 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-based Video Editing via Multi-Modal Multi-Level Transformer
Apr 02, 2021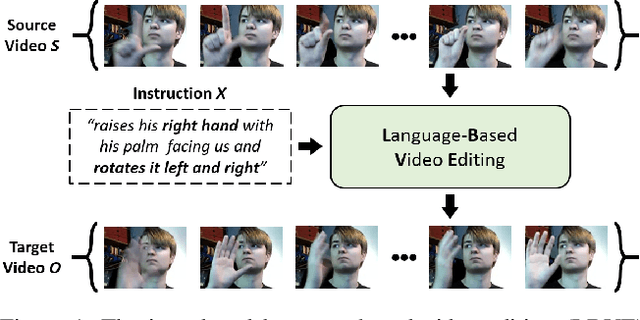
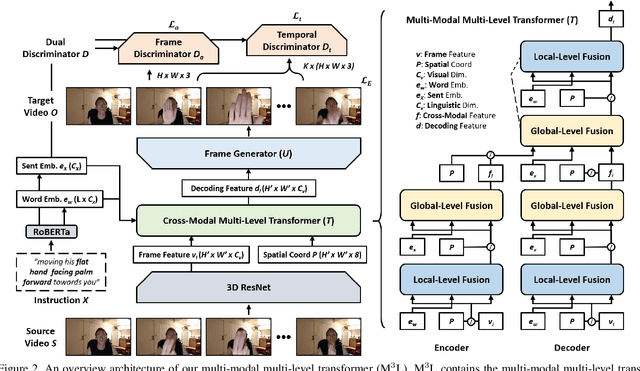

Video editing tools are widely used nowadays for digital design. Although the demand for these tools is high, the prior knowledge required makes it difficult for novices to get started. Systems that could follow natural language instructions to perform automatic editing would significantly improve accessibility. This paper introduces the language-based video editing (LBVE) task, which allows the model to edit, guided by text instruction, a source video into a target video. LBVE contains two features: 1) the scenario of the source video is preserved instead of generating a completely different video; 2) the semantic is presented differently in the target video, and all changes are controlled by the given instruction. We propose a Multi-Modal Multi-Level Transformer (M$^3$L-Transformer) to carry out LBVE. The M$^3$L-Transformer dynamically learns the correspondence between video perception and language semantic at different levels, which benefits both the video understanding and video frame synthesis. We build three new datasets for evaluation, including two diagnostic and one from natural videos with human-labeled text. Extensive experimental results show that M$^3$L-Transformer is effective for video editing and that LBVE can lead to a new field toward vision-and-language research.
DOC2PPT: Automatic Presentation Slides Generation from Scientific Documents
Feb 14, 2021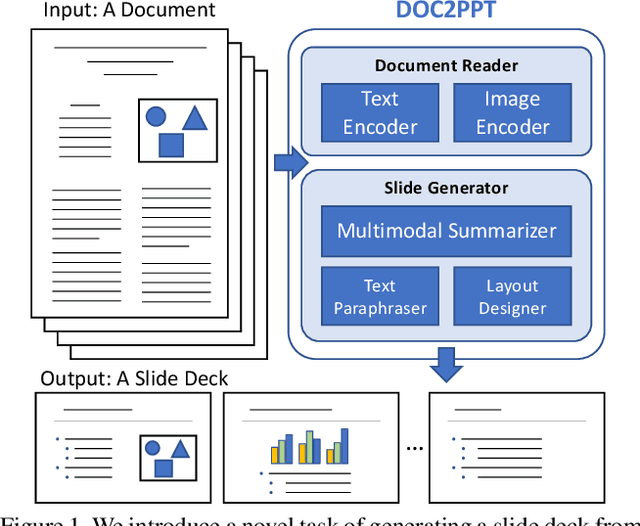

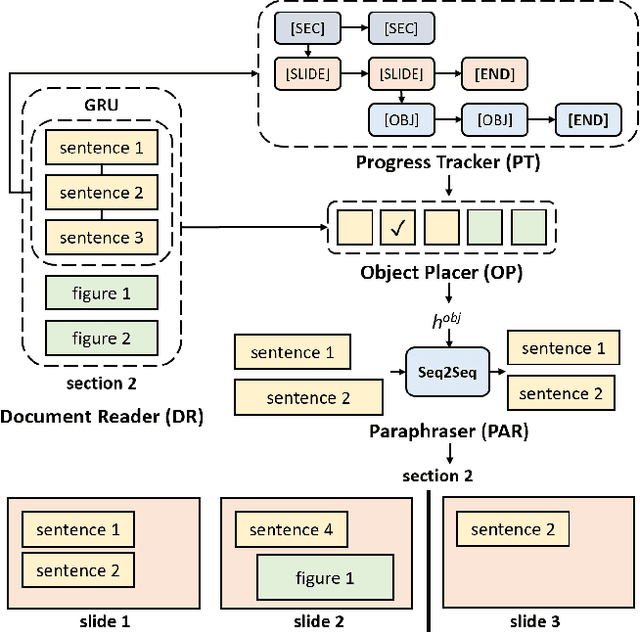
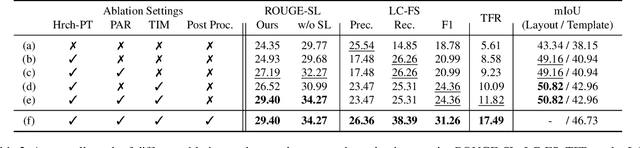
