 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncalibrated Neural Inverse Rendering for Photometric Stereo of General Surfaces
Dec 12, 2020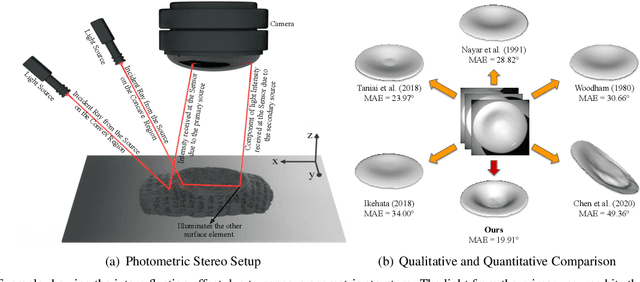
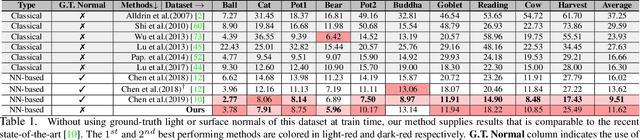
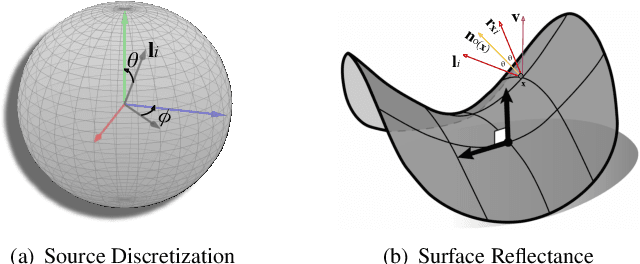

This paper presents an uncalibrated deep neural network framework for the photometric stereo problem. For training models to solve the problem, existing neural network-based methods either require exact light directions or ground-truth surface normals of the object or both. However, in practice, it is challenging to procure both of this information precisely, which restricts the broader adoption of photometric stereo algorithms for vision application. To bypass this difficulty, we propose an uncalibrated neural inverse rendering approach to this problem. Our method first estimates the light directions from the input images and then optimizes an image reconstruction loss to calculate the surface normals, bidirectional reflectance distribution function value, and depth. Additionally, our formulation explicitly models the concave and convex parts of a complex surface to consider the effects of interreflections in the image formation process. Extensive evaluation of the proposed method on the challenging subjects generally shows comparable or better results than the supervised and classical approaches.
Vid2CAD: CAD Model Alignment using Multi-View Constraints from Videos
Dec 08, 2020
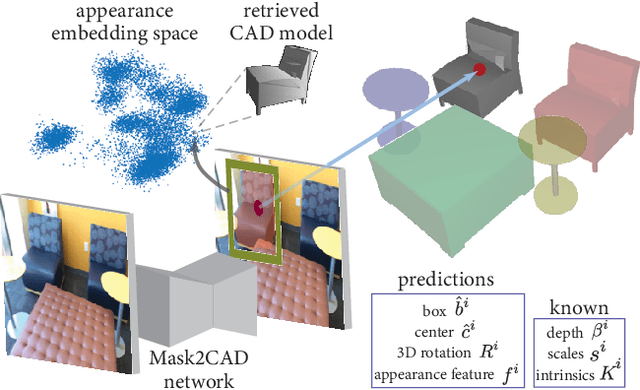
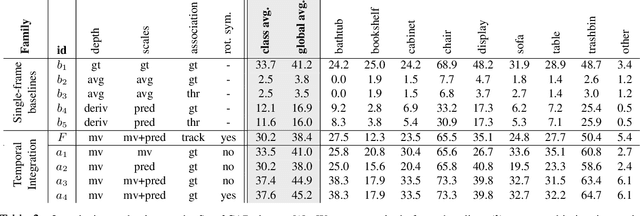

We address the task of aligning CAD models to a video sequence of a complex scene containing multiple objects. Our method is able to process arbitrary videos and fully automatically recover the 9 DoF pose for each object appearing in it, thus aligning them in a common 3D coordinate frame. The core idea of our method is to integrate neural network predictions from individual frames with a temporally global, multi-view constraint optimization formulation. This integration process resolves the scale and depth ambiguities in the per-frame predictions, and generally improves the estimate of all pose parameters. By leveraging multi-view constraints, our method also resolves occlusions and handles objects that are out of view in individual frames, thus reconstructing all objects into a single globally consistent CAD representation of the scene. In comparison to the state-of-the-art single-frame method Mask2CAD that we build on, we achieve substantial improvements on Scan2CAD (from 11.6% to 30.2% class average accuracy).
