 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVahid Partovi Nia
Understanding Neural Network Binarization with Forward and Backward Proximal Quantizers
Feb 27, 2024
In neural network binarization, BinaryConnect (BC) and its variants are considered the standard. These methods apply the sign function in their forward pass and their respective gradients are backpropagated to update the weights. However, the derivative of the sign function is zero whenever defined, which consequently freezes training. Therefore, implementations of BC (e.g., BNN) usually replace the derivative of sign in the backward computation with identity or other approximate gradient alternatives. Although such practice works well empirically, it is largely a heuristic or ''training trick.'' We aim at shedding some light on these training tricks from the optimization perspective. Building from existing theory on ProxConnect (PC, a generalization of BC), we (1) equip PC with different forward-backward quantizers and obtain ProxConnect++ (PC++) that includes existing binarization techniques as special cases; (2) derive a principled way to synthesize forward-backward quantizers with automatic theoretical guarantees; (3) illustrate our theory by proposing an enhanced binarization algorithm BNN++; (4) conduct image classification experiments on CNNs and vision transformers, and empirically verify that BNN++ generally achieves competitive results on binarizing these models.
Mitigating Outlier Activations in Low-Precision Fine-Tuning of Language Models
Dec 15, 2023Low-precision fine-tuning of language models has gained prominence as a cost-effective and energy-efficient approach to deploying large-scale models in various applications. However, this approach is susceptible to the existence of outlier values in activation. The outlier values in the activation can negatively affect the performance of fine-tuning language models in the low-precision regime since they affect the scaling factor and thus make representing smaller values harder. This paper investigates techniques for mitigating outlier activation in low-precision integer fine-tuning of the language models. Our proposed novel approach enables us to represent the outlier activation values in 8-bit integers instead of floating-point (FP16) values. The benefit of using integers for outlier values is that it enables us to use operator tiling to avoid performing 16-bit integer matrix multiplication to address this problem effectively. We provide theoretical analysis and supporting experiments to demonstrate the effectiveness of our approach in improving the robustness and performance of low-precision fine-tuned language models.
Mathematical Challenges in Deep Learning
Mar 24, 2023

