 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Stable Configurations for Semantic Placement of Novel Objects
Aug 26, 2021
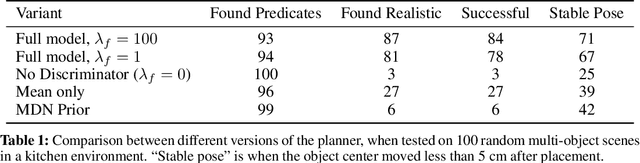
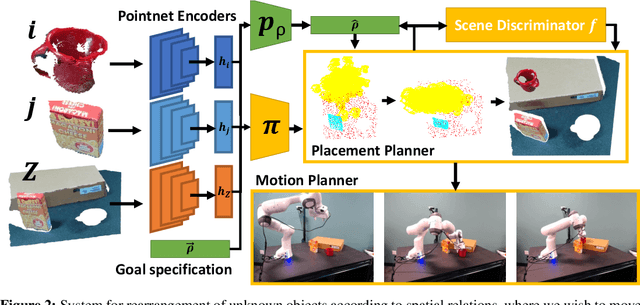
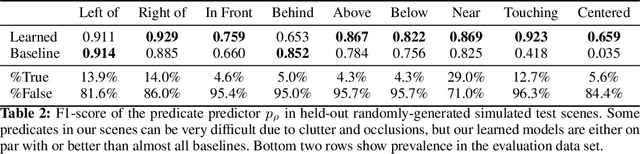
Human environments contain numerous objects configured in a variety of arrangements. Our goal is to enable robots to repose previously unseen objects according to learned semantic relationships in novel environments. We break this problem down into two parts: (1) finding physically valid locations for the objects and (2) determining if those poses satisfy learned, high-level semantic relationships. We build our models and training from the ground up to be tightly integrated with our proposed planning algorithm for semantic placement of unknown objects. We train our models purely in simulation, with no fine-tuning needed for use in the real world. Our approach enables motion planning for semantic rearrangement of unknown objects in scenes with varying geometry from only RGB-D sensing. Our experiments through a set of simulated ablations demonstrate that using a relational classifier alone is not sufficient for reliable planning. We further demonstrate the ability of our planner to generate and execute diverse manipulation plans through a set of real-world experiments with a variety of objects.
Parallelised Diffeomorphic Sampling-based Motion Planning
Aug 26, 2021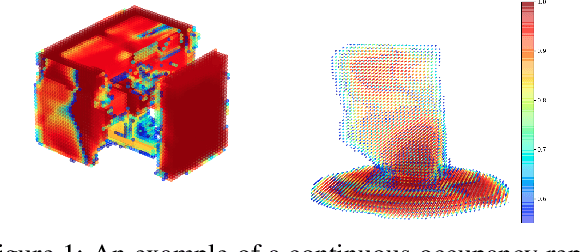
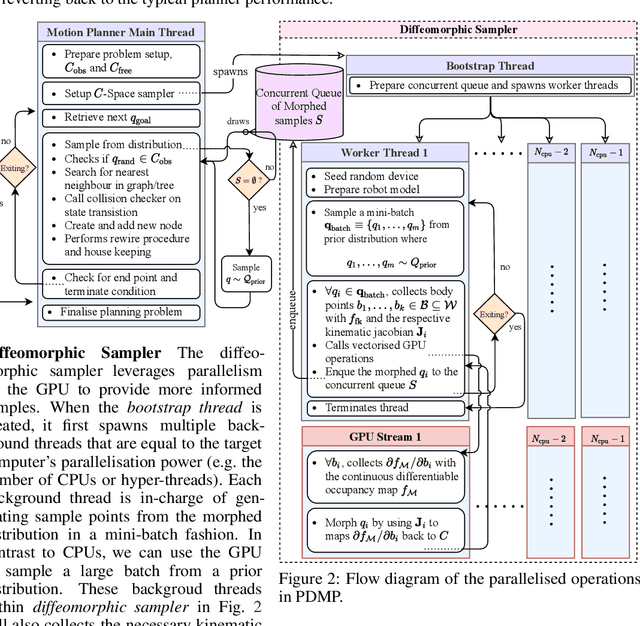
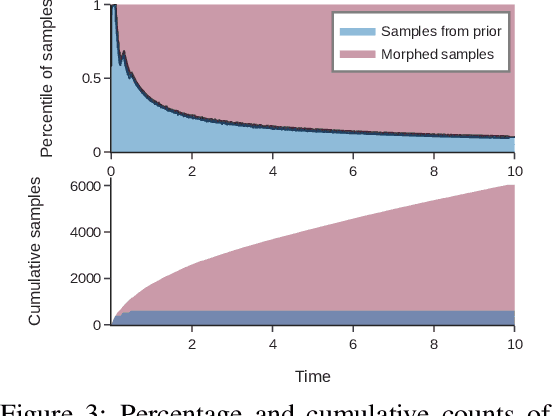
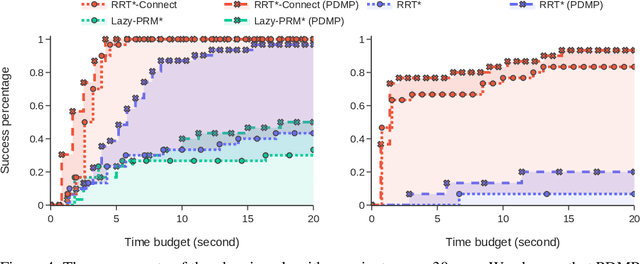
We propose Parallelised Diffeomorphic Sampling-based Motion Planning (PDMP). PDMP is a novel parallelised framework that uses bijective and differentiable mappings, or diffeomorphisms, to transform sampling distributions of sampling-based motion planners, in a manner akin to normalising flows. Unlike normalising flow models which use invertible neural network structures to represent these diffeomorphisms, we develop them from