 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualNILM: Energy Injection Identification Enabled Disaggregation with Deep Multi-Task Learning
Aug 20, 2025Non-Intrusive Load Monitoring (NILM) offers a cost-effective method to obtain fine-grained appliance-level energy consumption in smart homes and building applications. However, the increasing adoption of behind-the-meter energy sources, such as solar panels and battery storage, poses new challenges for conventional NILM methods that rely solely on at-the-meter data. The injected energy from the behind-the-meter sources can obscure the power signatures of individual appliances, leading to a significant decline in NILM performance. To address this challenge, we present DualNILM, a deep multi-task learning framework designed for the dual tasks of appliance state recognition and injected energy identification in NILM. By integrating sequence-to-point and sequence-to-sequence strategies within a Transformer-based architecture, DualNILM can effectively capture multi-scale temporal dependencies in the aggregate power consumption patterns, allowing for accurate appliance state recognition and energy injection identification. We conduct validation of DualNILM using both self-collected and synthesized open NILM datasets that include both appliance-level energy consumption and energy injection. Extensive experimental results demonstrate that DualNILM maintains an excellent performance for the dual tasks in NILM, much outperforming conventional methods.
Quantum Learning and Estimation for Distribution Networks and Energy Communities Coordination
Jun 13, 2025Price signals from distribution networks (DNs) guide energy communities (ECs) to adjust energy usage, enabling effective coordination for reliable power system operation. However, this coordination faces significant challenges due to the limited availability of information (i.e., only the aggregated energy usage of ECs is available to DNs), and the high computational burden of accounting for uncertainties and the associated risks through numerous scenarios. To address these challenges, we propose a quantum learning and estimation approach to enhance coordination between DNs and ECs. Specifically, leveraging advanced quantum properties such as quantum superposition and entanglement, we develop a hybrid quantum temporal convolutional network-long short-term memory (Q-TCN-LSTM) model to establish an end-to-end mapping between ECs' responses and the price incentives from DNs. Moreover, we develop a quantum estimation method based on quantum amplitude estimation (QAE) and two phase-rotation circuits to significantly accelerate the optimization process under numerous uncertainty scenarios. Numerical experiments demonstrate that, compared to classical neural networks, the proposed Q-TCN-LSTM model improves the mapping accuracy by 69.2% while reducing the model size by 99.75% and the computation time by 93.9%. Compared to classical Monte Carlo simulation, QAE achieves comparable accuracy with a dramatic reduction in computational time (up to 99.99%) and requires significantly fewer computational resources.
Rethinking the Unsolvable: When In-Context Search Meets Test-Time Scaling
May 28, 2025Recent research has highlighted that Large Language Models (LLMs), even when trained to generate extended long reasoning steps, still face significant challenges on hard reasoning problems. However, much of the existing literature relies on direct prompting with simple in-context learning examples for evaluation, which largely overlooks advanced techniques to elicit LLMs' deliberate reasoning before drawing conclusions that LLMs hit a performance ceiling. In this paper, we systematically explore the combined potential of in-context search and test-time scaling on super hard reasoning tasks. We find that by employing advanced in-context search prompting to LLMs augmented with internal scaling, one can achieve transformative performance breakthroughs on tasks previously deemed "unsolvable" (e.g., reported success rates below 5%). We provide both empirical results and theoretical analysis of how this combination can unleash LLM reasoning capabilities: i) Empirically, on controlled NP-hard tasks and complex real-world planning benchmarks, our approach achieves up to a 30x improvement in success rates compared to previously reported results without any external mechanisms; ii) Theoretically, we show that in-context search prompting, when combined with internal scaling, significantly extends the complexity class of solvable reasoning problems. These findings challenge prevailing assumptions about the limitations of LLMs on complex tasks, indicating that current evaluation paradigms systematically underestimate their true potential. Our work calls for a critical reassessment of how LLM reasoning is benchmarked and a more robust evaluation strategy that fully captures the true capabilities of contemporary LLMs, which can lead to a better understanding of their operational reasoning boundaries in real-world deployments.
Safe Exploitative Play with Untrusted Type Beliefs
Nov 12, 2024



The combination of the Bayesian game and learning has a rich history, with the idea of controlling a single agent in a system composed of multiple agents with unknown behaviors given a set of types, each specifying a possible behavior for the other agents. The idea is to plan an agent's own actions with respect to those types which it believes are most likely to maximize the payoff. However, the type beliefs are often learned from past actions and likely to be incorrect. With this perspective in mind, we consider an agent in a game with type predictions of other components, and investigate the impact of incorrect beliefs to the agent's payoff. In particular, we formally define a tradeoff between risk and opportunity by comparing the payoff obtained against the optimal payoff, which is represented by a gap caused by trusting or distrusting the learned beliefs. Our main results characterize the tradeoff by establishing upper and lower bounds on the Pareto front for both normal-form and stochastic Bayesian games, with numerical results provided.
