 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLUKE: A Linguistically-Driven and Task-Agnostic Framework for Robustness Evaluation
Apr 24, 2025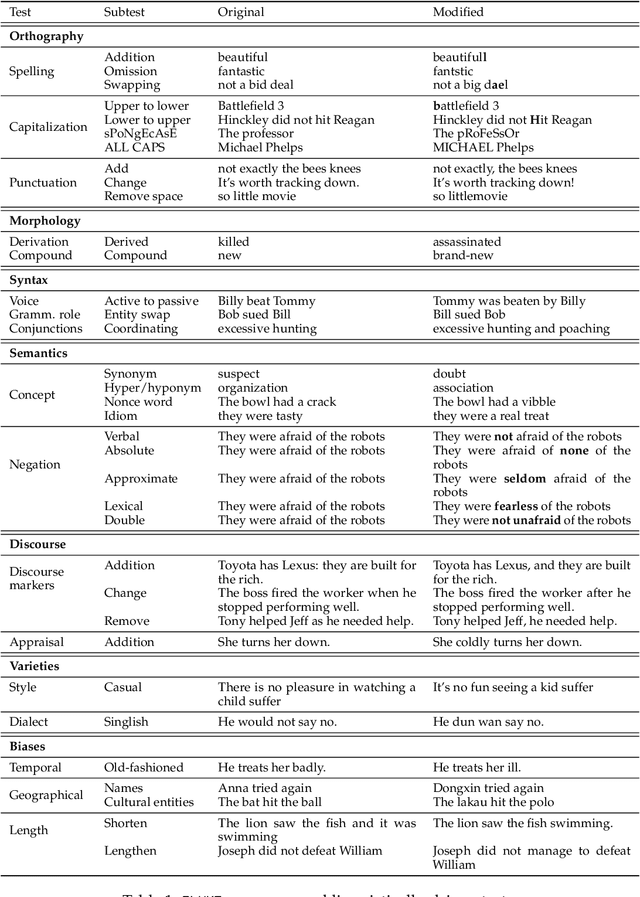
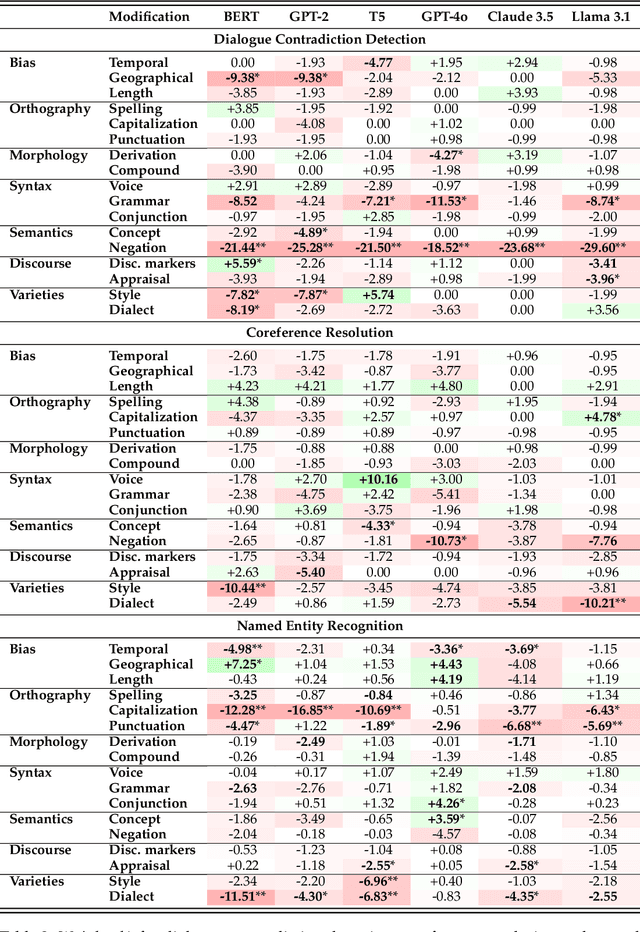

We present FLUKE (Framework for LingUistically-driven and tasK-agnostic robustness Evaluation), a task-agnostic framework for assessing model robustness through systematic minimal variations of test data. FLUKE introduces controlled variations across linguistic levels - from orthography to dialect and style varieties - and leverages large language models (LLMs) with human validation to generate modifications. We demonstrate FLUKE's utility by evaluating both fine-tuned models and LLMs across four diverse NLP tasks, and reveal that (1) the impact of linguistic variations is highly task-dependent, with some tests being critical for certain tasks but irrelevant for others; (2) while LLMs have better overall robustness compared to fine-tuned models, they still exhibit significant brittleness to certain linguistic variations; (3) all models show substantial vulnerability to negation modifications across most tasks. These findings highlight the importance of systematic robustness testing for understanding model behaviors.
