 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNever Explore Repeatedly in Multi-Agent Reinforcement Learning
Aug 19, 2023



In the realm of multi-agent reinforcement learning, intrinsic motivations have emerged as a pivotal tool for exploration. While the computation of many intrinsic rewards relies on estimating variational posteriors using neural network approximators, a notable challenge has surfaced due to the limited expressive capability of these neural statistics approximators. We pinpoint this challenge as the "revisitation" issue, where agents recurrently explore confined areas of the task space. To combat this, we propose a dynamic reward scaling approach. This method is crafted to stabilize the significant fluctuations in intrinsic rewards in previously explored areas and promote broader exploration, effectively curbing the revisitation phenomenon. Our experimental findings underscore the efficacy of our approach, showcasing enhanced performance in demanding environments like Google Research Football and StarCraft II micromanagement tasks, especially in sparse reward settings.
Deep Contract Design via Discontinuous Piecewise Affine Neural Networks
Jul 05, 2023Contract design involves a principal who establishes contractual agreements about payments for outcomes that arise from the actions of an agent. In this paper, we initiate the study of deep learning for the automated design of optimal contracts. We formulate this as an offline learning problem, where a deep network is used to represent the principal's expected utility as a function of the design of a contract. We introduce a novel representation: the Discontinuous ReLU (DeLU) network, which models the principal's utility as a discontinuous piecewise affine function where each piece corresponds to the agent taking a particular action. DeLU networks implicitly learn closed-form expressions for the incentive compatibility constraints of the agent and the utility maximization objective of the principal, and support parallel inference on each piece through linear programming or interior-point methods that solve for optimal contracts. We provide empirical results that demonstrate success in approximating the principal's utility function with a small number of training samples and scaling to find approximately optimal contracts on problems with a large number of actions and outcomes.
Symmetry-Aware Robot Design with Structured Subgroups
May 31, 2023



Robot design aims at learning to create robots that can be easily controlled and perform tasks efficiently. Previous works on robot design have proven its ability to generate robots for various tasks. However, these works searched the robots directly from the vast design space and ignored common structures, resulting in abnormal robots and poor performance. To tackle this problem, we propose a Symmetry-Aware Robot Design (SARD) framework that exploits the structure of the design space by incorporating symmetry searching into the robot design process. Specifically, we represent symmetries with the subgroups of the dihedral group and search for the optimal symmetry in structured subgroups. Then robots are designed under the searched symmetry. In this way, SARD can design efficient symmetric robots while covering the original design space, which is theoretically analyzed. We further empirically evaluate SARD on various tasks, and the results show its superior efficiency and generalizability.
Low-Rank Modular Reinforcement Learning via Muscle Synergy
Oct 26, 2022



Modular Reinforcement Learning (RL) decentralizes the control of multi-joint robots by learning policies for each actuator. Previous work on modular RL has proven its ability to control morphologically different agents with a shared actuator policy. However, with the increase in the Degree of Freedom (DoF) of robots, training a morphology-generalizable modular controller becomes exponentially difficult. Motivated by the way the human central nervous system controls numerous muscles, we propose a Synergy-Oriented LeARning (SOLAR) framework that exploits the redundant nature of DoF in robot control. Actuators are grouped into synergies by an unsupervised learning method, and a synergy action is learned to control multiple actuators in synchrony. In this way, we achieve a low-rank control at the synergy level. We extensively evaluate our method on a variety of robot morphologies, and the results show its superior efficiency and generalizability, especially on robots with a large DoF like Humanoids++ and UNIMALs.
Non-Linear Coordination Graphs
Oct 26, 2022



Value decomposition multi-agent reinforcement learning methods learn the global value function as a mixing of each agent's individual utility functions. Coordination graphs (CGs) represent a higher-order decomposition by incorporating pairwise payoff functions and thus is supposed to have a more powerful representational capacity. However, CGs decompose the global value function linearly over local value functions, severely limiting the complexity of the value function class that can be represented. In this paper, we propose the first non-linear coordination graph by extending CG value decomposition beyond the linear case. One major challenge is to conduct greedy action selections in this new function class to which commonly adopted DCOP algorithms are no longer applicable. We study how to solve this problem when mixing networks with LeakyReLU activation are used. An enumeration method with a global optimality guarantee is proposed and motivates an efficient iterative optimization method with a local optimality guarantee. We find that our method can achieve superior performance on challenging multi-agent coordination tasks like MACO.
