 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Toolkit for Joint Speaker Diarization and Identification with Application to Speaker-Attributed ASR
Sep 09, 2024

We present a modular toolkit to perform joint speaker diarization and speaker identification. The toolkit can leverage on multiple models and algorithms which are defined in a configuration file. Such flexibility allows our system to work properly in various conditions (e.g., multiple registered speakers' sets, acoustic conditions and languages) and across application domains (e.g. media monitoring, institutional, speech analytics). In this demonstration we show a practical use-case in which speaker-related information is used jointly with automatic speech recognition engines to generate speaker-attributed transcriptions. To achieve that, we employ a user-friendly web-based interface to process audio and video inputs with the chosen configuration.
* Show and Tell paper. Presented at Interspeech 2024
Exploring Spoken Language Identification Strategies for Automatic Transcription of Multilingual Broadcast and Institutional Speech
Jun 13, 2024


This paper addresses spoken language identification (SLI) and speech recognition of multilingual broadcast and institutional speech, real application scenarios that have been rarely addressed in the SLI literature. Observing that in these domains language changes are mostly associated with speaker changes, we propose a cascaded system consisting of speaker diarization and language identification and compare it with more traditional language identification and language diarization systems. Results show that the proposed system often achieves lower language classification and language diarization error rates (up to 10% relative language diarization error reduction and 60% relative language confusion reduction) and leads to lower WERs on multilingual test sets (more than 8% relative WER reduction), while at the same time does not negatively affect speech recognition on monolingual audio (with an absolute WER increase between 0.1% and 0.7% w.r.t. monolingual ASR).
An Experimental Review of Speaker Diarization methods with application to Two-Speaker Conversational Telephone Speech recordings
May 29, 2023We performed an experimental review of current diarization systems for the conversational telephone speech (CTS) domain. In detail, we considered a total of eight different algorithms belonging to clustering-based, end-to-end neural diarization (EEND), and speech separation guided diarization (SSGD) paradigms. We studied the inference-time computational requirements and diarization accuracy on four CTS datasets with different characteristics and languages. We found that, among all methods considered, EEND-vector clustering (EEND-VC) offers the best trade-off in terms of computing requirements and performance. More in general, EEND models have been found to be lighter and faster in inference compared to clustering-based methods. However, they also require a large amount of diarization-oriented annotated data. In particular EEND-VC performance in our experiments degraded when the dataset size was reduced, whereas self-attentive EEND (SA-EEND) was less affected. We also found that SA-EEND gives less consistent results among all the datasets compared to EEND-VC, with its performance degrading on long conversations with high speech sparsity. Clustering-based diarization systems, and in particular VBx, instead have more consistent performance compared to SA-EEND but are outperformed by EEND-VC. The gap with respect to this latter is reduced when overlap-aware clustering methods are considered. SSGD is the most computationally demanding method, but it could be convenient if speech recognition has to be performed. Its performance is close to SA-EEND but degrades significantly when the training and inference data characteristics are less matched.
End-to-End Integration of Speech Separation and Voice Activity Detection for Low-Latency Diarization of Telephone Conversations
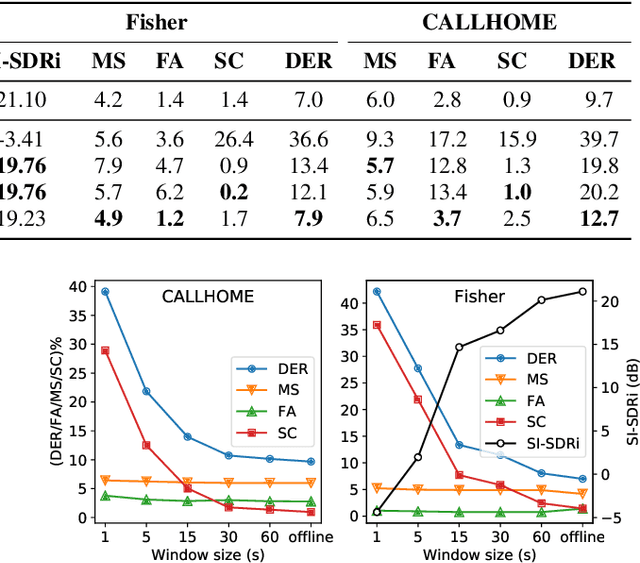
Mar 21, 2023Recent works show that speech separation guided diarization (SSGD) is an increasingly promising direction, mainly thanks to the recent progress in speech separation. It performs diarization by first separating the speakers and then applying voice activity detection (VAD) on each separated stream. In this work we conduct an in-depth study of SSGD in the conversational telephone speech (CTS) domain, focusing mainly on low-latency streaming diarization applications. We consider three state-of-the-art speech separation (SSep) algorithms and study their performance both in online and offline scenarios, considering non-causal and causal implementations as well as continuous SSep (CSS) windowed inference. We compare different SSGD algorithms on two widely used CTS datasets: CALLHOME and Fisher Corpus (Part 1 and 2) and evaluate both separation and diarization performance. To improve performance, a novel, causal and computationally efficient leakage removal algorithm is proposed, which significantly decreases false alarms. We also explore, for the first time, fully end-to-end SSGD integration between SSep and VAD modules. Crucially, this enables fine-tuning on real-world data for which oracle speakers sources are not available. In particular, our best model achieves 8.8% DER on CALLHOME, which outperforms the current state-of-the-art end-to-end neural diarization model, despite being trained on an order of magnitude less data and having significantly lower latency, i.e., 0.1 vs. 1 seconds. Finally, we also show that the separated signals can be readily used also for automatic speech recognition, reaching performance close to using oracle sources in some configurations.
