 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Beats to Breaches:How Offensive AI Infers Sensitive User Information from Playlists
May 06, 2026The pervasive integration of AI has enabled Offensive AI: the exploitation of AI for malicious ends across the cyber-kill chain. A critical manifestation is the user attribute inference attack, where AI infers sensitive Personally Identifiable Information (PII) from innocuous public data. We explore how music streaming ecosystems, where users routinely release public playlists, can be exploited for Offensive AI. To quantify this threat, we developed musicPIIrate. This novel tool leverages deep learning architectures that utilize both standalone data representations and the structural information embedded in a user's playlist collection. Our design explores set-based approaches (e.g., Deep Sets) and methodologies modeling relationships between playlists (e.g., Graph Neural Networks), which we also combine to leverage both perspectives. Our approach addresses feature extraction from unordered, variable-length set data, enabling accurate PII prediction. Empirical evaluation demonstrates that musicPIIrate achieves state-of-the-art inference accuracy. The tool successfully infers a wide array of attributes, including: Demographics (Age, Country, Gender), Habits (Alcohol, Smoke, Sport), and Personality Traits (OCEAN scores). musicPIIrate outperforms existing methods, beating baselines in 9 out of 15 attribute inference tasks. To counter this vulnerability, we propose JamShield, a lightweight defensive framework. JamShield strategically injects dummy playlists into an account to dilute the PII-carrying signal. Our analysis indicates that JamShield represents a promising defense, lowering inference F1-scores by an average of 10%. This work provides an initial Offensive-AI benchmark for playlist-based PII inference using architectures that leverage set- and graph-structured data and introduces a defense showing encouraging mitigation effects.
Moshi Moshi? A Model Selection Hijacking Adversarial Attack
Feb 20, 2025Model selection is a fundamental task in Machine Learning~(ML), focusing on selecting the most suitable model from a pool of candidates by evaluating their performance on specific metrics. This process ensures optimal performance, computational efficiency, and adaptability to diverse tasks and environments. Despite its critical role, its security from the perspective of adversarial ML remains unexplored. This risk is heightened in the Machine-Learning-as-a-Service model, where users delegate the training phase and the model selection process to third-party providers, supplying data and training strategies. Therefore, attacks on model selection could harm both the user and the provider, undermining model performance and driving up operational costs. In this work, we present MOSHI (MOdel Selection HIjacking adversarial attack), the first adversarial attack specifically targeting model selection. Our novel approach manipulates model selection data to favor the adversary, even without prior knowledge of the system. Utilizing a framework based on Variational Auto Encoders, we provide evidence that an attacker can induce inefficiencies in ML deployment. We test our attack on diverse computer vision and speech recognition benchmark tasks and different settings, obtaining an average attack success rate of 75.42%. In particular, our attack causes an average 88.30% decrease in generalization capabilities, an 83.33% increase in latency, and an increase of up to 105.85% in energy consumption. These results highlight the significant vulnerabilities in model selection processes and their potential impact on real-world applications.
"All of Me": Mining Users' Attributes from their Public Spotify Playlists
Jan 25, 2024In the age of digital music streaming, playlists on platforms like Spotify have become an integral part of individuals' musical experiences. People create and publicly share their own playlists to express their musical tastes, promote the discovery of their favorite artists, and foster social connections. These publicly accessible playlists transcend the boundaries of mere musical preferences: they serve as sources of rich insights into users' attributes and identities. For example, the musical preferences of elderly individuals may lean more towards Frank Sinatra, while Billie Eilish remains a favored choice among teenagers. These playlists thus become windows into the diverse and evolving facets of one's musical identity. In this work, we investigate the relationship between Spotify users' attributes and their public playlists. In particular, we focus on identifying recurring musical characteristics associated with users' individual attributes, such as demographics, habits, or personality traits. To this end, we conducted an online survey involving 739 Spotify users, yielding a dataset of 10,286 publicly shared playlists encompassing over 200,000 unique songs and 55,000 artists. Through extensive statistical analyses, we first assess a deep connection between a user's Spotify playlists and their real-life attributes. For instance, we found individuals high in openness often create playlists featuring a diverse array of artists, while female users prefer Pop and K-pop music genres. Building upon these observed associations, we create accurate predictive models for users' attributes, presenting a novel DeepSet application that outperforms baselines in most of these users' attributes.
