 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Representations for Adaptive Deployment
Jun 01, 2022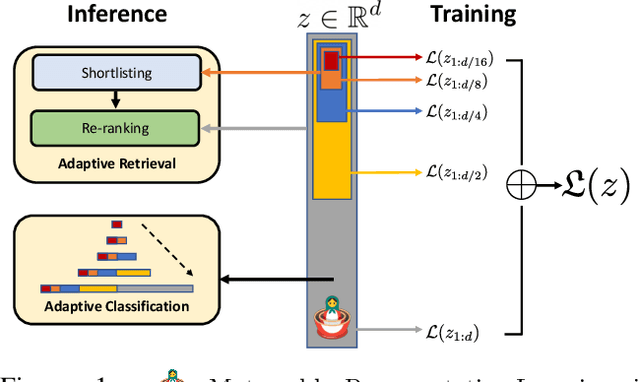
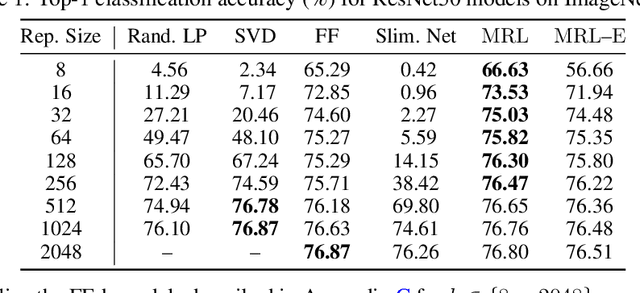
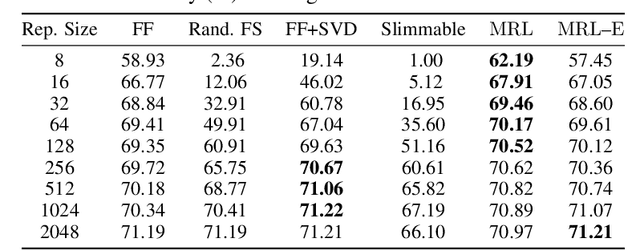
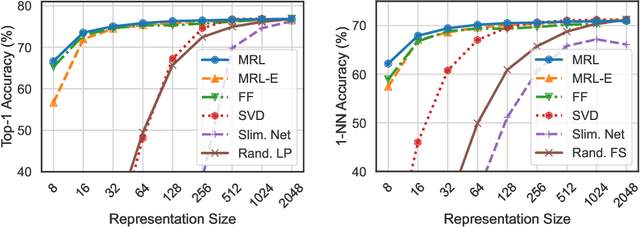
Learned representations are a central component in modern ML systems, serving a multitude of downstream tasks. When training such representations, it is often the case that computational and statistical constraints for each downstream task are unknown. In this context rigid, fixed capacity representations can be either over or under-accommodating to the task at hand. This leads us to ask: can we design a flexible representation that can adapt to multiple downstream tasks with varying computational resources? Our main contribution is Matryoshka Representation Learning (MRL) which encodes information at different granularities and allows a single embedding to adapt to the computational constraints of downstream tasks. MRL minimally modifies existing representation learning pipelines and imposes no additional cost during inference and deployment. MRL learns coarse-to-fine representations that are at least as accurate and rich as independently trained low-dimensional representations. The flexibility within the learned Matryoshka Representations offer: (a) up to 14x smaller embedding size for ImageNet-1K classification at the same level of accuracy; (b) up to 14x real-world speed-ups for large-scale retrieval on ImageNet-1K and 4K; and (c) up to 2% accuracy improvements for long-tail few-shot classification, all while being as robust as the original representations. Finally, we show that MRL extends seamlessly to web-scale datasets (ImageNet, JFT) across various modalities -- vision (ViT, ResNet), vision + language (ALIGN) and language (BERT). MRL code and pretrained models are open-sourced at https://github.com/RAIVNLab/MRL.
