 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-Learner: Quasi-Oracle Bounds on Heterogeneous Causal Effects Under Hidden Confounding
Apr 20, 2023



Estimating heterogeneous treatment effects from observational data is a crucial task across many fields, helping policy and decision-makers take better actions. There has been recent progress on robust and efficient methods for estimating the conditional average treatment effect (CATE) function, but these methods often do not take into account the risk of hidden confounding, which could arbitrarily and unknowingly bias any causal estimate based on observational data. We propose a meta-learner called the B-Learner, which can efficiently learn sharp bounds on the CATE function under limits on the level of hidden confounding. We derive the B-Learner by adapting recent results for sharp and valid bounds of the average treatment effect (Dorn et al., 2021) into the framework given by Kallus & Oprescu (2022) for robust and model-agnostic learning of distributional treatment effects. The B-Learner can use any function estimator such as random forests and deep neural networks, and we prove its estimates are valid, sharp, efficient, and have a quasi-oracle property with respect to the constituent estimators under more general conditions than existing methods. Semi-synthetic experimental comparisons validate the theoretical findings, and we use real-world data demonstrate how the method might be used in practice.
Malign Overfitting: Interpolation Can Provably Preclude Invariance
Nov 28, 2022



Learned classifiers should often possess certain invariance properties meant to encourage fairness, robustness, or out-of-distribution generalization. However, multiple recent works empirically demonstrate that common invariance-inducing regularizers are ineffective in the over-parameterized regime, in which classifiers perfectly fit (i.e. interpolate) the training data. This suggests that the phenomenon of ``benign overfitting," in which models generalize well despite interpolating, might not favorably extend to settings in which robustness or fairness are desirable. In this work we provide a theoretical justification for these observations. We prove that -- even in the simplest of settings -- any interpolating learning rule (with arbitrarily small margin) will not satisfy these invariance properties. We then propose and analyze an algorithm that -- in the same setting -- successfully learns a non-interpolating classifier that is provably invariant. We validate our theoretical observations on simulated data and the Waterbirds dataset.
Reinforcement Learning with a Terminator
May 30, 2022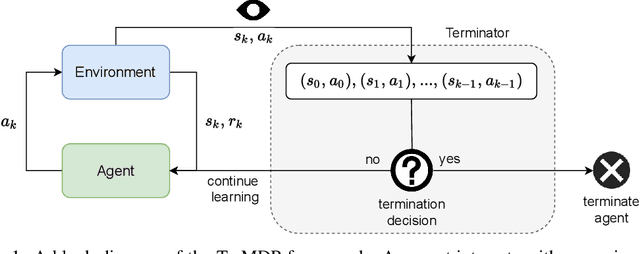
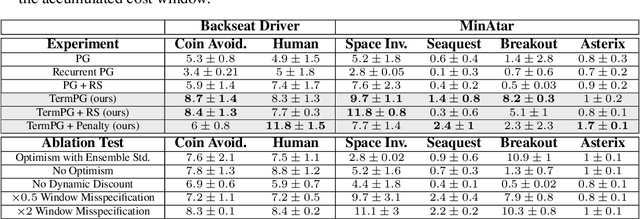
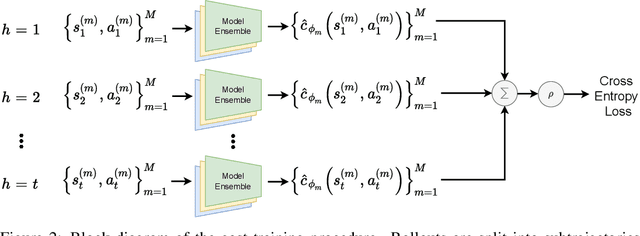
We present the problem of reinforcement learning with exogenous termination. We define the Termination Markov Decision Process (TerMDP), an extension of the MDP framework, in which episodes may be interrupted by an external non-Markovian observer. This formulation accounts for numerous real-world situations, such as a human interrupting an autonomous driving agent for reasons of discomfort. We learn the parameters of the TerMDP and leverage the structure of the estimation problem to provide state-wise confidence bounds. We use these to construct a provably-efficient algorithm, which accounts for termination, and bound its regret. Motivated by our theoretical analysis, we design and implement a scalable approach, which combines optimism (w.r.t. termination) and a dynamic discount factor, incorporating the termination probability. We deploy our method on high-dimensional driving and MinAtar benchmarks. Additionally, we test our approach on human data in a driving setting. Our results demonstrate fast convergence and significant improvement over various baseline approaches.