Beyond Numeric Awards: In-Context Dueling Bandits with LLM Agents
Jul 02, 2024In-context decision-making is an important capability of artificial general intelligence, which Large Language Models (LLMs) have effectively demonstrated in various scenarios. However, LLMs often face challenges when dealing with numerical contexts, and limited attention has been paid to evaluating their performance through preference feedback generated by the environment. This paper investigates the performance of LLMs as decision-makers in the context of Dueling Bandits (DB). We first evaluate the performance of LLMs by comparing GPT-3.5-Turbo, GPT-4, and GPT-4-Turbo against established DB algorithms. Our results reveal that LLMs, particularly GPT-4 Turbo, quickly identify the Condorcet winner, thus outperforming existing state-of-the-art algorithms in terms of weak regret. Nevertheless, LLMs struggle to converge even when explicitly prompted to do so, and are sensitive to prompt variations. To overcome these issues, we introduce an LLM-augmented algorithm, IF-Enhanced LLM, which takes advantage of both in-context decision-making capabilities of LLMs and theoretical guarantees inherited from classic DB algorithms. The design of such an algorithm sheds light on how to enhance trustworthiness for LLMs used in decision-making tasks where performance robustness matters. We show that IF-Enhanced LLM has theoretical guarantees on both weak and strong regret. Our experimental results validate that IF-Enhanced LLM is robust even with noisy and adversarial prompts.
Building Socially-Equitable Public Models
Jun 04, 2024



Public models offer predictions to a variety of downstream tasks and have played a crucial role in various AI applications, showcasing their proficiency in accurate predictions. However, the exclusive emphasis on prediction accuracy may not align with the diverse end objectives of downstream agents. Recognizing the public model's predictions as a service, we advocate for integrating the objectives of downstream agents into the optimization process. Concretely, to address performance disparities and foster fairness among heterogeneous agents in training, we propose a novel Equitable Objective. This objective, coupled with a policy gradient algorithm, is crafted to train the public model to produce a more equitable/uniform performance distribution across downstream agents, each with their unique concerns. Both theoretical analysis and empirical case studies have proven the effectiveness of our method in advancing performance equity across diverse downstream agents utilizing the public model for their decision-making. Codes and datasets are released at https://github.com/Ren-Research/Socially-Equitable-Public-Models.
Anytime-Competitive Reinforcement Learning with Policy Prior
Nov 13, 2023This paper studies the problem of Anytime-Competitive Markov Decision Process (A-CMDP). Existing works on Constrained Markov Decision Processes (CMDPs) aim to optimize the expected reward while constraining the expected cost over random dynamics, but the cost in a specific episode can still be unsatisfactorily high. In contrast, the goal of A-CMDP is to optimize the expected reward while guaranteeing a bounded cost in each round of any episode against a policy prior. We propose a new algorithm, called Anytime-Competitive Reinforcement Learning (ACRL), which provably guarantees the anytime cost constraints. The regret analysis shows the policy asymptotically matches the optimal reward achievable under the anytime competitive constraints. Experiments on the application of carbon-intelligent computing verify the reward performance and cost constraint guarantee of ACRL.
Learning-Augmented Scheduling for Solar-Powered Electric Vehicle Charging
Nov 10, 2023We tackle the complex challenge of scheduling the charging of electric vehicles (EVs) equipped with solar panels and batteries, particularly under out-of-distribution (OOD) conditions. Traditional scheduling approaches, such as reinforcement learning (RL) and model predictive control (MPC), often fail to provide satisfactory results when faced with OOD data, struggling to balance robustness (worst-case performance) and consistency (near-optimal average performance). To address this gap, we introduce a novel learning-augmented policy. This policy employs a dynamic robustness budget, which is adapted in real-time based on the reinforcement learning policy's performance. Specifically, it leverages the temporal difference (TD) error, a measure of the learning policy's prediction accuracy, to assess the trustworthiness of the machine-learned policy. This method allows for a more effective balance between consistency and robustness in EV charging schedules, significantly enhancing adaptability and efficiency in real-world, unpredictable environments. Our results demonstrate that this approach markedly improves scheduling effectiveness and reliability, particularly in OOD contexts, paving the way for more resilient and adaptive EV charging systems.
Beyond Black-Box Advice: Learning-Augmented Algorithms for MDPs with Q-Value Predictions
Jul 20, 2023We study the tradeoff between consistency and robustness in the context of a single-trajectory time-varying Markov Decision Process (MDP) with untrusted machine-learned advice. Our work departs from the typical approach of treating advice as coming from black-box sources by instead considering a setting where additional information about how the advice is generated is available. We prove a first-of-its-kind consistency and robustness tradeoff given Q-value advice under a general MDP model that includes both continuous and discrete state/action spaces. Our results highlight that utilizing Q-value advice enables dynamic pursuit of the better of machine-learned advice and a robust baseline, thus result in near-optimal performance guarantees, which provably improves what can be obtained solely with black-box advice.