Not another Negation Benchmark: The NaN-NLI Test Suite for Sub-clausal Negation
Oct 06, 2022
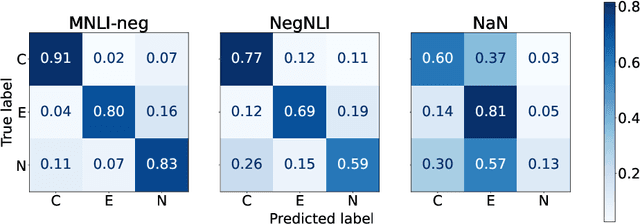
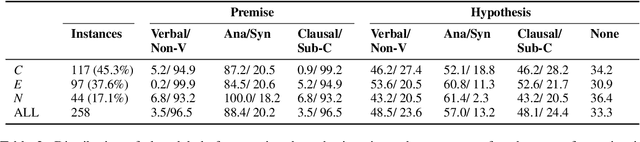
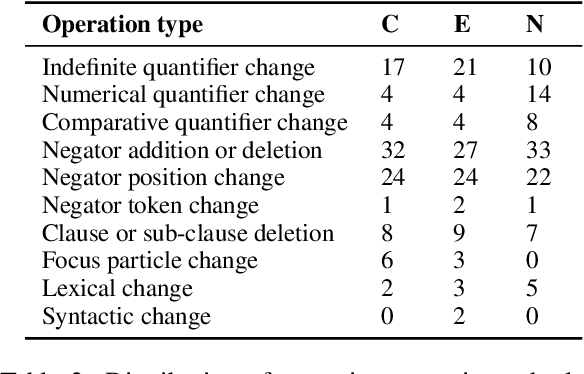
Negation is poorly captured by current language models, although the extent of this problem is not widely understood. We introduce a natural language inference (NLI) test suite to enable probing the capabilities of NLP methods, with the aim of understanding sub-clausal negation. The test suite contains premise--hypothesis pairs where the premise contains sub-clausal negation and the hypothesis is constructed by making minimal modifications to the premise in order to reflect different possible interpretations. Aside from adopting standard NLI labels, our test suite is systematically constructed under a rigorous linguistic framework. It includes annotation of negation types and constructions grounded in linguistic theory, as well as the operations used to construct hypotheses. This facilitates fine-grained analysis of model performance. We conduct experiments using pre-trained language models to demonstrate that our test suite is more challenging than existing benchmarks focused on negation, and show how our annotation supports a deeper understanding of the current NLI capabilities in terms of negation and quantification.
LED down the rabbit hole: exploring the potential of global attention for biomedical multi-document summarisation
Sep 19, 2022
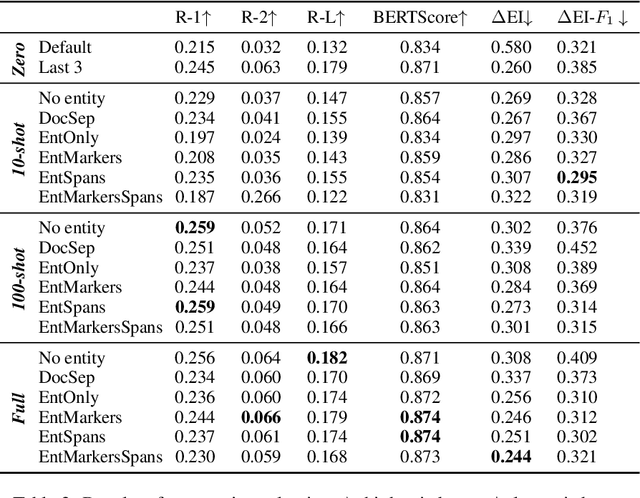
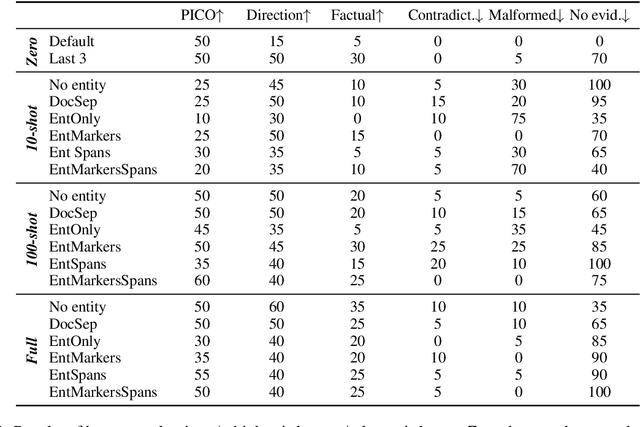
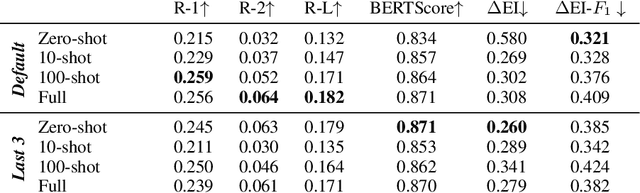
In this paper we report on our submission to the Multidocument Summarisation for Literature Review (MSLR) shared task. Specifically, we adapt PRIMERA (Xiao et al., 2022) to the biomedical domain by placing global attention on important biomedical entities in several ways. We analyse the outputs of the 23 resulting models, and report patterns in the results related to the presence of additional global attention, number of training steps, and the input configuration.