 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Monocular Depth and Ego-motion Learning with Structure and Semantics
Jun 12, 2019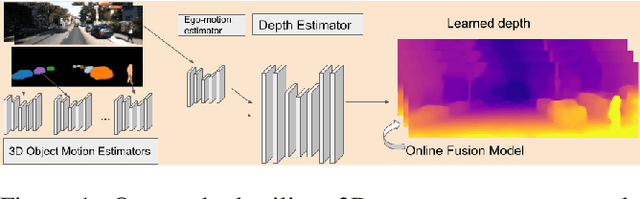
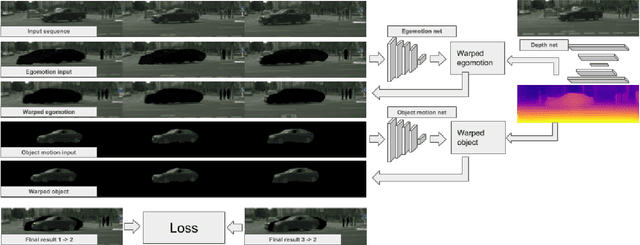

We present an approach which takes advantage of both structure and semantics for unsupervised monocular learning of depth and ego-motion. More specifically, we model the motion of individual objects and learn their 3D motion vector jointly with depth and ego-motion. We obtain more accurate results, especially for challenging dynamic scenes not addressed by previous approaches. This is an extended version of Casser et al. [AAAI'19]. Code and models have been open sourced at https://sites.google.com/corp/view/struct2depth.
Learning a Controller Fusion Network by Online Trajectory Filtering for Vision-based UAV Racing
Apr 18, 2019
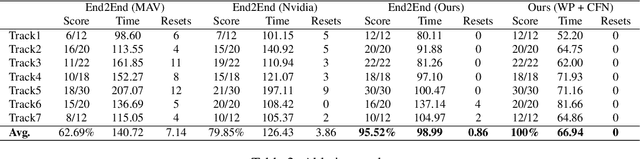

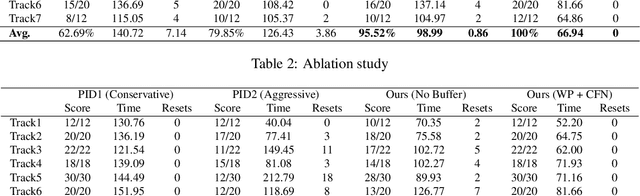
Autonomous UAV racing has recently emerged as an interesting research problem. The dream is to beat humans in this new fast-paced sport. A common approach is to learn an end-to-end policy that directly predicts controls from raw images by imitating an expert. However, such a policy is limited by the expert it imitates and scaling to other environments and vehicle dynamics is difficult. One approach to overcome the drawbacks of an end-to-end policy is to train a network only on the perception task and handle control with a PID or MPC controller. However, a single controller must be extensively tuned and cannot usually cover the whole state space. In this paper, we propose learning an optimized controller using a DNN that fuses multiple controllers. The network learns a robust controller with online trajectory filtering, which suppresses noisy trajectories and imperfections of individual controllers. The result is a network that is able to learn a good fusion of filtered trajectories from different controllers leading to significant improvements in overall performance. We compare our trained network to controllers it has learned from, end-to-end baselines and human pilots in a realistic simulation; our network beats all baselines in extensive experiments and approaches the performance of a professional human pilot. A video summarizing this work is available at https://youtu.be/hGKlE5X9Z5U
Fast Mitochondria Segmentation for Connectomics
Dec 14, 2018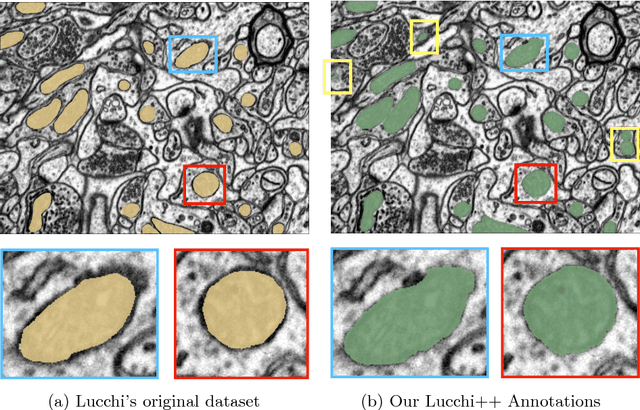