DeFMO: Deblurring and Shape Recovery of Fast Moving Objects
Dec 01, 2020
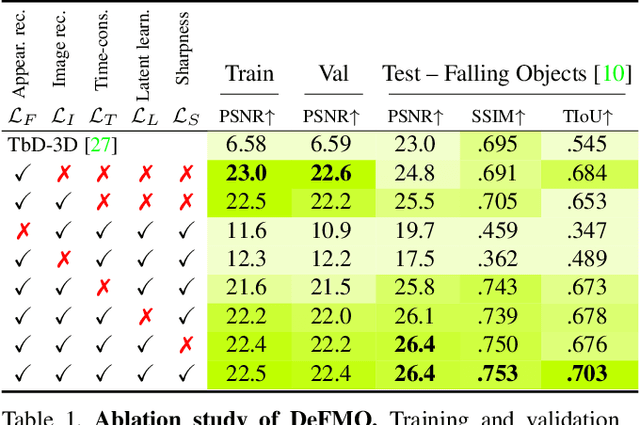
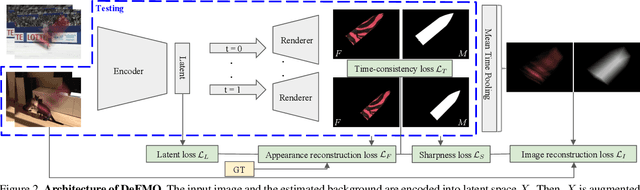
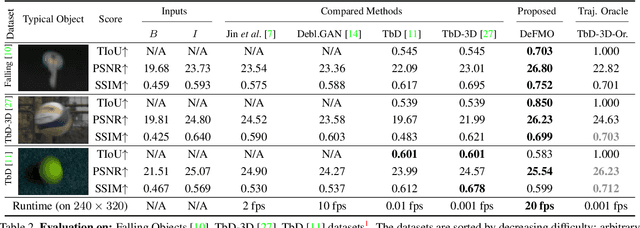
Objects moving at high speed appear significantly blurred when captured with cameras. The blurry appearance is especially ambiguous when the object has complex shape or texture. In such cases, classical methods, or even humans, are unable to recover the object's appearance and motion. We propose a method that, given a single image with its estimated background, outputs the object's appearance and position in a series of sub-frames as if captured by a high-speed camera (i.e. temporal super-resolution). The proposed generative model embeds an image of the blurred object into a latent space representation, disentangles the background, and renders the sharp appearance. Inspired by the image formation model, we design novel self-supervised loss function terms that boost performance and show good generalization capabilities. The proposed DeFMO method is trained on a complex synthetic dataset, yet it performs well on real-world data from several datasets. DeFMO outperforms the state of the art and generates high-quality temporal super-resolution frames.
Efficient Full Image Interactive Segmentation by Leveraging Within-image Appearance Similarity
Jul 16, 2020
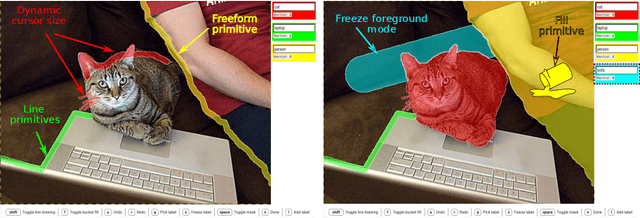

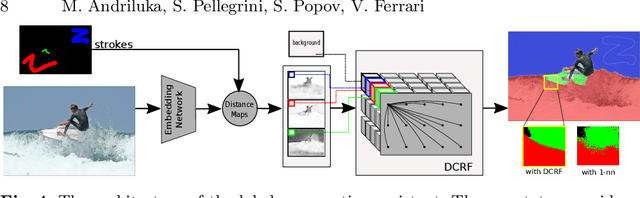
We propose a new approach to interactive full-image semantic segmentation which enables quickly collecting training data for new datasets with previously unseen semantic classes (A demo is available at https://youtu.be/yUk8D5gEX-o). We leverage a key observation: propagation from labeled to unlabeled pixels does not necessarily require class-specific knowledge, but can be done purely based on appearance similarity within an image. We build on this observation and propose an approach capable of jointly propagating pixel labels from multiple classes without having explicit class-specific appearance models. To enable long-range propagation, our approach first globally measures appearance similarity between labeled and unlabeled pixels across the entire image. Then it locally integrates per-pixel measurements which improves the accuracy at boundaries and removes noisy label switches in homogeneous regions. We also design an efficient manual annotation interface that extends the traditional polygon drawing tools with a suite of additional convenient features (and add automatic propagation to it). Experiments with human annotators on the COCO Panoptic Challenge dataset show that the combination of our better manual interface and our novel automatic propagation mechanism leads to reducing annotation time by more than factor of 2x compared to polygon drawing. We also test our method on the ADE-20k and Fashionista datasets without making any dataset-specific adaptation nor retraining our model, demonstrating that it can generalize to new datasets and visual classes.