Creating presentation materials requires complex multimodal reasoning skills to summarize key concepts and arrange them in a logical and visually pleasing manner. Can machines learn to emulate this laborious process? We present a novel task and approach for document-to-slide generation. Solving this involves document summarization, image and text retrieval, slide structure and layout prediction to arrange key elements in a form suitable for presentation. We propose a hierarchical sequence-to-sequence approach to tackle our task in an end-to-end manner. Our approach exploits the inherent structures within documents and slides and incorporates paraphrasing and layout prediction modules to generate slides. To help accelerate research in this domain, we release a dataset about 6K paired documents and slide decks used in our experiments. We show that our approach outperforms strong baselines and produces slides with rich content and aligned imagery.
L2C: Describing Visual Differences Needs Semantic Understanding of Individuals
Feb 03, 2021
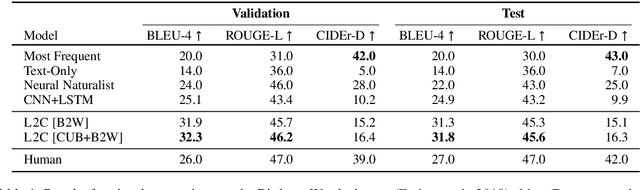
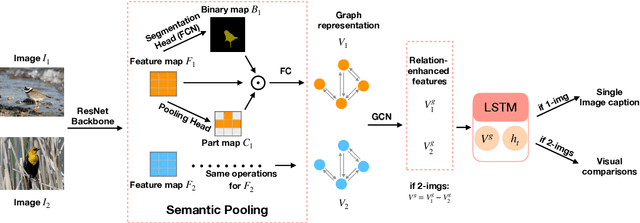

Recent advances in language and vision push forward the research of captioning a single image to describing visual differences between image pairs. Suppose there are two images, I_1 and I_2, and the task is to generate a description W_{1,2} comparing them, existing methods directly model { I_1, I_2 } -> W_{1,2} mapping without the semantic understanding of individuals. In this paper, we introduce a Learning-to-Compare (L2C) model, which learns to understand the semantic structures of these two images and compare them while learning to describe each one. We demonstrate that L2C benefits from a comparison between explicit semantic representations and single-image captions, and generalizes better on the new testing image pairs. It outperforms the baseline on both automatic evaluation and human evaluation for the Birds-to-Words dataset.
