 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Very Large Pretrained Language Models Learn Storytelling With A Few Examples?
Jan 24, 2023



While pre-trained language models can generate individually fluent sentences for automatic story generation, they struggle to generate stories that are coherent, sensible and interesting. Current state-of-the-art (SOTA) story generation models explore using higher-level features such as plots or commonsense knowledge to improve the quality of generated stories. Prompt-based learning using very large pre-trained language models (VLPLMs) such as GPT3 has demonstrated impressive performance even across various NLP tasks. In this paper, we present an extensive study using automatic and human evaluation to compare the story generation capability of VLPLMs to those SOTA models in three different datasets where stories differ in style, register and length. Our results show that VLPLMs generate much higher quality stories than other story generation models, and to a certain extent rival human authors, although preliminary investigation also reveals that they tend to ``plagiarise'' real stories in scenarios that involve world knowledge.
A Survey for Efficient Open Domain Question Answering
Nov 15, 2022Open domain question answering (ODQA) is a longstanding task aimed at answering factual questions from a large knowledge corpus without any explicit evidence in natural language processing (NLP). Recent works have predominantly focused on improving the answering accuracy and achieved promising progress. However, higher accuracy often comes with more memory consumption and inference latency, which might not necessarily be efficient enough for direct deployment in the real world. Thus, a trade-off between accuracy, memory consumption and processing speed is pursued. In this paper, we provide a survey of recent advances in the efficiency of ODQA models. We walk through the ODQA models and conclude the core techniques on efficiency. Quantitative analysis on memory cost, processing speed, accuracy and overall comparison are given. We hope that this work would keep interested scholars informed of the advances and open challenges in ODQA efficiency research, and thus contribute to the further development of ODQA efficiency.
Systematic Evaluation of Predictive Fairness
Oct 17, 2022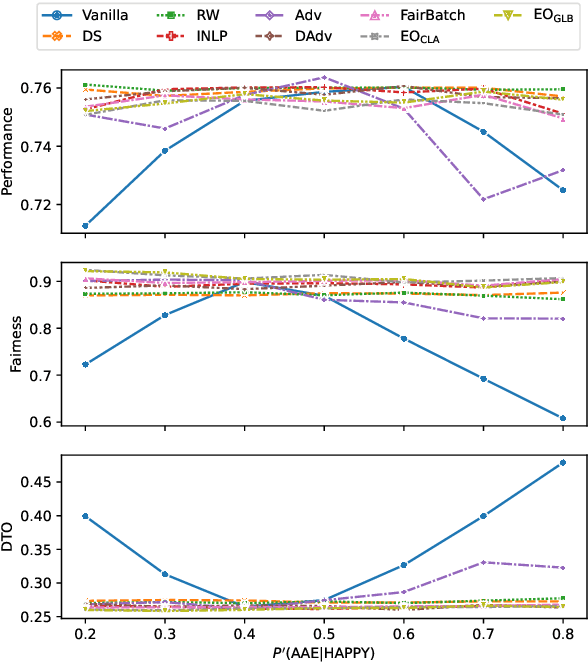
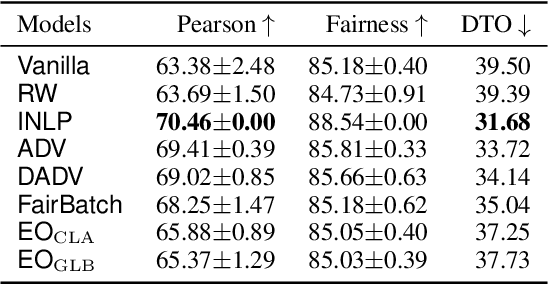
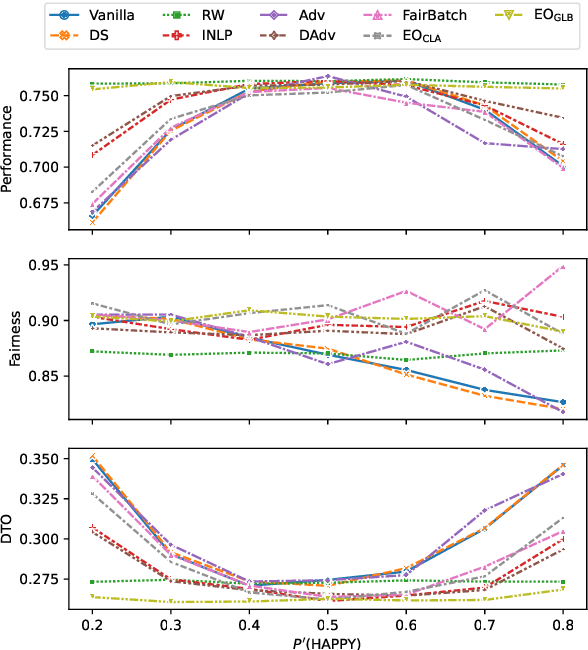
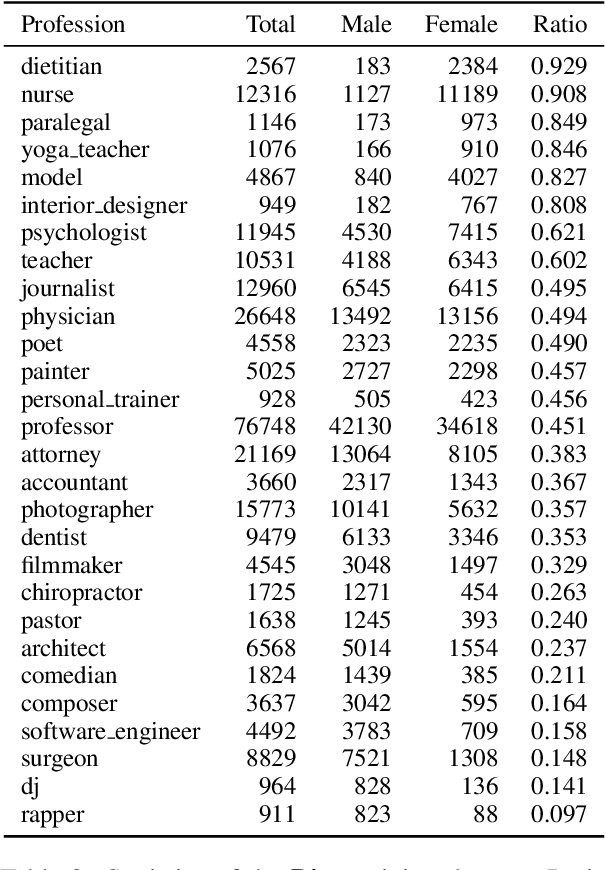
Mitigating bias in training on biased datasets is an important open problem. Several techniques have been proposed, however the typical evaluation regime is very limited, considering very narrow data conditions. For instance, the effect of target class imbalance and stereotyping is under-studied. To address this gap, we examine the performance of various debiasing methods across multiple tasks, spanning binary classification (Twitter sentiment), multi-class classification (profession prediction), and regression (valence prediction). Through extensive experimentation, we find that data conditions have a strong influence on relative model performance, and that general conclusions cannot be drawn about method efficacy when evaluating only on standard datasets, as is current practice in fairness research.
