 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Tuning Deep Reinforcement Learning
Mar 02, 2020
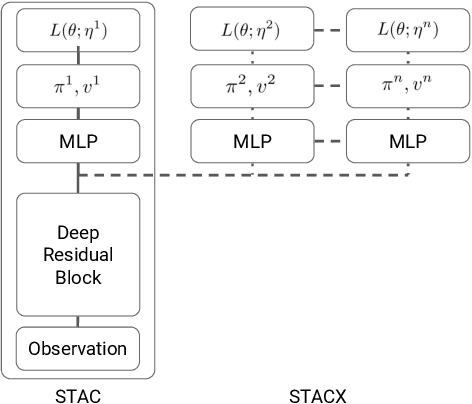
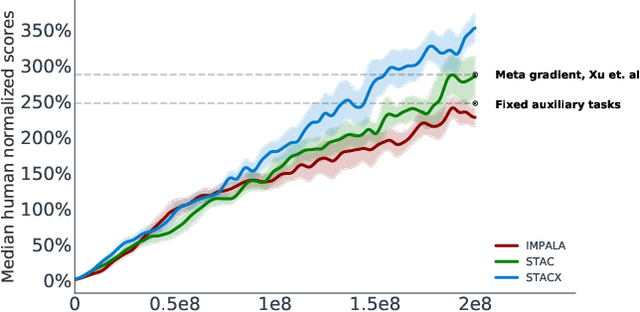
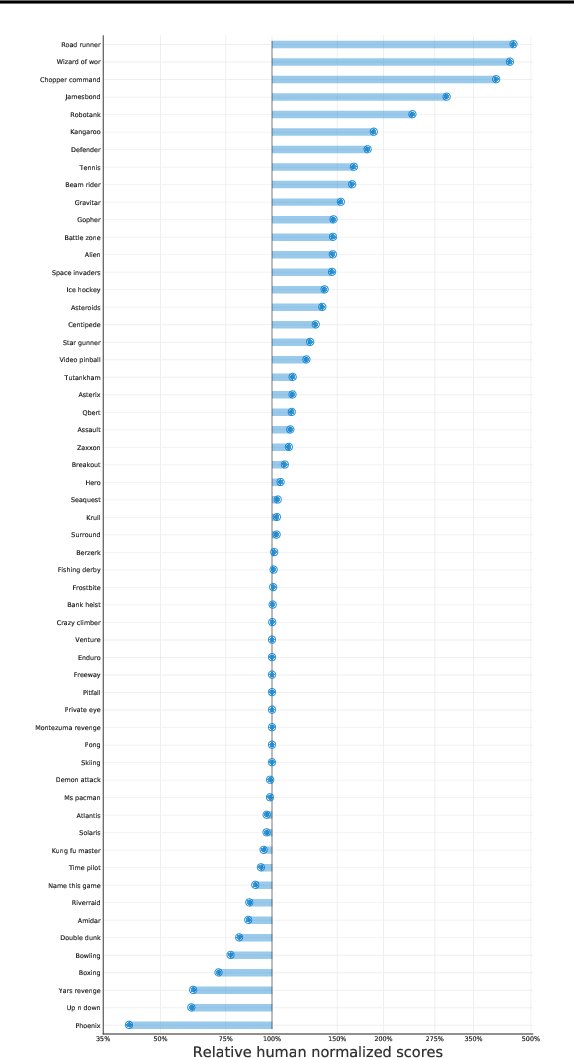
Reinforcement learning (RL) algorithms often require expensive manual or automated hyperparameter searches in order to perform well on a new domain. This need is particularly acute in modern deep RL architectures which often incorporate many modules and multiple loss functions. In this paper, we take a step towards addressing this issue by using metagradients (Xu et al., 2018) to tune these hyperparameters via differentiable cross validation, whilst the agent interacts with and learns from the environment. We present the Self-Tuning Actor Critic (STAC) which uses this process to tune the hyperparameters of the usual loss function of the IMPALA actor critic agent(Espeholt et. al., 2018), to learn the hyperparameters that define auxiliary loss functions, and to balance trade offs in off policy learning by introducing and adapting the hyperparameters of a novel leaky V-trace operator. The method is simple to use, sample efficient and does not require significant increase in compute. Ablative studies show that the overall performance of STAC improves as we adapt more hyperparameters. When applied to 57 games on the Atari 2600 environment over 200 million frames our algorithm improves the median human normalized score of the baseline from 243% to 364%.