H-FND: Hierarchical False-Negative Denoising for Distant Supervision Relation Extraction
Dec 14, 2020
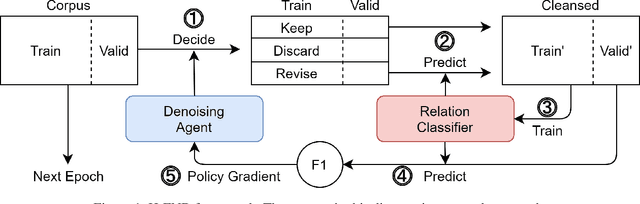
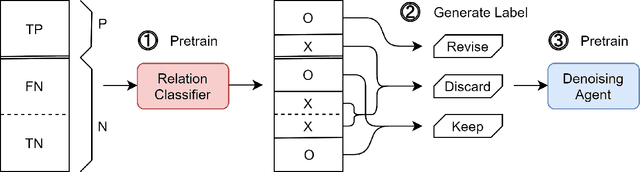
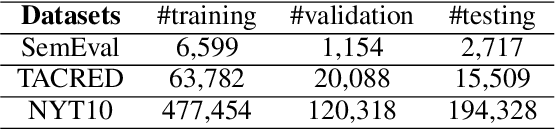
Although distant supervision automatically generates training data for relation extraction, it also introduces false-positive (FP) and false-negative (FN) training instances to the generated datasets. Whereas both types of errors degrade the final model performance, previous work on distant supervision denoising focuses more on suppressing FP noise and less on resolving the FN problem. We here propose H-FND, a hierarchical false-negative denoising framework for robust distant supervision relation extraction, as an FN denoising solution. H-FND uses a hierarchical policy which first determines whether non-relation (NA) instances should be kept, discarded, or revised during the training process. For those learning instances which are to be revised, the policy further reassigns them appropriate relations, making them better training inputs. Experiments on SemEval-2010 and TACRED were conducted with controlled FN ratios that randomly turn the relations of training and validation instances into negatives to generate FN instances. In this setting, H-FND can revise FN instances correctly and maintains high F1 scores even when 50% of the instances have been turned into negatives. Experiment on NYT10 is further conducted to shows that H-FND is applicable in a realistic setting.
SSCR: Iterative Language-Based Image Editing via Self-Supervised Counterfactual Reasoning
Sep 29, 2020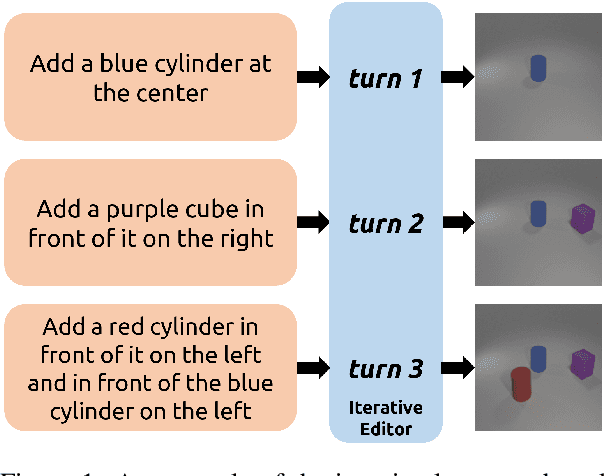

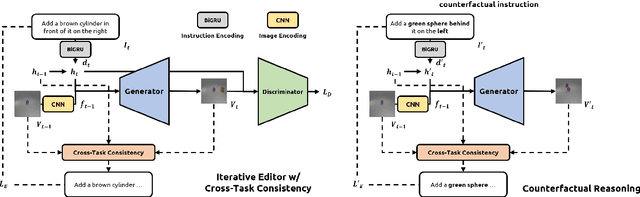
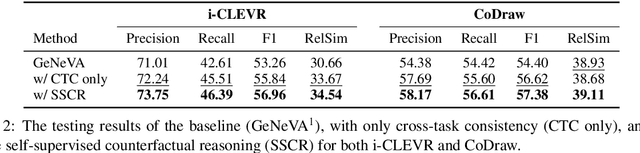
Iterative Language-Based Image Editing (IL-BIE) tasks follow iterative instructions to edit images step by step. Data scarcity is a significant issue for ILBIE as it is challenging to collect large-scale examples of images before and after instruction-based changes. However, humans still accomplish these editing tasks even when presented with an unfamiliar image-instruction pair. Such ability results from counterfactual thinking and the ability to think about alternatives to events that have happened already. In this paper, we introduce a Self-Supervised Counterfactual Reasoning (SSCR) framework that incorporates counterfactual thinking to overcome data scarcity. SSCR allows the model to consider out-of-distribution instructions paired with previous images. With the help of cross-task consistency (CTC), we train these counterfactual instructions in a self-supervised scenario. Extensive results show that SSCR improves the correctness of ILBIE in terms of both object identity and position, establishing a new state of the art (SOTA) on two IBLIE datasets (i-CLEVR and CoDraw). Even with only 50% of the training data, SSCR achieves a comparable result to using complete data.