Equipping Black-Box Policies with Model-Based Advice for Stable Nonlinear Control
Jun 02, 2022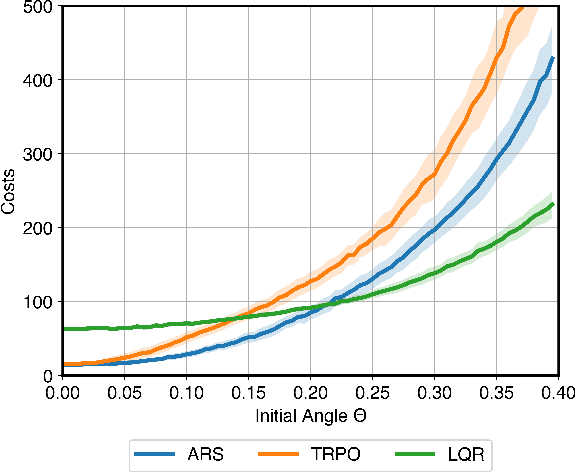

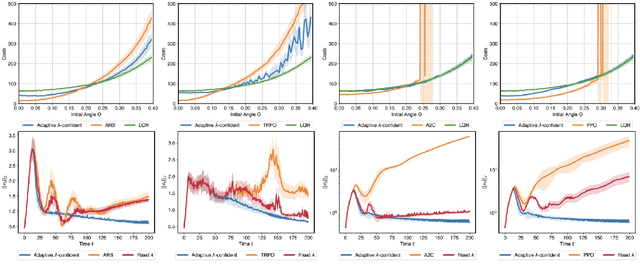
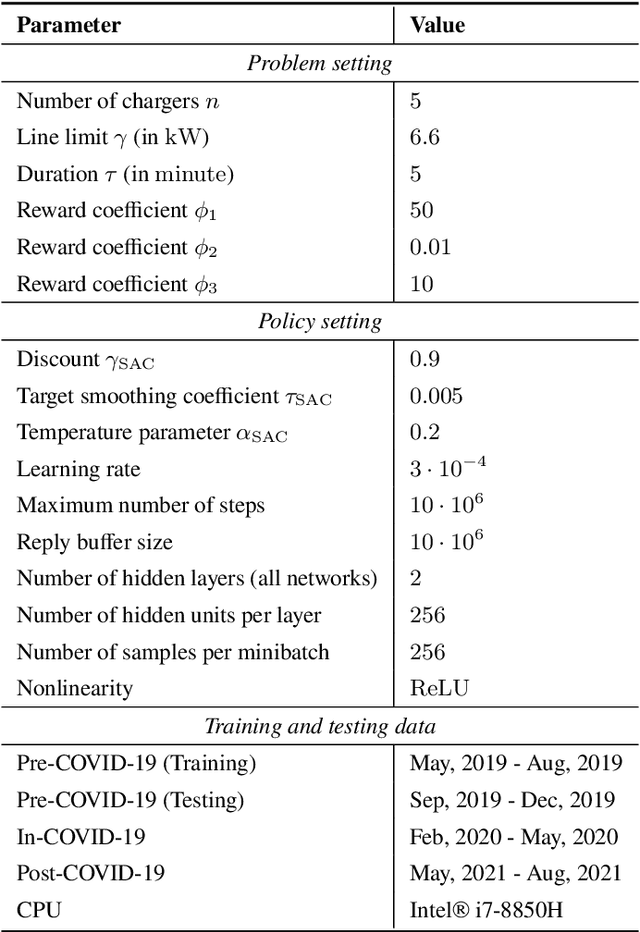
Machine-learned black-box policies are ubiquitous for nonlinear control problems. Meanwhile, crude model information is often available for these problems from, e.g., linear approximations of nonlinear dynamics. We study the problem of equipping a black-box control policy with model-based advice for nonlinear control on a single trajectory. We first show a general negative result that a naive convex combination of a black-box policy and a linear model-based policy can lead to instability, even if the two policies are both stabilizing. We then propose an adaptive $\lambda$-confident policy, with a coefficient $\lambda$ indicating the confidence in a black-box policy, and prove its stability. With bounded nonlinearity, in addition, we show that the adaptive $\lambda$-confident policy achieves a bounded competitive ratio when a black-box policy is near-optimal. Finally, we propose an online learning approach to implement the adaptive $\lambda$-confident policy and verify its efficacy in case studies about the CartPole problem and a real-world electric vehicle (EV) charging problem with data bias due to COVID-19.