Not another Negation Benchmark: The NaN-NLI Test Suite for Sub-clausal Negation
Oct 06, 2022
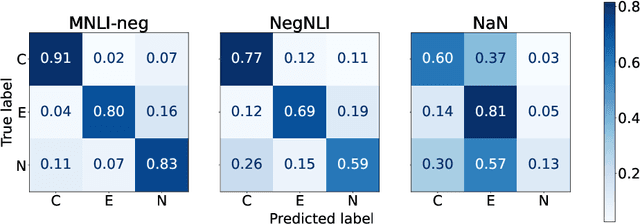
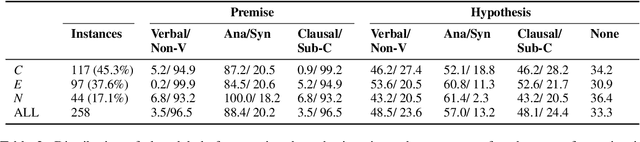
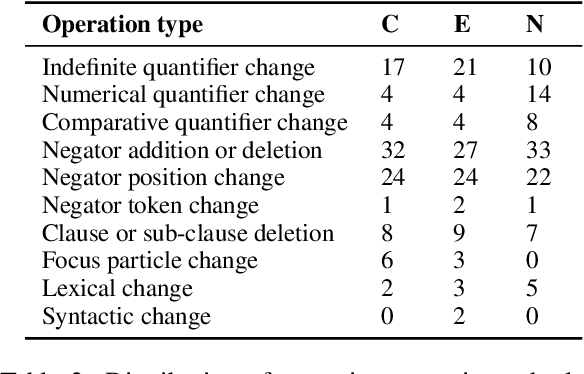
Negation is poorly captured by current language models, although the extent of this problem is not widely understood. We introduce a natural language inference (NLI) test suite to enable probing the capabilities of NLP methods, with the aim of understanding sub-clausal negation. The test suite contains premise--hypothesis pairs where the premise contains sub-clausal negation and the hypothesis is constructed by making minimal modifications to the premise in order to reflect different possible interpretations. Aside from adopting standard NLI labels, our test suite is systematically constructed under a rigorous linguistic framework. It includes annotation of negation types and constructions grounded in linguistic theory, as well as the operations used to construct hypotheses. This facilitates fine-grained analysis of model performance. We conduct experiments using pre-trained language models to demonstrate that our test suite is more challenging than existing benchmarks focused on negation, and show how our annotation supports a deeper understanding of the current NLI capabilities in terms of negation and quantification.
LED down the rabbit hole: exploring the potential of global attention for biomedical multi-document summarisation
Sep 19, 2022
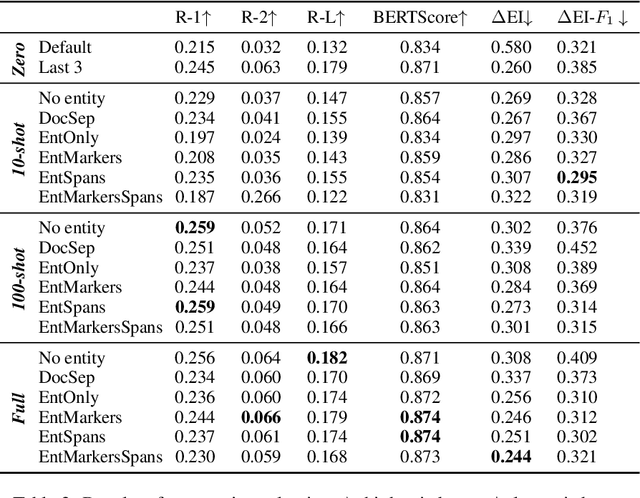
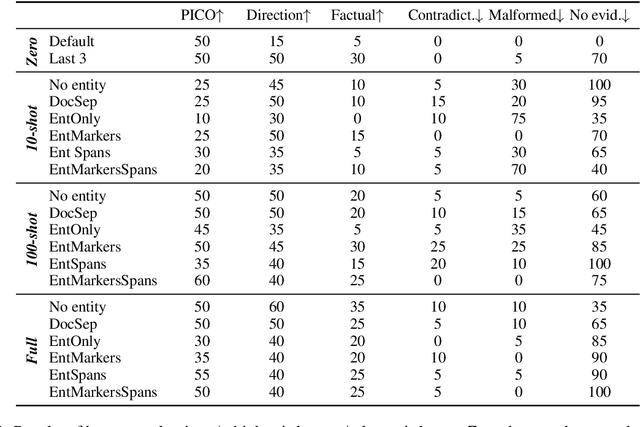
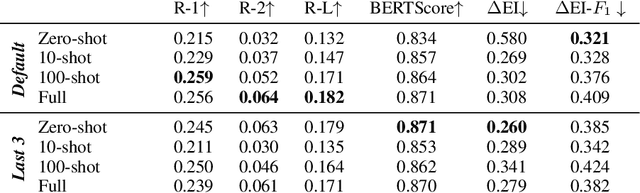
In this paper we report on our submission to the Multidocument Summarisation for Literature Review (MSLR) shared task. Specifically, we adapt PRIMERA (Xiao et al., 2022) to the biomedical domain by placing global attention on important biomedical entities in several ways. We analyse the outputs of the 23 resulting models, and report patterns in the results related to the presence of additional global attention, number of training steps, and the input configuration.
