 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to restore images degraded by atmospheric turbulence using uncertainty
Jul 07, 2022
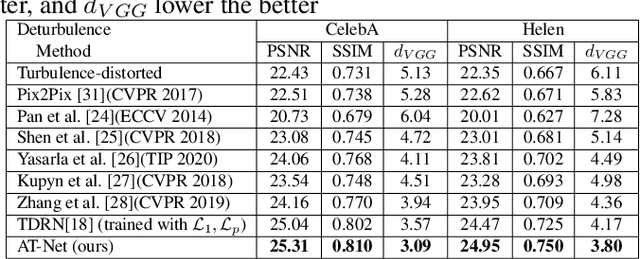
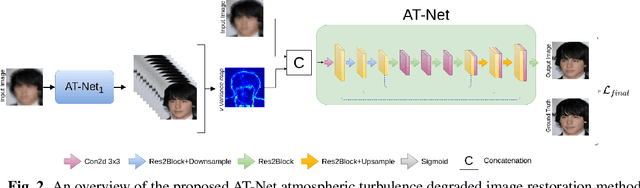
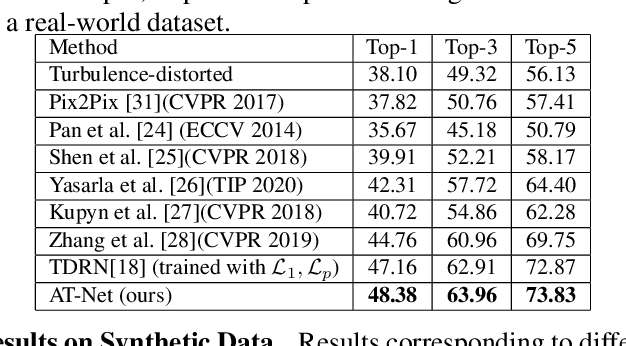
Atmospheric turbulence can significantly degrade the quality of images acquired by long-range imaging systems by causing spatially and temporally random fluctuations in the index of refraction of the atmosphere. Variations in the refractive index causes the captured images to be geometrically distorted and blurry. Hence, it is important to compensate for the visual degradation in images caused by atmospheric turbulence. In this paper, we propose a deep learning-based approach for restring a single image degraded by atmospheric turbulence. We make use of the epistemic uncertainty based on Monte Carlo dropouts to capture regions in the image where the network is having hard time restoring. The estimated uncertainty maps are then used to guide the network to obtain the restored image. Extensive experiments are conducted on synthetic and real images to show the significance of the proposed work. Code is available at : https://github.com/rajeevyasarla/AT-Net
DDPM-CD: Remote Sensing Change Detection using Denoising Diffusion Probabilistic Models
Jun 27, 2022
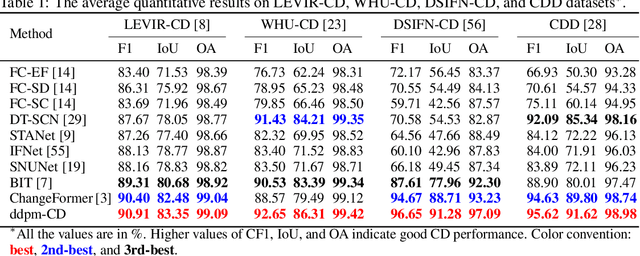

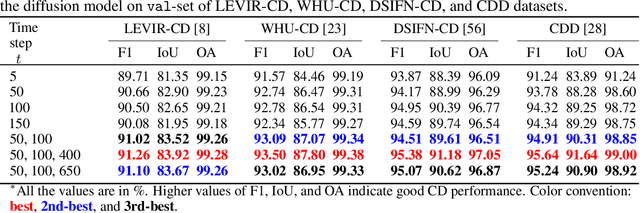
Human civilization has an increasingly powerful influence on the earth system, and earth observations are an invaluable tool for assessing and mitigating the negative impacts. To this end, observing precisely defined changes on Earth's surface is essential, and we propose an effective way to achieve this goal. Notably, our change detection (CD)/ segmentation method proposes a novel way to incorporate the millions of off-the-shelf, unlabeled, remote sensing images available through different earth observation programs into the training process through denoising diffusion probabilistic models. We first leverage the information from these off-the-shelf, uncurated, and unlabeled remote sensing images by using a pre-trained denoising diffusion probabilistic model and then employ the multi-scale feature representations from the diffusion model decoder to train a lightweight CD classifier to detect precise changes. The experiments performed on four publically available CD datasets show that the proposed approach achieves remarkably better results than the state-of-the-art methods in F1, IoU, and overall accuracy. Code and pre-trained models are available at: https://github.com/wgcban/ddpm-cd