Multimodal Text Style Transfer for Outdoor Vision-and-Language Navigation
Jul 01, 2020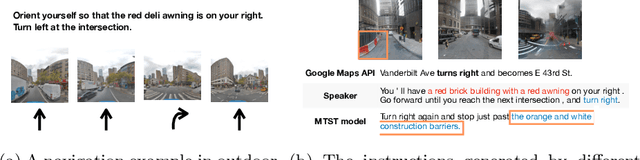
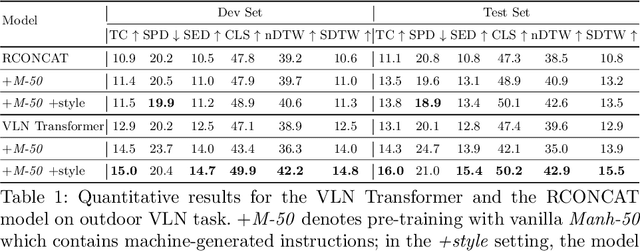
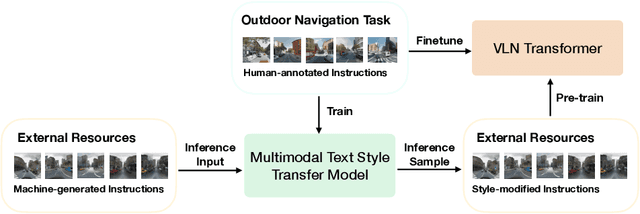

In the vision-and-language navigation (VLN) task, an agent follows natural language instructions and navigate in visual environments. Compared to the indoor navigation task that has been broadly studied, navigation in real-life outdoor environments remains a significant challenge with its complicated visual inputs and an insufficient amount of instructions that illustrate the intricate urban scenes. In this paper, we introduce a Multimodal Text Style Transfer (MTST) learning approach to mitigate the problem of data scarcity in outdoor navigation tasks by effectively leveraging external multimodal resources. We first enrich the navigation data by transferring the style of the instructions generated by Google Maps API, then pre-train the navigator with the augmented external outdoor navigation dataset. Experimental results show that our MTST learning approach is model-agnostic, and our MTST approach significantly outperforms the baseline models on the outdoor VLN task, improving task completion rate by 22\% relatively on the test set and achieving new state-of-the-art performance.
Counterfactual Vision-and-Language Navigation via Adversarial Path Sampling
Nov 17, 2019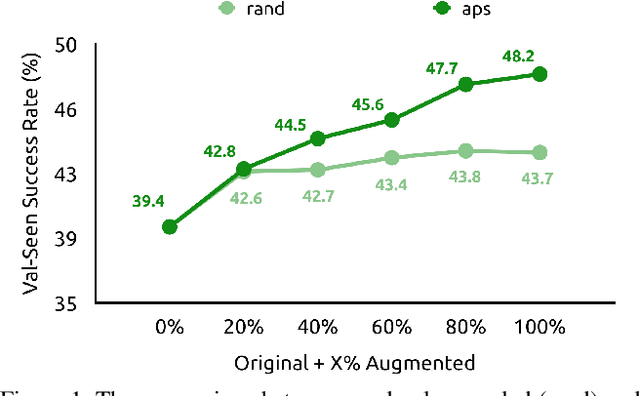
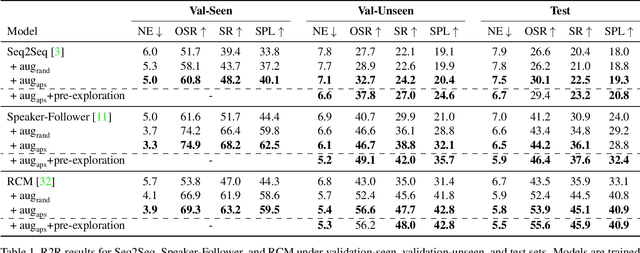
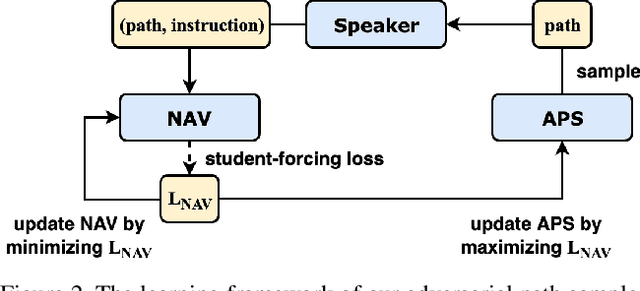
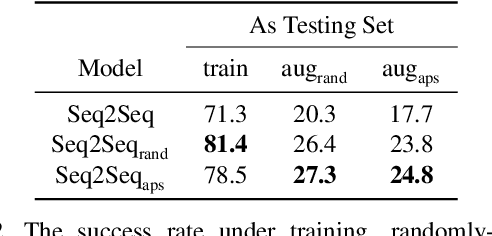
Vision-and-Language Navigation (VLN) is a task where agents must decide how to move through a 3D environment to reach a goal by grounding natural language instructions to the visual surroundings. One of the problems of the VLN task is data scarcity since it is difficult to collect enough navigation paths with human-annotated instructions for interactive environments. In this paper, we explore the use of counterfactual thinking as a human-inspired