Scalable Sensitivity and Uncertainty Analysis for Causal-Effect Estimates of Continuous-Valued Interventions
Apr 26, 2022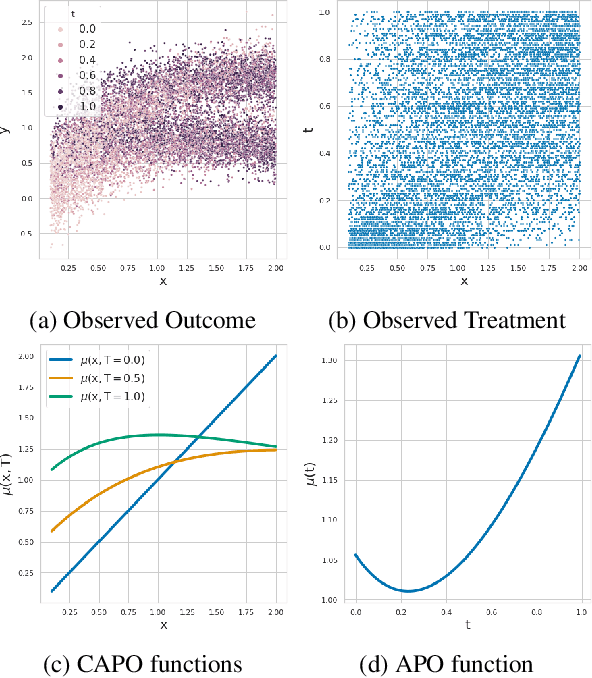

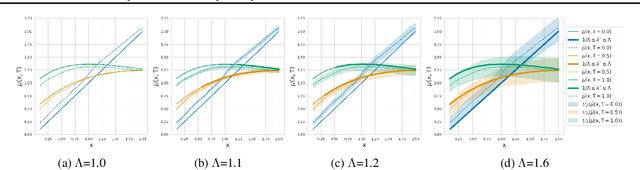
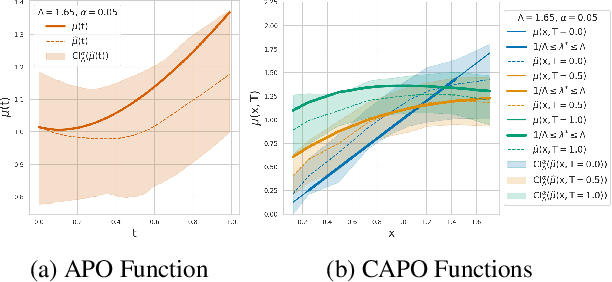
Estimating the effects of continuous-valued interventions from observational data is critically important in fields such as climate science, healthcare, and economics. Recent work focuses on designing neural-network architectures and regularization functions to allow for scalable estimation of average and individual-level dose response curves from high-dimensional, large-sample data. Such methodologies assume ignorability (all confounding variables are observed) and positivity (all levels of treatment can be observed for every unit described by a given covariate value), which are especially challenged in the continuous treatment regime. Developing scalable sensitivity and uncertainty analyses that allow us to understand the ignorance induced in our estimates when these assumptions are relaxed receives less attention. Here, we develop a continuous treatment-effect marginal sensitivity model (CMSM) and derive bounds that agree with both the observed data and a researcher-defined level of hidden confounding. We introduce a scalable algorithm to derive the bounds and uncertainty-aware deep models to efficiently estimate these bounds for high-dimensional, large-sample observational data. We validate our methods using both synthetic and real-world experiments. For the latter, we work in concert with climate scientists interested in evaluating the climatological impacts of human emissions on cloud properties using satellite observations from the past 15 years: a finite-data problem known to be complicated by the presence of a multitude of unobserved confounders.
