 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Classification: Dynamic Adapter Routing for Continual Multimodal Retrieval
May 29, 2026While retrieval is a core function of vision-language models, continually updating these models for retrieval tasks remains critically underexplored. Existing work often approaches continual retrieval through the lens of class-incremental learning (CIL), evaluating both standard CIL methods and retrieval-oriented adaptations in settings that may not fully capture the retrieval-specific dynamics. To address this, we introduce a new, principled evaluation framework for continual multimodal retrieval (CMR) spanning diverse visual domains, and systematically evaluate common approaches within this setting. Our empirical analysis shows that standard CIL methods fail to yield meaningful gains in our more challenging scenario. Therefore, we propose Dynamic Adapter Routing (DAR), a novel approach based on adapters selected through prototype-based routing and combined via model merging.DAR achieves superior performance over the previous baselines and demonstrates strong generalization under out-of-distribution evaluation. Our results highlights the unique challenges of CMR and encourages further research in this direction.
ExpertSim: Fast Particle Detector Simulation Using Mixture-of-Generative-Experts
Aug 28, 2025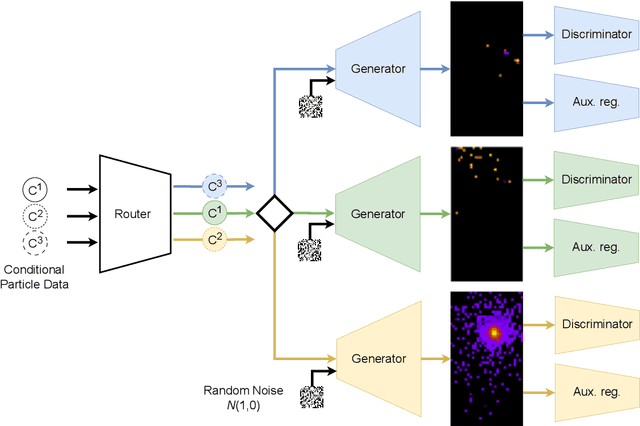
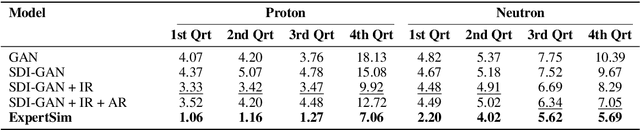
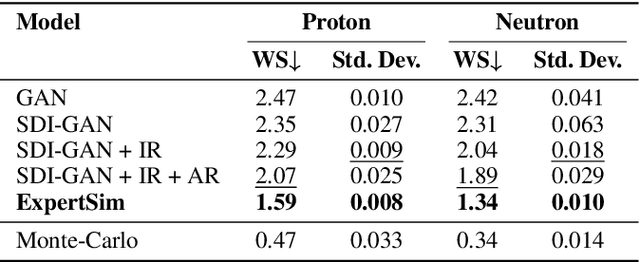
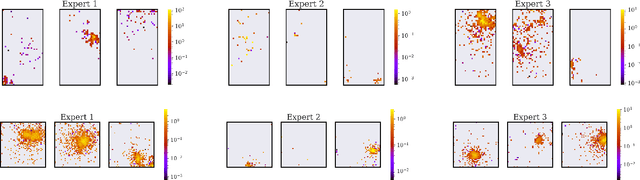
Simulating detector responses is a crucial part of understanding the inner workings of particle collisions in the Large Hadron Collider at CERN. Such simulations are currently performed with statistical Monte Carlo methods, which are computationally expensive and put a significant strain on CERN's computational grid. Therefore, recent proposals advocate for generative machine learning methods to enable more efficient simulations. However, the distribution of the data varies significantly across the simulations, which is hard to capture with out-of-the-box methods. In this study, we present ExpertSim - a deep learning simulation approach tailored for the Zero Degree Calorimeter in the ALICE experiment. Our method utilizes a Mixture-of-Generative-Experts architecture, where each expert specializes in simulating a different subset of the data. This allows for a more precise and efficient generation process, as each expert focuses on a specific aspect of the calorimeter response. ExpertSim not only improves accuracy, but also provides a significant speedup compared to the traditional Monte-Carlo methods, offering a promising solution for high-efficiency detector simulations in particle physics experiments at CERN. We make the code available at https://github.com/patrick-bedkowski/expertsim-mix-of-generative-experts.
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs?
Feb 22, 2025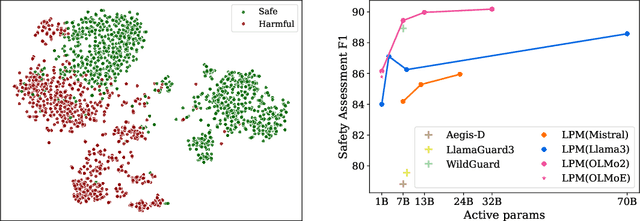
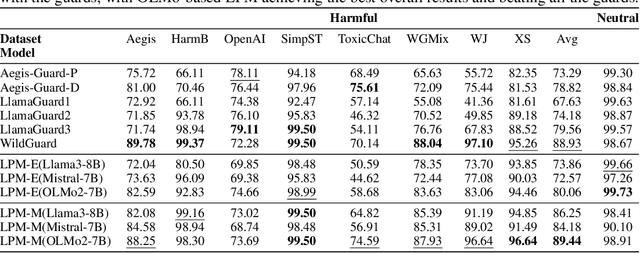