data augmentation method that results in robust models. Counterfactual thinking is a concept that describes the human propensity to create possible alternatives to life events that have already occurred. We propose an adversarial-driven counterfactual reasoning model that can consider effective conditions instead of low-quality augmented data. In particular, we present a model-agnostic adversarial path sampler (APS) that learns to sample challenging paths that force the navigator to improve based on the navigation performance. APS also serves to do pre-exploration of unseen environments to strengthen the model's ability to generalize. We evaluate the influence of APS on the performance of different VLN baseline models using the room-to-room dataset (R2R). The results show that the adversarial training process with our proposed APS benefits VLN models under both seen and unseen environments. And the pre-exploration process can further gain additional improvements under unseen environments.
Why Attention? Analyzing and Remedying BiLSTM Deficiency in Modeling Cross-Context for NER
Oct 07, 2019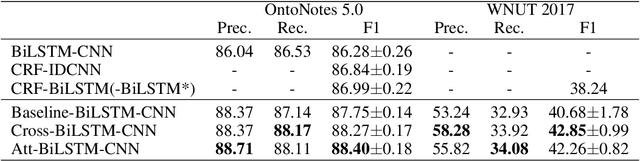



State-of-the-art approaches of NER have used sequence-labeling BiLSTM as a core module. This paper formally shows the limitation of BiLSTM in modeling cross-context patterns. Two types of simple cross-structures -- self-attention and Cross-BiLSTM -- are shown to effectively remedy the problem. On both OntoNotes 5.0 and WNUT 2017, clear and consistent improvements are achieved over bare-bone models, up to 8.7% on some of the multi-token mentions. In-depth analyses across several aspects of the improvements, especially the identification of multi-token mentions, are further given.
Remedying BiLSTM-CNN Deficiency in Modeling Cross-Context for NER
Aug 29, 2019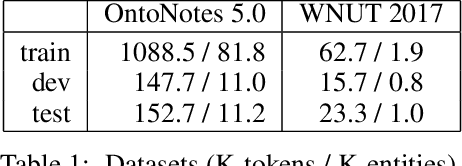

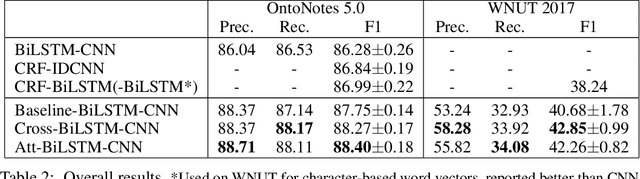
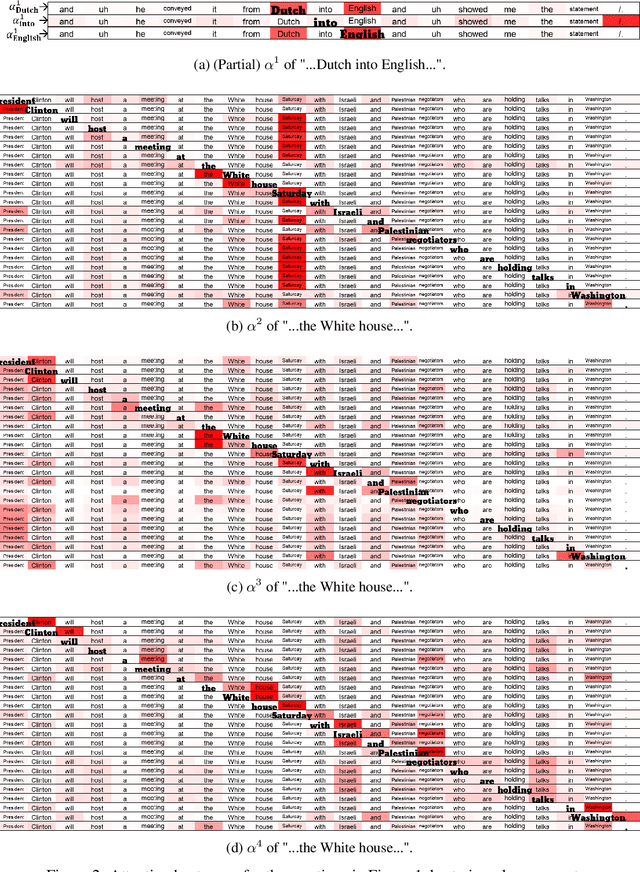
