 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Node Attack for Fooling Graph Neural Networks
Nov 06, 2020
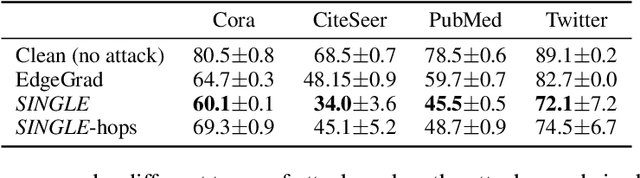
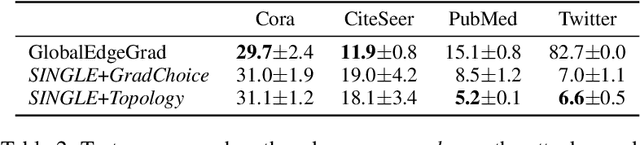
Graph neural networks (GNNs) have shown broad applicability in a variety of domains. Some of these domains, such as social networks and product recommendations, are fertile ground for malicious users and behavior. In this paper, we show that GNNs are vulnerable to the extremely limited scenario of a single-node adversarial example, where the node cannot be picked by the attacker. That is, an attacker can force the GNN to classify any target node to a chosen label by only slightly perturbing another single arbitrary node in the graph, even when not being able to pick that specific attacker node. When the adversary is allowed to pick a specific attacker node, the attack is even more effective. We show that this attack is effective across various GNN types, such as GraphSAGE, GCN, GAT, and GIN, across a variety of real-world datasets, and as a targeted and a non-targeted attack. Our code is available at https://github.com/benfinkelshtein/SINGLE .
On the Bottleneck of Graph Neural Networks and its Practical Implications
Jun 09, 2020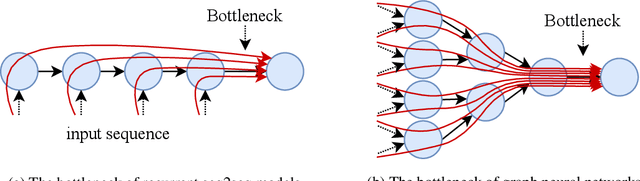
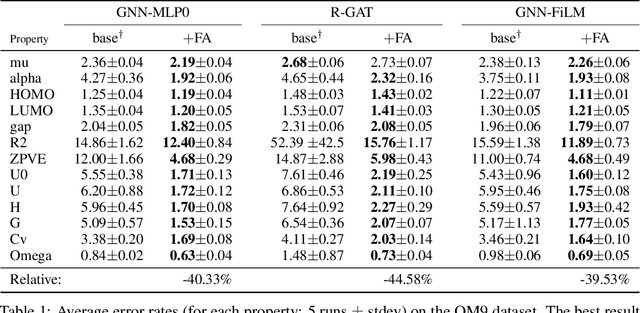
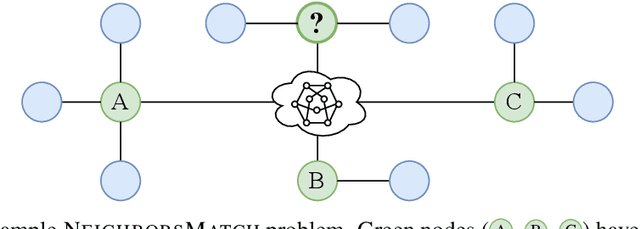
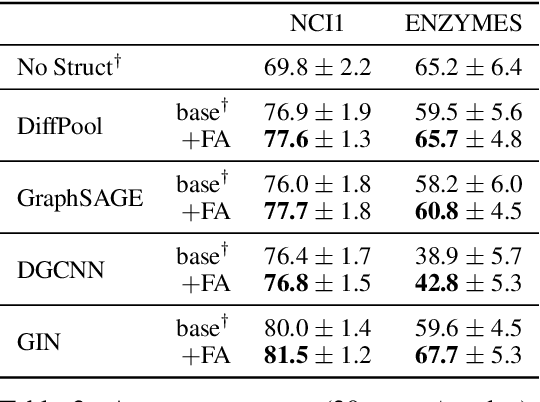
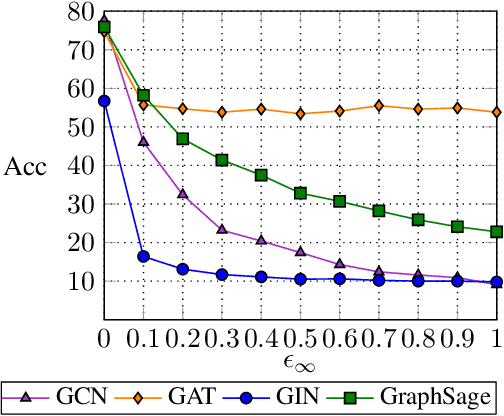
Graph neural networks (GNNs) were shown to effectively learn from highly structured data containing elements (nodes) with relationships (edges) between them. GNN variants differ in how each node in the graph absorbs the information flowing from its neighbor nodes. In this paper, we highlight an inherent problem in GNNs: the mechanism of propagating information between neighbors creates a bottleneck when every node aggregates messages from its neighbors. This bottleneck causes the over-squashing of exponentially-growing