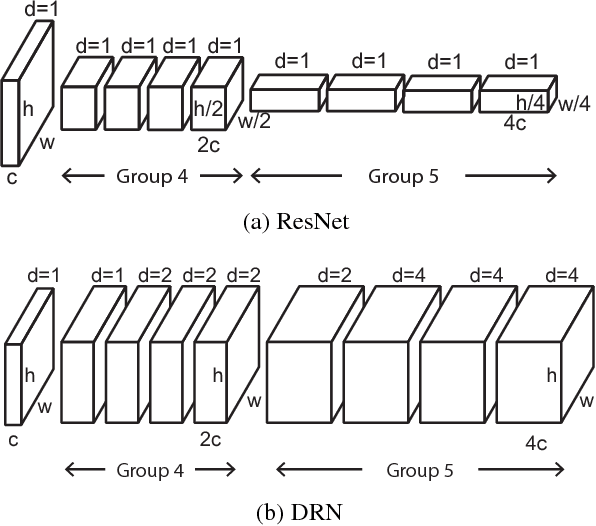
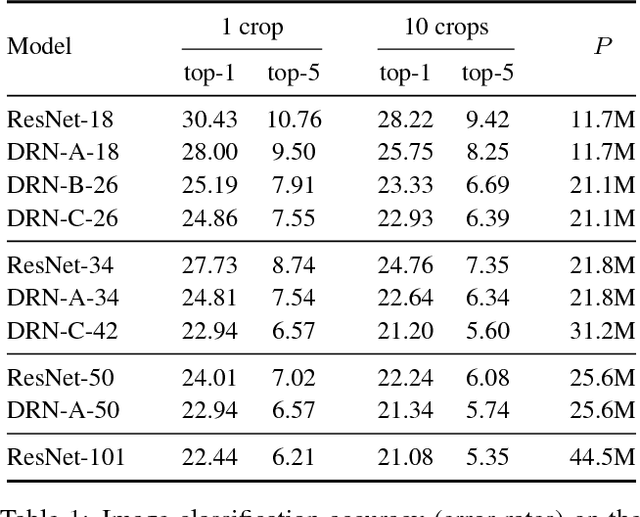
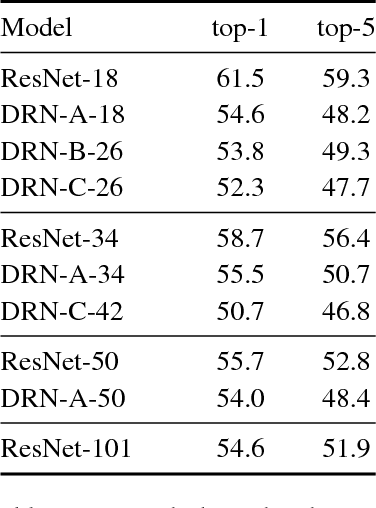
Convolutional networks for image classification progressively reduce resolution until the image is represented by tiny feature maps in which the spatial structure of the scene is no longer discernible. Such loss of spatial acuity can limit image classification accuracy and complicate the transfer of the model to downstream applications that require detailed scene understanding. These problems can be alleviated by dilation, which increases the resolution of output feature maps without reducing the receptive field of individual neurons. We show that dilated residual networks (DRNs) outperform their non-dilated counterparts in image classification without increasing the model's depth or complexity. We then study gridding artifacts introduced by dilation, develop an approach to removing these artifacts (`degridding'), and show that this further increases the performance of DRNs. In addition, we show that the accuracy advantage of DRNs is further magnified in downstream applications such as object localization and semantic segmentation.