Forward Compatible Training for Representation Learning
Dec 06, 2021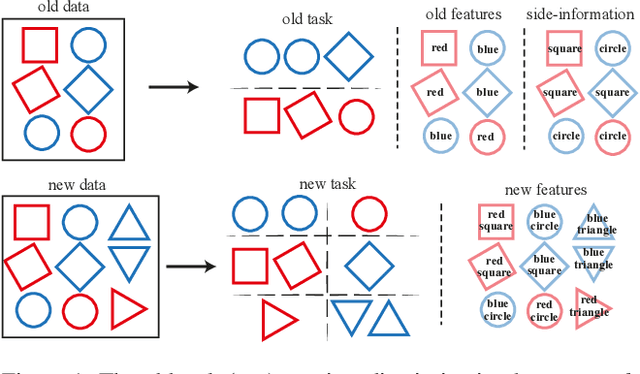
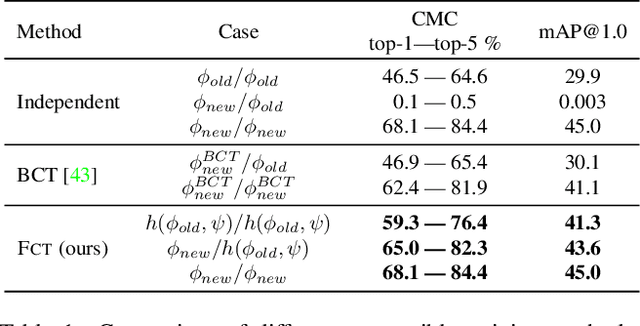

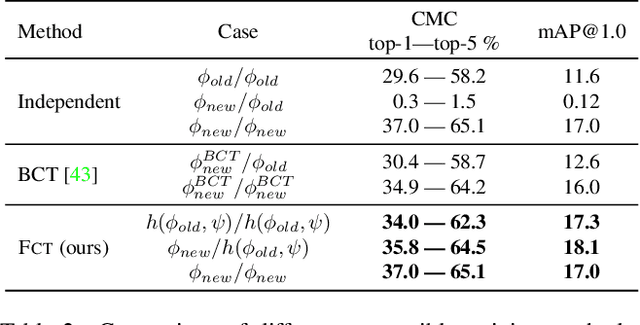
In visual retrieval systems, updating the embedding model requires recomputing features for every piece of data. This expensive process is referred to as backfilling. Recently, the idea of backward compatible training (BCT) was proposed. To avoid the cost of backfilling, BCT modifies training of the new model to make its representations compatible with those of the old model. However, BCT can significantly hinder the performance of the new model. In this work, we propose a new learning paradigm for representation learning: forward compatible training (FCT). In FCT, when the old model is trained, we also prepare for a future unknown version of the model. We propose learning side-information, an auxiliary feature for each sample which facilitates future updates of the model. To develop a powerful and flexible framework for model compatibility, we combine side-information with a forward transformation from old to new embeddings. Training of the new model is not modified, hence, its accuracy is not degraded. We demonstrate significant retrieval accuracy improvement compared to BCT for various datasets: ImageNet-1k (+18.1%), Places-365 (+5.4%), and VGG-Face2 (+8.3%). FCT obtains model compatibility when the new and old models are trained across different datasets, losses, and architectures.
LLC: Accurate, Multi-purpose Learnt Low-dimensional Binary Codes
Jun 02, 2021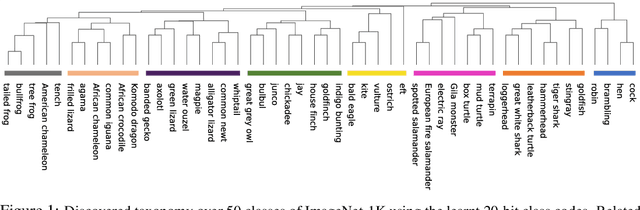

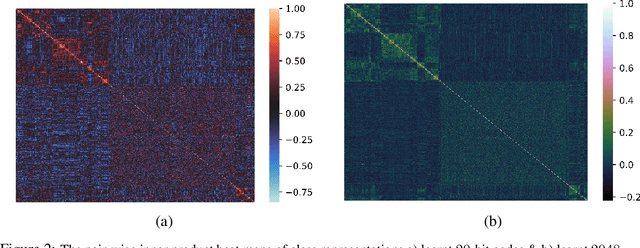

Learning binary representations of instances and classes is a classical problem with several high potential applications. In modern settings, the compression of high-dimensional neural representations to low-dimensional binary codes is a challenging task and often require large bit-codes to be accurate. In this work, we propose a novel method for Learning Low-dimensional binary Codes (LLC) for instances as well as classes. Our method does not require any side-information, like annotated attributes or label meta-data, and learns extremely low-dimensional binary codes (~20 bits for ImageNet-1K). The learnt codes are super-efficient while still ensuring nearly optimal classification accuracy for ResNet50 on ImageNet-1K. We demonstrate that the learnt codes capture intrinsically important features in the data, by discovering an intuitive taxonomy over classes. We further quantitatively measure the quality of our codes by applying it to the efficient image retrieval as well as out-of-distribution (OOD) detection problems. For ImageNet-100 retrieval problem, our learnt binary codes outperform 16 bit HashNet using only 10 bits and also are as accurate as 10 dimensional real representations. Finally, our learnt binary codes can perform OOD detection, out-of-the-box, as accurately as a baseline that needs ~3000 samples to tune its threshold, while we require none. Code and pre-trained models are available at https://github.com/RAIVNLab/LLC.