information into fixed-size vectors. As a result, the graph fails to propagate messages flowing from distant nodes and performs poorly when the prediction task depends on long-range information. We demonstrate that the bottleneck hinders popular GNNs from fitting the training data. We show that GNNs that absorb incoming edges equally, like GCN and GIN, are more susceptible to over-squashing than other GNN types. We further show that existing, extensively-tuned, GNN-based models suffer from over-squashing and that breaking the bottleneck improves state-of-the-art results without any hyperparameter tuning or additional weights.
Neural Edit Completion
May 27, 2020
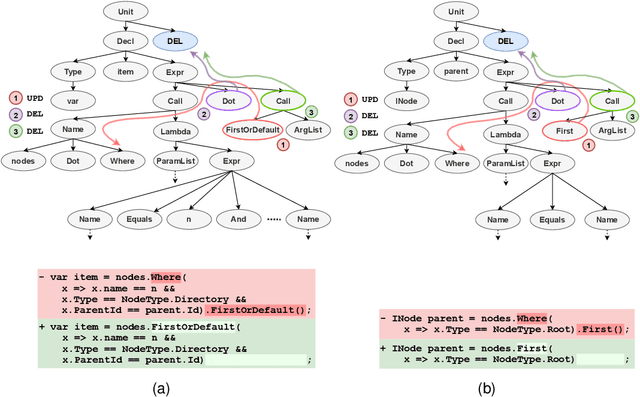
We address the problem of predicting edit completions based on a learned model that was trained on past edits. Given a code snippet that is partially edited, our goal is to predict a completion of the edit for the rest of the snippet. We refer to this task as the EditCompletion task and present a novel approach for tackling it. The main idea is to directly represent structural edits. This allows us to model the likelihood of the edit itself, rather than learning the likelihood of the edited code. We represent an edit operation as a path in the program's Abstract Syntax Tree (AST), originating from the source of the edit to the target of the edit. Using this representation, we present a powerful and lightweight neural model for the EditCompletion task. We conduct a thorough evaluation, comparing our approach to a variety of representation and modeling approaches that are driven by multiple strong models such as LSTMs, Transformers, and neural CRFs. Our experiments show that our model achieves 28% relative gain over state-of-the-art sequential models and 2$\times$ higher accuracy than syntactic models that learn to generate the edited code instead of modeling the edits directly. We make our code, dataset, and trained models publicly available.