gradient information of desired costs, and encode desirable behaviour, such as obstacle avoidance. These transformed sampling distributions can then be used for sampling-based motion planning. A particular example is when we wish to imbue the sampling distribution with knowledge of the environment geometry, such that drawn samples are less prone to be in collisions. To this end, we propose to learn a continuous occupancy representation from environment occupancy data, such that gradients of the representation defines a valid diffeomorphism and is amenable to fast parallel evaluation. We use this to "morph" the sampling distribution to draw far fewer collision-prone samples. PDMP is able to leverage gradient information of costs, to inject specifications, in a manner similar to optimisation-based motion planning methods, but relies on drawing from a sampling distribution, retaining the tendency to find more global solutions, thereby bridging the gap between trajectory optimisation and sampling-based planning methods.
Ergonomically Intelligent Physical Human-Robot Interaction: Postural Estimation, Assessment, and Optimization
Aug 12, 2021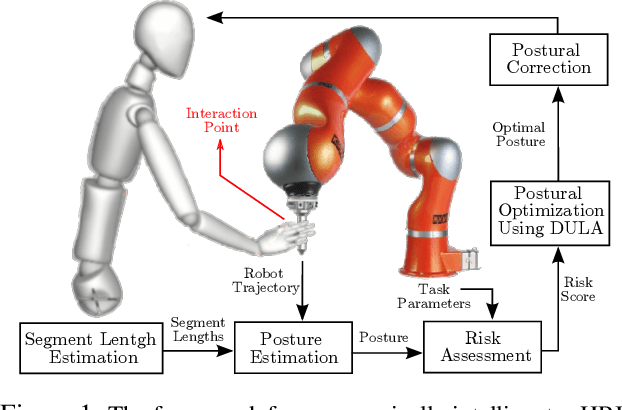

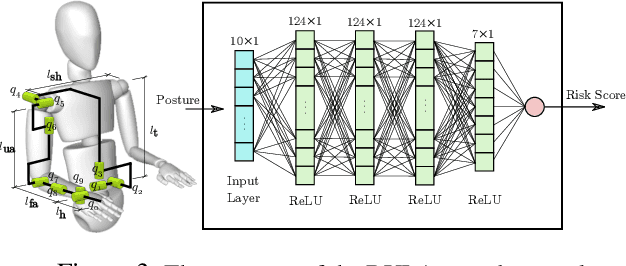
Ergonomics and human comfort are essential concerns in physical human-robot interaction applications, and common practical methods either fail in estimating the correct posture due to occlusion or suffer from less accurate ergonomics models in their postural optimization methods. Instead, we propose a novel framework for posture estimation, assessment, and optimization for ergonomically intelligent physical human-robot interaction. We show that we can estimate human posture solely from the trajectory of the interacting robot. We propose DULA, a differentiable ergonomics model, and use it in gradient-free postural optimization for physical human-robot interaction tasks such as co-manipulation and teleoperation. We evaluate our framework through human and simulation experiments.