Conversational Speech Separation: an Evaluation Study for Streaming Applications
May 31, 2022
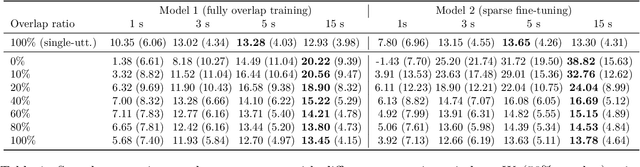
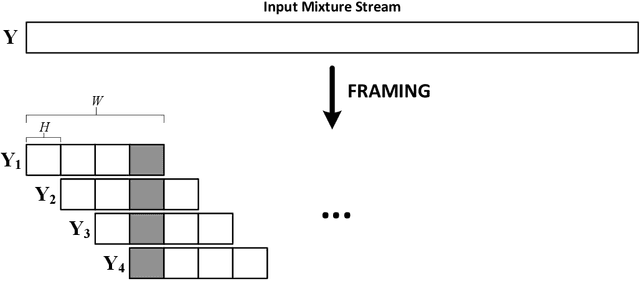
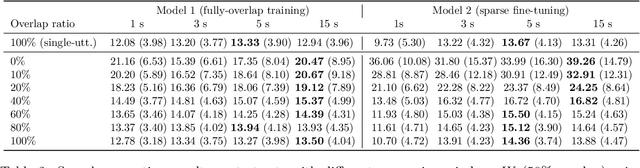
Continuous speech separation (CSS) is a recently proposed framework which aims at separating each speaker from an input mixture signal in a streaming fashion. Hereafter we perform an evaluation study on practical design considerations for a CSS system, addressing important aspects which have been neglected in recent works. In particular, we focus on the trade-off between separation performance, computational requirements and output latency showing how an offline separation algorithm can be used to perform CSS with a desired latency. We carry out an extensive analysis on the choice of CSS processing window size and hop size on sparsely overlapped data. We find out that the best trade-off between computational burden and performance is obtained for a window of 5 s.