* Authors are listed in alphabetical order
Multi-Agent Policy Transfer via Task Relationship Modeling
Mar 09, 2022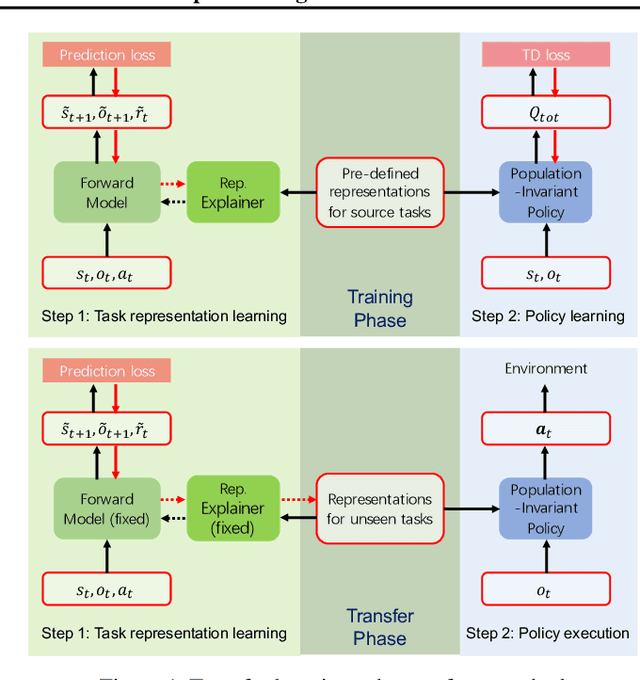
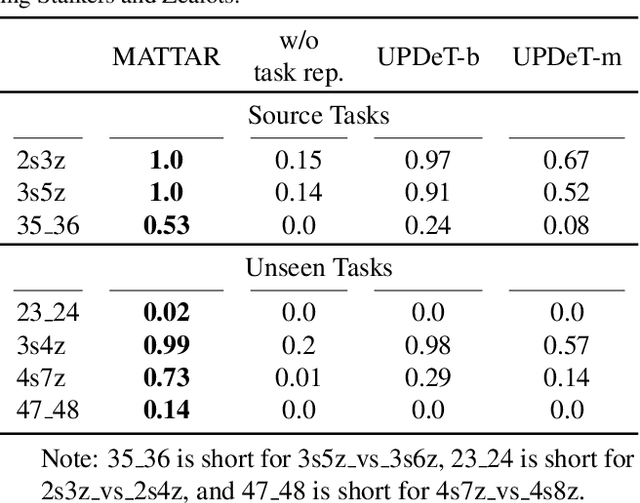
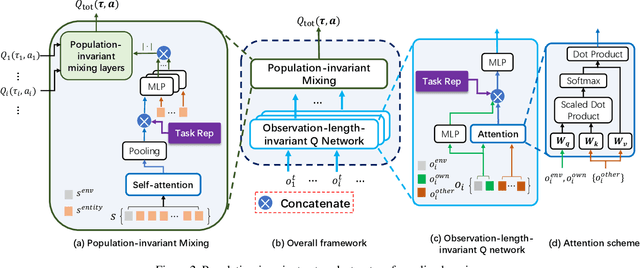
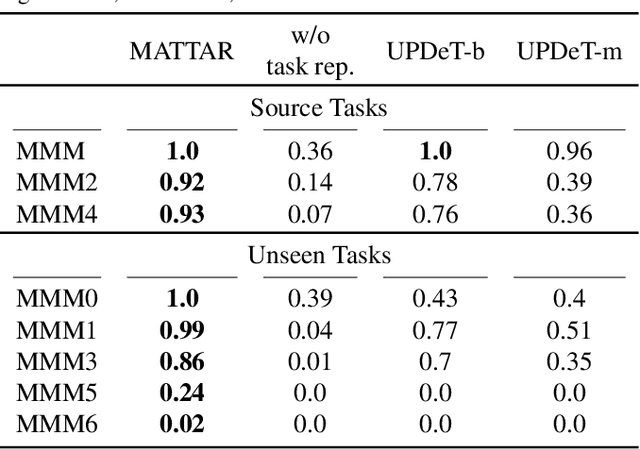
Team adaptation to new cooperative tasks is a hallmark of human intelligence, which has yet to be fully realized in learning agents. Previous work on multi-agent transfer learning accommodate teams of different sizes, heavily relying on the generalization ability of neural networks for adapting to unseen tasks. We believe that the relationship among tasks provides the key information for policy adaptation. In this paper, we try to discover and exploit common structures among tasks for more efficient transfer, and propose to learn effect-based task representations as a common space of tasks, using an alternatively fixed training scheme. We demonstrate that the task representation can capture the relationship among tasks, and can generalize to unseen tasks. As a result, the proposed method can help transfer learned cooperation knowledge to new tasks after training on a few source tasks. We also find that fine-tuning the transferred policies help solve tasks that are hard to learn from scratch.