DeformerNet: A Deep Learning Approach to 3D Deformable Object Manipulation
Jul 16, 2021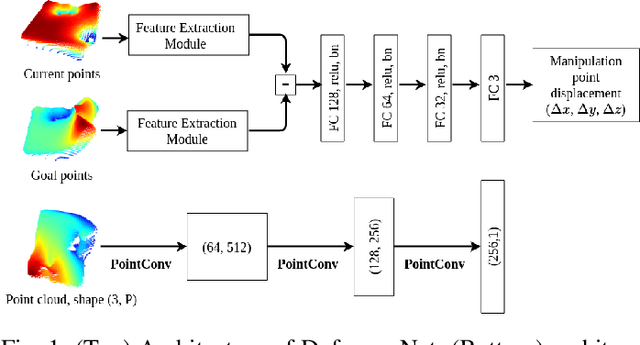


In this paper, we propose a novel approach to 3D deformable object manipulation leveraging a deep neural network called DeformerNet. Controlling the shape of a 3D object requires an effective state representation that can capture the full 3D geometry of the object. Current methods work around this problem by defining a set of feature points on the object or only deforming the object in 2D image space, which does not truly address the 3D shape control problem. Instead, we explicitly use 3D point clouds as the state representation and apply Convolutional Neural Network on point clouds to learn the 3D features. These features are then mapped to the robot end-effector's position using a fully-connected neural network. Once trained in an end-to-end fashion, DeformerNet directly maps the current point cloud of a deformable object, as well as a target point cloud shape, to the desired displacement in robot gripper position. In addition, we investigate the problem of predicting the manipulation point location given the initial and goal shape of the object.