CoReNet: Coherent 3D scene reconstruction from a single RGB image
Apr 27, 2020
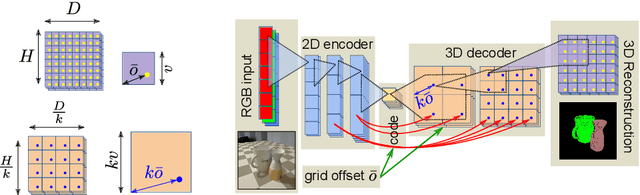
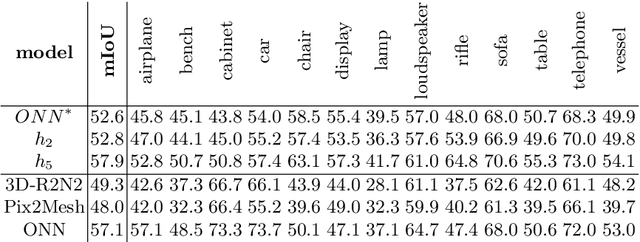
Advances in deep learning techniques have allowed recent work to reconstruct the shape of a single object given only one RBG image as input. Building on common encoder-decoder architectures for this task, we propose three extensions: (1) ray-traced skip connections that propagate local 2D information to the output 3D volume in a physically correct manner; (2) a hybrid 3D volume representation that enables building translation equivariant models, while at the same time encoding fine object details without an excessive memory footprint; (3) a reconstruction loss tailored to capture overall object geometry. Furthermore, we adapt our model to address the harder task of reconstructing multiple objects from a single image. We reconstruct all objects jointly in one pass, producing a coherent reconstruction, where all objects live in a single consistent 3D coordinate frame relative to the camera and they do not intersect in 3D space. We also handle occlusions and resolve them by hallucinating the missing object parts in the 3D volume. We validate the impact of our contributions experimentally both on synthetic data from ShapeNet as well as real images from Pix3D. Our method outperforms the state-of-the-art single-object methods on both datasets. Finally, we evaluate performance quantitatively on multiple object reconstruction with synthetic scenes assembled from ShapeNet objects.
Training Neural Networks to Produce Compatible Features
Apr 08, 2020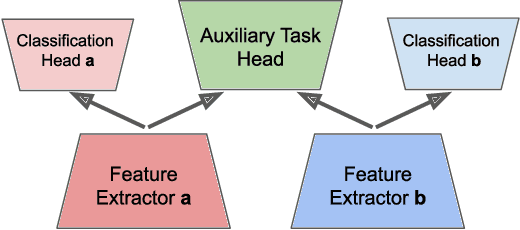
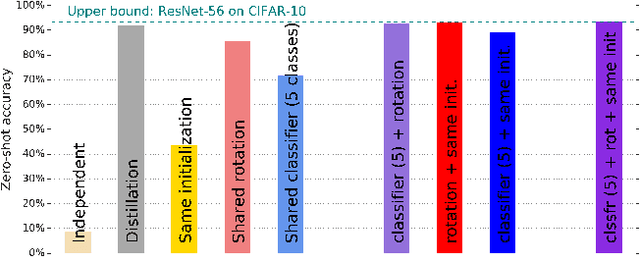

This paper makes a first step towards compatible and hence reusable network components. Rather than training networks for different tasks independently, we adapt the training process to produce network components that are compatible across tasks. We propose and compare several different approaches to accomplish compatibility. Our experiments on CIFAR-10 show that: (i) we can train networks to produce compatible features, without degrading task accuracy compared to training networks independently; (ii) the degree of compatibility is highly dependent on where we split the network into a feature extractor and a classification head; (iii) random initialization has a large effect on compatibility; (iv) we can train incrementally: given previously trained components, we can train new ones which are also compatible with them. This work is part of a larger goal to increase network reusability: we envision that compatibility will enable solving new tasks by mixing and matching suitable components.