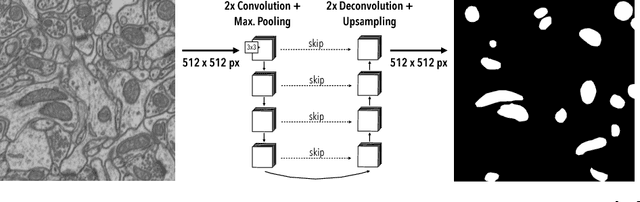
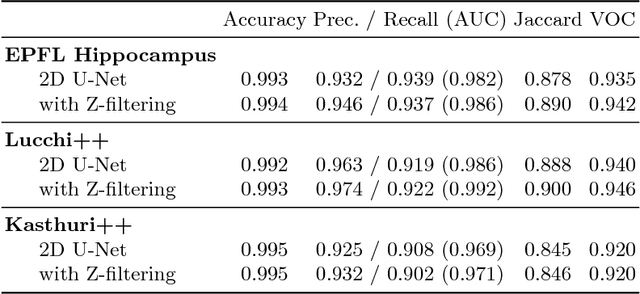
In connectomics, scientists create the wiring diagram of a mammalian brain by identifying synaptic connections between neurons in nano-scale electron microscopy images. This allows for the identification of dysfunctional mitochondria which are linked to a variety of diseases such as autism or bipolar. However, manual analysis is not feasible since connectomics datasets can be petabytes in size. To process such large data, we present a fully automatic mitochondria detector based on a modified U-Net architecture that yields high accuracy and fast processing times. We evaluate our method on multiple real-world connectomics datasets, including an improved version of the EPFL Hippocampus mitochondria detection benchmark. Our results show a Jaccard index of up to 0.90 with inference speeds lower than 16ms for a 512x512 image tile. This speed is faster than the acquisition time of modern electron microscopes, allowing mitochondria detection in real-time. Compared to previous work, our detector ranks first among real-time methods and third overall. Our data, results, and code are freely available.
OIL: Observational Imitation Learning
Nov 27, 2018
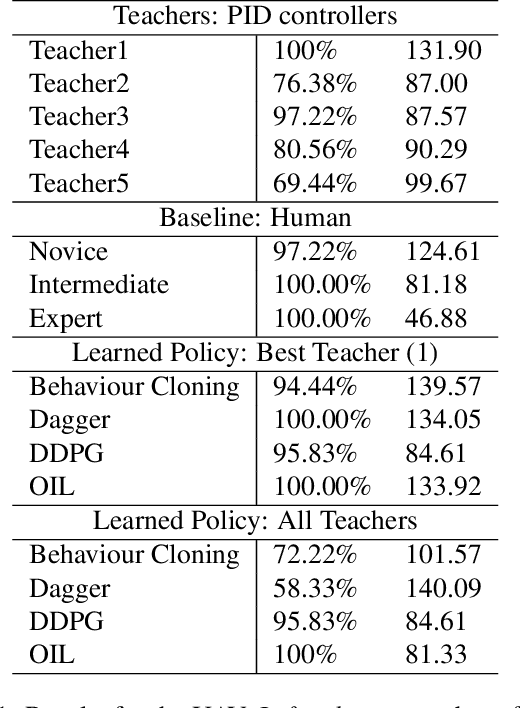