SAR Despeckling using a Denoising Diffusion Probabilistic Model
Jun 09, 2022
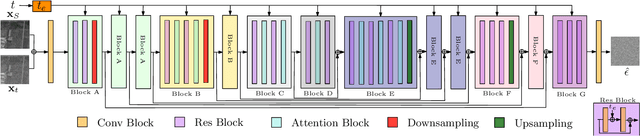


Speckle is a multiplicative noise which affects all coherent imaging modalities including Synthetic Aperture Radar (SAR) images. The presence of speckle degrades the image quality and adversely affects the performance of SAR image understanding applications such as automatic target recognition and change detection. Thus, SAR despeckling is an important problem in remote sensing. In this paper, we introduce SAR-DDPM, a denoising diffusion probabilistic model for SAR despeckling. The proposed method comprises of a Markov chain that transforms clean images to white Gaussian noise by repeatedly adding random noise. The despeckled image is recovered by a reverse process which iteratively predicts the added noise using a noise predictor which is conditioned on the speckled image. In addition, we propose a new inference strategy based on cycle spinning to improve the despeckling performance. Our experiments on both synthetic and real SAR images demonstrate that the proposed method achieves significant improvements in both quantitative and qualitative results over the state-of-the-art despeckling methods.
SAR Despeckling Using Overcomplete Convolutional Networks
May 31, 2022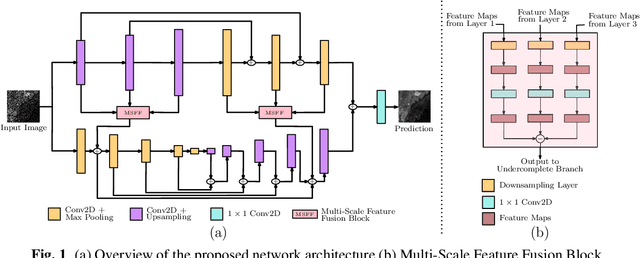
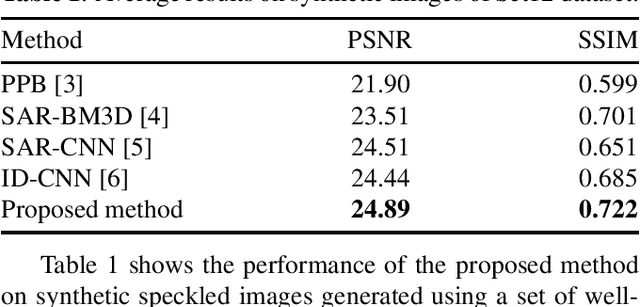


Synthetic Aperture Radar (SAR) despeckling is an important problem in remote sensing as speckle degrades SAR images, affecting downstream tasks like detection and segmentation. Recent studies show that convolutional neural networks(CNNs) outperform classical despeckling methods. Traditional CNNs try to increase the receptive field size as the network goes deeper, thus extracting global features. However,speckle is relatively small, and increasing receptive field does not help in extracting speckle features. This study employs an overcomplete CNN architecture to focus on learning low-level features by restricting the receptive field. The proposed network consists of an overcomplete branch to focus on the local structures and an undercomplete branch that focuses on the global structures. We show that the proposed network improves despeckling performance compared to recent despeckling methods on synthetic and real SAR images.