Rethinking Round-trip Translation for Automatic Machine Translation Evaluation
Sep 15, 2022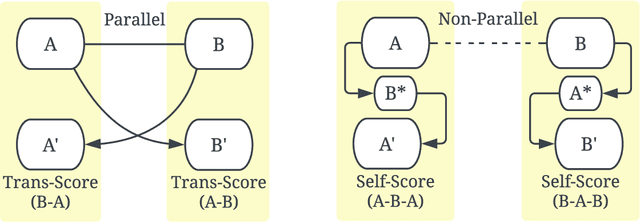
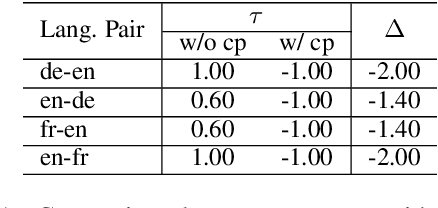
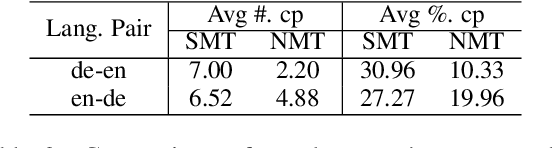
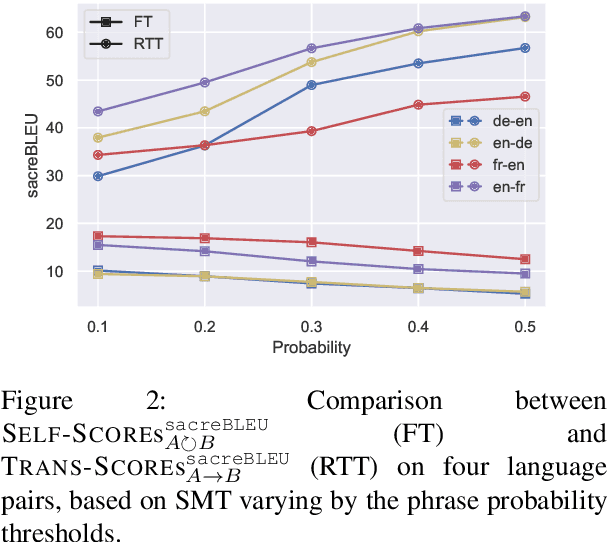
A parallel corpus is generally required to automatically evaluate the translation quality using the metrics, such as BLEU, METEOR and BERTScore. While the reference-based evaluation paradigm is widely used in many machine translation tasks, it is difficult to be applied to translation with low-resource languages, as those languages suffer from a deficiency of corpora. Round-trip translation provides an encouraging way to alleviate the urgent requirement of the parallel corpus, although it was unfortunately not observed to correlate with forwarding translation in the era of statistical machine translation. In this paper, we firstly observe that forward translation quality consistently correlates to corresponding round-trip translation quality in the scope of neural machine translation. Then, we carefully analyse and unveil the reason for the contradictory results on statistical machine translation systems. Secondly, we propose a simple yet effective regression method to predict the performance of forward translation scores based on round-trip translation scores for various language pairs, including those between very low-resource languages. We conduct extensive experiments to show the effectiveness and robustness of the predictive models on 1,000+ language pairs. Finally, we test our method on challenging settings, such as predicting scores: i) for unseen language pairs in training and ii) on real-world WMT shared tasks but in new domains. The extensive experiments demonstrate the robustness and utility of our approach. We believe our work will inspire works on very low-resource multilingual machine translation.