Causal-BALD: Deep Bayesian Active Learning of Outcomes to Infer Treatment-Effects from Observational Data
Nov 03, 2021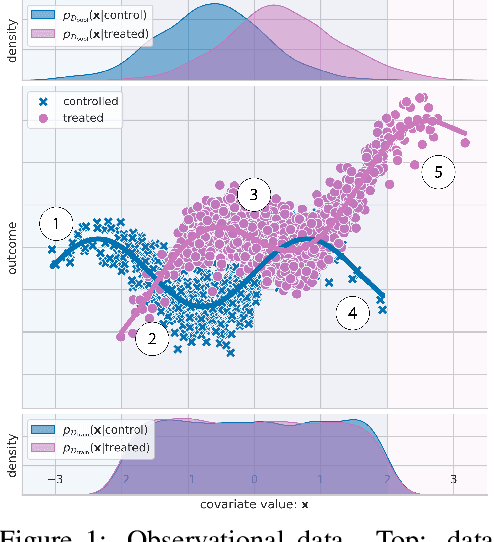
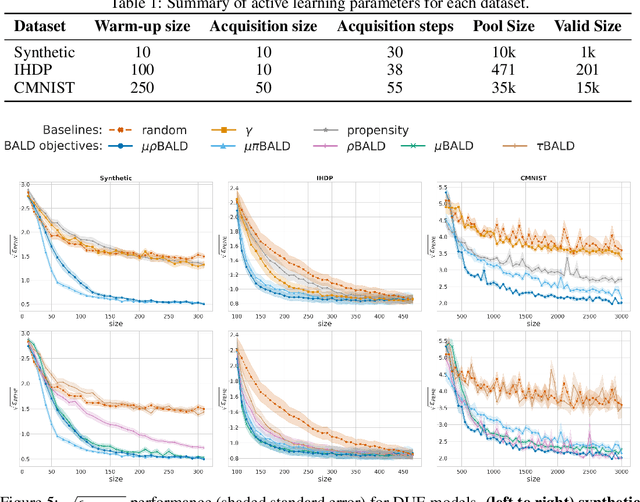
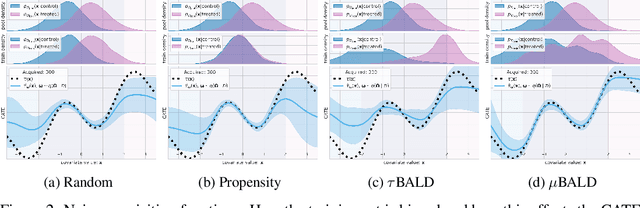

Estimating personalized treatment effects from high-dimensional observational data is essential in situations where experimental designs are infeasible, unethical, or expensive. Existing approaches rely on fitting deep models on outcomes observed for treated and control populations. However, when measuring individual outcomes is costly, as is the case of a tumor biopsy, a sample-efficient strategy for acquiring each result is required. Deep Bayesian active learning provides a framework for efficient data acquisition by selecting points with high uncertainty. However, existing methods bias training data acquisition towards regions of non-overlapping support between the treated and control populations. These are not sample-efficient because the treatment effect is not identifiable in such regions. We introduce causal, Bayesian acquisition functions grounded in information theory that bias data acquisition towards regions with overlapping support to maximize sample efficiency for learning personalized treatment effects. We demonstrate the performance of the proposed acquisition strategies on synthetic and semi-synthetic datasets IHDP and CMNIST and their extensions, which aim to simulate common dataset biases and pathologies.
