 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSneakPeek: Future-Guided Instructional Streaming Video Generation
Dec 15, 2025Instructional video generation is an emerging task that aims to synthesize coherent demonstrations of procedural activities from textual descriptions. Such capability has broad implications for content creation, education, and human-AI interaction, yet existing video diffusion models struggle to maintain temporal consistency and controllability across long sequences of multiple action steps. We introduce a pipeline for future-driven streaming instructional video generation, dubbed SneakPeek, a diffusion-based autoregressive framework designed to generate precise, stepwise instructional videos conditioned on an initial image and structured textual prompts. Our approach introduces three key innovations to enhance consistency and controllability: (1) predictive causal adaptation, where a causal model learns to perform next-frame prediction and anticipate future keyframes; (2) future-guided self-forcing with a dual-region KV caching scheme to address the exposure bias issue at inference time; (3) multi-prompt conditioning, which provides fine-grained and procedural control over multi-step instructions. Together, these components mitigate temporal drift, preserve motion consistency, and enable interactive video generation where future prompt updates dynamically influence ongoing streaming video generation. Experimental results demonstrate that our method produces temporally coherent and semantically faithful instructional videos that accurately follow complex, multi-step task descriptions.
CamCtrl3D: Single-Image Scene Exploration with Precise 3D Camera Control
Jan 10, 2025



We propose a method for generating fly-through videos of a scene, from a single image and a given camera trajectory. We build upon an image-to-video latent diffusion model. We condition its UNet denoiser on the camera trajectory, using four techniques. (1) We condition the UNet's temporal blocks on raw camera extrinsics, similar to MotionCtrl. (2) We use images containing camera rays and directions, similar to CameraCtrl. (3) We reproject the initial image to subsequent frames and use the resulting video as a condition. (4) We use 2D<=>3D transformers to introduce a global 3D representation, which implicitly conditions on the camera poses. We combine all conditions in a ContolNet-style architecture. We then propose a metric that evaluates overall video quality and the ability to preserve details with view changes, which we use to analyze the trade-offs of individual and combined conditions. Finally, we identify an optimal combination of conditions. We calibrate camera positions in our datasets for scale consistency across scenes, and we train our scene exploration model, CamCtrl3D, demonstrating state-of-theart results.
Estimating Generic 3D Room Structures from 2D Annotations
Jun 15, 2023



Indoor rooms are among the most common use cases in 3D scene understanding. Current state-of-the-art methods for this task are driven by large annotated datasets. Room layouts are especially important, consisting of structural elements in 3D, such as wall, floor, and ceiling. However, they are difficult to annotate, especially on pure RGB video. We propose a novel method to produce generic 3D room layouts just from 2D segmentation masks, which are easy to annotate for humans. Based on these 2D annotations, we automatically reconstruct 3D plane equations for the structural elements and their spatial extent in the scene, and connect adjacent elements at the appropriate contact edges. We annotate and publicly release 2266 3D room layouts on the RealEstate10k dataset, containing YouTube videos. We demonstrate the high quality of these 3D layouts annotations with extensive experiments.
NAVI: Category-Agnostic Image Collections with High-Quality 3D Shape and Pose Annotations
Jun 15, 2023



Recent advances in neural reconstruction enable high-quality 3D object reconstruction from casually captured image collections. Current techniques mostly analyze their progress on relatively simple image collections where Structure-from-Motion (SfM) techniques can provide ground-truth (GT) camera poses. We note that SfM techniques tend to fail on in-the-wild image collections such as image search results with varying backgrounds and illuminations. To enable systematic research progress on 3D reconstruction from casual image captures, we propose NAVI: a new dataset of category-agnostic image collections of objects with high-quality 3D scans along with per-image 2D-3D alignments providing near-perfect GT camera parameters. These 2D-3D alignments allow us to extract accurate derivative annotations such as dense pixel correspondences, depth and segmentation maps. We demonstrate the use of NAVI image collections on different problem settings and show that NAVI enables more thorough evaluations that were not possible with existing datasets. We believe NAVI is beneficial for systematic research progress on 3D reconstruction and correspondence estimation. Project page: https://navidataset.github.io
CAD-Estate: Large-scale CAD Model Annotation in RGB Videos
Jun 15, 2023



We propose a method for annotating videos of complex multi-object scenes with a globally-consistent 3D representation of the objects. We annotate each object with a CAD model from a database, and place it in the 3D coordinate frame of the scene with a 9-DoF pose transformation. Our method is semi-automatic and works on commonly-available RGB videos, without requiring a depth sensor. Many steps are performed automatically, and the tasks performed by humans are simple, well-specified, and require only limited reasoning in 3D. This makes them feasible for crowd-sourcing and has allowed us to construct a large-scale dataset by annotating real-estate videos from YouTube. Our dataset CAD-Estate offers 108K instances of 12K unique CAD models placed in the 3D representations of 21K videos. In comparison to Scan2CAD, the largest existing dataset with CAD model annotations on real scenes, CAD-Estate has 8x more instances and 4x more unique CAD models. We showcase the benefits of pre-training a Mask2CAD model on CAD-Estate for the task of automatic 3D object reconstruction and pose estimation, demonstrating that it leads to improvements on the popular Scan2CAD benchmark. We will release the data by mid July 2023.