Ensuring the safety of the Large Language Model (LLM) is critical, but currently used methods in most cases sacrifice the model performance to obtain increased safety or perform poorly on data outside of their adaptation distribution. We investigate existing methods for such generalization and find them insufficient. Surprisingly, while even plain LLMs recognize unsafe prompts, they may still generate unsafe responses. To avoid performance degradation and preserve safe performance, we advocate for a two-step framework, where we first identify unsafe prompts via a lightweight classifier, and apply a "safe" model only to such prompts. In particular, we explore the design of the safety detector in more detail, investigating the use of different classifier architectures and prompting techniques. Interestingly, we find that the final hidden state for the last token is enough to provide robust performance, minimizing false positives on benign data while performing well on malicious prompt detection. Additionally, we show that classifiers trained on the representations from different model layers perform comparably on the latest model layers, indicating that safety representation is present in the LLMs' hidden states at most model stages. Our work is a step towards efficient, representation-based safety mechanisms for LLMs.
Exploring the Stability Gap in Continual Learning: The Role of the Classification Head
Nov 06, 2024



Continual learning (CL) has emerged as a critical area in machine learning, enabling neural networks to learn from evolving data distributions while mitigating catastrophic forgetting. However, recent research has identified the stability gap -- a phenomenon where models initially lose performance on previously learned tasks before partially recovering during training. Such learning dynamics are contradictory to the intuitive understanding of stability in continual learning where one would expect the performance to degrade gradually instead of rapidly decreasing and then partially recovering later. To better understand and alleviate the stability gap, we investigate it at different levels of the neural network architecture, particularly focusing on the role of the classification head. We introduce the nearest-mean classifier (NMC) as a tool to attribute the influence of the backbone and the classification head on the stability gap. Our experiments demonstrate that NMC not only improves final performance, but also significantly enhances training stability across various continual learning benchmarks, including CIFAR100, ImageNet100, CUB-200, and FGVC Aircrafts. Moreover, we find that NMC also reduces task-recency bias. Our analysis provides new insights into the stability gap and suggests that the primary contributor to this phenomenon is the linear head, rather than the insufficient representation learning.
Sparser, Better, Deeper, Stronger: Improving Sparse Training with Exact Orthogonal Initialization
Jun 03, 2024



Static sparse training aims to train sparse models from scratch, achieving remarkable results in recent years. A key design choice is given by the sparse initialization, which determines the trainable sub-network through a binary mask. Existing methods mainly select such mask based on a predefined dense initialization. Such an approach may not efficiently leverage the mask's potential impact on the optimization. An alternative direction, inspired by research into dynamical isometry, is to introduce orthogonality in the sparse subnetwork, which helps in stabilizing the gradient signal. In this work, we propose Exact Orthogonal Initialization (EOI), a novel sparse orthogonal initialization scheme based on composing random Givens rotations. Contrary to other existing approaches, our method provides exact (not approximated) orthogonality and enables the creation of layers with arbitrary densities. We demonstrate the superior effectiveness and efficiency of EOI through experiments, consistently outperforming common sparse initialization techniques. Our method enables training highly sparse 1000-layer MLP and CNN networks without residual connections or normalization techniques, emphasizing the crucial role of weight initialization in static sparse training alongside sparse mask selection. The code is available at https://github.com/woocash2/sparser-better-deeper-stronger
Accelerated Inference and Reduced Forgetting: The Dual Benefits of Early-Exit Networks in Continual Learning
Mar 12, 2024