On Trace of PGD-Like Adversarial Attacks
May 19, 2022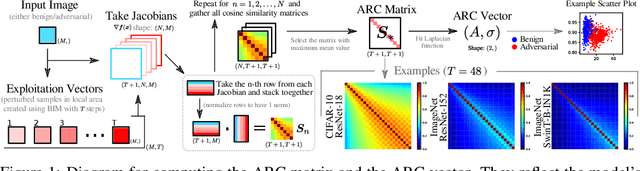
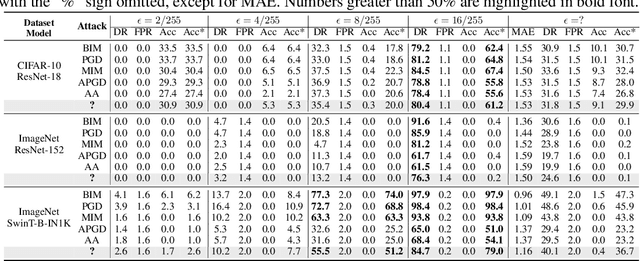
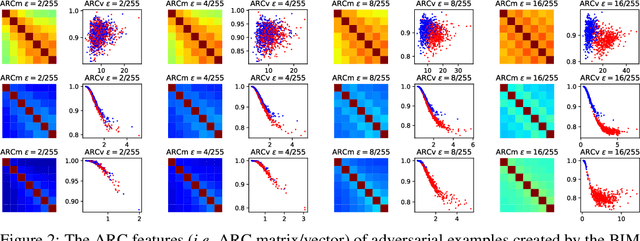
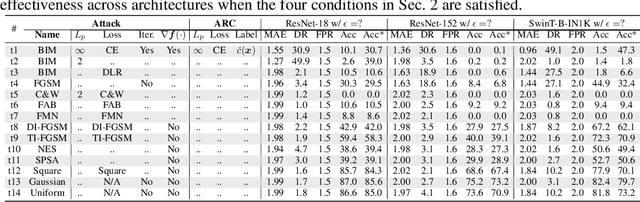
Adversarial attacks pose safety and security concerns for deep learning applications. Yet largely imperceptible, a strong PGD-like attack may leave strong trace in the adversarial example. Since attack triggers the local linearity of a network, we speculate network behaves in different extents of linearity for benign examples and adversarial examples. Thus, we construct Adversarial Response Characteristics (ARC) features to reflect the model's gradient consistency around the input to indicate the extent of linearity. Under certain conditions, it shows a gradually varying pattern from benign example to adversarial example, as the later leads to Sequel Attack Effect (SAE). ARC feature can be used for informed attack detection (perturbation magnitude is known) with binary classifier, or uninformed attack detection (perturbation magnitude is unknown) with ordinal regression. Due to the uniqueness of SAE to PGD-like attacks, ARC is also capable of inferring other attack details such as loss function, or the ground-truth label as a post-processing defense. Qualitative and quantitative evaluations manifest the effectiveness of ARC feature on CIFAR-10 w/ ResNet-18 and ImageNet w/ ResNet-152 and SwinT-B-IN1K with considerable generalization among PGD-like attacks despite domain shift. Our method is intuitive, light-weighted, non-intrusive, and data-undemanding.
Deep-learning-enabled Brain Hemodynamic Mapping Using Resting-state fMRI