On Covariate Shift of Latent Confounders in Imitation and Reinforcement Learning
Oct 13, 2021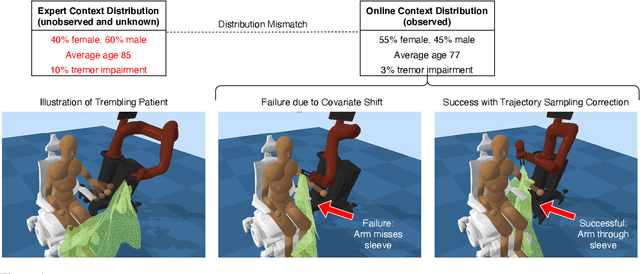
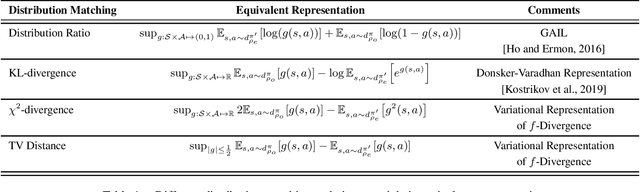

We consider the problem of using expert data with unobserved confounders for imitation and reinforcement learning. We begin by defining the problem of learning from confounded expert data in a contextual MDP setup. We analyze the limitations of learning from such data with and without external reward, and propose an adjustment of standard imitation learning algorithms to fit this setup. We then discuss the problem of distribution shift between the expert data and the online environment when the data is only partially observable. We prove possibility and impossibility results for imitation learning under arbitrary distribution shift of the missing covariates. When additional external reward is provided, we propose a sampling procedure that addresses the unknown shift and prove convergence to an optimal solution. Finally, we validate our claims empirically on challenging assistive healthcare and recommender system simulation tasks.
Quantifying Ignorance in Individual-Level Causal-Effect Estimates under Hidden Confounding
Mar 08, 2021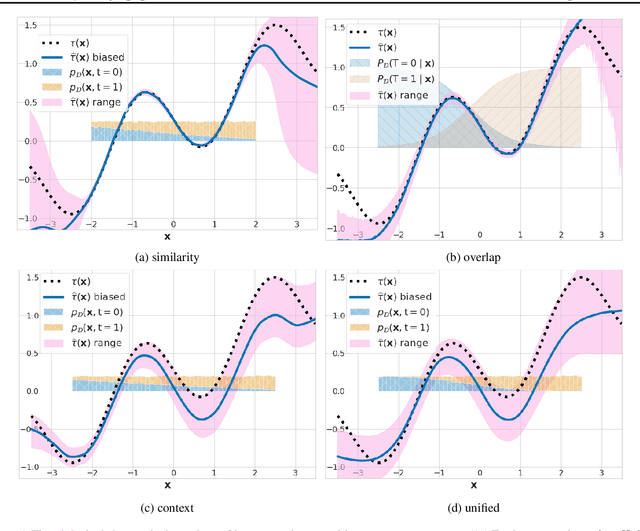

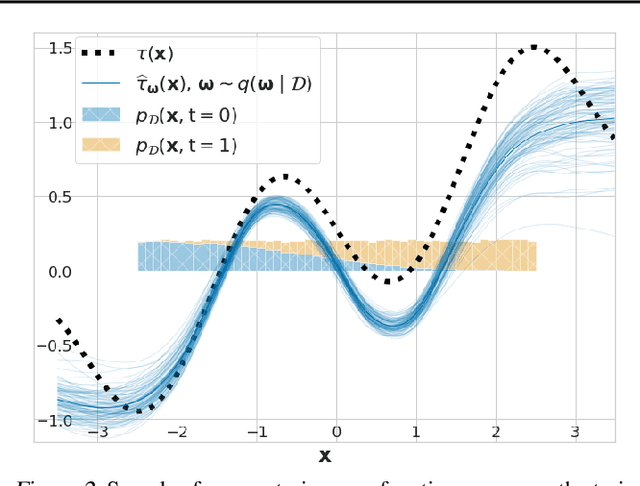
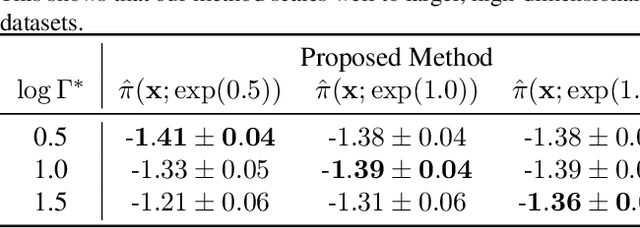
We study the problem of learning conditional average treatment effects (CATE) from high-dimensional, observational data with unobserved confounders. Unobserved confounders introduce ignorance -- a level of unidentifiability -- about an individual's response to treatment by inducing bias in CATE estimates. We present a new parametric interval estimator suited for high-dimensional data, that estimates a range of possible CATE values when given a predefined bound on the level of hidden confounding. Further, previous interval estimators do not account for ignorance about the CATE stemming from samples that may be underrepresented in the original study, or samples that violate the overlap assumption. Our novel interval estimator also incorporates model uncertainty so that practitioners can be made aware of out-of-distribution data. We prove that our estimator converges to tight bounds on CATE when there may be unobserved confounding, and assess it using semi-synthetic, high-dimensional datasets.