Driven by the demand for energy-efficient employment of deep neural networks, early-exit methods have experienced a notable increase in research attention. These strategies allow for swift predictions by making decisions early in the network, thereby conserving computation time and resources. However, so far the early-exit networks have only been developed for stationary data distributions, which restricts their application in real-world scenarios with continuous non-stationary data. This study aims to explore the continual learning of the early-exit networks. We adapt existing continual learning methods to fit with early-exit architectures and investigate their behavior in the continual setting. We notice that early network layers exhibit reduced forgetting and can outperform standard networks even when using significantly fewer resources. Furthermore, we analyze the impact of task-recency bias on early-exit inference and propose Task-wise Logits Correction (TLC), a simple method that equalizes this bias and improves the network performance for every given compute budget in the class-incremental setting. We assess the accuracy and computational cost of various continual learning techniques enhanced with early-exits and TLC across standard class-incremental learning benchmarks such as 10 split CIFAR100 and ImageNetSubset and show that TLC can achieve the accuracy of the standard methods using less than 70\% of their computations. Moreover, at full computational budget, our method outperforms the accuracy of the standard counterparts by up to 15 percentage points. Our research underscores the inherent synergy between early-exit networks and continual learning, emphasizing their practical utility in resource-constrained environments.
Exploiting Transformer Activation Sparsity with Dynamic Inference
Oct 06, 2023



Transformer models, despite their impressive performance, often face practical limitations due to their high computational requirements. At the same time, previous studies have revealed significant activation sparsity in these models, indicating the presence of redundant computations. In this paper, we propose Dynamic Sparsified Transformer Inference (DSTI), a method that radically reduces the inference cost of Transformer models by enforcing activation sparsity and subsequently transforming a dense model into its sparse Mixture of Experts (MoE) version. We demonstrate that it is possible to train small gating networks that successfully predict the relative contribution of each expert during inference. Furthermore, we introduce a mechanism that dynamically determines the number of executed experts individually for each token. DSTI can be applied to any Transformer-based architecture and has negligible impact on the accuracy. For the BERT-base classification model, we reduce inference cost by almost 60%.
Adapt Your Teacher: Improving Knowledge Distillation for Exemplar-free Continual Learning
Aug 18, 2023



In this work, we investigate exemplar-free class incremental learning (CIL) with knowledge distillation (KD) as a regularization strategy, aiming to prevent forgetting. KD-based methods are successfully used in CIL, but they often struggle to regularize the model without access to exemplars of the training data from previous tasks. Our analysis reveals that this issue originates from substantial representation shifts in the teacher network when dealing with out-of-distribution data. This causes large errors in the KD loss component, leading to performance degradation in CIL. Inspired by recent test-time adaptation methods, we introduce Teacher Adaptation (TA), a method that concurrently updates the teacher and the main model during incremental training. Our method seamlessly integrates with KD-based CIL approaches and allows for consistent enhancement of their performance across multiple exemplar-free CIL benchmarks.
Hypernetworks build Implicit Neural Representations of Sounds
Feb 17, 2023



Implicit Neural Representations (INRs) are nowadays used to represent multimedia signals across various real-life applications, including image super-resolution, image compression, or 3D rendering. Existing methods that leverage INRs are predominantly focused on visual data, as their application to other modalities, such as audio, is nontrivial due to the inductive biases present in architectural attributes of image-based INR models. To address this limitation, we introduce HyperSound, the first meta-learning approach to produce INRs for audio samples that leverages hypernetworks to generalize beyond samples observed in training. Our approach reconstructs audio samples with quality comparable to other state-of-the-art models and provides a viable alternative to contemporary sound representations used in deep neural networks for audio processing, such as spectrograms.
HyperSound: Generating Implicit Neural Representations of Audio Signals with Hypernetworks
Nov 03, 2022


Implicit neural representations (INRs) are a rapidly growing research field, which provides alternative ways to represent multimedia signals. Recent applications of INRs include image super-resolution, compression of high-dimensional signals, or 3D rendering. However, these solutions usually focus on visual data, and adapting them to the audio domain is not trivial. Moreover, it requires a separately trained model for every data sample. To address this limitation, we propose HyperSound, a meta-learning method leveraging hypernetworks to produce INRs for audio signals unseen at training time. We show that our approach can reconstruct sound waves with quality comparable to other state-of-the-art models.