Accurate Optical Flow via Direct Cost Volume Processing
Apr 24, 2017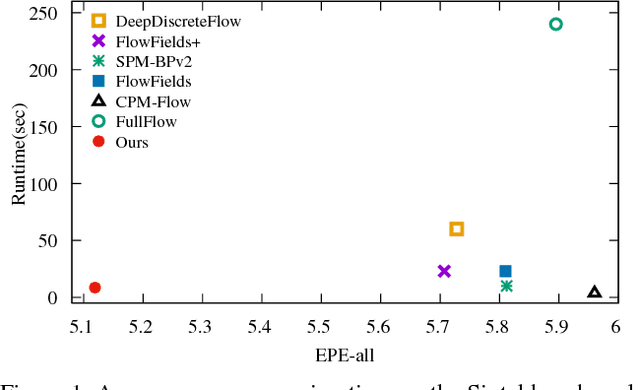
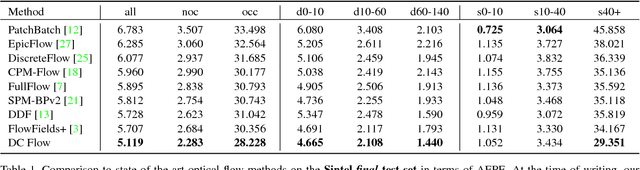

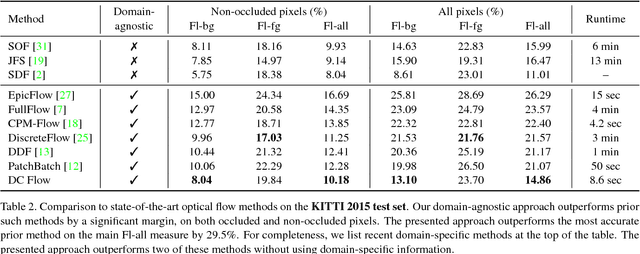
We present an optical flow estimation approach that operates on the full four-dimensional cost volume. This direct approach shares the structural benefits of leading stereo matching pipelines, which are known to yield high accuracy. To this day, such approaches have been considered impractical due to the size of the cost volume. We show that the full four-dimensional cost volume can be constructed in a fraction of a second due to its regularity. We then exploit this regularity further by adapting semi-global matching to the four-dimensional setting. This yields a pipeline that achieves significantly higher accuracy than state-of-the-art optical flow methods while being faster than most. Our approach outperforms all published general-purpose optical flow methods on both Sintel and KITTI 2015 benchmarks.
Learning to Act by Predicting the Future
Feb 14, 2017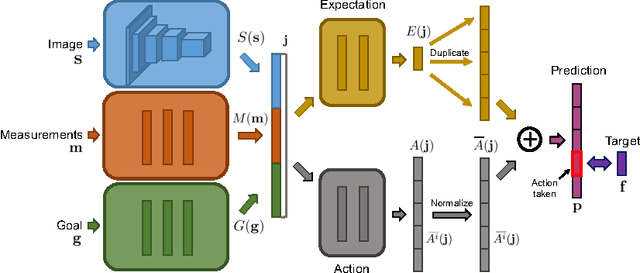
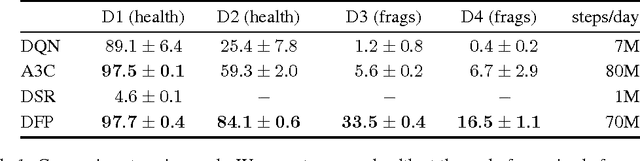

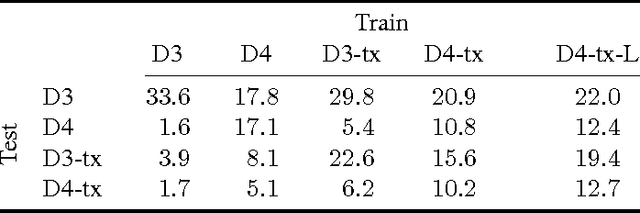
We present an approach to sensorimotor control in immersive environments. Our approach utilizes a high-dimensional sensory stream and a lower-dimensional measurement stream. The cotemporal structure of these streams provides a rich supervisory signal, which enables training a sensorimotor control model by interacting with the environment. The model is trained using supervised learning techniques, but without extraneous supervision. It learns to act based on raw sensory input from a complex three-dimensional environment. The presented formulation enables learning without a fixed goal at training time, and pursuing dynamically changing goals at test time. We conduct extensive experiments in three-dimensional simulations based on the classical first-person game Doom. The results demonstrate that the presented approach outperforms sophisticated prior formulations, particularly on challenging tasks. The results also show that trained models successfully generalize across environments and goals. A model trained using the presented approach won the Full Deathmatch track of the Visual Doom AI Competition, which was held in previously unseen environments.