Apr 25, 2022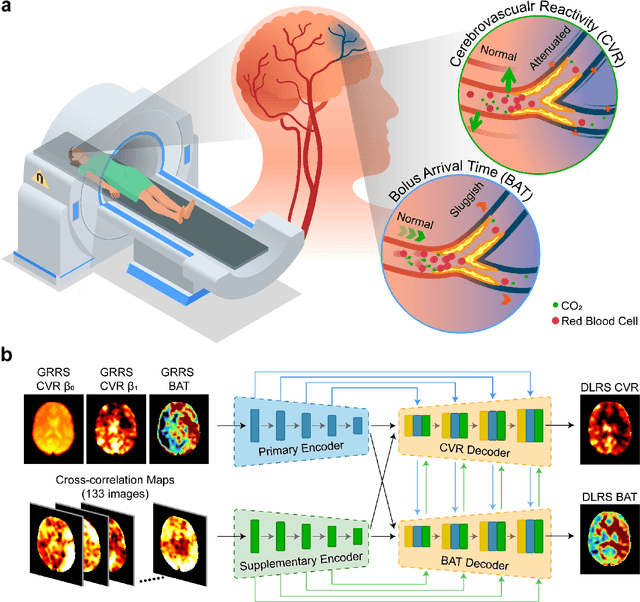
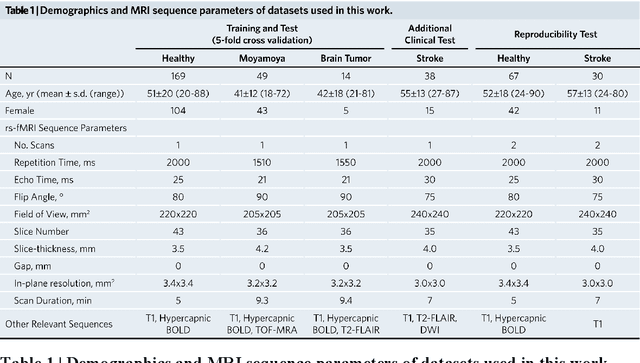
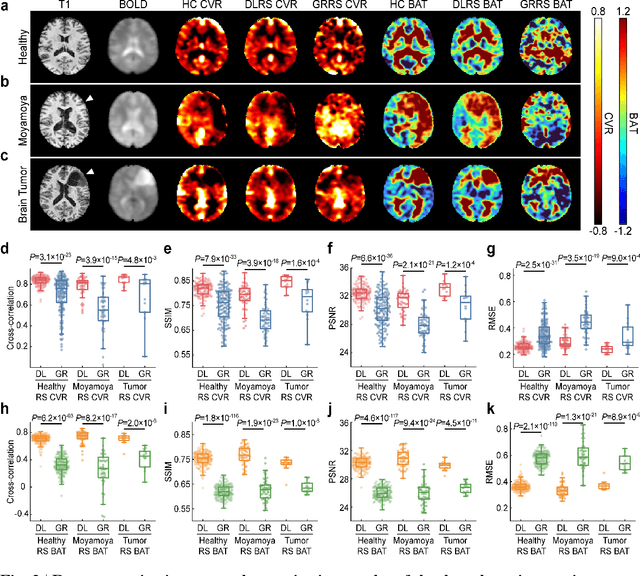
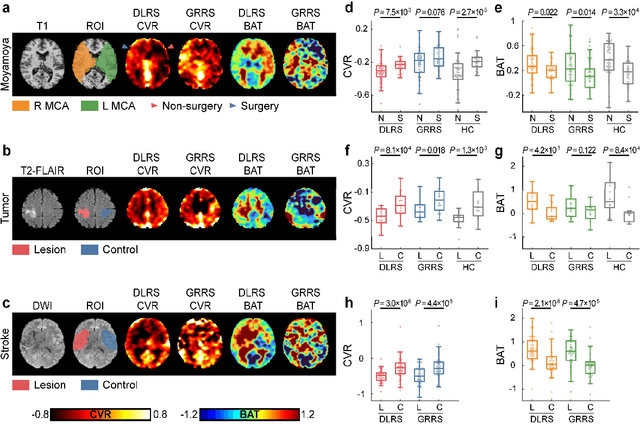
Cerebrovascular disease is a leading cause of death globally. Prevention and early intervention are known to be the most effective forms of its management. Non-invasive imaging methods hold great promises for early stratification, but at present lack the sensitivity for personalized prognosis. Resting-state functional magnetic resonance imaging (rs-fMRI), a powerful tool previously used for mapping neural activity, is available in most hospitals. Here we show that rs-fMRI can be used to map cerebral hemodynamic function and delineate impairment. By exploiting time variations in breathing pattern during rs-fMRI, deep learning enables reproducible mapping of cerebrovascular reactivity (CVR) and bolus arrive time (BAT) of the human brain using resting-state CO2 fluctuations as a natural 'contrast media'. The deep-learning network was trained with CVR and BAT maps obtained with a reference method of CO2-inhalation MRI, which included data from young and older healthy subjects and patients with Moyamoya disease and brain tumors. We demonstrate the performance of deep-learning cerebrovascular mapping in the detection of vascular abnormalities, evaluation of revascularization effects, and vascular alterations in normal aging. In addition, cerebrovascular maps obtained with the proposed method exhibited excellent reproducibility in both healthy volunteers and stroke patients. Deep-learning resting-state vascular imaging has the potential to become a useful tool in clinical cerebrovascular imaging.