DULA: A Differentiable Ergonomics Model for Postural Optimization in Physical HRI
Jul 14, 2021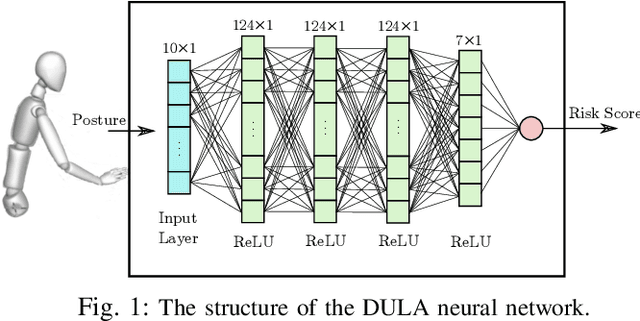
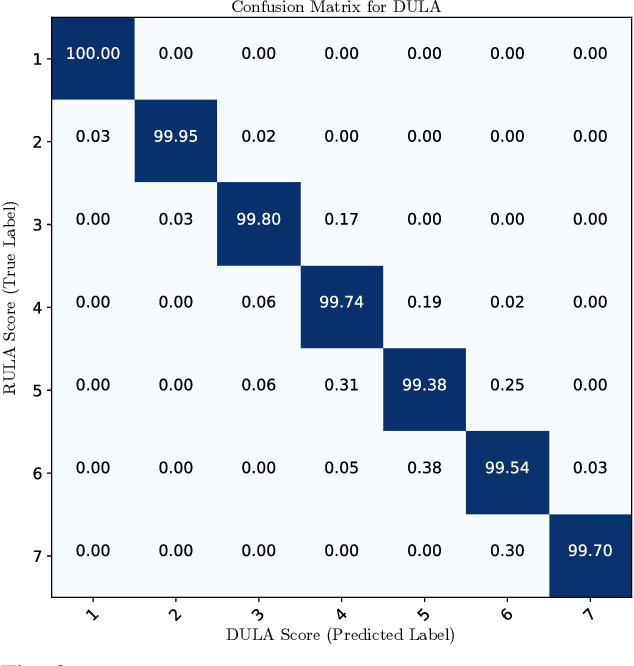
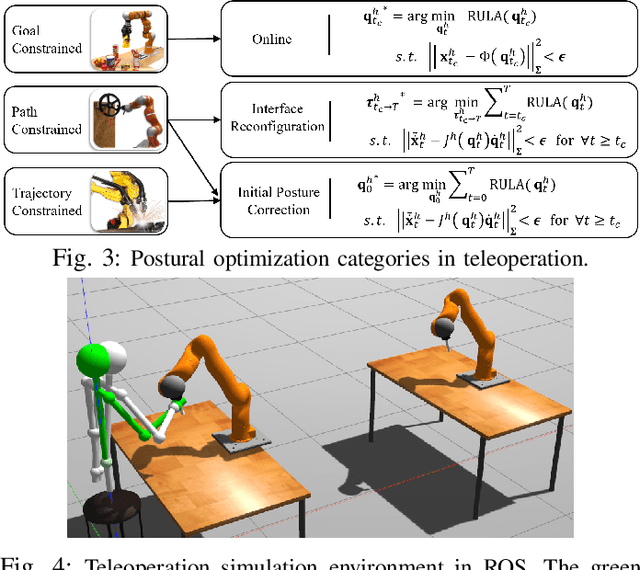
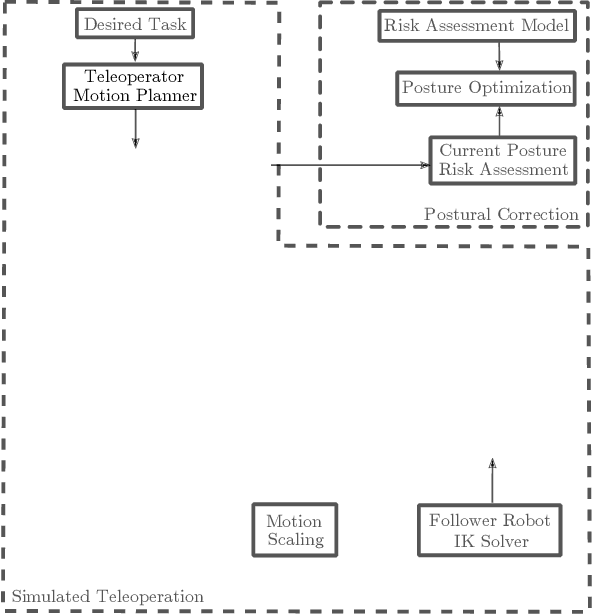
Ergonomics and human comfort are essential concerns in physical human-robot interaction applications. Defining an accurate and easy-to-use ergonomic assessment model stands as an important step in providing feedback for postural correction to improve operator health and comfort. In order to enable efficient computation, previously proposed automated ergonomic assessment and correction tools make approximations or simplifications to gold-standard assessment tools used by ergonomists in practice. In order to retain assessment quality, while improving computational considerations, we introduce DULA, a differentiable and continuous ergonomics model learned to replicate the popular and scientifically validated RULA assessment. We show that DULA provides assessment comparable to RULA while providing computational benefits. We highlight DULA's strength in a demonstration of gradient-based postural optimization for a simulated teleoperation task.