C-Flow: Conditional Generative Flow Models for Images and 3D Point Clouds
Dec 15, 2019
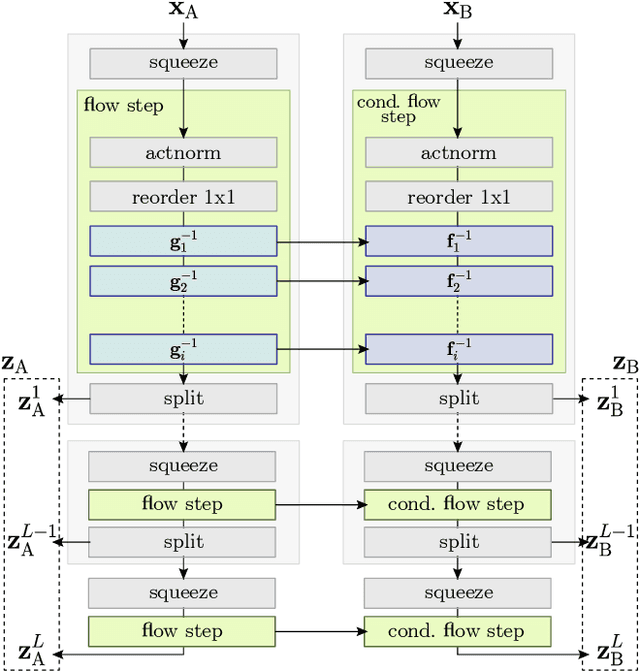
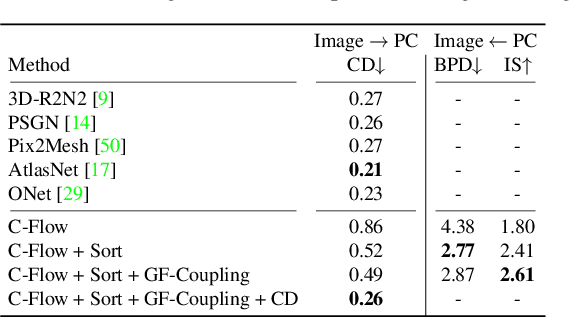
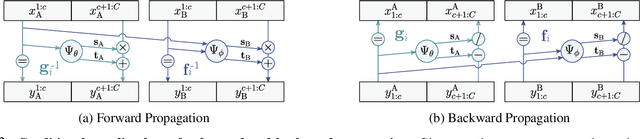
Flow-based generative models have highly desirable properties like exact log-likelihood evaluation and exact latent-variable inference, however they are still in their infancy and have not received as much attention as alternative generative models. In this paper, we introduce C-Flow, a novel conditioning scheme that brings normalizing flows to an entirely new scenario with great possibilities for multi-modal data modeling. C-Flow is based on a parallel sequence of invertible mappings in which a source flow guides the target flow at every step, enabling fine-grained control over the generation process. We also devise a new strategy to model unordered 3D point clouds that, in combination with the conditioning scheme, makes it possible to address 3D reconstruction from a single image and its inverse problem of rendering an image given a point cloud. We demonstrate our conditioning method to be very adaptable, being also applicable to image manipulation, style transfer and multi-modal image-to-image mapping in a diversity of domains, including RGB images, segmentation maps, and edge masks.
Neural Voxel Renderer: Learning an Accurate and Controllable Rendering Tool
Dec 10, 2019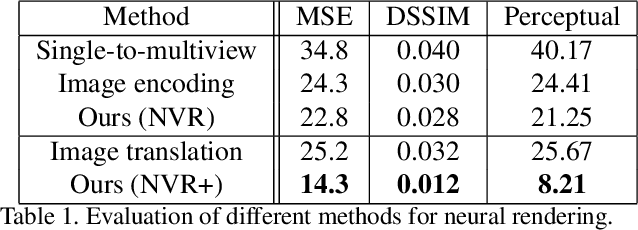
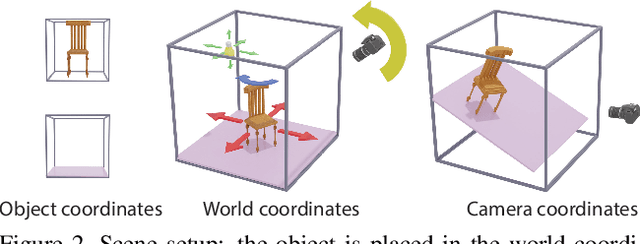

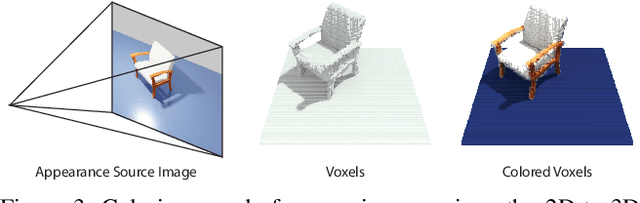
We present a neural rendering framework that maps a voxelized scene into a high quality image. Highly-textured objects and scene element interactions are realistically rendered by our method, despite having a rough representation as an input. Moreover, our approach allows controllable rendering: geometric and appearance modifications in the input are accurately propagated to the output. The user can move, rotate and scale an object, change its appearance and texture or modify the position of the light and all these edits are represented in the final rendering. We demonstrate the effectiveness of our approach by rendering scenes with varying appearance, from single color per object to complex, high-frequency textures. We show that our rerendering network can generate very detailed images that represent precisely the appearance of the input scene. Our experiments illustrate that our approach achieves more accurate image synthesis results compared to alternatives and can also handle low voxel grid resolutions. Finally, we show how our neural rendering framework can capture and faithfully render objects from real images and from a diverse set of classes.