Unsupervised Restoration of Weather-affected Images using Deep Gaussian Process-based CycleGAN
Apr 23, 2022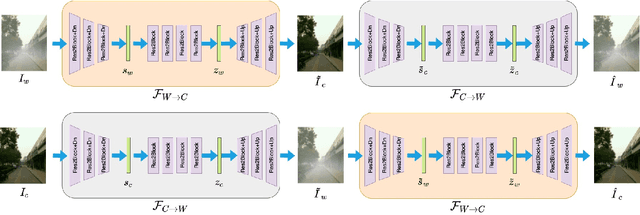



Existing approaches for restoring weather-degraded images follow a fully-supervised paradigm and they require paired data for training. However, collecting paired data for weather degradations is extremely challenging, and existing methods end up training on synthetic data. To overcome this issue, we describe an approach for supervising deep networks that are based on CycleGAN, thereby enabling the use of unlabeled real-world data for training. Specifically, we introduce new losses for training CycleGAN that lead to more effective training, resulting in high-quality reconstructions. These new losses are obtained by jointly modeling the latent space embeddings of predicted clean images and original clean images through Deep Gaussian Processes. This enables the CycleGAN architecture to transfer the knowledge from one domain (weather-degraded) to another (clean) more effectively. We demonstrate that the proposed method can be effectively applied to different restoration tasks like de-raining, de-hazing and de-snowing and it outperforms other unsupervised techniques (that leverage weather-based characteristics) by a considerable margin.
Revisiting Consistency Regularization for Semi-supervised Change Detection in Remote Sensing Images
Apr 21, 2022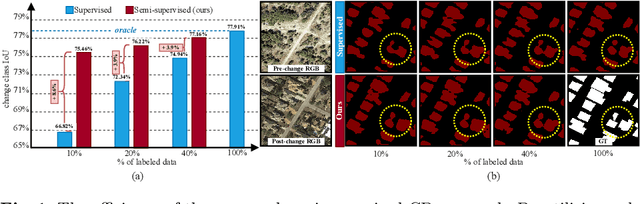
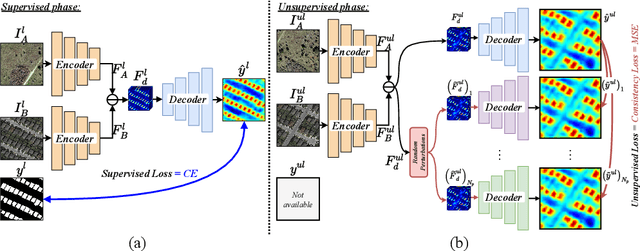
Remote-sensing (RS) Change Detection (CD) aims to detect "changes of interest" from co-registered bi-temporal images. The performance of existing deep supervised CD methods is attributed to the large amounts of annotated data used to train the networks. However, annotating large amounts of remote sensing images is labor-intensive and expensive, particularly with bi-temporal images, as it requires pixel-wise comparisons by a human expert. On the other hand, we often have access to unlimited unlabeled multi-temporal RS imagery thanks to ever-increasing earth observation programs. In this paper, we propose a simple yet effective way to leverage the information from unlabeled bi-temporal images to improve the performance of CD approaches. More specifically, we propose a semi-supervised CD model in which we formulate an unsupervised CD loss in addition to the supervised Cross-Entropy (CE) loss by constraining the output change probability map of a given unlabeled bi-temporal image pair to be consistent under the small random perturbations applied on the deep feature difference map that is obtained by subtracting their latent feature representations. Experiments conducted on two publicly available CD datasets show that the proposed semi-supervised CD method can reach closer to the performance of supervised CD even with access to as little as 10% of the annotated training data. Code available at https://github.com/wgcban/SemiCD
A comparison of different atmospheric turbulence simulation methods for image restoration