DefGraspSim: Simulation-based grasping of 3D deformable objects
Jul 12, 2021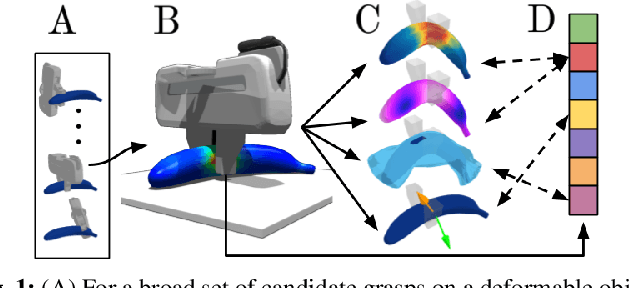
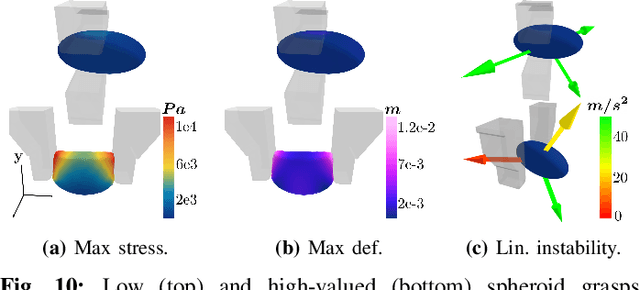

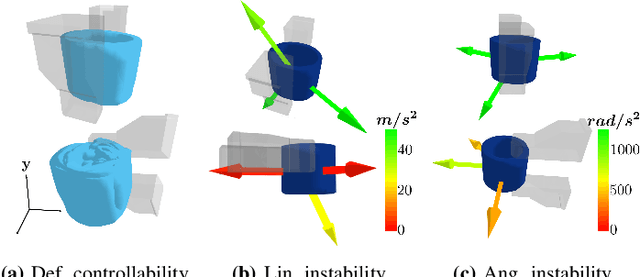
Robotic grasping of 3D deformable objects (e.g., fruits/vegetables, internal organs, bottles/boxes) is critical for real-world applications such as food processing, robotic surgery, and household automation. However, developing grasp strategies for such objects is uniquely challenging. In this work, we efficiently simulate grasps on a wide range of 3D deformable objects using a GPU-based implementation of the corotational finite element method (FEM). To facilitate future research, we open-source our simulated dataset (34 objects, 1e5 Pa elasticity range, 6800 grasp evaluations, 1.1M grasp measurements), as well as a code repository that allows researchers to run our full FEM-based grasp evaluation pipeline on arbitrary 3D object models of their choice. We also provide a detailed analysis on 6 object primitives. For each primitive, we methodically describe the effects of different grasp strategies, compute a set of performance metrics (e.g., deformation, stress) that fully capture the object response, and identify simple grasp features (e.g., gripper displacement, contact area) measurable by robots prior to pickup and predictive of these performance metrics. Finally, we demonstrate good correspondence between grasps on simulated objects and their real-world counterparts.