Deep models are dominating the artificial intelligence (AI) industry since the ImageNet challenge in 2012. The size of deep models is increasing ever since, which brings new challenges to this field with applications in cell phones, personal computers, autonomous cars, and wireless base stations. Here we list a set of problems, ranging from training, inference, generalization bound, and optimization with some formalism to communicate these challenges with mathematicians, statisticians, and theoretical computer scientists. This is a subjective view of the research questions in deep learning that benefits the tech industry in long run.
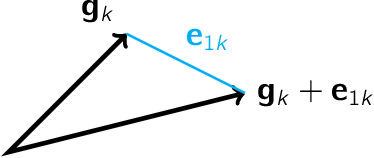
Scaling Deep Networks with the Mesh Adaptive Direct Search algorithm
Jan 17, 2023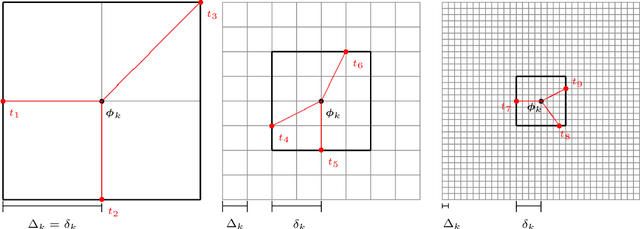
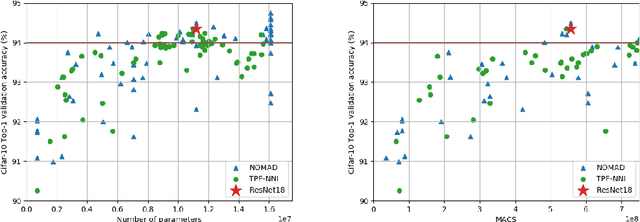
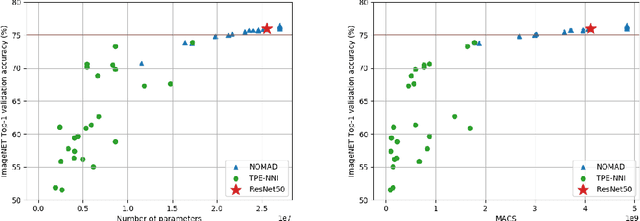
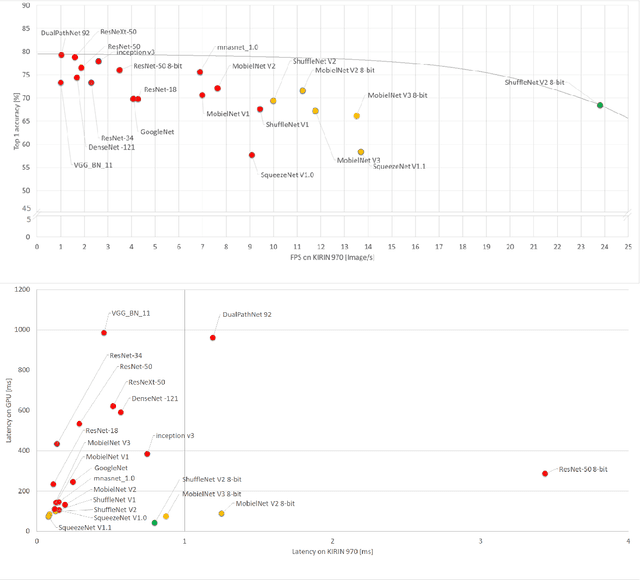
Deep neural networks are getting larger. Their implementation on edge and IoT devices becomes more challenging and moved the community to design lighter versions with similar performance. Standard automatic design tools such as \emph{reinforcement learning} and \emph{evolutionary computing} fundamentally rely on cheap evaluations of an objective function. In the neural network design context, this objective is the accuracy after training, which is expensive and time-consuming to evaluate. We automate the design of a light deep neural network for image classification using the \emph{Mesh Adaptive Direct Search}(MADS) algorithm, a mature derivative-free optimization method that effectively accounts for the expensive blackbox nature of the objective function to explore the design space, even in the presence of constraints.Our tests show competitive compression rates with reduced numbers of trials.
On the Convergence of Stochastic Gradient Descent in Low-precision Number Formats
Jan 09, 2023
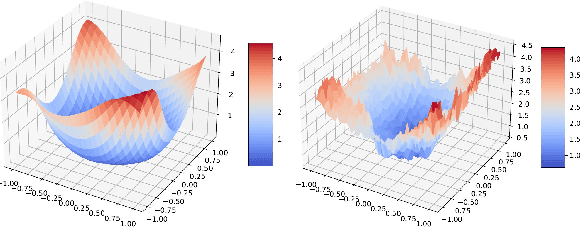
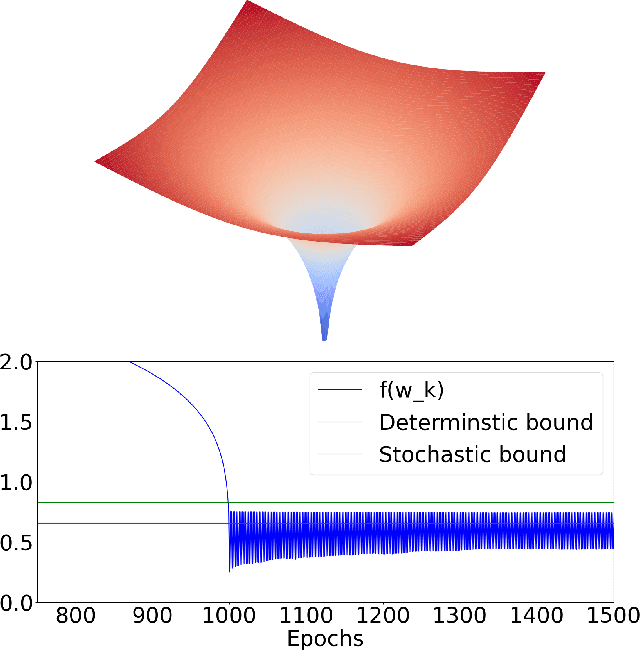
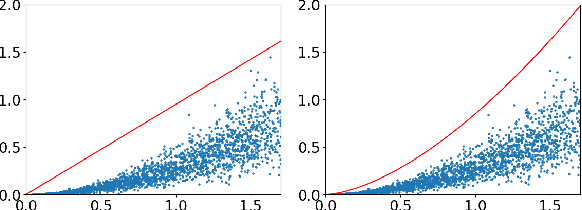
Deep learning models are dominating almost all artificial intelligence tasks such as vision, text, and speech processing. Stochastic Gradient Descent (SGD) is the main tool for training such models, where the computations are usually performed in single-precision floating-point number format. The convergence of single-precision SGD is normally aligned with the theoretical results of real numbers since they exhibit negligible error. However, the numerical error increases when the computations are performed in low-precision number formats. This provides compelling reasons to study the SGD convergence adapted for low-precision computations. We present both deterministic and stochastic analysis of the SGD algorithm, obtaining bounds that show the effect of number format. Such bounds can provide guidelines as to how SGD convergence is affected when constraints render the possibility of performing high-precision computations remote.