Self-Organized Polynomial-Time Coordination Graphs
Dec 07, 2021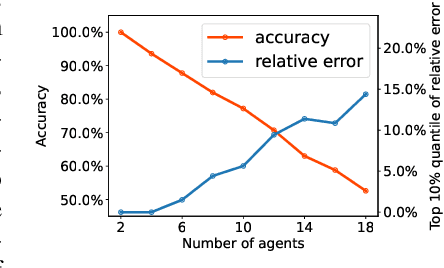
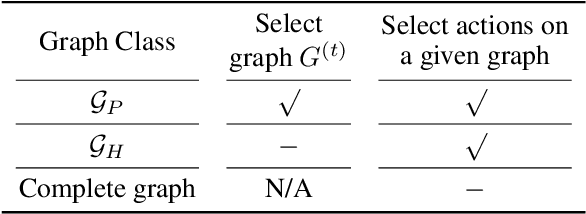
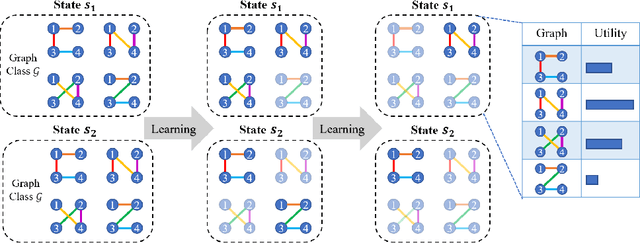

Coordination graph is a promising approach to model agent collaboration in multi-agent reinforcement learning. It factorizes a large multi-agent system into a suite of overlapping groups that represent the underlying coordination dependencies. One critical challenge in this paradigm is the complexity of computing maximum-value actions for a graph-based value factorization. It refers to the decentralized constraint optimization problem (DCOP), which and whose constant-ratio approximation are NP-hard problems. To bypass this fundamental hardness, this paper proposes a novel method, named Self-Organized Polynomial-time Coordination Graphs (SOP-CG), which uses structured graph classes to guarantee the optimality of the induced DCOPs with sufficient function expressiveness. We extend the graph topology to be state-dependent, formulate the graph selection as an imaginary agent, and finally derive an end-to-end learning paradigm from the unified Bellman optimality equation. In experiments, we show that our approach learns interpretable graph topologies, induces effective coordination, and improves performance across a variety of cooperative multi-agent tasks.