RayTran: 3D pose estimation and shape reconstruction of multiple objects from videos with ray-traced transformers
Mar 24, 2022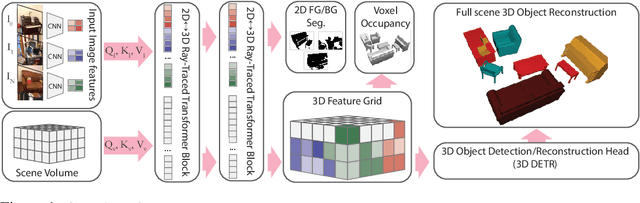
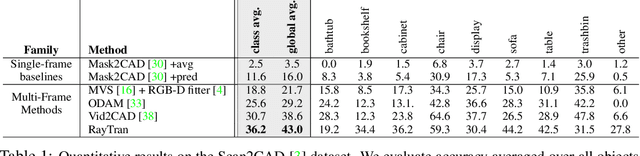
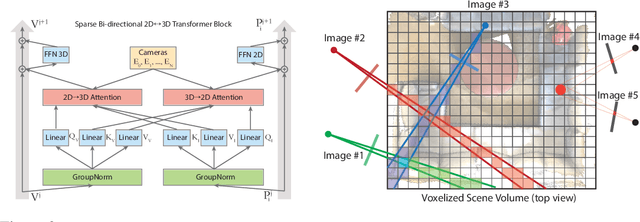
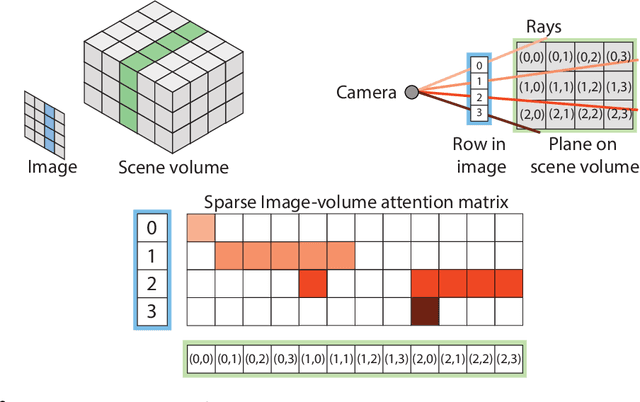
We propose a transformer-based neural network architecture for multi-object 3D reconstruction from RGB videos. It relies on two alternative ways to represent its knowledge: as a global 3D grid of features and an array of view-specific 2D grids. We progressively exchange information between the two with a dedicated bidirectional attention mechanism. We exploit knowledge about the image formation process to significantly sparsify the attention weight matrix, making our architecture feasible on current hardware, both in terms of memory and computation. We attach a DETR-style head on top of the 3D feature grid in order to detect the objects in the scene and to predict their 3D pose and 3D shape. Compared to previous methods, our architecture is single stage, end-to-end trainable, and it can reason holistically about a scene from multiple video frames without needing a brittle tracking step. We evaluate our method on the challenging Scan2CAD dataset, where we outperform (1) recent state-of-the-art methods for 3D object pose estimation from RGB videos; and (2) a strong alternative method combining Multi-view Stereo with RGB-D CAD alignment. We plan to release our source code.