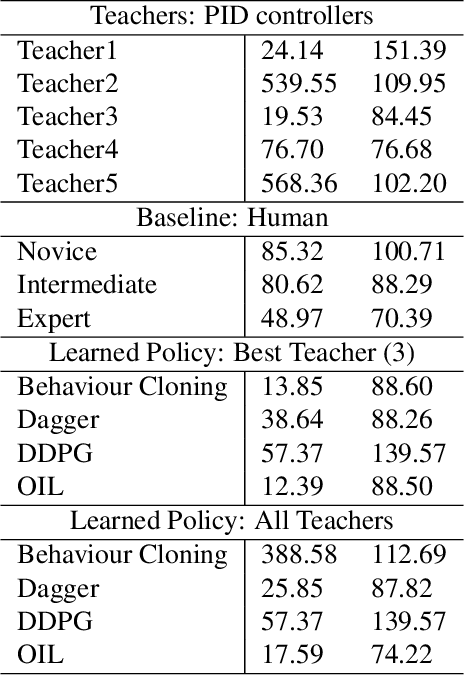
Recent work has explored the problem of autonomous navigation by imitating a teacher and learning an end-to-end policy, which directly predicts controls from raw images. However, these approaches tend to be sensitive to mistakes by the teacher and do not scale well to other environments or vehicles. To this end, we propose Observational Imitation Learning (OIL), a novel imitation learning variant that supports online training and automatic selection of optimal behavior by observing multiple imperfect teachers. We apply our proposed methodology to the challenging problems of autonomous driving and UAV racing. For both tasks, we utilize the Sim4CV simulator that enables the generation of large amounts of synthetic training data and also allows for online learning and evaluation. We train a perception network to predict waypoints from raw image data and use OIL to train another network to predict controls from these waypoints. Extensive experiments demonstrate that our trained network outperforms its teachers, conventional imitation learning (IL) and reinforcement learning (RL) baselines and even humans in simulation. The project website is available at https://sites.google.com/kaust.edu.sa/oil/
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
Nov 15, 2018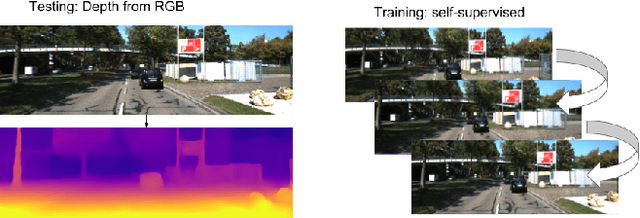
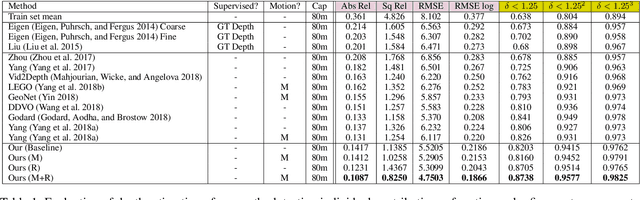
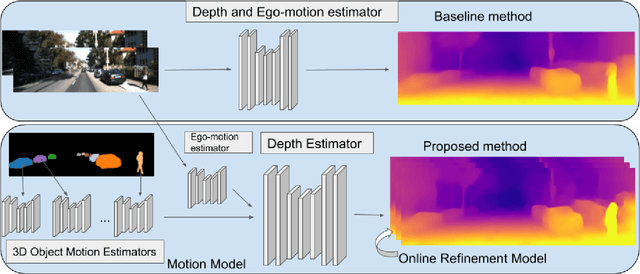