Deep learning reconstruction of ultrashort pulses from 2D spatial intensity patterns recorded by an all-in-line system in a single-shot
Nov 23, 2019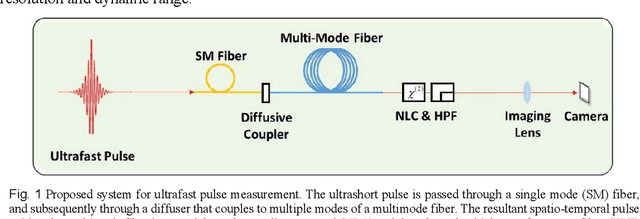
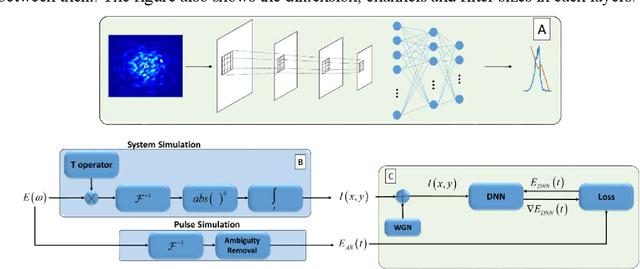
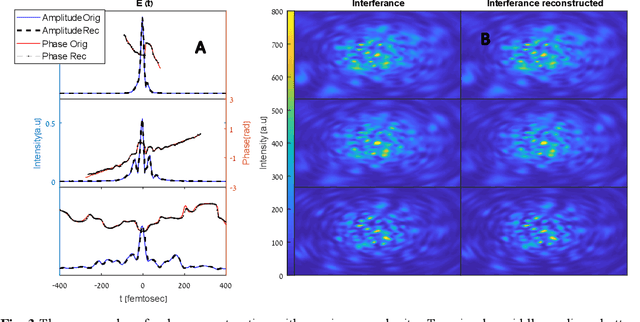
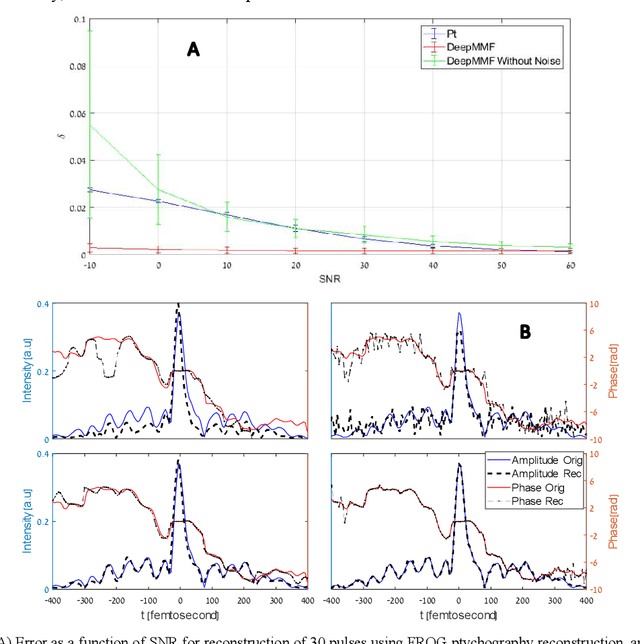
We propose a simple all-in-line single-shot scheme for diagnostics of ultrashort laser pulses, consisting of a multi-mode fiber, a nonlinear crystal and a CCD camera. The system records a 2D spatial intensity pattern, from which the pulse shape (amplitude and phase) are recovered, through a fast Deep Learning algorithm. We explore this scheme in simulations and demonstrate the recovery of ultrashort pulses, robustness to noise in measurements and to inaccuracies in the parameters of the system components. Our technique mitigates the need for commonly used iterative optimization reconstruction methods, which are usually slow and hampered by the presence of noise. These features make our concept system advantageous for real time probing of ultrafast processes and noisy conditions. Moreover, this work exemplifies that using deep learning we can unlock new types of systems for pulse recovery.
Apprenticeship Learning via Frank-Wolfe
Nov 20, 2019
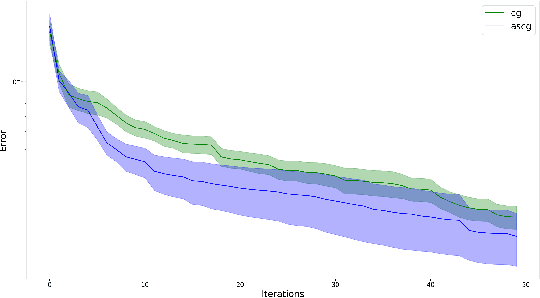
We consider the applications of the Frank-Wolfe (FW) algorithm for Apprenticeship Learning (AL). In this setting, we are given a Markov Decision Process (MDP) without an explicit reward function. Instead, we observe an expert that acts according to some policy, and the goal is to find a policy whose feature expectations are closest to those of the expert policy. We formulate this problem as finding the projection of the feature expectations of the expert on the feature expectations polytope -- the convex hull of the feature expectations of all the deterministic policies in the MDP. We show that this formulation is equivalent to the AL objective and that solving this problem using the FW algorithm is equivalent well-known Projection method of Abbeel and Ng (2004). This insight allows us to analyze AL with tools from convex optimization literature and derive tighter convergence bounds on AL. Specifically, we show that a variation of the FW method that is based on taking "away steps" achieves a linear rate of convergence when applied to AL and that a stochastic version of the FW algorithm can be used to avoid precise estimation of feature expectations. We also experimentally show that this version outperforms the FW baseline. To the best of our knowledge, this is the first work that shows linear convergence rates for AL.