Parameter Norm Growth During Training of Transformers
Nov 11, 2020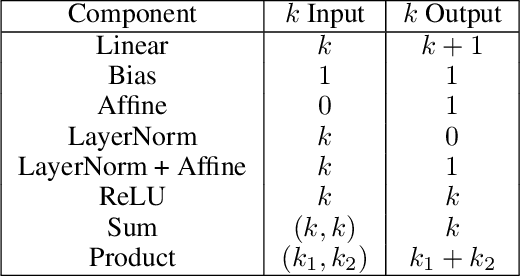
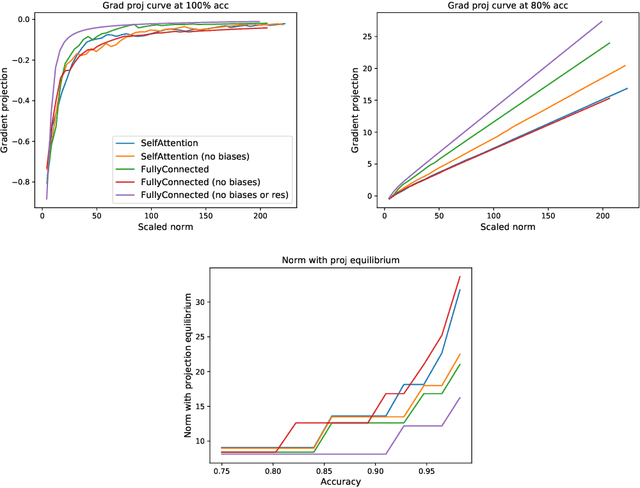
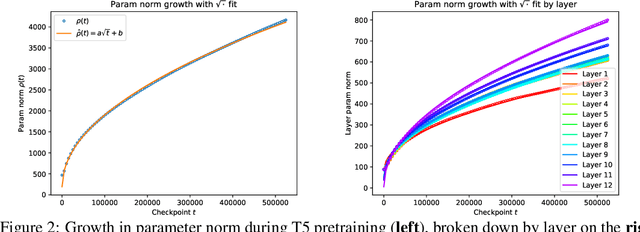
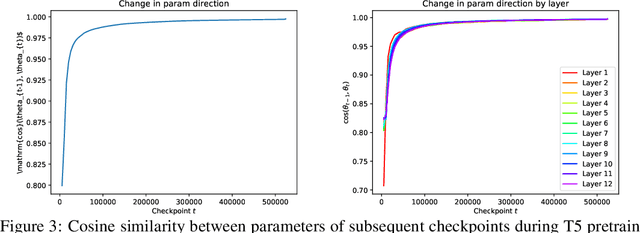
The capacity of neural networks like the widely adopted transformer is known to be very high. Evidence is emerging that they learn successfully due to inductive bias in the training routine, typically some variant of gradient descent (GD). To better understand this bias, we study the tendency of transformer parameters to grow in magnitude during training. We find, both theoretically and empirically, that, in certain contexts, GD increases the parameter $L_2$ norm up to a threshold that itself increases with training-set accuracy. This means increasing training accuracy over time enables the norm to increase. Empirically, we show that the norm grows continuously over pretraining for T5 (Raffel et al., 2019). We show that pretrained T5 approximates a semi-discretized network with saturated activation functions. Such "saturated" networks are known to have a reduced capacity compared to the original network family that can be described in automata-theoretic terms. This suggests saturation is a new characterization of an inductive bias implicit in GD that is of particular interest for NLP. While our experiments focus on transformers, our theoretical analysis extends to other architectures with similar formal properties, such as feedforward ReLU networks.