EuclidNets: An Alternative Operation for Efficient Inference of Deep Learning Models
Dec 22, 2022
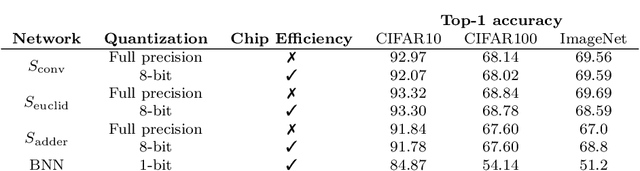

With the advent of deep learning application on edge devices, researchers actively try to optimize their deployments on low-power and restricted memory devices. There are established compression method such as quantization, pruning, and architecture search that leverage commodity hardware. Apart from conventional compression algorithms, one may redesign the operations of deep learning models that lead to more efficient implementation. To this end, we propose EuclidNet, a compression method, designed to be implemented on hardware which replaces multiplication, $xw$, with Euclidean distance $(x-w)^2$. We show that EuclidNet is aligned with matrix multiplication and it can be used as a measure of similarity in case of convolutional layers. Furthermore, we show that under various transformations and noise scenarios, EuclidNet exhibits the same performance compared to the deep learning models designed with multiplication operations.
Training Integer-Only Deep Recurrent Neural Networks
Dec 22, 2022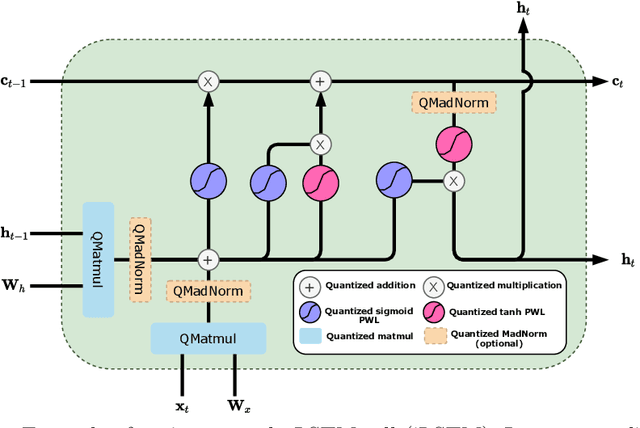

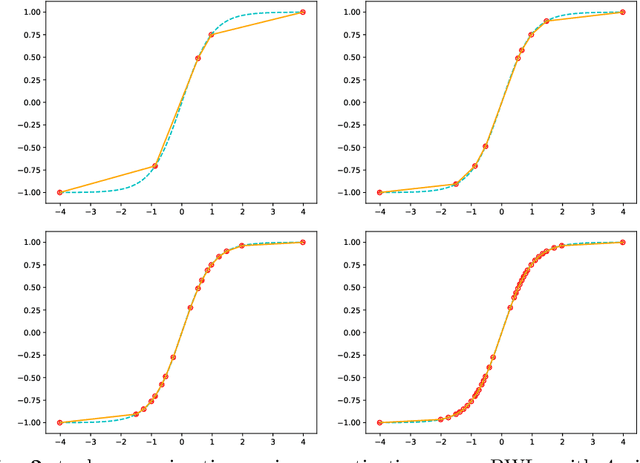

Recurrent neural networks (RNN) are the backbone of many text and speech applications. These architectures are typically made up of several computationally complex components such as; non-linear activation functions, normalization, bi-directional dependence and attention. In order to maintain good accuracy, these components are frequently run using full-precision floating-point computation, making them slow, inefficient and difficult to deploy on edge devices. In addition, the complex nature of these operations makes them challenging to quantize using standard quantization methods without a significant performance drop. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear (PWL) approximation of activation functions, to serve a wide range of state-of-the-art RNNs. The proposed method enables RNN-based language models to run on edge devices with $2\times$ improvement in runtime, and $4\times$ reduction in model size while maintaining similar accuracy as its full-precision counterpart.