On Calibration and Out-of-domain Generalization
Feb 20, 2021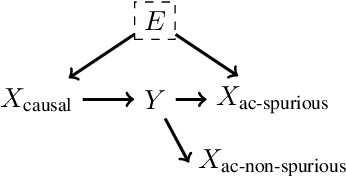

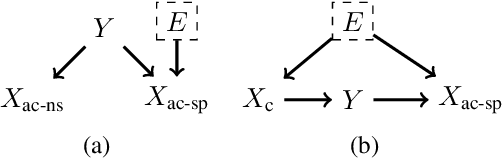
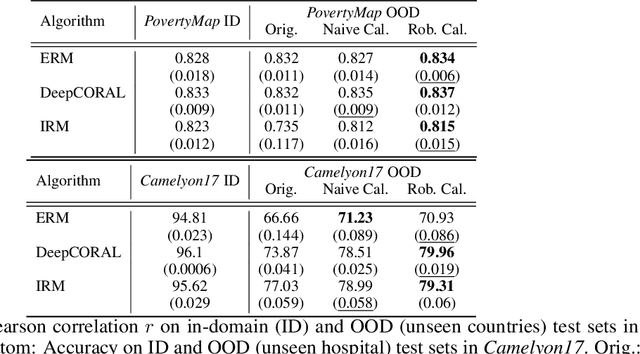
Out-of-domain (OOD) generalization is a significant challenge for machine learning models. To overcome it, many novel techniques have been proposed, often focused on learning models with certain invariance properties. In this work, we draw a link between OOD performance and model calibration, arguing that calibration across multiple domains can be viewed as a special case of an invariant representation leading to better OOD generalization. Specifically, we prove in a simplified setting that models which achieve multi-domain calibration are free of spurious correlations. This leads us to propose multi-domain calibration as a measurable surrogate for the OOD performance of a classifier. An important practical benefit of calibration is that there are many effective tools for calibrating classifiers. We show that these tools are easy to apply and adapt for a multi-domain setting. Using five datasets from the recently proposed WILDS OOD benchmark we demonstrate that simply re-calibrating models across multiple domains in a validation set leads to significantly improved performance on unseen test domains. We believe this intriguing connection between calibration and OOD generalization is promising from a practical point of view and deserves further research from a theoretical point of view.
Conditional Distributional Treatment Effect with Kernel Conditional Mean Embeddings and U-Statistic Regression
Feb 16, 2021


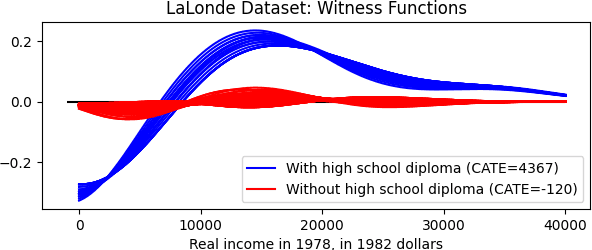
We propose to analyse the conditional distributional treatment effect (CoDiTE), which, in contrast to the more common conditional average treatment effect (CATE), is designed to encode a treatment's distributional aspects beyond the mean. We first introduce a formal definition of the CoDiTE associated with a distance function between probability measures. Then we discuss the CoDiTE associated with the maximum mean discrepancy via kernel conditional mean embeddings, which, coupled with a hypothesis test, tells us whether there is any conditional distributional effect of the treatment. Finally, we investigate what kind of conditional distributional effect the treatment has, both in an exploratory manner via the conditional witness function, and in a quantitative manner via U-statistic regression, generalising the CATE to higher-order moments. Experiments on synthetic, semi-synthetic and real datasets demonstrate the merits of our approach.