Recent researches prevalently used BiLSTM-CNN as a core module for NER in a sequence-labeling setup. This paper formally shows the limitation of BiLSTM-CNN encoders in modeling cross-context patterns for each word, i.e., patterns crossing past and future for a specific time step. Two types of cross-structures are used to remedy the problem: A BiLSTM variant with cross-link between layers; a multi-head self-attention mechanism. These cross-structures bring consistent improvements across a wide range of NER domains for a core system using BiLSTM-CNN without additional gazetteers, POS taggers, language-modeling, or multi-task supervision. The model surpasses comparable previous models on OntoNotes 5.0 and WNUT 2017 by 1.4% and 4.6%, especially improving emerging, complex, confusing, and multi-token entity mentions, showing the importance of remedying the core module of NER.
Visual Relationship Prediction via Label Clustering and Incorporation of Depth Information
Sep 09, 2018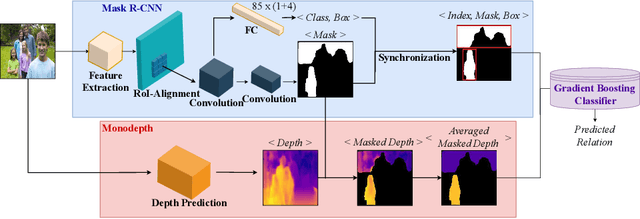
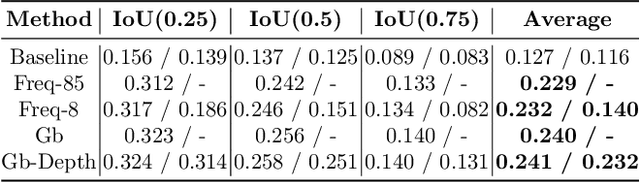
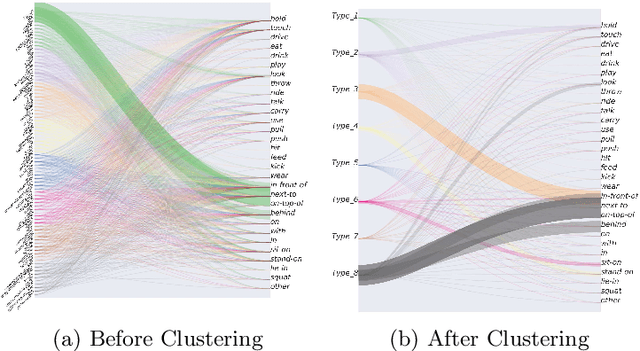
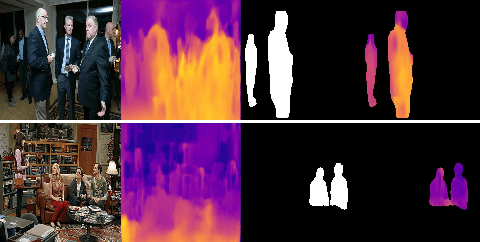
In this paper, we investigate the use of an unsupervised label clustering technique and demonstrate that it enables substantial improvements in visual relationship prediction accuracy on the Person in Context (PIC) dataset. We propose to group object labels with similar patterns of relationship distribution in the dataset into fewer categories. Label clustering not only mitigates both the large classification space and class imbalance issues, but also potentially increases data samples for each clustered category. We further propose to incorporate depth information as an additional feature into the instance segmentation model. The additional depth prediction path supplements the relationship prediction model in a way that bounding boxes or segmentation masks are unable to deliver. We have rigorously evaluated the proposed techniques and performed various ablation analysis to validate the benefits of them.