Optimizing Hospital Room Layout to Reduce the Risk of Patient Falls
Jan 08, 2021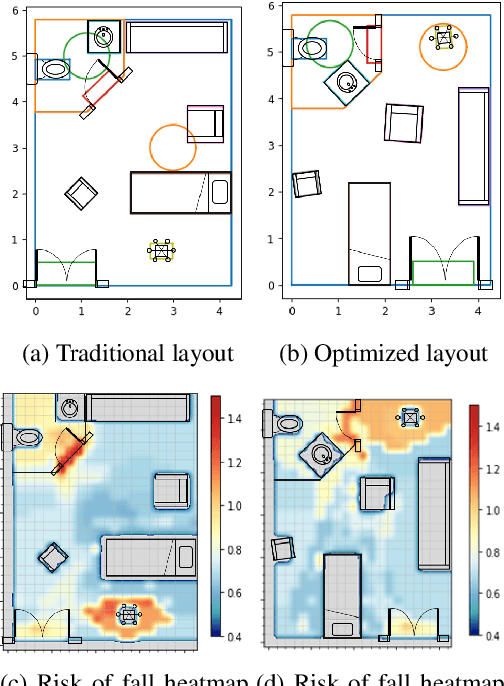
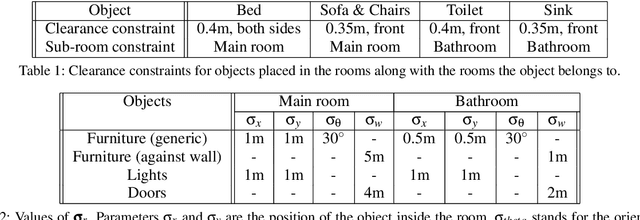
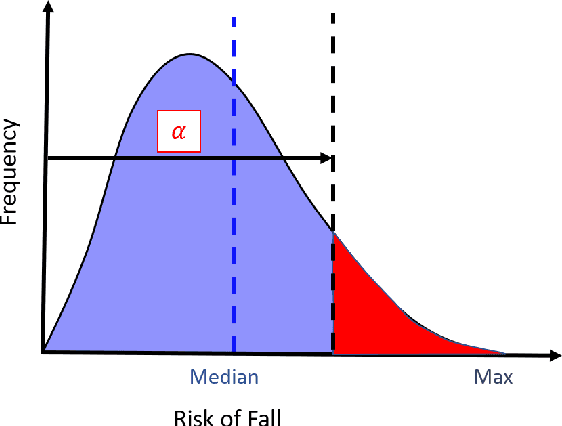
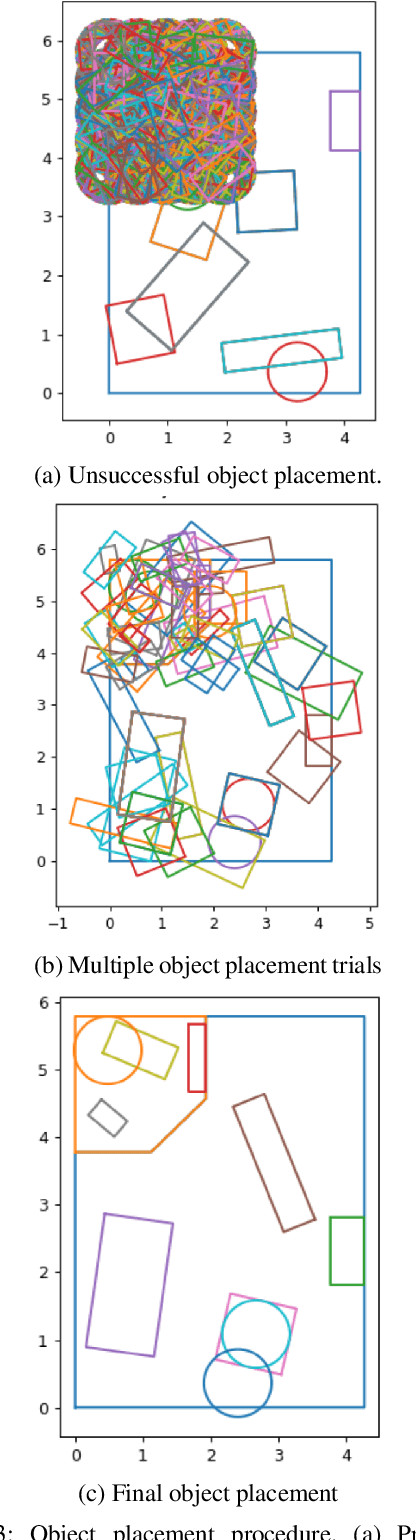
Despite years of research into patient falls in hospital rooms, falls and related injuries remain a serious concern to patient safety. In this work, we formulate a gradient-free constrained optimization problem to generate and reconfigure the hospital room interior layout to minimize the risk of falls. We define a cost function built on a hospital room fall model that takes into account the supportive or hazardous effect of the patient's surrounding objects, as well as simulated patient trajectories inside the room. We define a constraint set that ensures the functionality of the generated room layouts in addition to conforming to architectural guidelines. We solve this problem efficiently using a variant of simulated annealing. We present results for two real-world hospital room types and demonstrate a significant improvement of 18% on average in patient fall risk when compared with a traditional hospital room layout and 41% when compared with randomly generated layouts.