Using Deep Networks for Scientific Discovery in Physiological Signals
Aug 25, 2020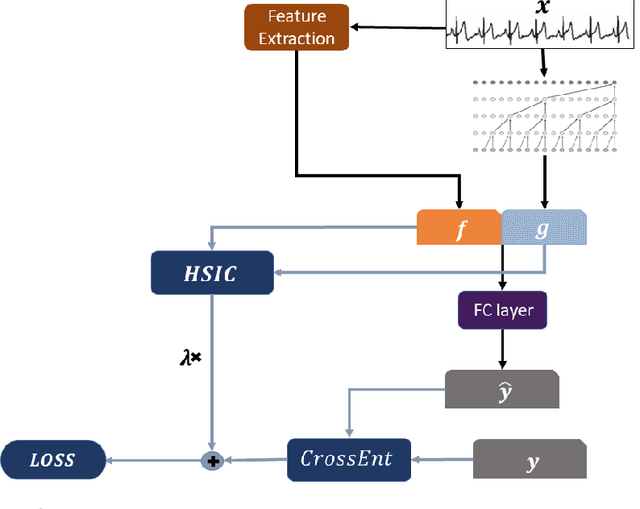
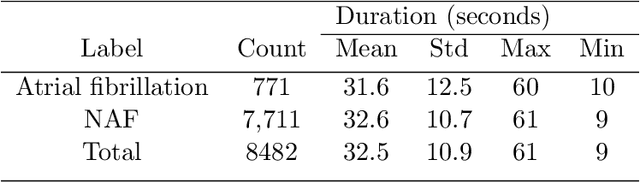

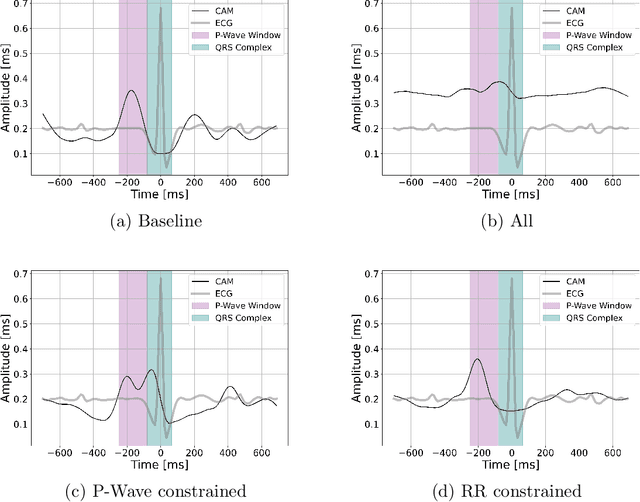
Deep neural networks (DNN) have shown remarkable success in the classification of physiological signals. In this study we propose a method for examining to what extent does a DNN's performance rely on rediscovering existing features of the signals, as opposed to discovering genuinely new features. Moreover, we offer a novel method of "removing" a hand-engineered feature from the network's hypothesis space, thus forcing it to try and learn representations which are different from known ones, as a method of scientific exploration. We then build on existing work in the field of interpretability, specifically class activation maps, to try and infer what new features the network has learned. We demonstrate this approach using ECG and EEG signals. With respect to ECG signals we show that for the specific task of classifying atrial fibrillation, DNNs are likely rediscovering known features. We also show how our method could be used to discover new features, by selectively removing some ECG features and "rediscovering" them. We further examine how could our method be used as a tool for examining scientific hypotheses. We simulate this scenario by looking into the importance of eye movements in classifying sleep from EEG. We show that our tool can successfully focus a researcher's attention by bringing to light patterns in the data that would be hidden otherwise.