Vid2CAD: CAD Model Alignment using Multi-View Constraints from Videos
Dec 08, 2020
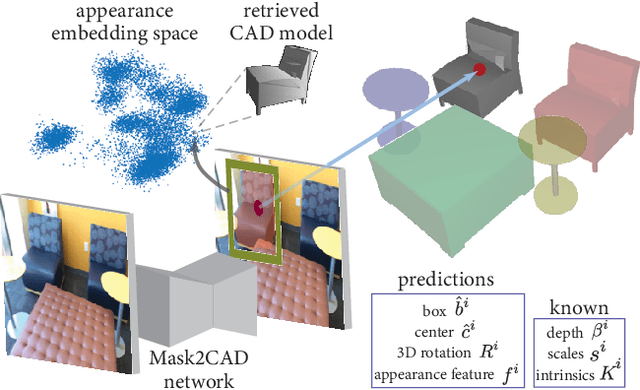
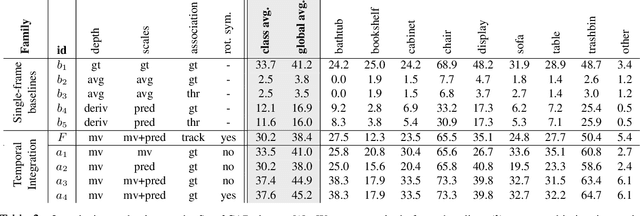

We address the task of aligning CAD models to a video sequence of a complex scene containing multiple objects. Our method is able to process arbitrary videos and fully automatically recover the 9 DoF pose for each object appearing in it, thus aligning them in a common 3D coordinate frame. The core idea of our method is to integrate neural network predictions from individual frames with a temporally global, multi-view constraint optimization formulation. This integration process resolves the scale and depth ambiguities in the per-frame predictions, and generally improves the estimate of all pose parameters. By leveraging multi-view constraints, our method also resolves occlusions and handles objects that are out of view in individual frames, thus reconstructing all objects into a single globally consistent CAD representation of the scene. In comparison to the state-of-the-art single-frame method Mask2CAD that we build on, we achieve substantial improvements on Scan2CAD (from 11.6% to 30.2% class average accuracy).
Efficient Full Image Interactive Segmentation by Leveraging Within-image Appearance Similarity
Jul 16, 2020
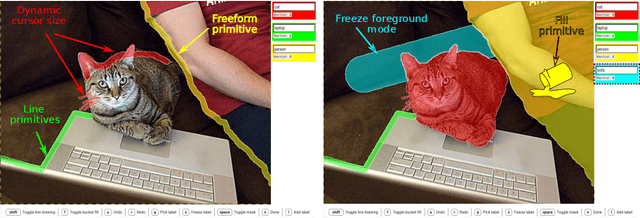

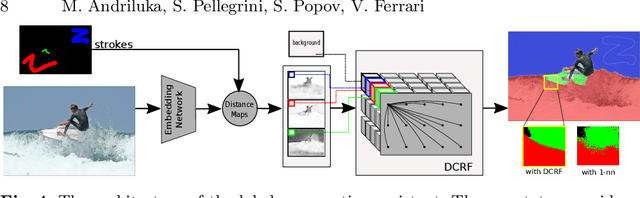
We propose a new approach to interactive full-image semantic segmentation which enables quickly collecting training data for new datasets with previously unseen semantic classes (A demo is available at https://youtu.be/yUk8D5gEX-o). We leverage a key observation: propagation from labeled to unlabeled pixels does not necessarily require class-specific knowledge, but can be done purely based on appearance similarity within an image. We build on this observation and propose an approach capable of jointly propagating pixel labels from multiple classes without having explicit class-specific appearance models. To enable long-range propagation, our approach first globally measures appearance similarity between labeled and unlabeled pixels across the entire image. Then it locally integrates per-pixel measurements which improves the accuracy at boundaries and removes noisy label switches in homogeneous regions. We also design an efficient manual annotation interface that extends the traditional polygon drawing tools with a suite of additional convenient features (and add automatic propagation to it). Experiments with human annotators on the COCO Panoptic Challenge dataset show that the combination of our better manual interface and our novel automatic propagation mechanism leads to reducing annotation time by more than factor of 2x compared to polygon drawing. We also test our method on the ADE-20k and Fashionista datasets without making any dataset-specific adaptation nor retraining our model, demonstrating that it can generalize to new datasets and visual classes.
