 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAWP: Activation-Aware Weight Pruning and Quantization with Projected Gradient Descent
Jun 11, 2025To address the enormous size of Large Language Models (LLMs), model compression methods, such as quantization and pruning, are often deployed, especially on edge devices. In this work, we focus on layer-wise post-training quantization and pruning. Drawing connections between activation-aware weight pruning and sparse approximation problems, and motivated by the success of Iterative Hard Thresholding (IHT), we propose a unified method for Activation-aware Weight pruning and quantization via Projected gradient descent (AWP). Our experiments demonstrate that AWP outperforms state-of-the-art LLM pruning and quantization methods. Theoretical convergence guarantees of the proposed method for pruning are also provided.
TuneComp: Joint Fine-tuning and Compression for Large Foundation Models
May 27, 2025



To reduce model size during post-training, compression methods, including knowledge distillation, low-rank approximation, and pruning, are often applied after fine-tuning the model. However, sequential fine-tuning and compression sacrifices performance, while creating a larger than necessary model as an intermediate step. In this work, we aim to reduce this gap, by directly constructing a smaller model while guided by the downstream task. We propose to jointly fine-tune and compress the model by gradually distilling it to a pruned low-rank structure. Experiments demonstrate that joint fine-tuning and compression significantly outperforms other sequential compression methods.
$μ$-MoE: Test-Time Pruning as Micro-Grained Mixture-of-Experts
May 24, 2025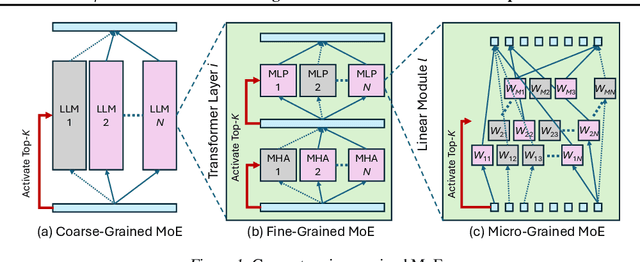
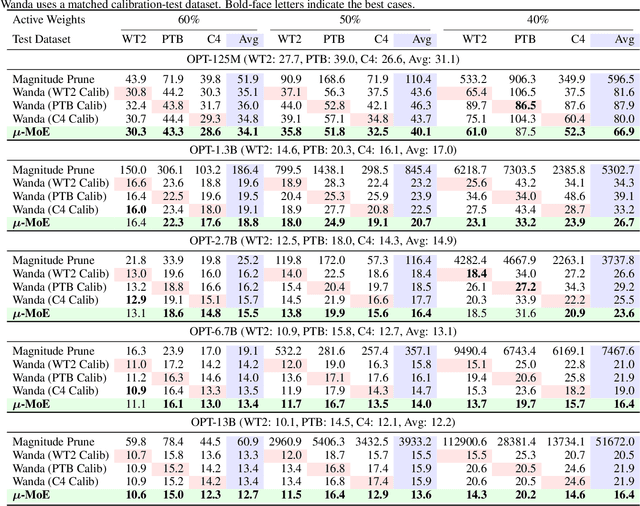
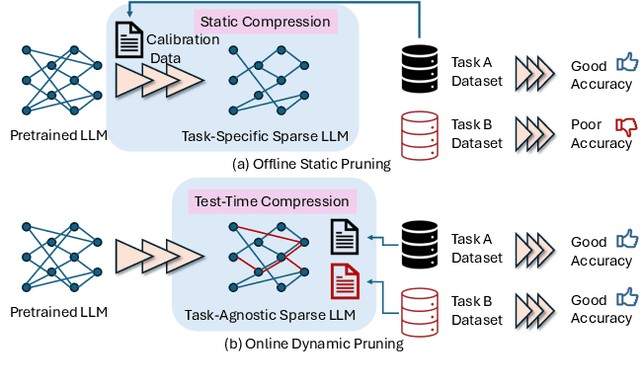
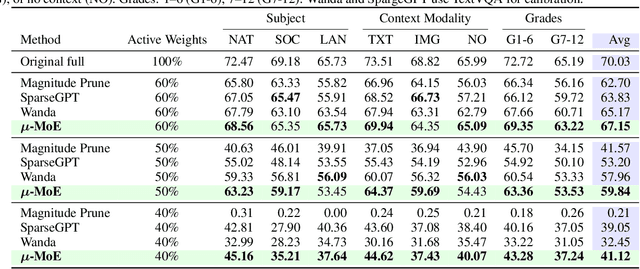
To tackle the huge computational demand of large foundation models, activation-aware compression techniques without retraining have been introduced. However, since these rely on calibration data, domain shift may arise for unknown downstream tasks. With a computationally efficient calibration, activation-aware pruning can be executed for every prompt adaptively, yet achieving reduced complexity at inference. We formulate it as a mixture of micro-experts, called $\mu$-MoE. Several experiments demonstrate that $\mu$-MoE can dynamically adapt to task/prompt-dependent structured sparsity on the fly.