Containerized Distributed Value-Based Multi-Agent Reinforcement Learning
Oct 15, 2021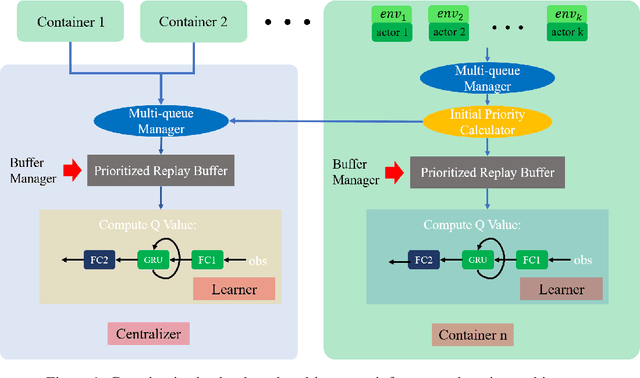
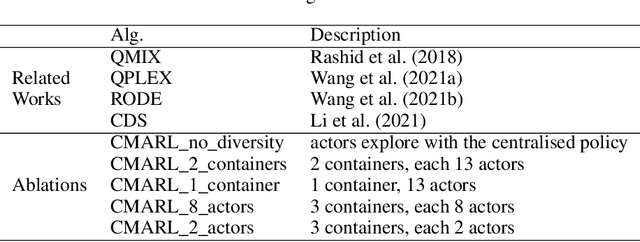
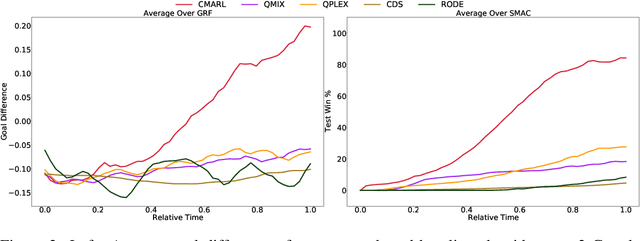
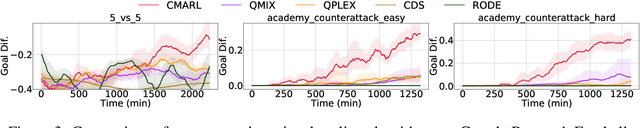
Multi-agent reinforcement learning tasks put a high demand on the volume of training samples. Different from its single-agent counterpart, distributed value-based multi-agent reinforcement learning faces the unique challenges of demanding data transfer, inter-process communication management, and high requirement of exploration. We propose a containerized learning framework to solve these problems. We pack several environment instances, a local learner and buffer, and a carefully designed multi-queue manager which avoids blocking into a container. Local policies of each container are encouraged to be as diverse as possible, and only trajectories with highest priority are sent to a global learner. In this way, we achieve a scalable, time-efficient, and diverse distributed MARL learning framework with high system throughput. To own knowledge, our method is the first to solve the challenging Google Research Football full game $5\_v\_5$. On the StarCraft II micromanagement benchmark, our method gets $4$-$18\times$ better results compared to state-of-the-art non-distributed MARL algorithms.
Context-Aware Sparse Deep Coordination Graphs
Jun 05, 2021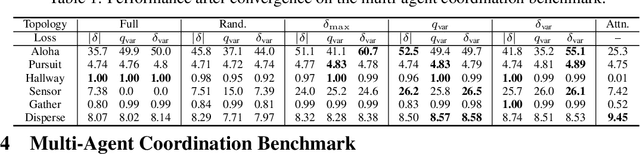
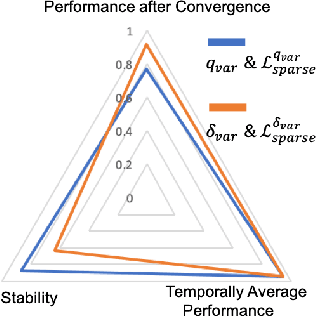
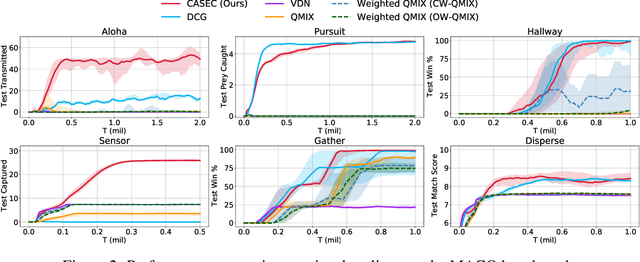
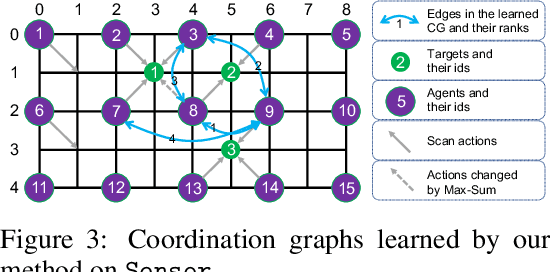
Learning sparse coordination graphs adaptive to the coordination dynamics among agents is a long-standing problem in cooperative multi-agent learning. This paper studies this problem by proposing several value-based and observation-based schemes for learning dynamic topologies and evaluating them on a new Multi-Agent COordination (MACO) benchmark. The benchmark collects classic coordination problems in the literature, increases their difficulty, and classifies them into different types. By analyzing the individual advantages of each learning scheme on each type of problem and their overall performance, we propose a novel method using the variance of utility difference functions to learn context-aware sparse coordination topologies. Moreover, our method learns action representations that effectively reduce the influence of utility functions' estimation errors on graph construction. Experiments show that our method significantly outperforms dense and static topologies across the MACO and StarCraft II micromanagement benchmark.