CoReNet: Coherent 3D scene reconstruction from a single RGB image
Apr 27, 2020
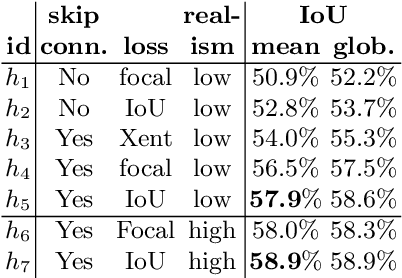
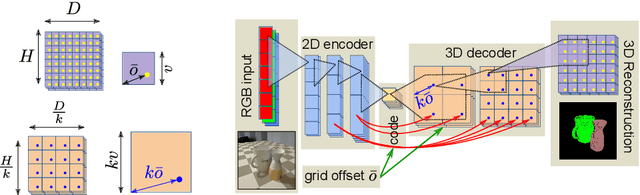
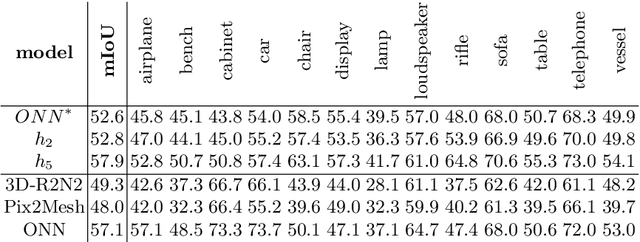
Advances in deep learning techniques have allowed recent work to reconstruct the shape of a single object given only one RBG image as input. Building on common encoder-decoder architectures for this task, we propose three extensions: (1) ray-traced skip connections that propagate local 2D information to the output 3D volume in a physically correct manner; (2) a hybrid 3D volume representation that enables building translation equivariant models, while at the same time encoding fine object details without an excessive memory footprint; (3) a reconstruction loss tailored to capture overall object geometry. Furthermore, we adapt our model to address the harder task of reconstructing multiple objects from a single image. We reconstruct all objects jointly in one pass, producing a coherent reconstruction, where all objects live in a single consistent 3D coordinate frame relative to the camera and they do not intersect in 3D space. We also handle occlusions and resolve them by hallucinating the missing object parts in the 3D volume. We validate the impact of our contributions experimentally both on synthetic data from ShapeNet as well as real images from Pix3D. Our method outperforms the state-of-the-art single-object methods on both datasets. Finally, we evaluate performance quantitatively on multiple object reconstruction with synthetic scenes assembled from ShapeNet objects.
C-Flow: Conditional Generative Flow Models for Images and 3D Point Clouds
Dec 15, 2019
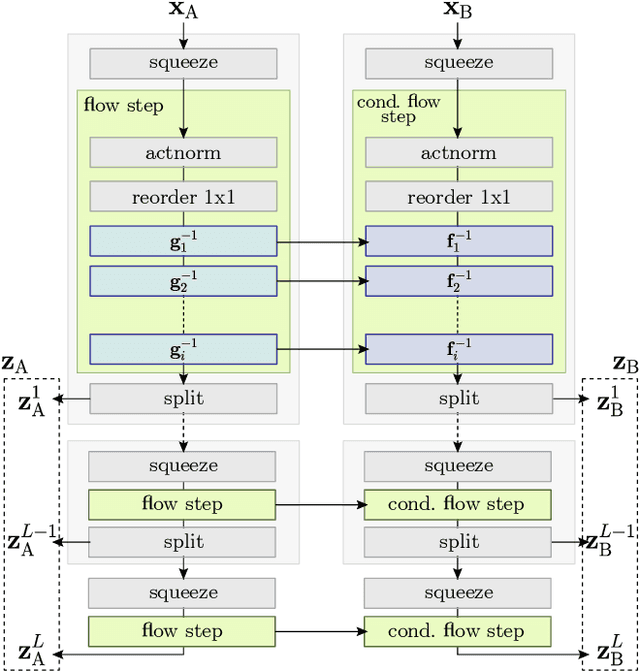
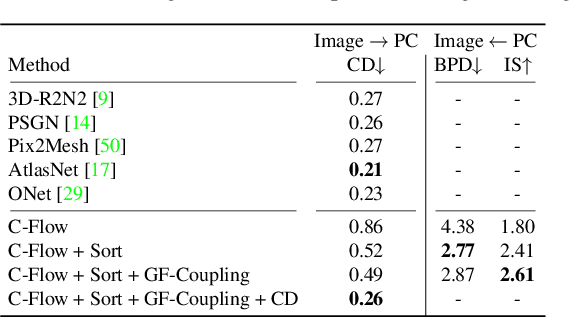
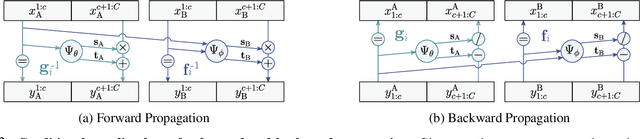
Flow-based generative models have highly desirable properties like exact log-likelihood evaluation and exact latent-variable inference, however they are still in their infancy and have not received as much attention as alternative generative models. In this paper, we introduce C-Flow, a novel conditioning scheme that brings normalizing flows to an entirely new scenario with great possibilities for multi-modal data modeling. C-Flow is based on a parallel sequence of invertible mappings in which a source flow guides the target flow at every step, enabling fine-grained control over the generation process. We also devise a new strategy to model unordered 3D point clouds that, in combination with the conditioning scheme, makes it possible to address 3D reconstruction from a single image and its inverse problem of rendering an image given a point cloud. We demonstrate our conditioning method to be very adaptable, being also applicable to image manipulation, style transfer and multi-modal image-to-image mapping in a diversity of domains, including RGB images, segmentation maps, and edge masks.