Direct Sparse Odometry
Oct 07, 2016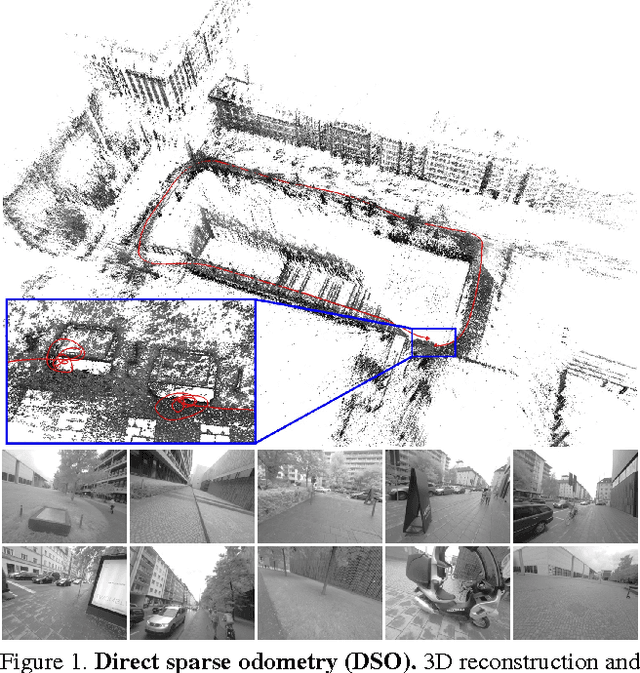
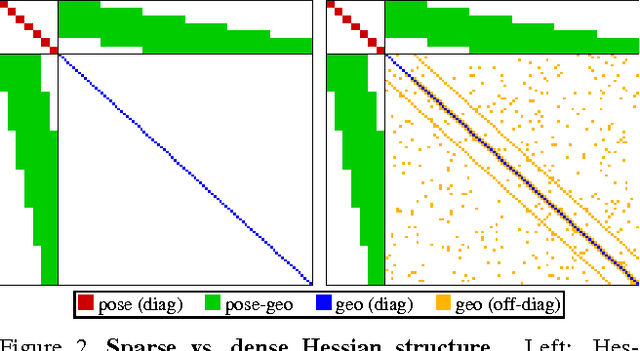
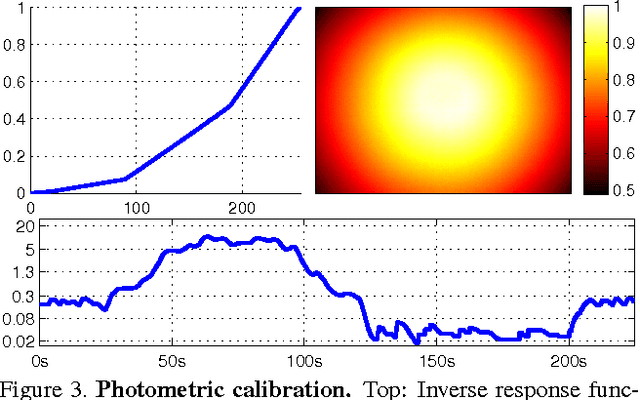

We propose a novel direct sparse visual odometry formulation. It combines a fully direct probabilistic model (minimizing a photometric error) with consistent, joint optimization of all model parameters, including geometry -- represented as inverse depth in a reference frame -- and camera motion. This is achieved in real time by omitting the smoothness prior used in other direct methods and instead sampling pixels evenly throughout the images. Since our method does not depend on keypoint detectors or descriptors, it can naturally sample pixels from across all image regions that have intensity gradient, including edges or smooth intensity variations on mostly white walls. The proposed model integrates a full photometric calibration, accounting for exposure time, lens vignetting, and non-linear response functions. We thoroughly evaluate our method on three different datasets comprising several hours of video. The experiments show that the presented approach significantly outperforms state-of-the-art direct and indirect methods in a variety of real-world settings, both in terms of tracking accuracy and robustness.