LatentLLM: Attention-Aware Joint Tensor Compression
May 23, 2025Modern foundation models such as large language models (LLMs) and large multi-modal models (LMMs) require a massive amount of computational and memory resources. We propose a new framework to convert such LLMs/LMMs into a reduced-dimension latent structure. Our method extends a local activation-aware tensor decomposition to a global attention-aware joint tensor de-composition. Our framework can significantly improve the model accuracy over the existing model compression methods when reducing the latent dimension to realize computationally/memory-efficient LLMs/LLMs. We show the benefit on several benchmark including multi-modal reasoning tasks.
Range Image-Based Implicit Neural Compression for LiDAR Point Clouds
Apr 24, 2025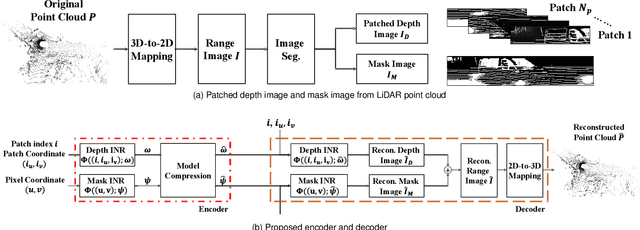
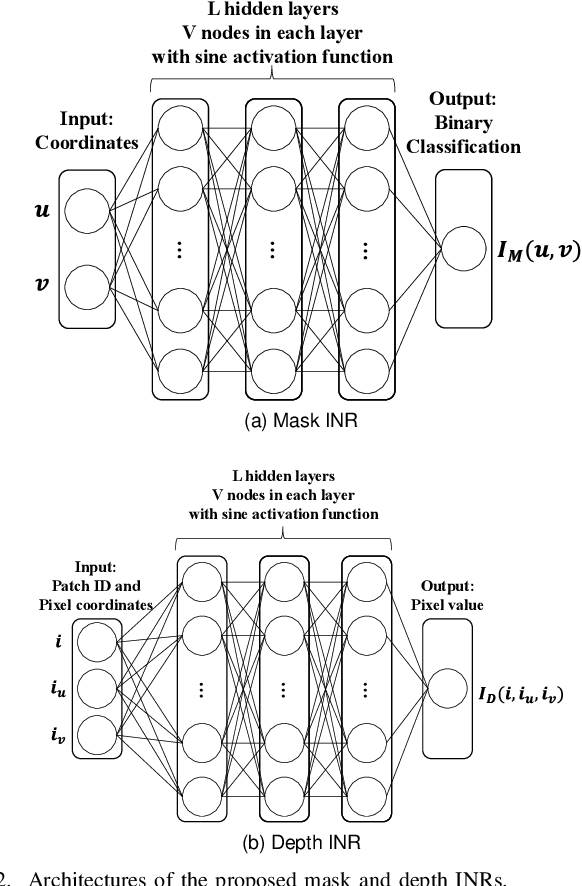
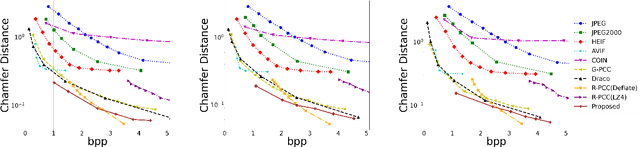
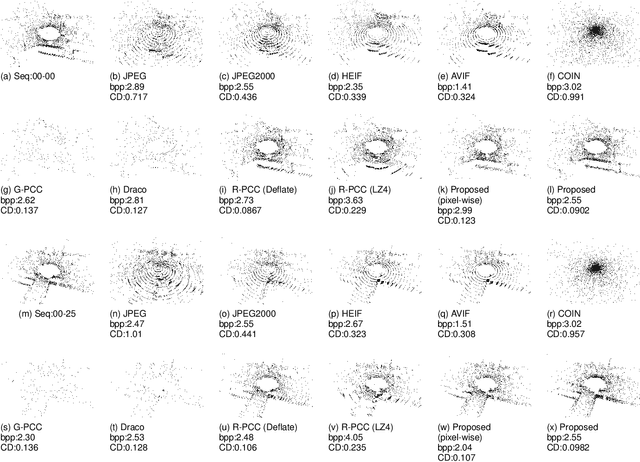
This paper presents a novel scheme to efficiently compress Light Detection and Ranging~(LiDAR) point clouds, enabling high-precision 3D scene archives, and such archives pave the way for a detailed understanding of the corresponding 3D scenes. We focus on 2D range images~(RIs) as a lightweight format for representing 3D LiDAR observations. Although conventional image compression techniques can be adapted to improve compression efficiency for RIs, their practical performance is expected to be limited due to differences in bit precision and the distinct pixel value distribution characteristics between natural images and RIs. We propose a novel implicit neural representation~(INR)--based RI compression method that effectively handles floating-point valued pixels. The proposed method divides RIs into depth and mask images and compresses them using patch-wise and pixel-wise INR architectures with model pruning and quantization, respectively. Experiments on the KITTI dataset show that the proposed method outperforms existing image, point cloud, RI, and INR-based compression methods in terms of 3D reconstruction and detection quality at low bitrates and decoding latency.