Simple Graph Convolutional Networks
Jun 10, 2021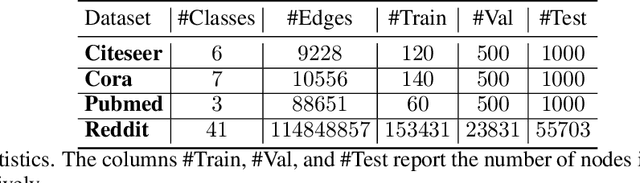
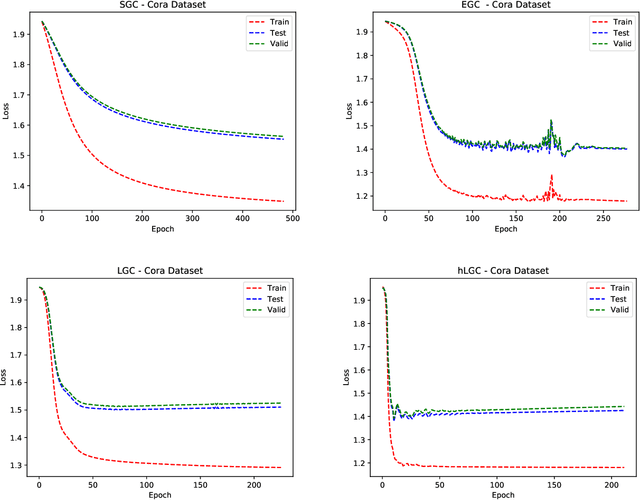

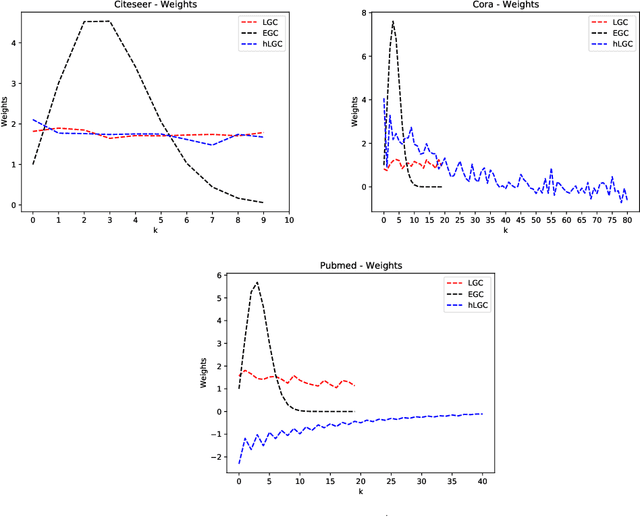
Many neural networks for graphs are based on the graph convolution operator, proposed more than a decade ago. Since then, many alternative definitions have been proposed, that tend to add complexity (and non-linearity) to the model. In this paper, we follow the opposite direction by proposing simple graph convolution operators, that can be implemented in single-layer graph convolutional networks. We show that our convolution operators are more theoretically grounded than many proposals in literature, and exhibit state-of-the-art predictive performance on the considered benchmark datasets.
Audio-Visual Target Speaker Extraction on Multi-Talker Environment using Event-Driven Cameras
Dec 05, 2019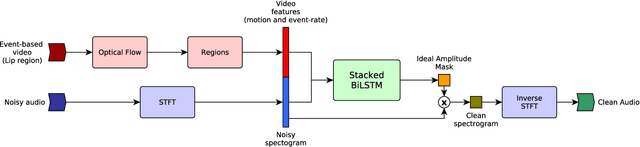

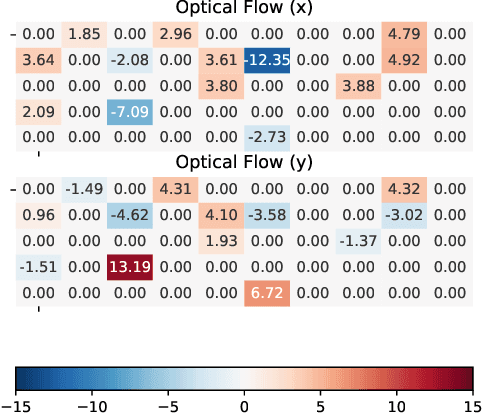
In this work, we propose a new method to address audio-visual target speaker extraction in multi-talker environments using event-driven cameras. All audio-visual speech separation approaches use a frame-based video to extract visual features. However, these frame-based cameras usually work at 30 frames per second. This limitation makes it difficult to process an audio-visual signal with low latency. In order to overcome this limitation, we propose using event-driven cameras due to their high temporal resolution and low latency. Recent work showed that the use of landmark motion features is very important in order to get good results on audio-visual speech separation. Thus, we use event-driven vision sensors from which the extraction of motion is available at lower latency computational cost. A stacked Bidirectional LSTM is trained to predict an Ideal Amplitude Mask before post-processing to get a clean audio signal. The performance of our model is close to those yielded in frame-based fashion.