Celebrating Diversity in Shared Multi-Agent Reinforcement Learning
Jun 04, 2021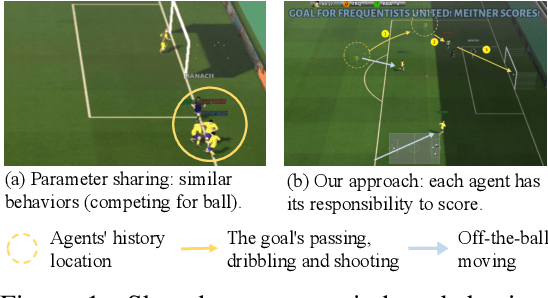
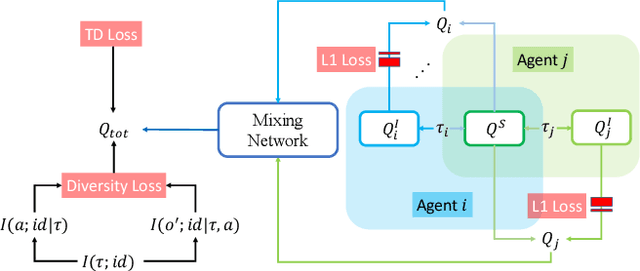
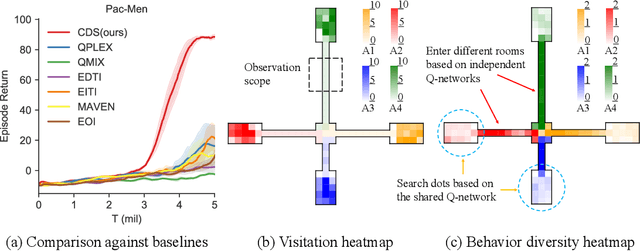
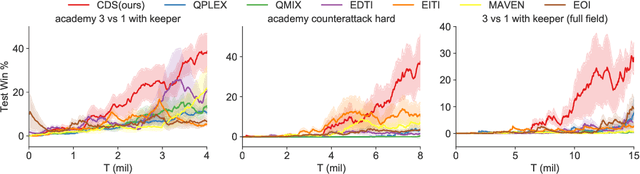
Recently, deep multi-agent reinforcement learning (MARL) has shown the promise to solve complex cooperative tasks. Its success is partly because of parameter sharing among agents. However, such sharing may lead agents to behave similarly and limit their coordination capacity. In this paper, we aim to introduce diversity in both optimization and representation of shared multi-agent reinforcement learning. Specifically, we propose an information-theoretical regularization to maximize the mutual information between agents' identities and their trajectories, encouraging extensive exploration and diverse individualized behaviors. In representation, we incorporate agent-specific modules in the shared neural network architecture, which are regularized by L1-norm to promote learning sharing among agents while keeping necessary diversity. Empirical results show that our method achieves state-of-the-art performance on Google Research Football and super hard StarCraft II micromanagement tasks.