Connecting Vision and Language with Localized Narratives
Dec 06, 2019

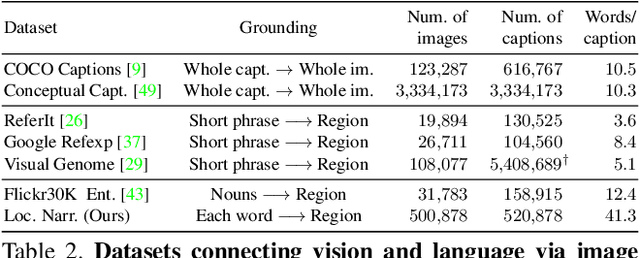
We propose Localized Narratives, an efficient way to collect image captions with dense visual grounding. We ask annotators to describe an image with their voice while simultaneously hovering their mouse over the region they are describing. Since the voice and the mouse pointer are synchronized, we can localize every single word in the description. This dense visual grounding takes the form of a mouse trace segment per word and is unique to our data. We annotate 500k images with Localized Narratives: the whole COCO dataset and 380k images of the Open Images dataset. We provide an extensive analysis of these annotations, which we will release early 2020. Moreover, we demonstrate the utility of our data on two applications which benefit from our mouse trace: controlled image captioning and image generation.
Training Object Detectors from Few Weakly-Labeled and Many Unlabeled Images
Dec 01, 2019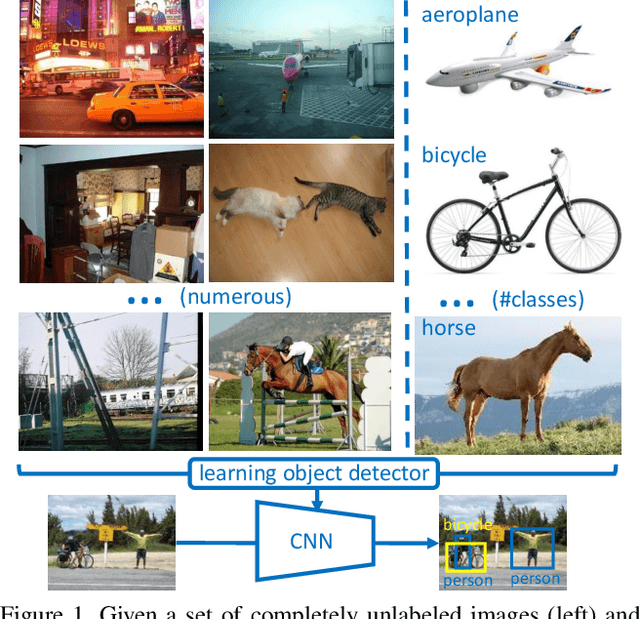


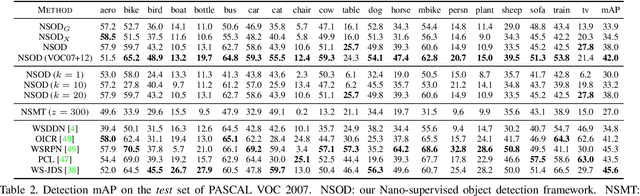
Weakly-supervised object detection attempts to limit the amount of supervision by dispensing the need for bounding boxes, but still assumes image-level labels on the entire training set are available. In this work, we study the problem of training an object detector from one or few clean images with image-level labels and a larger set of completely unlabeled images. This is an extreme case of semi-supervised learning where the labeled data are not enough to bootstrap the learning of a classifier or detector. Our solution is to use a standard weakly-supervised pipeline to train a student model from image-level pseudo-labels generated on the unlabeled set by a teacher model, bootstrapped by region-level similarities to clean labeled images. By using the recent pipeline of PCL and more unlabeled images, we achieve performance competitive or superior to many state of the art weakly-supervised detection solutions.