Supermasks in Superposition
Jun 30, 2020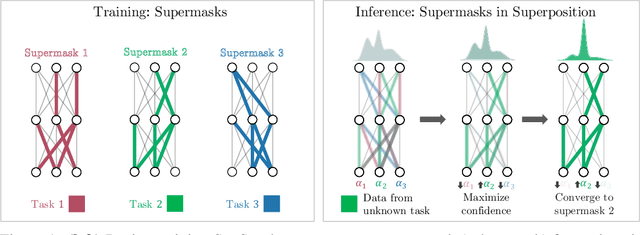

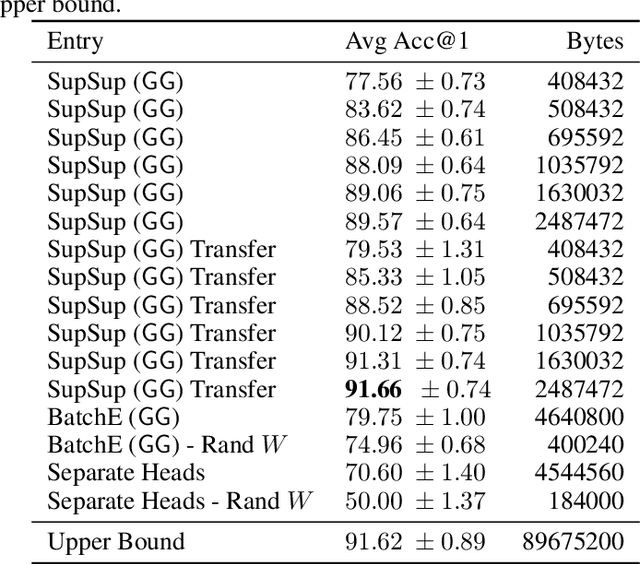
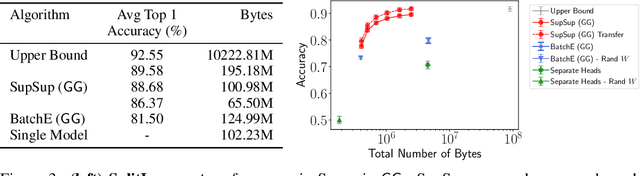
We present the Supermasks in Superposition (SupSup) model, capable of sequentially learning thousands of tasks without catastrophic forgetting. Our approach uses a randomly initialized, fixed base network and for each task finds a subnetwork (supermask) that achieves good performance. If task identity is given at test time, the correct subnetwork can be retrieved with minimal memory usage. If not provided, SupSup can infer the task using gradient-based optimization to find a linear superposition of learned supermasks which minimizes the output entropy. In practice we find that a single gradient step is often sufficient to identify the correct mask, even among 2500 tasks. We also showcase two promising extensions. First, SupSup models can be trained entirely without task identity information, as they may detect when they are uncertain about new data and allocate an additional supermask for the new training distribution. Finally the entire, growing set of supermasks can be stored in a constant-sized reservoir by implicitly storing them as attractors in a fixed-sized Hopfield network.