Leveraging Speech Separation for Conversational Telephone Speaker Diarization
Apr 05, 2022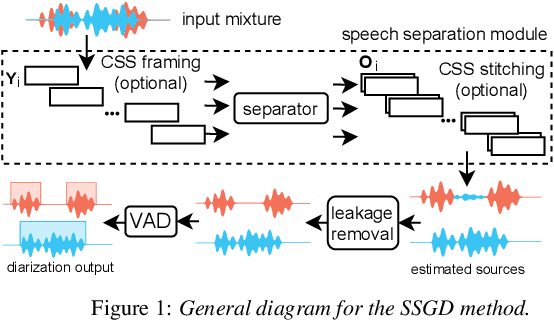
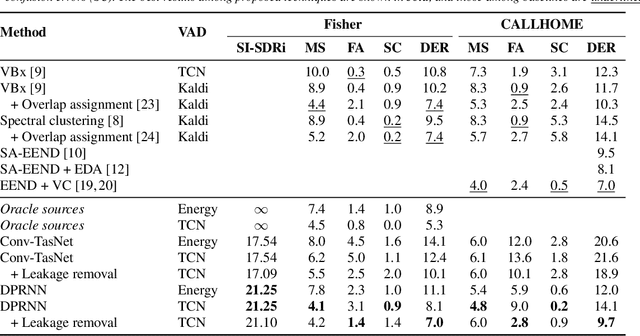

Speech separation and speaker diarization have strong similarities. In particular with respect to end-to-end neural diarization (EEND) methods. Separation aims at extracting each speaker from overlapped speech, while diarization identifies time boundaries of speech segments produced by the same speaker. In this paper, we carry out an analysis of the use of speech separation guided diarization (SSGD) where diarization is performed simply by separating the speakers signals and applying voice activity detection. In particular we compare two speech separation (SSep) models, both in offline and online settings. In the online setting we consider both the use of continuous source separation (CSS) and causal SSep models architectures. As an additional contribution, we show a simple post-processing algorithm which reduces significantly the false alarm errors of a SSGD pipeline. We perform our experiments on Fisher Corpus Part 1 and CALLHOME datasets evaluating both separation and diarization metrics. Notably, without fine-tuning, our SSGD DPRNN-based online model achieves 12.7% DER on CALLHOME, comparable with state-of-the-art EEND models despite having considerably lower latency, i.e., 50 ms vs 1 s.
Audio-Visual Speech Inpainting with Deep Learning
Oct 09, 2020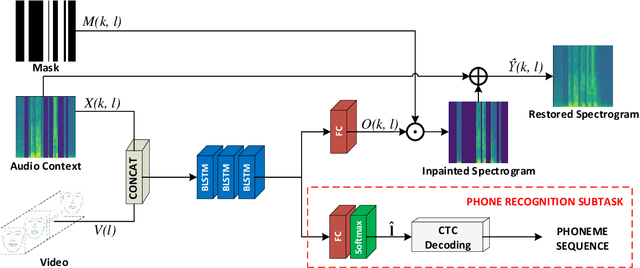
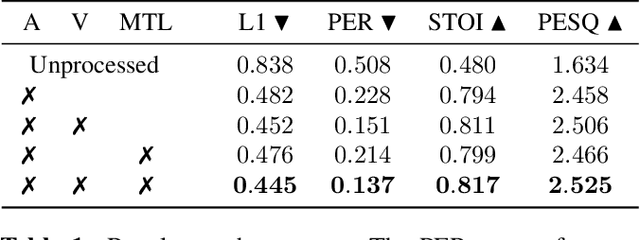
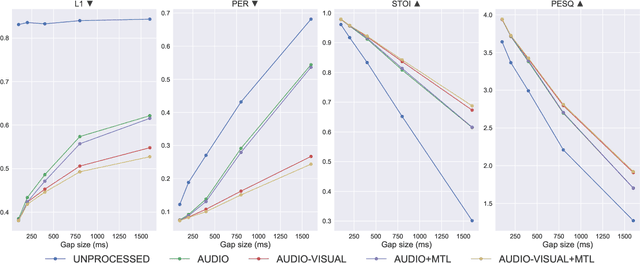
In this paper, we present a deep-learning-based framework for audio-visual speech inpainting, i.e., the task of restoring the missing parts of an acoustic speech signal from reliable audio context and uncorrupted visual information. Recent work focuses solely on audio-only methods and generally aims at inpainting music signals, which show highly different structure than speech. Instead, we inpaint speech signals with gaps ranging from 100 ms to 1600 ms to investigate the contribution that vision can provide for gaps of different duration. We also experiment with a multi-task learning approach where a phone recognition task is learned together with speech inpainting. Results show that the performance of audio-only speech inpainting approaches degrades rapidly when gaps get large, while the proposed audio-visual approach is able to plausibly restore missing information. In addition, we show that multi-task learning is effective, although the largest contribution to performance comes from vision.