Quantum-PEFT: Ultra parameter-efficient fine-tuning
Mar 07, 2025This paper introduces Quantum-PEFT that leverages quantum computations for parameter-efficient fine-tuning (PEFT). Unlike other additive PEFT methods, such as low-rank adaptation (LoRA), Quantum-PEFT exploits an underlying full-rank yet surprisingly parameter efficient quantum unitary parameterization. With the use of Pauli parameterization, the number of trainable parameters grows only logarithmically with the ambient dimension, as opposed to linearly as in LoRA-based PEFT methods. Quantum-PEFT achieves vanishingly smaller number of trainable parameters than the lowest-rank LoRA as dimensions grow, enhancing parameter efficiency while maintaining a competitive performance. We apply Quantum-PEFT to several transfer learning benchmarks in language and vision, demonstrating significant advantages in parameter efficiency.
Winning Big with Small Models: Knowledge Distillation vs. Self-Training for Reducing Hallucination in QA Agents
Feb 26, 2025The deployment of Large Language Models (LLMs) in customer support is constrained by hallucination-generating false information-and the high cost of proprietary models. To address these challenges, we propose a retrieval-augmented question-answering (QA) pipeline and explore how to balance human input and automation. Using a dataset of questions about a Samsung Smart TV user manual, we demonstrate that synthetic data generated by LLMs outperforms crowdsourced data in reducing hallucination in finetuned models. We also compare self-training (fine-tuning models on their own outputs) and knowledge distillation (fine-tuning on stronger models' outputs, e.g., GPT-4o), and find that self-training achieves comparable hallucination reduction. We conjecture that this surprising finding can be attributed to increased exposure bias issues in the knowledge distillation case and support this conjecture with post hoc analysis. We also improve robustness to unanswerable questions and retrieval failures with contextualized "I don't know" responses. These findings show that scalable, cost-efficient QA systems can be built using synthetic data and self-training with open-source models, reducing reliance on proprietary tools or costly human annotations.
Smoothed Embeddings for Robust Language Models
Jan 27, 2025



Improving the safety and reliability of large language models (LLMs) is a crucial aspect of realizing trustworthy AI systems. Although alignment methods aim to suppress harmful content generation, LLMs are often still vulnerable to jailbreaking attacks that employ adversarial inputs that subvert alignment and induce harmful outputs. We propose the Randomized Embedding Smoothing and Token Aggregation (RESTA) defense, which adds random noise to the embedding vectors and performs aggregation during the generation of each output token, with the aim of better preserving semantic information. Our experiments demonstrate that our approach achieves superior robustness versus utility tradeoffs compared to the baseline defenses.
Quantum Implicit Neural Compression
Dec 19, 2024Signal compression based on implicit neural representation (INR) is an emerging technique to represent multimedia signals with a small number of bits. While INR-based signal compression achieves high-quality reconstruction for relatively low-resolution signals, the accuracy of high-frequency details is significantly degraded with a small model. To improve the compression efficiency of INR, we introduce quantum INR (quINR), which leverages the exponentially rich expressivity of quantum neural networks for data compression. Evaluations using some benchmark datasets show that the proposed quINR-based compression could improve rate-distortion performance in image compression compared with traditional codecs and classic INR-based coding methods, up to 1.2dB gain.
Quantum Diffusion Models for Few-Shot Learning
Nov 06, 2024



Modern quantum machine learning (QML) methods involve the variational optimization of parameterized quantum circuits on training datasets, followed by predictions on testing datasets. Most state-of-the-art QML algorithms currently lack practical advantages due to their limited learning capabilities, especially in few-shot learning tasks. In this work, we propose three new frameworks employing quantum diffusion model (QDM) as a solution for the few-shot learning: label-guided generation inference (LGGI); label-guided denoising inference (LGDI); and label-guided noise addition inference (LGNAI). Experimental results demonstrate that our proposed algorithms significantly outperform existing methods.