Comparing Piezoresistive Substrates for Tactile Sensing in Dexterous Hands
Nov 11, 2020

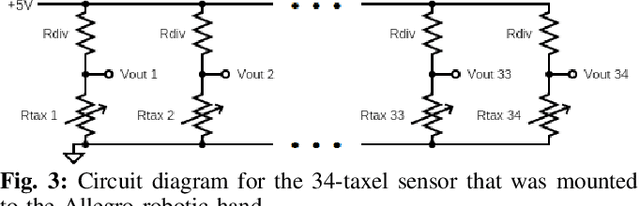

While tactile skins have been shown to be useful for detecting collisions between a robotic arm and its environment, they have not been extensively used for improving robotic grasping and in-hand manipulation. We propose a novel sensor design for use in covering existing multi-fingered robot hands. We analyze the performance of four different piezoresistive materials using both fabric and anti-static foam substrates in benchtop experiments. We find that although the piezoresistive foam was designed as packing material and not for use as a sensing substrate, it performs comparably with fabrics specifically designed for this purpose. While these results demonstrate the potential of piezoresistive foams for tactile sensing applications, they do not fully characterize the efficacy of these sensors for use in robot manipulation. As such, we use a high density foam substrate to develop a scalable tactile skin that can be attached to the palm of a robotic hand. We demonstrate several robotic manipulation tasks using this sensor to show its ability to reliably detect and localize contact, as well as analyze contact patterns during grasping and transport tasks.
Planning under Uncertainty to Goal Distributions
Nov 09, 2020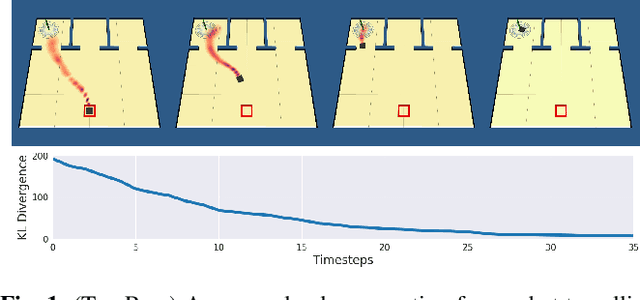
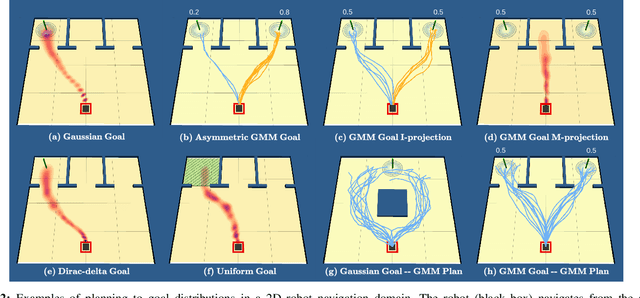

Goal spaces for planning problems are typically conceived of as subsets of the state space. It is common to select a particular goal state to plan to, and the agent monitors its progress to the goal with a distance function defined over the state space. Due to numerical imprecision, state uncertainty, and stochastic dynamics, the agent will be unable to arrive at a particular state in a verifiable manner. It is therefore common to consider a goal achieved if the agent reaches a state within a small distance threshold to the goal. This approximation fails to explicitly account for the agent's state uncertainty. Point-based goals further do not accommodate goal uncertainty that arises when goals are estimated in a data-driven way. We argue that goal distributions are a more appropriate goal representation and present a novel approach to planning under uncertainty to goal distributions. We use the unscented transform to propagate state uncertainty under stochastic dynamics and use cross-entropy method to minimize the Kullback-Leibler divergence between the current state distribution and the goal distribution. We derive reductions of our cost function to commonly used goal-reaching costs such as weighted Euclidean distance, goal set indicators, chance-constrained goal sets, and maximum expectation of reaching a goal point. We explore different combinations of goal distributions, planner distributions, and divergence to illustrate behaviors achievable in our framework.