KronA: Parameter Efficient Tuning with Kronecker Adapter
Dec 20, 2022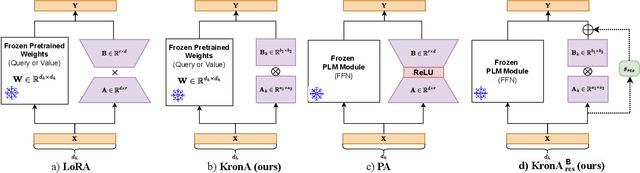
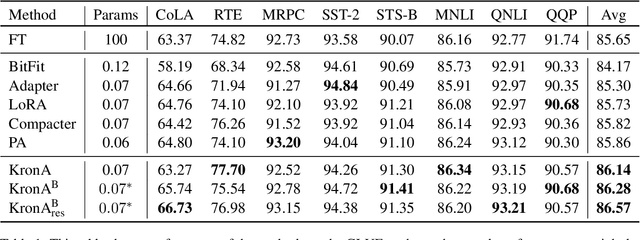

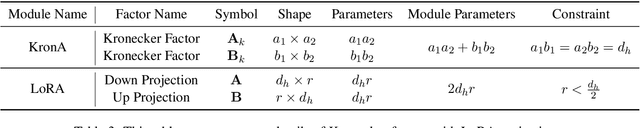
Fine-tuning a Pre-trained Language Model (PLM) on a specific downstream task has been a well-known paradigm in Natural Language Processing. However, with the ever-growing size of PLMs, training the entire model on several downstream tasks becomes very expensive and resource-hungry. Recently, different Parameter Efficient Tuning (PET) techniques are proposed to improve the efficiency of fine-tuning PLMs. One popular category of PET methods is the low-rank adaptation methods which insert learnable truncated SVD modules into the original model either sequentially or in parallel. However, low-rank decomposition suffers from limited representation power. In this work, we address this problem using the Kronecker product instead of the low-rank representation. We introduce KronA, a Kronecker product-based adapter module for efficient fine-tuning of Transformer-based PLMs. We apply the proposed methods for fine-tuning T5 on the GLUE benchmark to show that incorporating the Kronecker-based modules can outperform state-of-the-art PET methods.
SeKron: A Decomposition Method Supporting Many Factorization Structures
Oct 12, 2022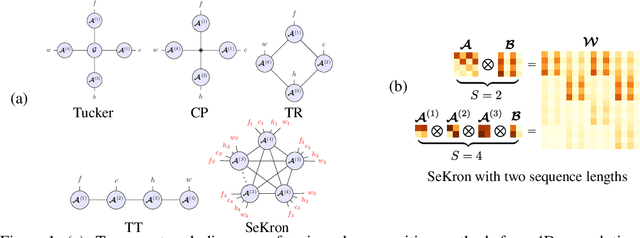
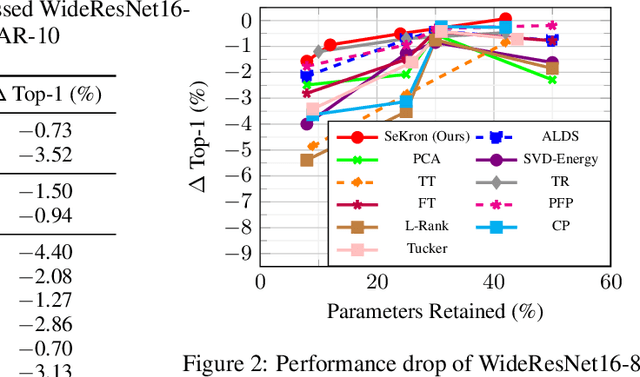
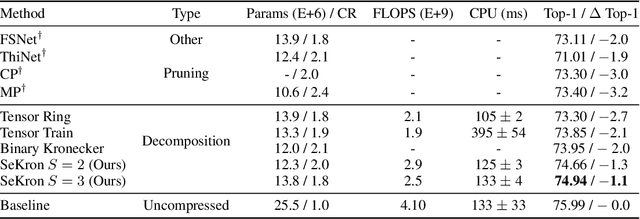
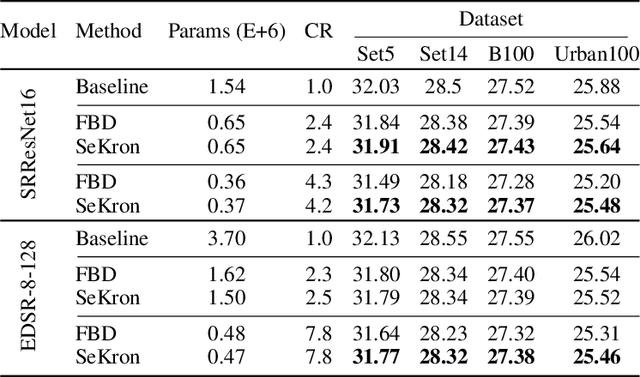
While convolutional neural networks (CNNs) have become the de facto standard for most image processing and computer vision applications, their deployment on edge devices remains challenging. Tensor decomposition methods provide a means of compressing CNNs to meet the wide range of device constraints by imposing certain factorization structures on their convolution tensors. However, being limited to the small set of factorization structures presented by state-of-the-art decomposition approaches can lead to sub-optimal performance. We propose SeKron, a novel tensor decomposition method that offers a wide variety of factorization structures, using sequences of Kronecker products. By recursively finding approximating Kronecker factors, we arrive at optimal decompositions for each of the factorization structures. We show that SeKron is a flexible decomposition that generalizes widely used methods, such as Tensor-Train (TT), Tensor-Ring (TR), Canonical Polyadic (CP) and Tucker decompositions. Crucially, we derive an efficient convolution projection algorithm shared by all SeKron structures, leading to seamless compression of CNN models. We validate SeKron for model compression on both high-level and low-level computer vision tasks and find that it outperforms state-of-the-art decomposition methods.