Adversarial Examples for Models of Code
Nov 27, 2019
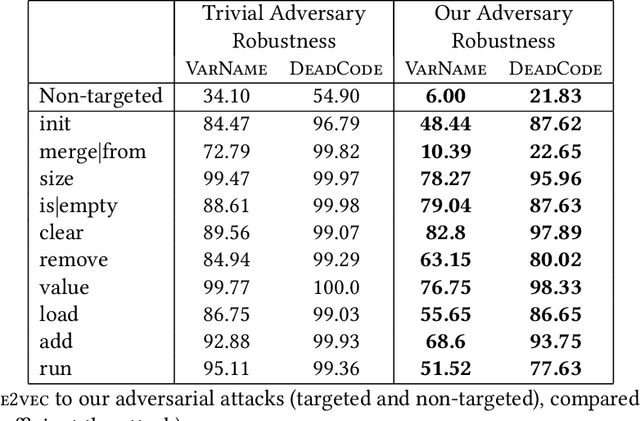
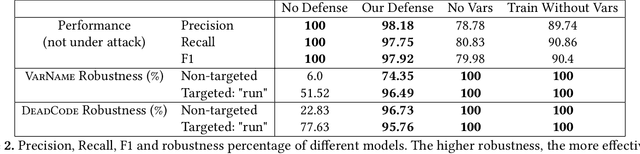
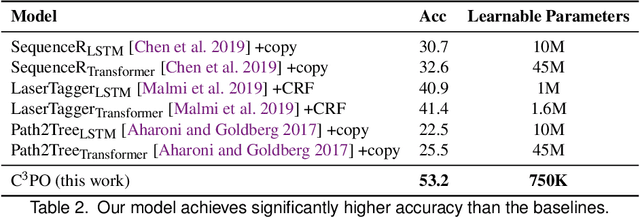
Neural models of code have shown impressive performance for tasks such as predicting method names and identifying certain kinds of bugs. In this paper, we show that these models are vulnerable to adversarial examples, and introduce a novel approach for attacking trained models of code with adversarial examples. The main idea is to force a given trained model to make an incorrect prediction as specified by the adversary by introducing small perturbations that do not change the program's semantics. To find such perturbations, we present a new technique for Discrete Adversarial Manipulation of Programs (DAMP). DAMP works by deriving the desired prediction with respect to the model's inputs while holding the model weights constant and following the gradients to slightly modify the code. To defend a model against such attacks, we propose placing a defensive model (Anti-DAMP) in front of it. Anti-DAMP detects unlikely mutations and masks them before feeding the input to the downstream model. We show that our DAMP attack is effective across three neural architectures: code2vec, GGNN, and GNN-FiLM, in both Java and C#. We show that DAMP has up to 89% success rate in changing a prediction to the adversary's choice ("targeted attack"), and a success rate of up to 94% in changing a given prediction to any incorrect prediction ("non-targeted attack"). By using Anti-DAMP, the success rate of the attack drops drastically for both targeted and non-targeted attacks, with a minor penalty of 2% relative degradation in accuracy while not performing under attack.
Structural Language Models for Any-Code Generation
Sep 30, 2019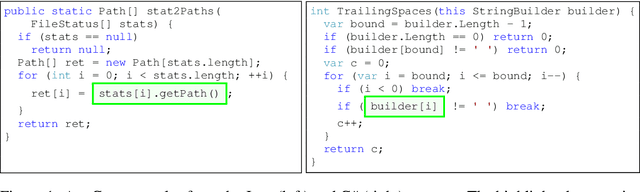
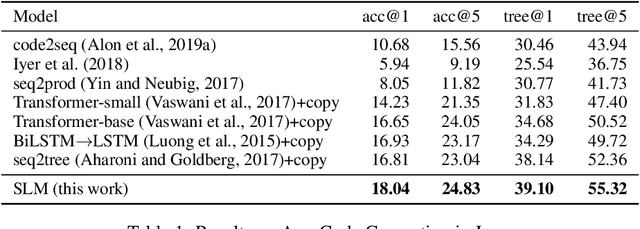
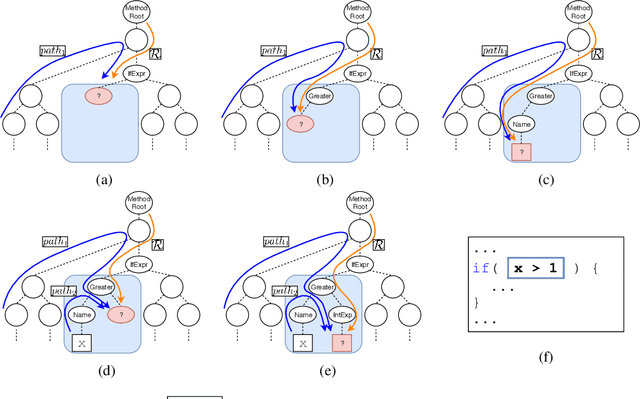
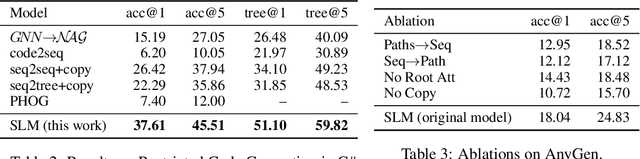
We address the problem of Any-Code Generation (AnyGen) - generating code without any restriction on the vocabulary or structure. The state-of-the-art in this problem is the sequence-to-sequence (seq2seq) approach, which treats code as a sequence and does not leverage any structural information. We introduce a new approach to AnyGen that leverages the strict syntax of programming languages to model a code snippet as a tree - structural language modeling (SLM). SLM estimates the probability of the program's abstract syntax tree (AST) by decomposing it into a product of conditional probabilities over its nodes. We present a neural model that computes these conditional probabilities by considering all AST paths leading to a target node. Unlike previous structural techniques that have severely restricted the kinds of expressions that can be generated, our approach can generate arbitrary expressions in any programming language. Our model significantly outperforms both seq2seq and a variety of existing structured approaches in generating Java and C# code. We make our code, datasets, and models available online.