Risk-Aware Decision Making in Service Robots to Minimize Risk of Patient Falls in Hospitals
Oct 16, 2020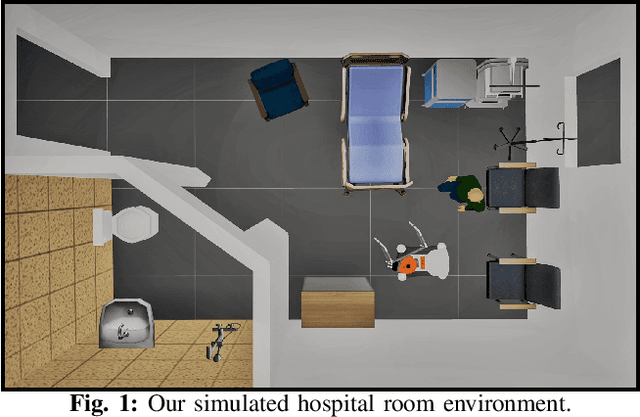
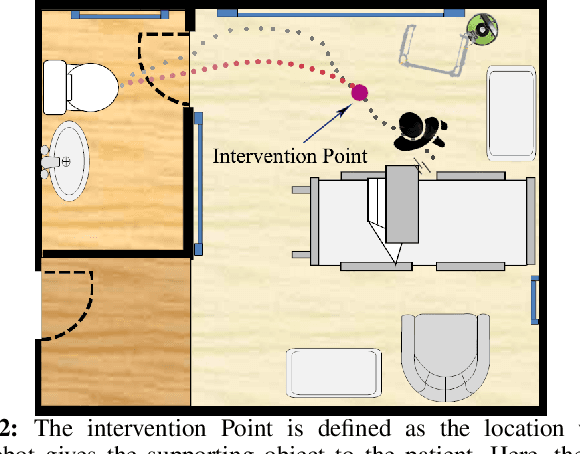
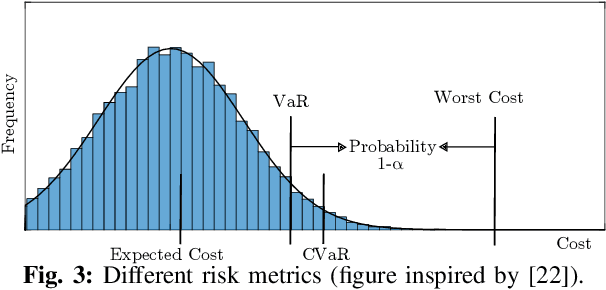
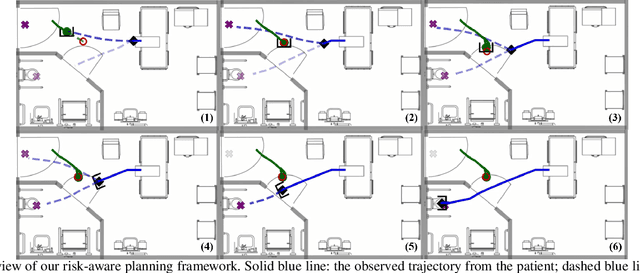
Planning under uncertainty is a crucial capability for autonomous systems to operate reliably in uncertain and dynamic environments. The concern of patient safety becomes even more critical in healthcare settings where robots interact with humans. In this paper, we propose a novel risk-aware planning framework to minimize the risk of patient falls by providing a patient with an assistive device. Our approach combines learning-based prediction with model-based control to plan for the fall prevention tasks. This provides advantages compared to end-to-end learning methods in which the robot's performance is limited to specific scenarios, or purely model-based approaches that use relatively simple function approximators and are prone to high modeling errors. We compare two different risk metrics and the combination of them and report the results from various simulated scenarios. The results show that using the proposed cost function, the robot can plan interventions to avoid high fall score events.