Apr 19, 2022
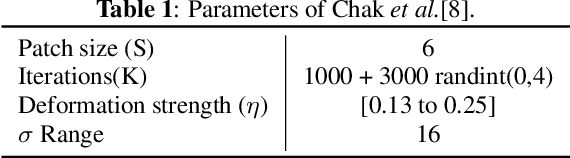
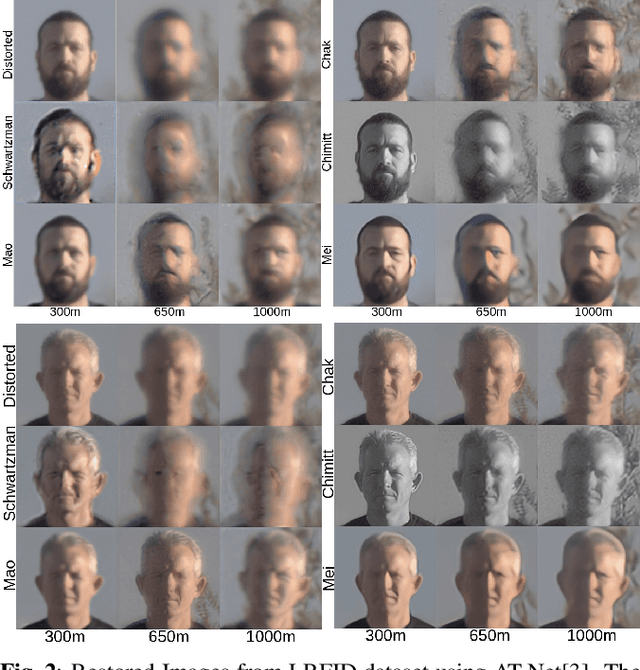
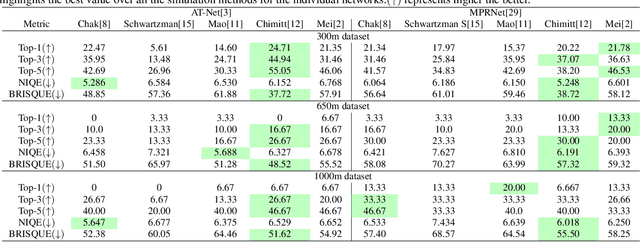
Atmospheric turbulence deteriorates the quality of images captured by long-range imaging systems by introducing blur and geometric distortions to the captured scene. This leads to a drastic drop in performance when computer vision algorithms like object/face recognition and detection are performed on these images. In recent years, various deep learning-based atmospheric turbulence mitigation methods have been proposed in the literature. These methods are often trained using synthetically generated images and tested on real-world images. Hence, the performance of these restoration methods depends on the type of simulation used for training the network. In this paper, we systematically evaluate the effectiveness of various turbulence simulation methods on image restoration. In particular, we evaluate the performance of two state-or-the-art restoration networks using six simulations method on a real-world LRFID dataset consisting of face images degraded by turbulence. This paper will provide guidance to the researchers and practitioners working in this field to choose the suitable data generation models for training deep models for turbulence mitigation. The implementation codes for the simulation methods, source codes for the networks, and the pre-trained models will be publicly made available.
Shape-guided Object Inpainting
Apr 16, 2022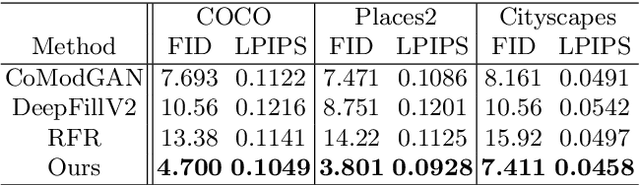


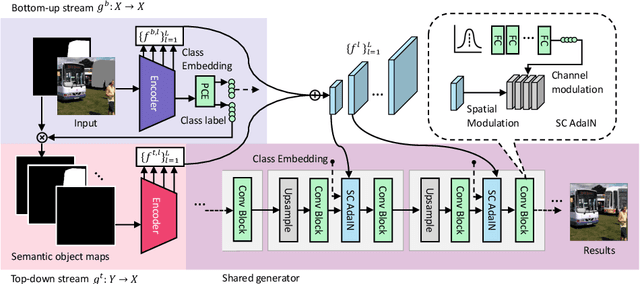
Previous works on image inpainting mainly focus on inpainting background or partially missing objects, while the problem of inpainting an entire missing object remains unexplored. This work studies a new image inpainting task, i.e. shape-guided object inpainting. Given an incomplete input image, the goal is to fill in the hole by generating an object based on the context and implicit guidance given by the hole shape. Since previous methods for image inpainting are mainly designed for background inpainting, they are not suitable for this task. Therefore, we propose a new data preparation method and a novel Contextual Object Generator (CogNet) for the object inpainting task. On the data side, we incorporate object priors into training data by using object instances as holes. The CogNet has a two-stream architecture that combines the standard bottom-up image completion process with a top-down object generation process. A predictive class embedding module bridges the two streams by predicting the class of the missing object from the bottom-up features, from which a semantic object map is derived as the input of the top-down stream. Experiments demonstrate that the proposed method can generate realistic objects that fit the context in terms of both visual appearance and semantic meanings. Code can be found at the project page \url{https://zengxianyu.github.io/objpaint}