Joined Audio-Visual Speech Enhancement and Recognition in the Cocktail Party: The Tug Of War Between Enhancement and Recognition Losses
Apr 16, 2019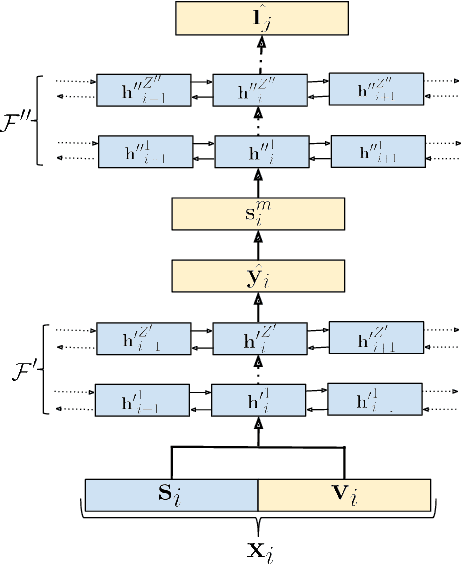
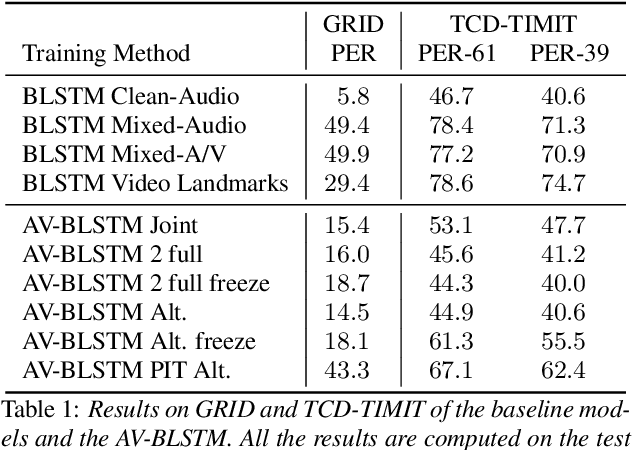
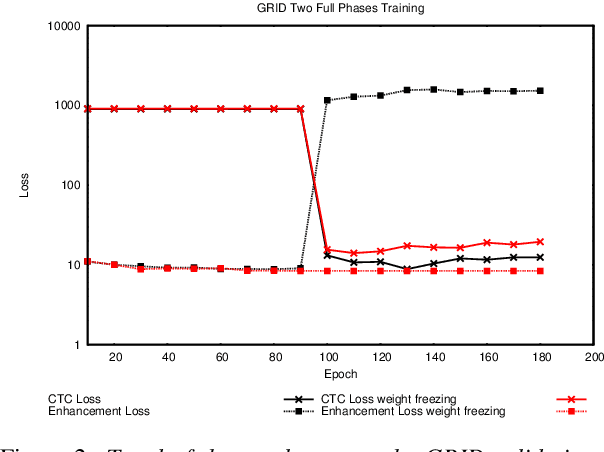
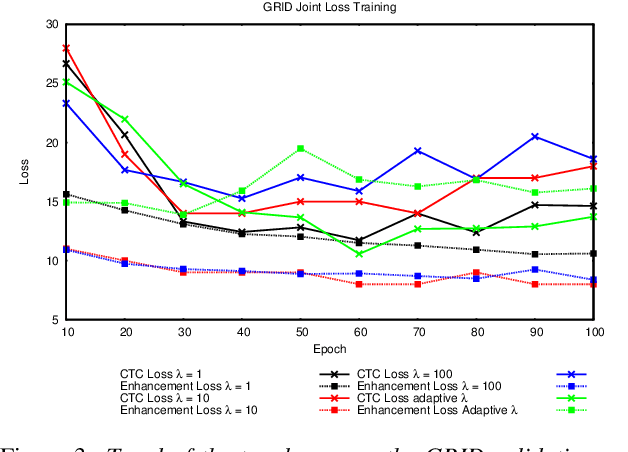
In this paper we propose an end-to-end LSTM-based model that performs single-channel speech enhancement and phone recognition in a cocktail party scenario where visual information of the target speaker is available. In the speech enhancement phase the proposed system uses a "visual attention" signal of the speaker of interest to extract her speech from the input mixed-speech signal, while in the ASR phase it recognizes her phone sequence through a phone recognizer trained with a CTC loss. It is well known that learning multiple related tasks from data simultaneously can improve performance than learning these tasks independently, therefore we decided to train the model by optimizing both tasks at the same time. This allowed us also to explore whether (and how) this joint optimization leads to better results. We analyzed different training strategies that reveal some interesting and unexpected behaviors. In particular, the experiments demonstrated that during optimization of the ASR phase the speech enhancement capability of the model significantly decreases and vice-versa. We evaluated our approach on mixed-speech versions of GRID and TCD-TIMIT. The obtained results show a remarkable drop of the Phone Error Rate (PER) compared to the audio-visual baseline models trained only to perform phone recognition phase.
