 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring the Internal Monologue: Probe Trajectories Reveal Reasoning Dynamics
May 18, 2026Large Reasoning Models (LRMs) introduce new opportunities for safety monitoring through their Chain of Thought (CoT) reasoning. However, CoT is not always faithful to the model's final output, undermining its reliability as a monitoring tool. To address this, we investigate the hidden representations of LRMs to determine whether future behavior can be predicted from prompt and CoT representations. By evaluating a probe at each generated token, we construct a probe trajectory, the continuous evolution of a concept's probability across the reasoning process. We find that future model behavior is more distinguishable when examined over the full trajectory than from a single static prediction. To characterize these temporal dynamics, we extract signal-processing features that capture volatility, trend, and steady-state behavior, significantly improving the separation of future model states. We also present two methodological insights. First, template-based training data achieves near-parity with dynamically generated model responses, eliminating the need for a costly initial inference and labeling. Second, the choice of pooling operation is critical: average-pooling and last-token methods collapse to near-random performance, while max-pooling achieves up to 95% AUROC and yields stable probe trajectories. Using four datasets and four reasoning models across the domains of safety and mathematics, we demonstrate that trajectory features encode task-specific dynamics that improve outcome separability. These findings establish probe trajectories as a complementary framework for monitoring LRM behavior. Warning: This article contains potentially harmful content.
Conditioned Activation Transport for T2I Safety Steering
Mar 03, 2026Despite their impressive capabilities, current Text-to-Image (T2I) models remain prone to generating unsafe and toxic content. While activation steering offers a promising inference-time intervention, we observe that linear activation steering frequently degrades image quality when applied to benign prompts. To address this trade-off, we first construct SafeSteerDataset, a contrastive dataset containing 2300 safe and unsafe prompt pairs with high cosine similarity. Leveraging this data, we propose Conditioned Activation Transport (CAT), a framework that employs a geometry-based conditioning mechanism and nonlinear transport maps. By conditioning transport maps to activate only within unsafe activation regions, we minimize interference with benign queries. We validate our approach on two state-of-the-art architectures: Z-Image and Infinity. Experiments demonstrate that CAT generalizes effectively across these backbones, significantly reducing Attack Success Rate while maintaining image fidelity compared to unsteered generations. Warning: This paper contains potentially offensive text and images.
PLLuM: A Family of Polish Large Language Models
Nov 05, 2025



Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
Evaluating LLMs Robustness in Less Resourced Languages with Proxy Models
Jun 09, 2025



Large language models (LLMs) have demonstrated impressive capabilities across various natural language processing (NLP) tasks in recent years. However, their susceptibility to jailbreaks and perturbations necessitates additional evaluations. Many LLMs are multilingual, but safety-related training data contains mainly high-resource languages like English. This can leave them vulnerable to perturbations in low-resource languages such as Polish. We show how surprisingly strong attacks can be cheaply created by altering just a few characters and using a small proxy model for word importance calculation. We find that these character and word-level attacks drastically alter the predictions of different LLMs, suggesting a potential vulnerability that can be used to circumvent their internal safety mechanisms. We validate our attack construction methodology on Polish, a low-resource language, and find potential vulnerabilities of LLMs in this language. Additionally, we show how it can be extended to other languages. We release the created datasets and code for further research.
Maybe I Should Not Answer That, but... Do LLMs Understand The Safety of Their Inputs?
Feb 22, 2025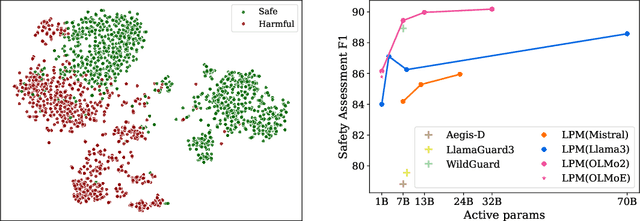
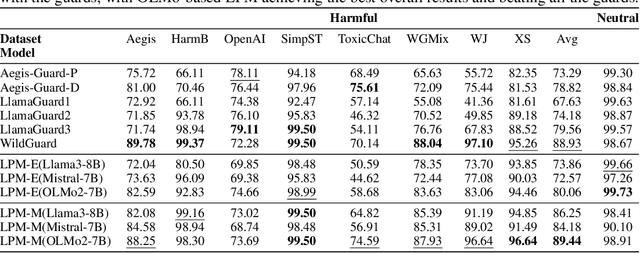

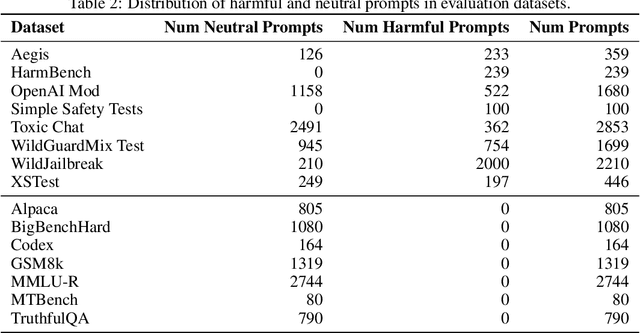
Ensuring the safety of the Large Language Model (LLM) is critical, but currently used methods in most cases sacrifice the model performance to obtain increased safety or perform poorly on data outside of their adaptation distribution. We investigate existing methods for such generalization and find them insufficient. Surprisingly, while even plain LLMs recognize unsafe prompts, they may still generate unsafe responses. To avoid performance degradation and preserve safe performance, we advocate for a two-step framework, where we first identify unsafe prompts via a lightweight classifier, and apply a "safe" model only to such prompts. In particular, we explore the design of the safety detector in more detail, investigating the use of different classifier architectures and prompting techniques. Interestingly, we find that the final hidden state for the last token is enough to provide robust performance, minimizing false positives on benign data while performing well on malicious prompt detection. Additionally, we show that classifiers trained on the representations from different model layers perform comparably on the latest model layers, indicating that safety representation is present in the LLMs' hidden states at most model stages. Our work is a step towards efficient, representation-based safety mechanisms for LLMs.