Audio-Visual Target Speaker Extraction on Multi-Talker Environment using Event-Driven Cameras
Dec 05, 2019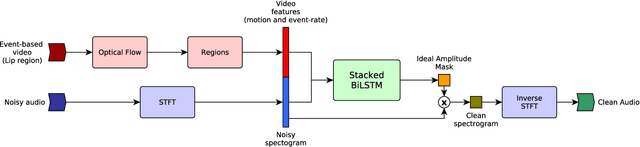

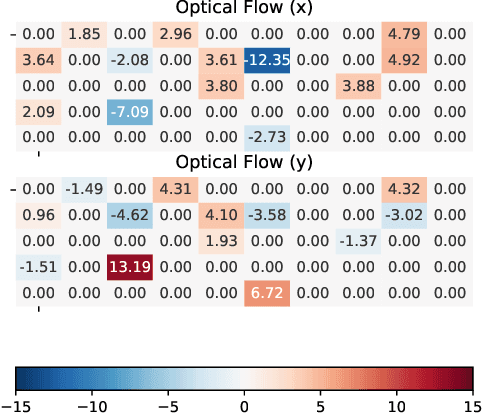
In this work, we propose a new method to address audio-visual target speaker extraction in multi-talker environments using event-driven cameras. All audio-visual speech separation approaches use a frame-based video to extract visual features. However, these frame-based cameras usually work at 30 frames per second. This limitation makes it difficult to process an audio-visual signal with low latency. In order to overcome this limitation, we propose using event-driven cameras due to their high temporal resolution and low latency. Recent work showed that the use of landmark motion features is very important in order to get good results on audio-visual speech separation. Thus, we use event-driven vision sensors from which the extraction of motion is available at lower latency computational cost. A stacked Bidirectional LSTM is trained to predict an Ideal Amplitude Mask before post-processing to get a clean audio signal. The performance of our model is close to those yielded in frame-based fashion.
Joined Audio-Visual Speech Enhancement and Recognition in the Cocktail Party: The Tug Of War Between Enhancement and Recognition Losses
Apr 16, 2019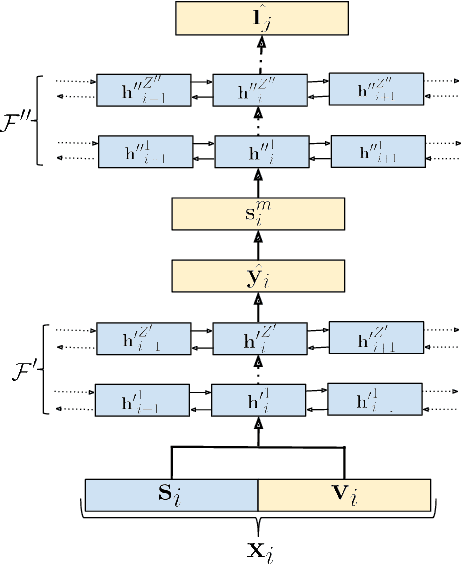
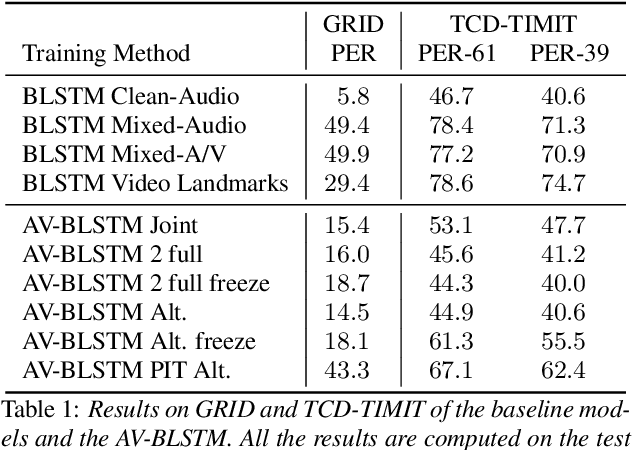
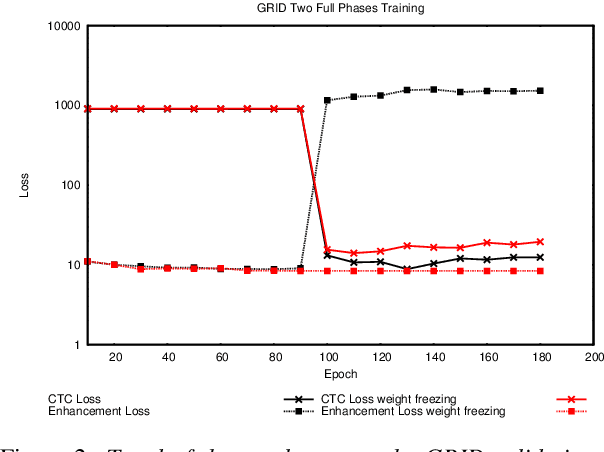
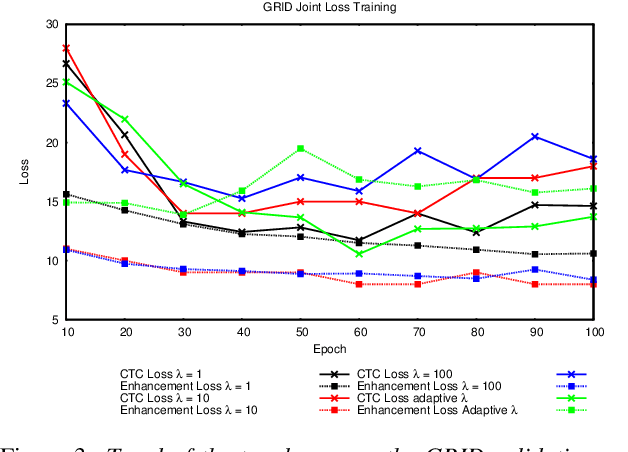
In this paper we propose an end-to-end LSTM-based model that performs single-channel speech enhancement and phone recognition in a cocktail party scenario where visual information of the target speaker is available. In the speech enhancement phase the proposed system uses a "visual attention" signal of the speaker of interest to extract her speech from the input mixed-speech signal, while in the ASR phase it recognizes her phone sequence through a phone recognizer trained