 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA graph-structured distance for heterogeneous datasets with meta variables
May 20, 2024



Heterogeneous datasets emerge in various machine learning or optimization applications that feature different data sources, various data types and complex relationships between variables. In practice, heterogeneous datasets are often partitioned into smaller well-behaved ones that are easier to process. However, some applications involve expensive-to-generate or limited size datasets, which motivates methods based on the whole dataset. The first main contribution of this work is a modeling graph-structured framework that generalizes state-of-the-art hierarchical, tree-structured, or variable-size frameworks. This framework models domains that involve heterogeneous datasets in which variables may be continuous, integer, or categorical, with some identified as meta if their values determine the inclusion/exclusion or affect the bounds of other so-called decreed variables. Excluded variables are introduced to manage variables that are either included or excluded depending on the given points. The second main contribution is the graph-structured distance that compares extended points with any combination of included and excluded variables: any pair of points can be compared, allowing to work directly in heterogeneous datasets with meta variables. The contributions are illustrated with some regression experiments, in which the performance of a multilayer perceptron with respect to its hyperparameters is modeled with inverse distance weighting and $K$-nearest neighbors models.
Efficient Training Under Limited Resources
Jan 23, 2023Training time budget and size of the dataset are among the factors affecting the performance of a Deep Neural Network (DNN). This paper shows that Neural Architecture Search (NAS), Hyper Parameters Optimization (HPO), and Data Augmentation help DNNs perform much better while these two factors are limited. However, searching for an optimal architecture and the best hyperparameter values besides a good combination of data augmentation techniques under low resources requires many experiments. We present our approach to achieving such a goal in three steps: reducing training epoch time by compressing the model while maintaining the performance compared to the original model, preventing model overfitting when the dataset is small, and performing the hyperparameter tuning. We used NOMAD, which is a blackbox optimization software based on a derivative-free algorithm to do NAS and HPO. Our work achieved an accuracy of 86.0 % on a tiny subset of Mini-ImageNet at the ICLR 2021 Hardware Aware Efficient Training (HAET) Challenge and won second place in the competition. The competition results can be found at haet2021.github.io/challenge and our source code can be found at github.com/DouniaLakhmiri/ICLR\_HAET2021.
Scaling Deep Networks with the Mesh Adaptive Direct Search algorithm