Face Landmark-based Speaker-Independent Audio-Visual Speech Enhancement in Multi-Talker Environments
Nov 06, 2018
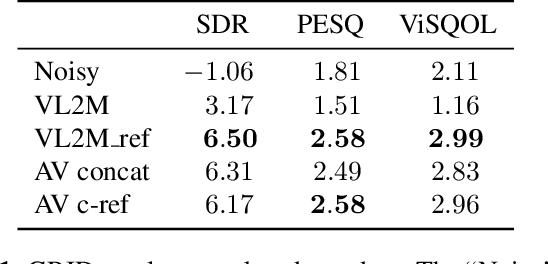
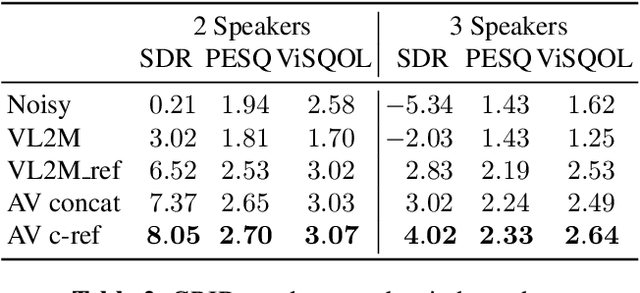
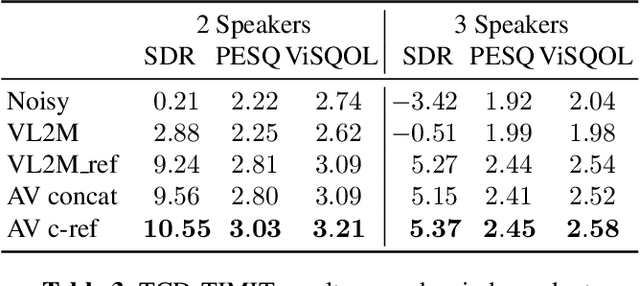
In this paper, we address the problem of enhancing the speech of a speaker of interest in a cocktail party scenario when visual information of the speaker of interest is available. Contrary to most previous studies, we do not learn visual features on the typically small audio-visual datasets, but use an already available face landmark detector (trained on a separate image dataset). The landmarks are used by LSTM-based models to generate time-frequency masks which are applied to the acoustic mixed-speech spectrogram. Results show that: (i) landmark motion features are very effective features for this task, (ii) similarly to previous work, reconstruction of the target speaker's spectrogram mediated by masking is significantly more accurate than direct spectrogram reconstruction, and (iii) the best masks depend on both motion landmark features and the input mixed-speech spectrogram. To the best of our knowledge, our proposed models are the first models trained and evaluated on the limited size GRID and TCD-TIMIT datasets, that achieve speaker-independent speech enhancement in a multi-talker setting.