Improving negation detection with negation-focused pre-training
May 09, 2022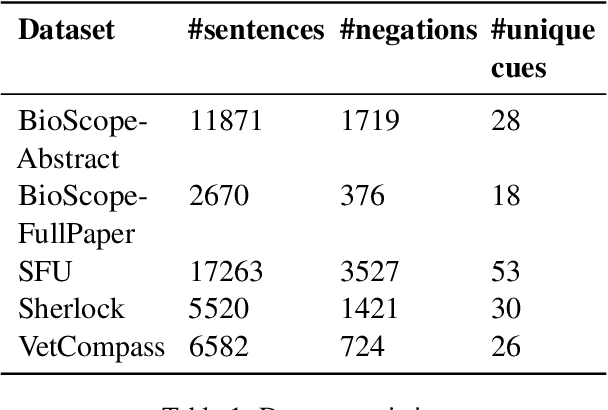


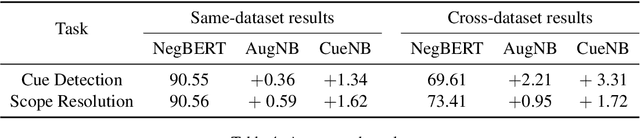
Negation is a common linguistic feature that is crucial in many language understanding tasks, yet it remains a hard problem due to diversity in its expression in different types of text. Recent work has shown that state-of-the-art NLP models underperform on samples containing negation in various tasks, and that negation detection models do not transfer well across domains. We propose a new negation-focused pre-training strategy, involving targeted data augmentation and negation masking, to better incorporate negation information into language models. Extensive experiments on common benchmarks show that our proposed approach improves negation detection performance and generalizability over the strong baseline NegBERT (Khandewal and Sawant, 2020).
Optimising Equal Opportunity Fairness in Model Training
May 05, 2022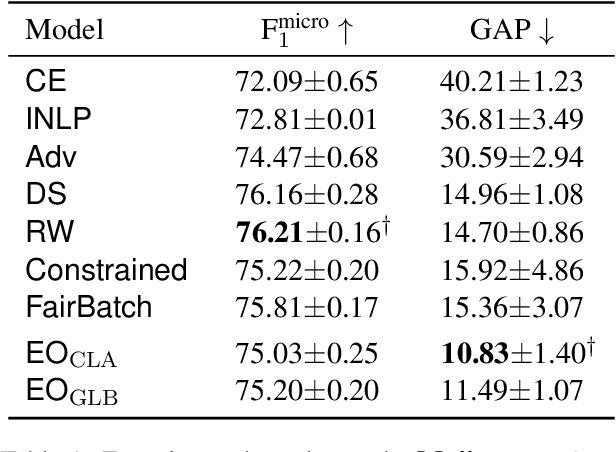
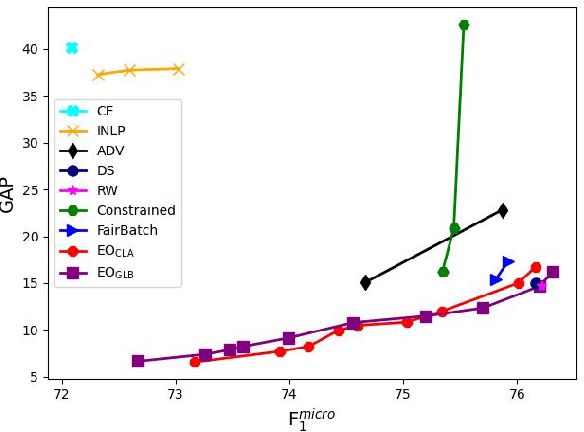
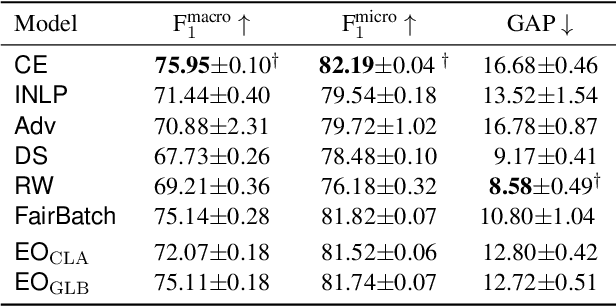
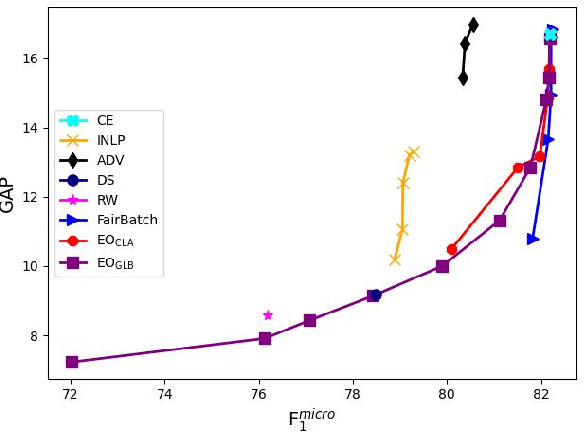
Real-world datasets often encode stereotypes and societal biases. Such biases can be implicitly captured by trained models, leading to biased predictions and exacerbating existing societal preconceptions. Existing debiasing methods, such as adversarial training and removing protected information from representations, have been shown to reduce bias. However, a disconnect between fairness criteria and training objectives makes it difficult to reason theoretically about the effectiveness of different techniques. In this work, we propose two novel training objectives which directly optimise for the widely-used criterion of {\it equal opportunity}, and show that they are effective in reducing bias while maintaining high performance over two classification tasks.