Playing for Data: Ground Truth from Computer Games
Aug 07, 2016
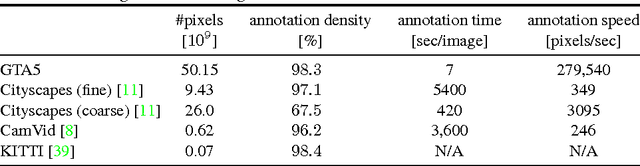


Recent progress in computer vision has been driven by high-capacity models trained on large datasets. Unfortunately, creating large datasets with pixel-level labels has been extremely costly due to the amount of human effort required. In this paper, we present an approach to rapidly creating pixel-accurate semantic label maps for images extracted from modern computer games. Although the source code and the internal operation of commercial games are inaccessible, we show that associations between image patches can be reconstructed from the communication between the game and the graphics hardware. This enables rapid propagation of semantic labels within and across images synthesized by the game, with no access to the source code or the content. We validate the presented approach by producing dense pixel-level semantic annotations for 25 thousand images synthesized by a photorealistic open-world computer game. Experiments on semantic segmentation datasets show that using the acquired data to supplement real-world images significantly increases accuracy and that the acquired data enables reducing the amount of hand-labeled real-world data: models trained with game data and just 1/3 of the CamVid training set outperform models trained on the complete CamVid training set.
A Large Dataset of Object Scans
May 05, 2016

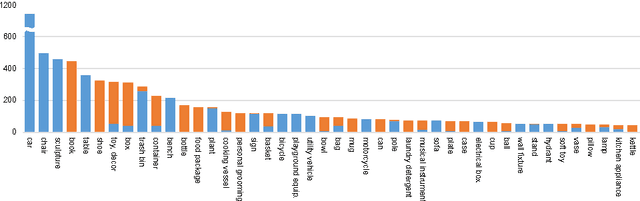
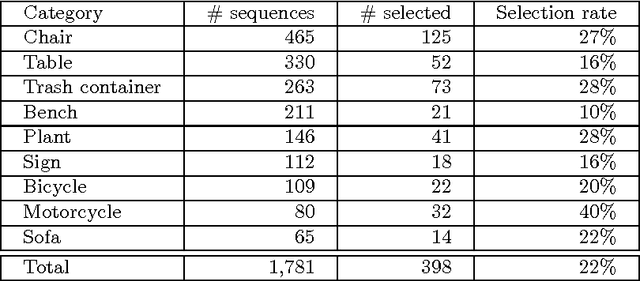
We have created a dataset of more than ten thousand 3D scans of real objects. To create the dataset, we recruited 70 operators, equipped them with consumer-grade mobile 3D scanning setups, and paid them to scan objects in their environments. The operators scanned objects of their choosing, outside the laboratory and without direct supervision by computer vision professionals. The result is a large and diverse collection of object scans: from shoes, mugs, and toys to grand pianos, construction vehicles, and large outdoor sculptures. We worked with an attorney to ensure that data acquisition did not violate privacy constraints. The acquired data was irrevocably placed in the public domain and is available freely at http://redwood-data.org/3dscan .