Jan 17, 2023Deep neural networks are getting larger. Their implementation on edge and IoT devices becomes more challenging and moved the community to design lighter versions with similar performance. Standard automatic design tools such as \emph{reinforcement learning} and \emph{evolutionary computing} fundamentally rely on cheap evaluations of an objective function. In the neural network design context, this objective is the accuracy after training, which is expensive and time-consuming to evaluate. We automate the design of a light deep neural network for image classification using the \emph{Mesh Adaptive Direct Search}(MADS) algorithm, a mature derivative-free optimization method that effectively accounts for the expensive blackbox nature of the objective function to explore the design space, even in the presence of constraints.Our tests show competitive compression rates with reduced numbers of trials.
Use of static surrogates in hyperparameter optimization
Mar 14, 2021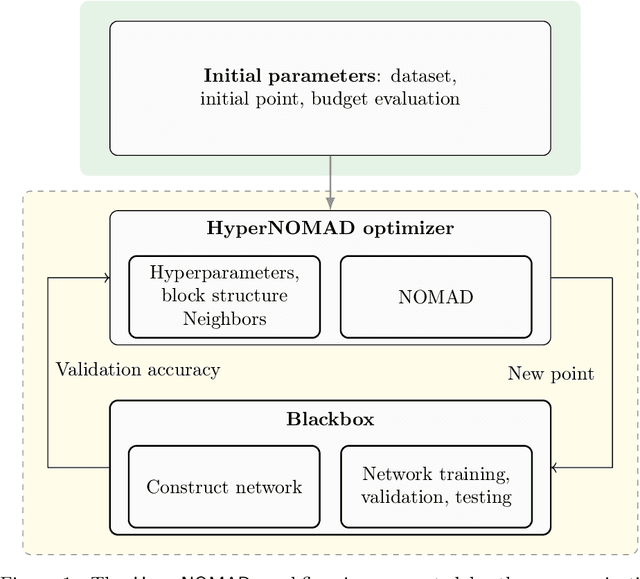
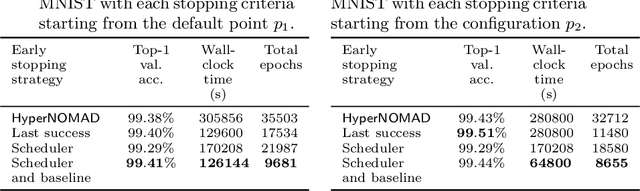
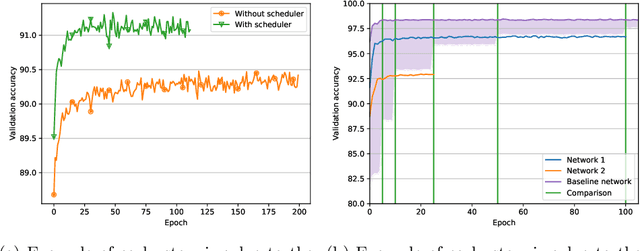
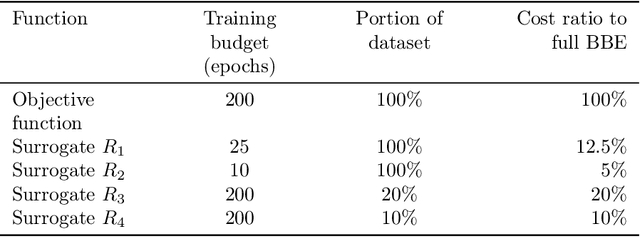
Optimizing the hyperparameters and architecture of a neural network is a long yet necessary phase in the development of any new application. This consuming process can benefit from the elaboration of strategies designed to quickly discard low quality configurations and focus on more promising candidates. This work aims at enhancing HyperNOMAD, a library that adapts a direct search derivative-free optimization algorithm to tune both the architecture and the training of a neural network simultaneously, by targeting two keys steps of its execution and exploiting cheap approximations in the form of static surrogates to trigger the early stopping of the evaluation of a configuration and the ranking of pools of candidates. These additions to HyperNOMAD are shown to improve on its resources consumption without harming the quality of the proposed solutions.
HyperNOMAD: Hyperparameter optimization of deep neural networks using mesh adaptive direct search
Jul 03, 2019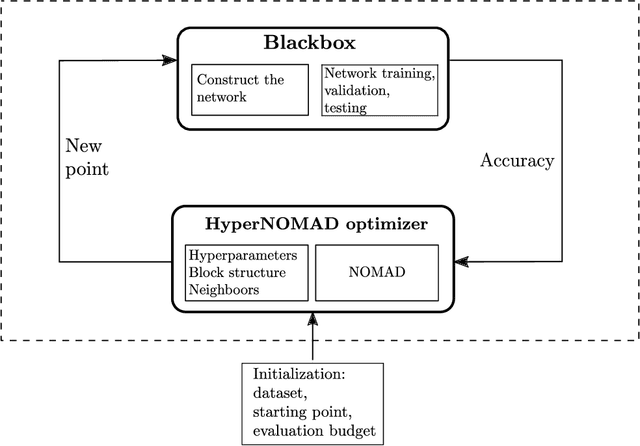
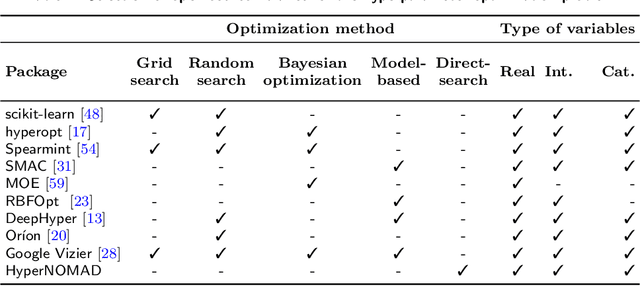
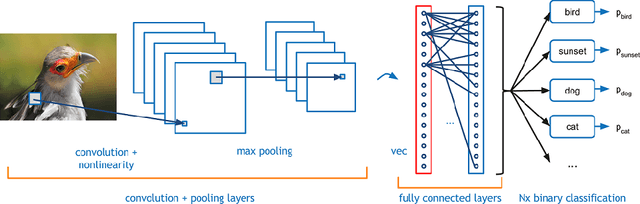
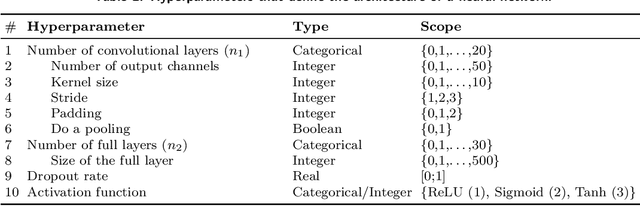
The performance of deep neural networks is highly sensitive to the choice of the hyperparameters that define the structure of the network and the learning process. When facing a new application, tuning a deep neural network is a tedious and time consuming process that is often described as a "dark art". This explains the necessity of automating the calibration of these hyperparameters. Derivative-free optimization is a field that develops methods designed to optimize time consuming functions without relying on derivatives. This work introduces the HyperNOMAD package, an extension of the NOMAD software that applies the MADS algorithm [7] to simultaneously tune the hyperparameters responsible for both the architecture and the learning process of a deep neural network (DNN), and that allows for an important flexibility in the exploration of the search space by taking advantage of categorical variables. This new approach is tested on the MNIST and CIFAR-10 data sets and achieves results comparable to the current state of the art.