Neural Reverse Engineering of Stripped Binaries
Feb 25, 2019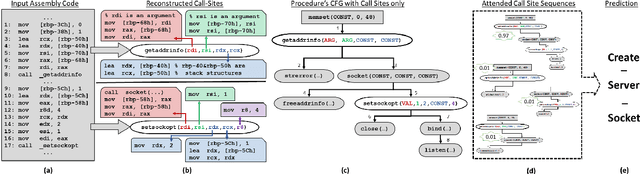
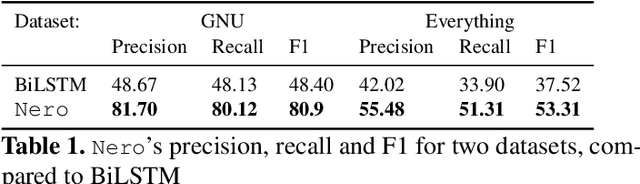

We address the problem of predicting procedure names in stripped executables which contain no debug information. Predicting procedure names can dramatically ease the task of reverse engineering, saving precious time and human effort. We present a novel approach that leverages static analysis of binaries with encoder-decoder-based neural networks. The main idea is to use static analysis to obtain enriched representations of API call sites; encode a set of sequences of these call sites; and finally, attend to the encoded sequences while decoding the target name token-by-token. We evaluate our model by predicting procedure names over $60,000$ procedures in $10,000$ stripped executables. Our model achieves $81.70$ precision and $80.12$ recall in predicting procedure names within GNU packages, and $55.48$ precision and $51.31$ recall in a diverse, cross-package, dataset. Comparing to previous approaches, the predictions made by our model are much more accurate and informative.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
code2vec: Learning Distributed Representations of Code
Oct 30, 2018

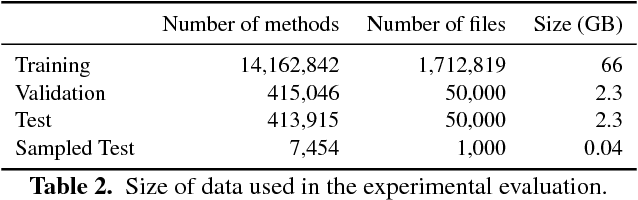
We present a neural model for representing snippets of code as continuous distributed vectors ("code embeddings"). The main idea is to represent a code snippet as a single fixed-length $\textit{code vector}$, which can be used to predict semantic properties of the snippet. This is performed by decomposing code to a collection of paths in its abstract syntax tree, and learning the atomic representation of each path $\textit{simultaneously}$ with learning how to aggregate a set of them. We demonstrate the effectiveness of our approach by using it to predict a method's name from the vector representation of its body. We evaluate our approach by training a model on a dataset of 14M methods. We show that code vectors trained on this dataset can predict method names from files that were completely unobserved during training. Furthermore, we show that our model learns useful method name vectors that capture semantic similarities, combinations, and analogies. Comparing previous techniques over the same data set, our approach obtains a relative improvement of over 75%, being the first to successfully predict method names based on a large, cross-project, corpus. Our trained model, visualizations and vector similarities are available as an interactive online demo at http://code2vec.org. The code, data, and trained models are available at https://github.com/tech-srl/code2vec.