Multi-Scale Context Aggregation by Dilated Convolutions
Apr 30, 2016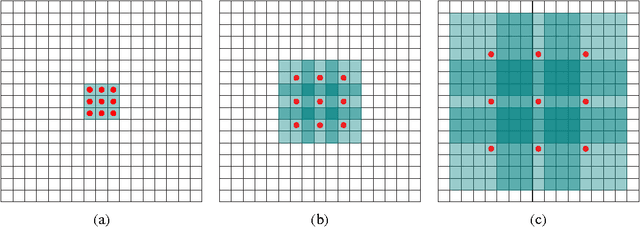
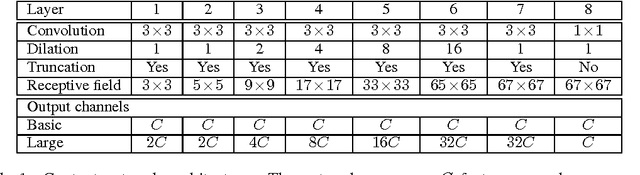


State-of-the-art models for semantic segmentation are based on adaptations of convolutional networks that had originally been designed for image classification. However, dense prediction and image classification are structurally different. In this work, we develop a new convolutional network module that is specifically designed for dense prediction. The presented module uses dilated convolutions to systematically aggregate multi-scale contextual information without losing resolution. The architecture is based on the fact that dilated convolutions support exponential expansion of the receptive field without loss of resolution or coverage. We show that the presented context module increases the accuracy of state-of-the-art semantic segmentation systems. In addition, we examine the adaptation of image classification networks to dense prediction and show that simplifying the adapted network can increase accuracy.
Full Flow: Optical Flow Estimation By Global Optimization over Regular Grids
Apr 12, 2016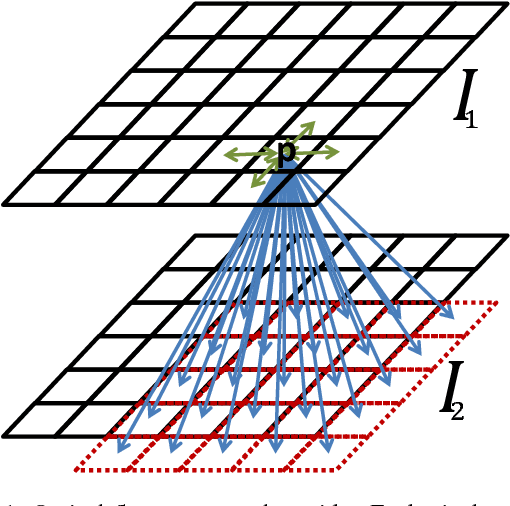
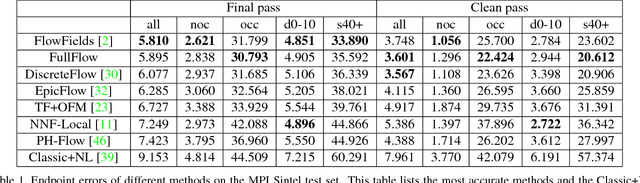

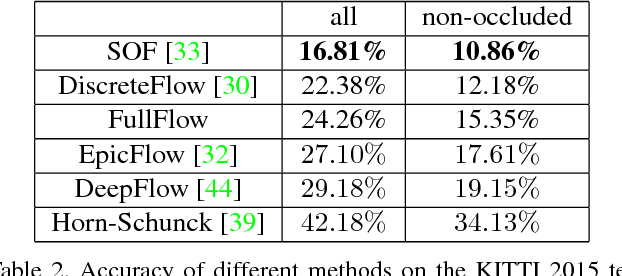
We present a global optimization approach to optical flow estimation. The approach optimizes a classical optical flow objective over the full space of mappings between discrete grids. No descriptor matching is used. The highly regular structure of the space of mappings enables optimizations that reduce the computational complexity of the algorithm's inner loop from quadratic to linear and support efficient matching of tens of thousands of nodes to tens of thousands of displacements. We show that one-shot global optimization of a classical Horn-Schunck-type objective over regular grids at a single resolution is sufficient to initialize continuous interpolation and achieve state-of-the-art performance on challenging modern benchmarks.
Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials
Oct 20, 2012Most state-of-the-art techniques for multi-class image segmentation and labeling use conditional random fields defined over pixels or image regions. While region-level models often feature dense pairwise connectivity, pixel-level models are considerably larger and have only permitted sparse graph structures. In this paper, we consider fully connected CRF models defined on the complete set of pixels in an image. The resulting graphs have billions of edges, making traditional inference algorithms impractical. Our main contribution is a highly efficient approximate inference algorithm for fully connected CRF models in which the pairwise edge potentials are defined by a linear combination of Gaussian kernels. Our experiments demonstrate that dense connectivity at the pixel level substantially improves segmentation and labeling accuracy.
* NIPS 2011