with a CTC loss. It is well known that learning multiple related tasks from data simultaneously can improve performance than learning these tasks independently, therefore we decided to train the model by optimizing both tasks at the same time. This allowed us also to explore whether (and how) this joint optimization leads to better results. We analyzed different training strategies that reveal some interesting and unexpected behaviors. In particular, the experiments demonstrated that during optimization of the ASR phase the speech enhancement capability of the model significantly decreases and vice-versa. We evaluated our approach on mixed-speech versions of GRID and TCD-TIMIT. The obtained results show a remarkable drop of the Phone Error Rate (PER) compared to the audio-visual baseline models trained only to perform phone recognition phase.
Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
Nov 06, 2018
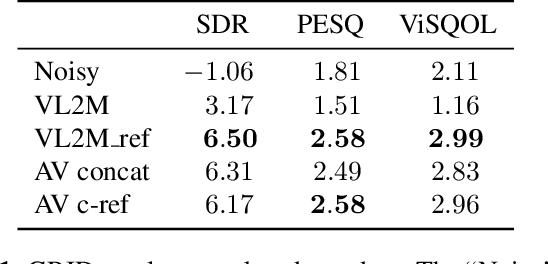
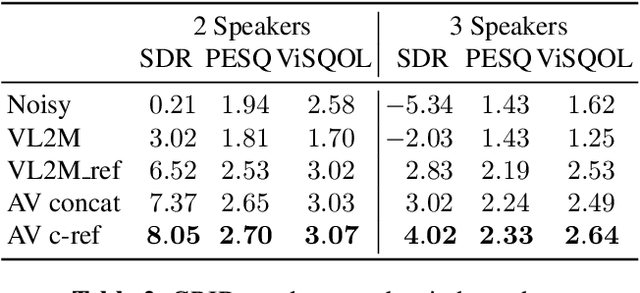
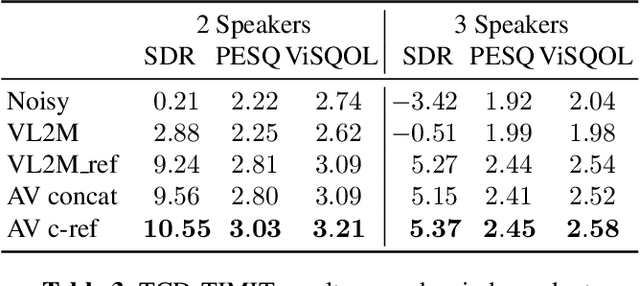
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available. Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, but use an already available face landmark detector (trained on a separate image dataset). The landmarks are used by LSTM-based models to generate time-frequency masks which are applied to the acoustic mixed-speech spectrogram. Results show that: (i) landmark motion features are very effective features for this task, (ii) similarly to previous work, reconstruction of the target speaker's spectrogram mediated by masking is significantly more accurate than direct spectrogram reconstruction, and (iii) the best masks depend on both motion landmark features and the input mixed-speech spectrogram. To the best of our knowledge, our proposed models are the first models trained and evaluated on the limited size GRID and TCD-TIMIT datasets, that achieve speaker-independent speech enhancement in a multi-talker setting.