Contextual Speech Recognition with Difficult Negative Training Examples
Oct 29, 2018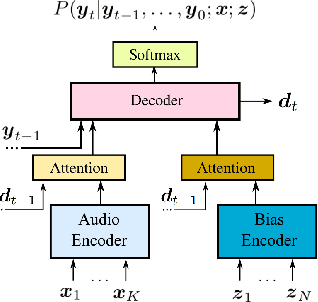
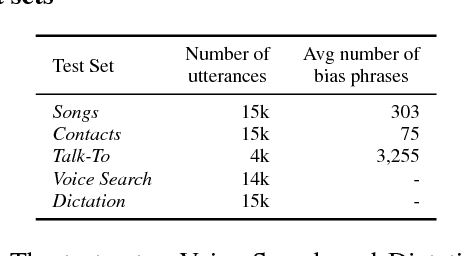
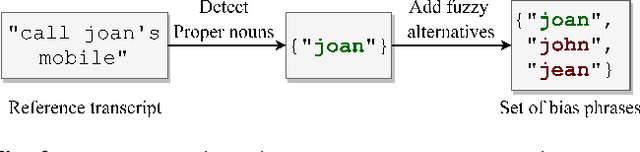
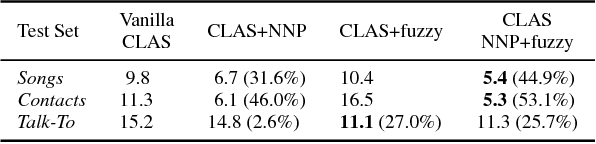
Improving the representation of contextual information is key to unlocking the potential of end-to-end (E2E) automatic speech recognition (ASR). In this work, we present a novel and simple approach for training an ASR context mechanism with difficult negative examples. The main idea is to focus on proper nouns (e.g., unique entities such as names of people and places) in the reference transcript, and use phonetically similar phrases as negative examples, encouraging the neural model to learn more discriminative representations. We apply our approach to an end-to-end contextual ASR model that jointly learns to transcribe and select the correct context items, and show that our proposed method gives up to $53.1\%$ relative improvement in word error rate (WER) across several benchmarks.
code2seq: Generating Sequences from Structured Representations of Code
Oct 10, 2018
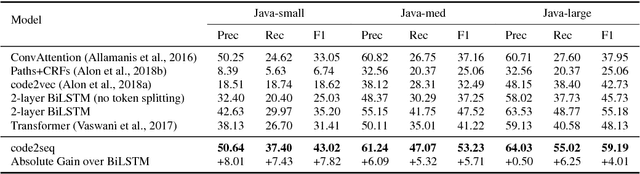
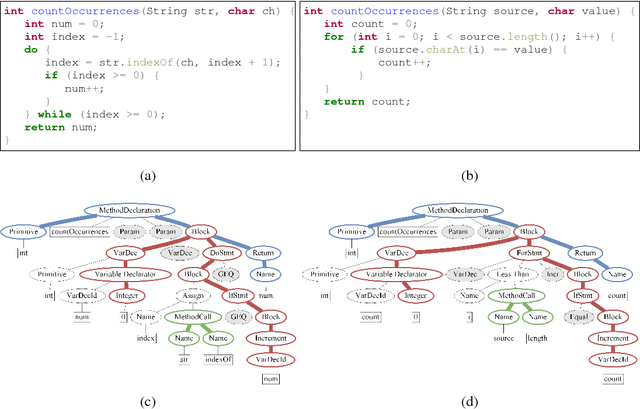
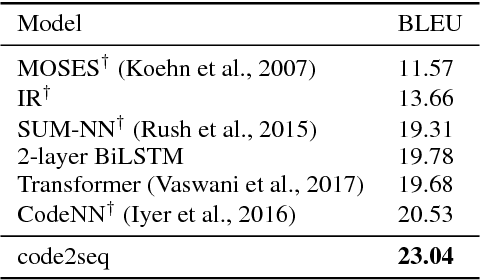
The ability to generate natural language sequences from source code snippets has a variety of applications such as code summarization, documentation, and retrieval. Sequence-to-sequence (seq2seq) models, adopted from neural machine translation (NMT), have achieved state-of-the-art performance on these tasks by treating source code as a sequence of tokens. We present ${\rm {\scriptsize CODE2SEQ}}$: an alternative approach that leverages the syntactic structure of programming languages to better encode source code. Our model represents a code snippet as the set of compositional paths in its abstract syntax tree (AST) and uses attention to select the relevant paths while decoding. We demonstrate the effectiveness of our approach for two tasks, two programming languages, and four datasets of up to $16$M examples. Our model significantly outperforms previous models that were specifically designed for programming languages, as well as state-of-the-art NMT models.