Soft Threshold Weight Reparameterization for Learnable Sparsity
Mar 11, 2020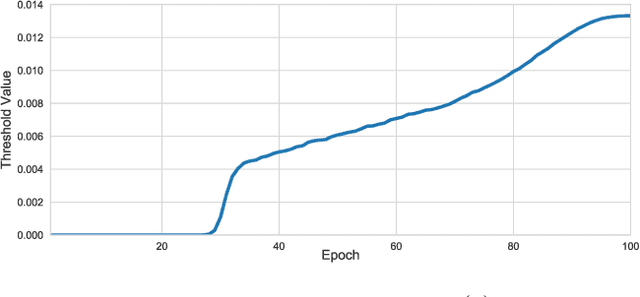
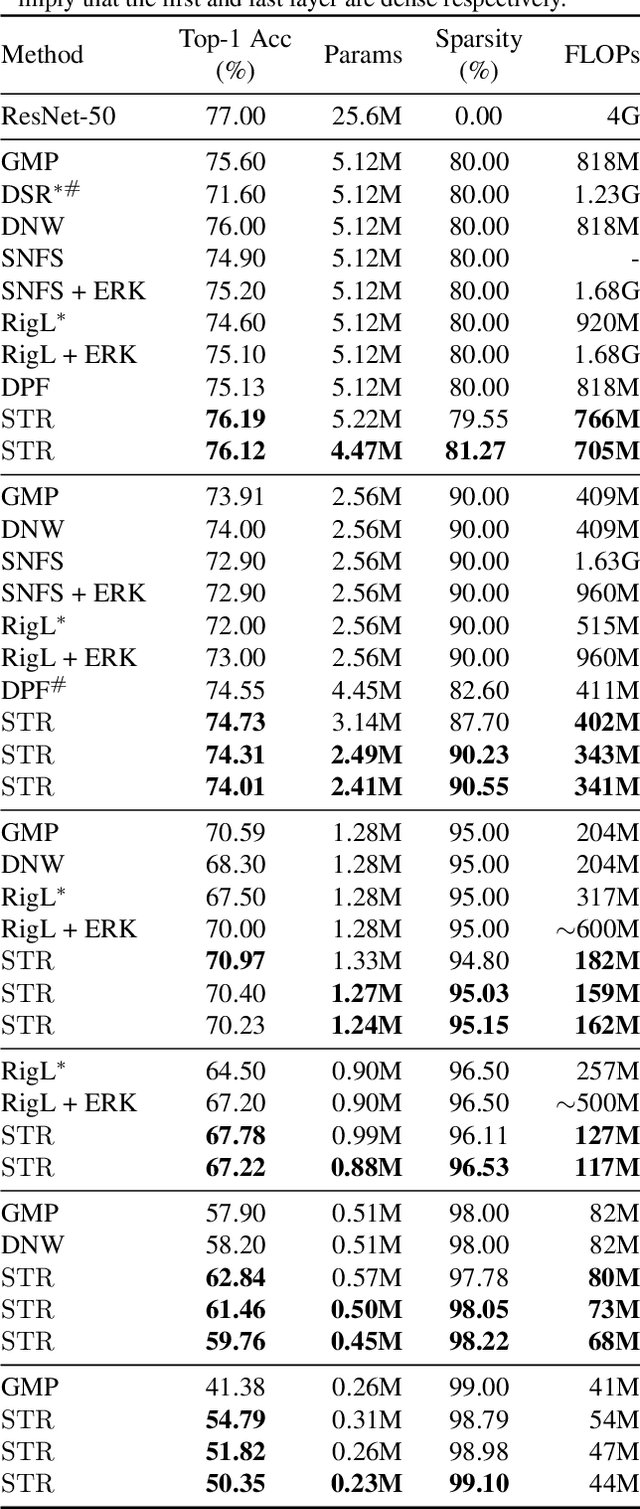
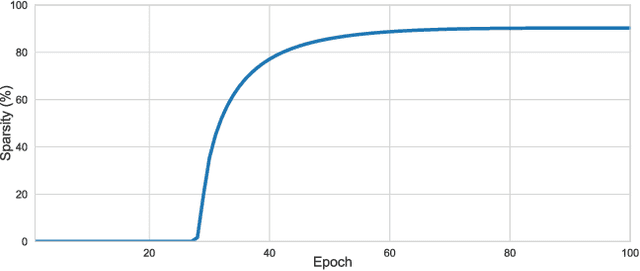
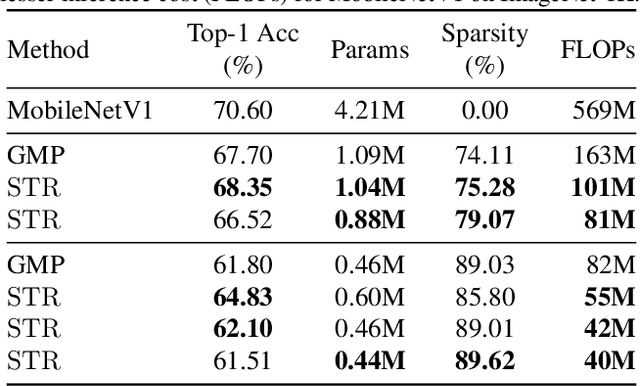
Sparsity in Deep Neural Networks (DNNs) is studied extensively with the focus of maximizing prediction accuracy given an overall parameter budget. Existing methods rely on uniform or heuristic non-uniform sparsity budgets which have sub-optimal layer-wise parameter allocation resulting in a) lower prediction accuracy or b) higher inference cost (FLOPs). This work proposes Soft Threshold Reparameterization (STR), a novel use of the soft-threshold operator on DNN weights. STR smoothly induces sparsity while learning pruning thresholds thereby obtaining a non-uniform sparsity budget. Our method achieves state-of-the-art accuracy for unstructured sparsity in CNNs (ResNet50 and MobileNetV1 on ImageNet-1K), and, additionally, learns non-uniform budgets that empirically reduce the FLOPs by up to 50%. Notably, STR boosts the accuracy over existing results by up to 10% in the ultra sparse (99%) regime and can also be used to induce low-rank (structured sparsity) in RNNs. In short, STR is a simple mechanism which learns effective sparsity budgets that contrast with popular heuristics.