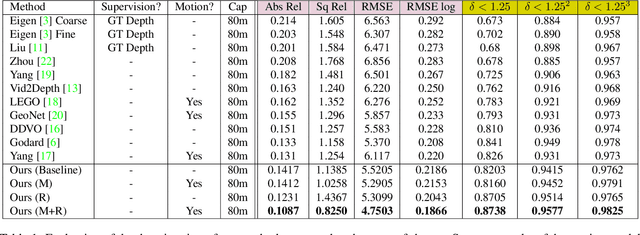
Learning to predict scene depth from RGB inputs is a challenging task both for indoor and outdoor robot navigation. In this work we address unsupervised learning of scene depth and robot ego-motion where supervision is provided by monocular videos, as cameras are the cheapest, least restrictive and most ubiquitous sensor for robotics. Previous work in unsupervised image-to-depth learning has established strong baselines in the domain. We propose a novel approach which produces higher quality results, is able to model moving objects and is shown to transfer across data domains, e.g. from outdoors to indoor scenes. The main idea is to introduce geometric structure in the learning process, by modeling the scene and the individual objects; camera ego-motion and object motions are learned from monocular videos as input. Furthermore an online refinement method is introduced to adapt learning on the fly to unknown domains. The proposed approach outperforms all state-of-the-art approaches, including those that handle motion e.g. through learned flow. Our results are comparable in quality to the ones which used stereo as supervision and significantly improve depth prediction on scenes and datasets which contain a lot of object motion. The approach is of practical relevance, as it allows transfer across environments, by transferring models trained on data collected for robot navigation in urban scenes to indoor navigation settings. The code associated with this paper can be found at https://sites.google.com/view/struct2depth.
Teaching UAVs to Race Using Sim4CV
Mar 24, 2018
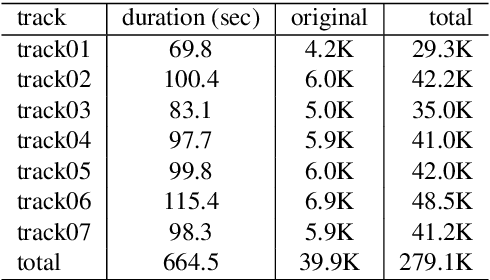
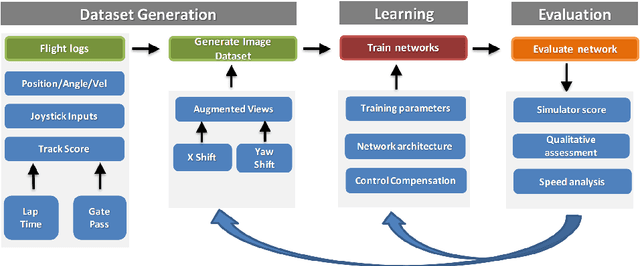

Automating the navigation of unmanned aerial vehicles (UAVs) in diverse scenarios has gained much attention in the recent years. However, teaching UAVs to fly in challenging environments remains an unsolved problem, mainly due to the lack of data for training. In this paper, we develop a photo-realistic simulator that can afford the generation of large amounts of training data (both images rendered from the UAV camera and its controls) to teach a UAV to autonomously race through challenging tracks. We train a deep neural network to predict UAV controls from raw image data for the task of autonomous UAV racing. Training is done through imitation learning enabled by data augmentation to allow for the correction of navigation mistakes. Extensive experiments demonstrate that our trained network (when sufficient data augmentation is used) outperforms state-of-the-art methods and flies more consistently than many human pilots.
Sim4CV: A Photo-Realistic Simulator for Computer Vision Applications
Mar 24, 2018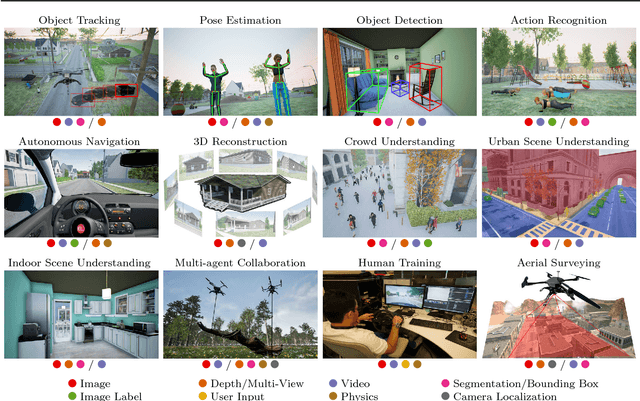

We present a photo-realistic training and evaluation simulator (Sim4CV) with extensive applications across various fields of computer vision. Built on top of the Unreal Engine, the simulator integrates full featured physics based cars, unmanned aerial vehicles (UAVs), and animated human actors in diverse urban and suburban 3D environments. We demonstrate the versatility of the simulator with two case studies: autonomous UAV-based tracking of moving objects and autonomous driving using supervised learning. The simulator fully integrates both several state-of-the-art tracking algorithms with a benchmark evaluation tool and a deep neural network (DNN) architecture for training vehicles to drive autonomously. It generates synthetic photo-realistic datasets with automatic ground truth annotations to easily extend existing real-world datasets and provides extensive synthetic data variety through its ability to reconfigure synthetic worlds on the fly using an automatic world generation tool. The supplementary video can be viewed a https://youtu.be/SqAxzsQ7qUU