fairlib: A Unified Framework for Assessing and Improving Classification Fairness
May 04, 2022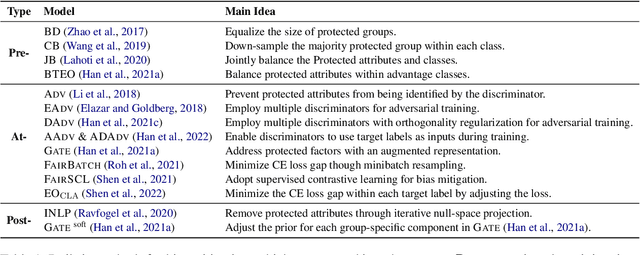
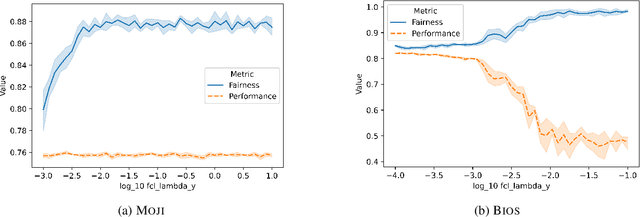
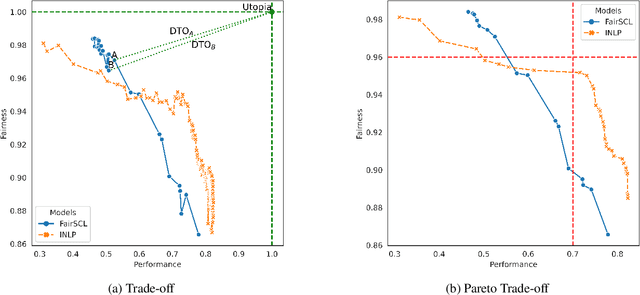
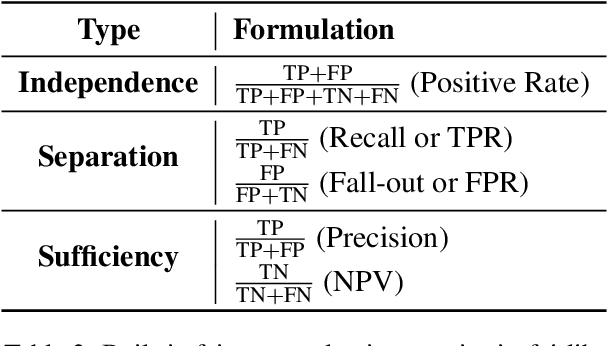
This paper presents fairlib, an open-source framework for assessing and improving classification fairness. It provides a systematic framework for quickly reproducing existing baseline models, developing new methods, evaluating models with different metrics, and visualizing their results. Its modularity and extensibility enable the framework to be used for diverse types of inputs, including natural language, images, and audio. In detail, we implement 14 debiasing methods, including pre-processing, at-training-time, and post-processing approaches. The built-in metrics cover the most commonly used fairness criterion and can be further generalized and customized for fairness evaluation.