What's Hidden in a Randomly Weighted Neural Network?
Nov 29, 2019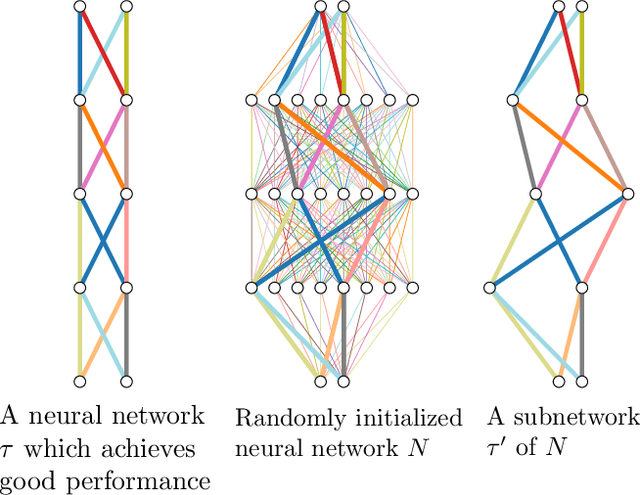
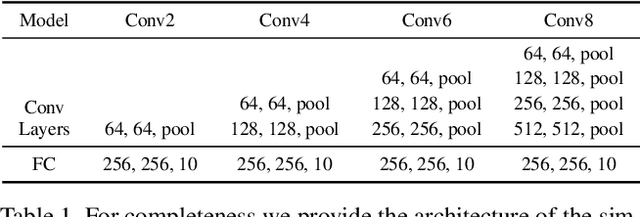
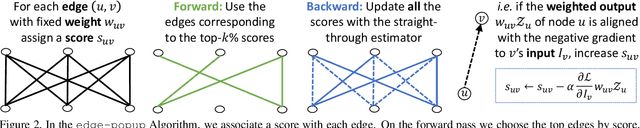
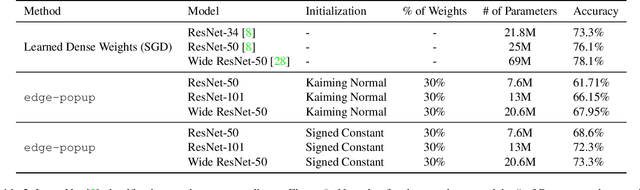
Training a neural network is synonymous with learning the values of the weights. In contrast, we demonstrate that randomly weighted neural networks contain subnetworks which achieve impressive performance without ever training the weight values. Hidden in a randomly weighted Wide ResNet-50 we show that there is a subnetwork (with random weights) that is smaller than, but matches the performance of a ResNet-34 trained on ImageNet. Not only do these "untrained subnetworks" exist, but we provide an algorithm to effectively find them. We empirically show that as randomly weighted neural networks with fixed weights grow wider and deeper, an "untrained subnetwork" approaches a network with learned weights in accuracy.
Improving Shape Deformation in Unsupervised Image-to-Image Translation
Aug 13, 2018



Unsupervised image-to-image translation techniques are able to map local texture between two domains, but they are typically unsuccessful when the domains require larger shape change. Inspired by semantic segmentation, we introduce a discriminator with dilated convolutions that is able to use information from across the entire image to train a more context-aware generator. This is coupled with a multi-scale perceptual loss that is better able to represent error in the underlying shape of objects. We demonstrate that this design is more capable of representing shape deformation in a challenging toy dataset, plus in complex mappings with significant dataset variation between humans, dolls, and anime faces, and between cats and dogs.