Integer Fine-tuning of Transformer-based Models
Sep 20, 2022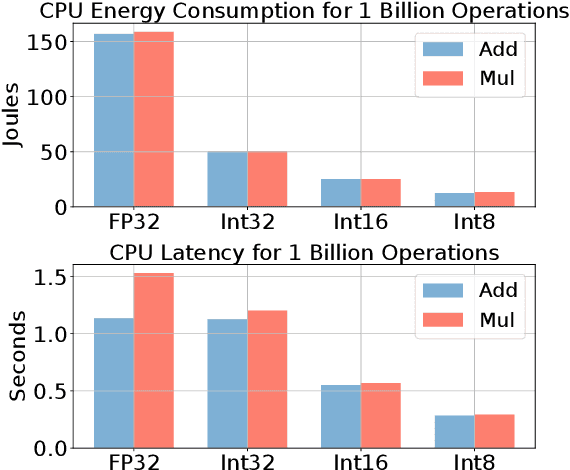
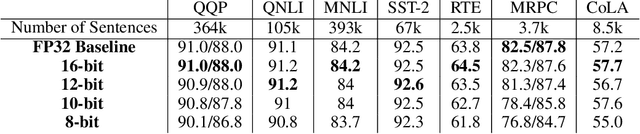
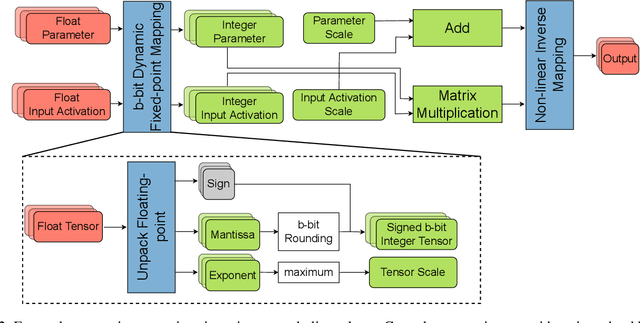
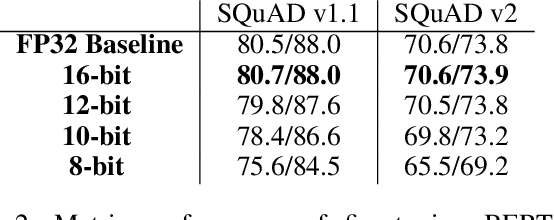
Transformer based models are used to achieve state-of-the-art performance on various deep learning tasks. Since transformer-based models have large numbers of parameters, fine-tuning them on downstream tasks is computationally intensive and energy hungry. Automatic mixed-precision FP32/FP16 fine-tuning of such models has been previously used to lower the compute resource requirements. However, with the recent advances in the low-bit integer back-propagation, it is possible to further reduce the computation and memory foot-print. In this work, we explore a novel integer training method that uses integer arithmetic for both forward propagation and gradient computation of linear, convolutional, layer-norm, and embedding layers in transformer-based models. Furthermore, we study the effect of various integer bit-widths to find the minimum required bit-width for integer fine-tuning of transformer-based models. We fine-tune BERT and ViT models on popular downstream tasks using integer layers. We show that 16-bit integer models match the floating-point baseline performance. Reducing the bit-width to 10, we observe 0.5 average score drop. Finally, further reduction of the bit-width to 8 provides an average score drop of 1.7 points.