Towards Equal Opportunity Fairness through Adversarial Learning
Mar 12, 2022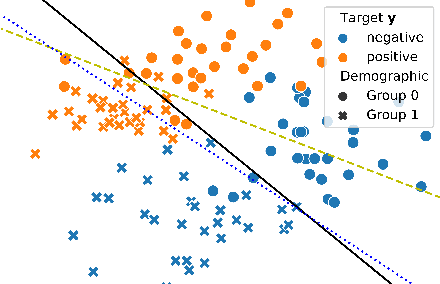
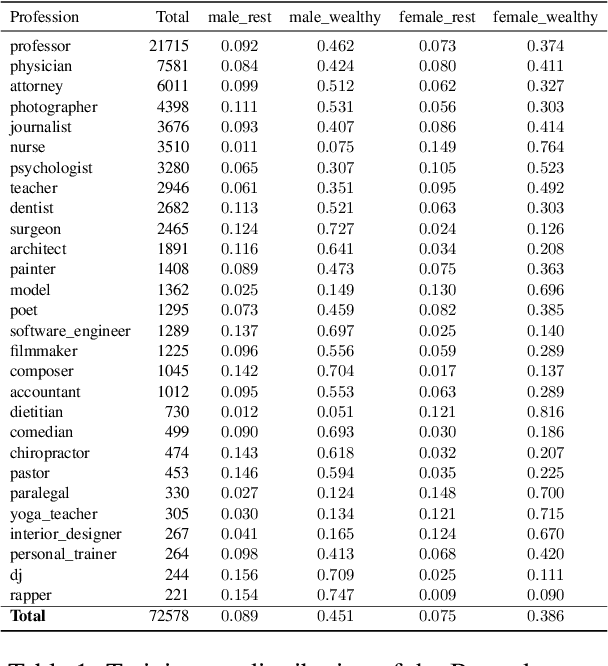
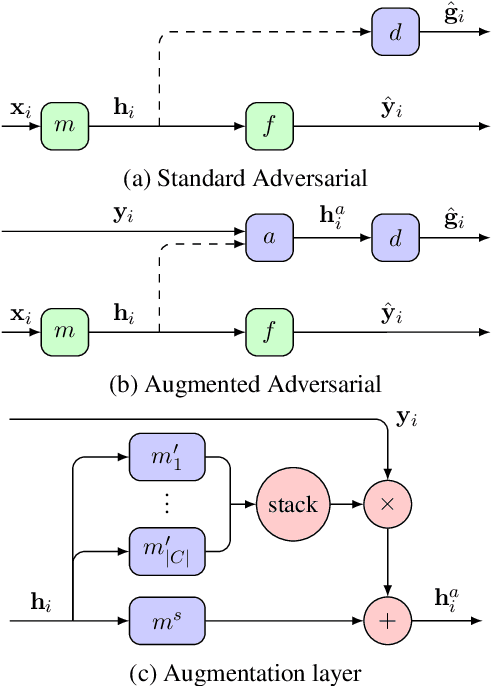
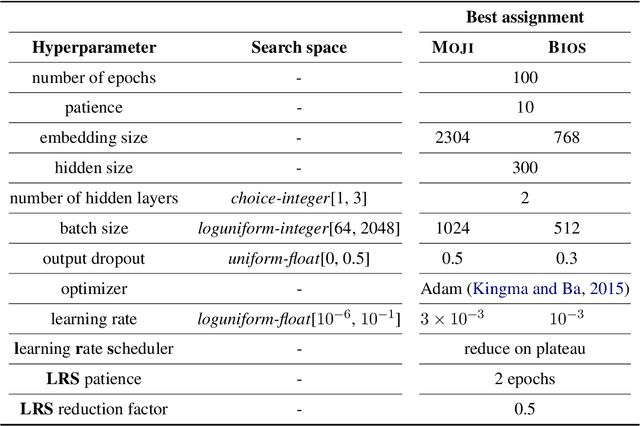
Adversarial training is a common approach for bias mitigation in natural language processing. Although most work on debiasing is motivated by equal opportunity, it is not explicitly captured in standard adversarial training. In this paper, we propose an augmented discriminator for adversarial training, which takes the target class as input to create richer features and more explicitly model equal opportunity. Experimental results over two datasets show that our method substantially improves over standard adversarial debiasing methods, in terms of the performance--fairness trade-off.