Inverse Reinforcement Learning in Contextual MDPs
May 29, 2019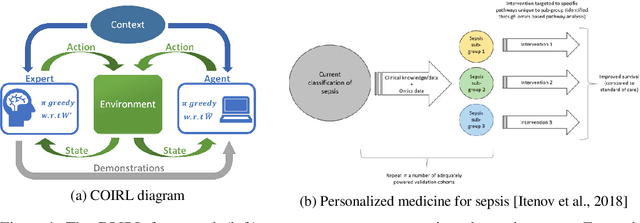
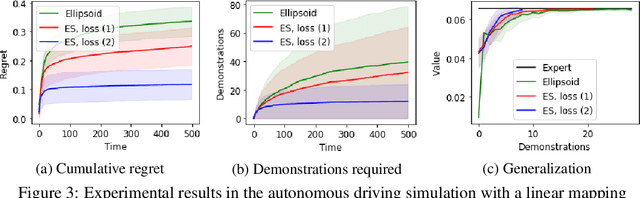
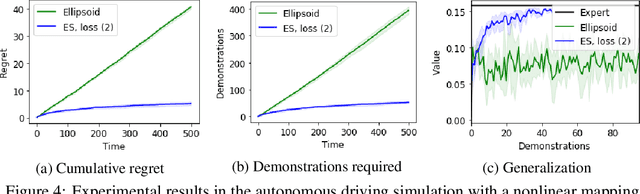
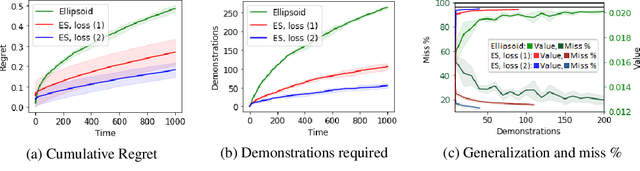
We consider the Inverse Reinforcement Learning (IRL) problem in Contextual Markov Decision Processes (CMDPs). Here, the reward of the environment, which is not available to the agent, depends on a static parameter referred to as the context. Each context defines an MDP (with a different reward signal), and the agent is provided demonstrations by an expert, for different contexts. The goal is to learn a mapping from contexts to rewards, such that planning with respect to the induced reward will perform similarly to the expert, even for unseen contexts. We suggest two learning algorithms for this scenario. (1) For rewards that are a linear function of the context, we provide a method that is guaranteed to return an $\epsilon$-optimal solution after a polynomial number of demonstrations. (2) For general reward functions, we propose black-box descent methods based on evolutionary strategies capable of working with nonlinear estimators (e.g., neural networks). We evaluate our algorithms in autonomous driving and medical treatment simulations and demonstrate their ability to learn and generalize to unseen contexts.
Average reward reinforcement learning with unknown mixing times
May 23, 2019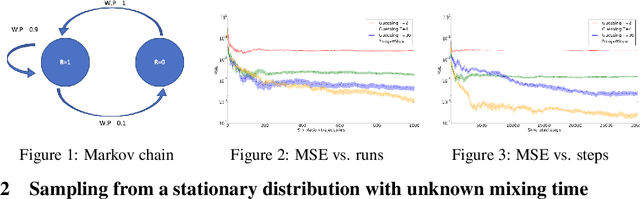
We derive and analyze learning algorithms for policy evaluation, apprenticeship learning, and policy gradient for average reward criteria. Existing algorithms explicitly require an upper bound on the mixing time. In contrast, we build on ideas from Markov chain theory and derive sampling algorithms that do not require such an upper bound. For these algorithms, we provide theoretical bounds on their sample-complexity and running time.
Action Assembly: Sparse Imitation Learning for Text Based Games with Combinatorial Action Spaces
May 23, 2019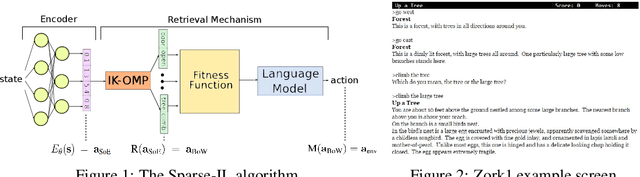
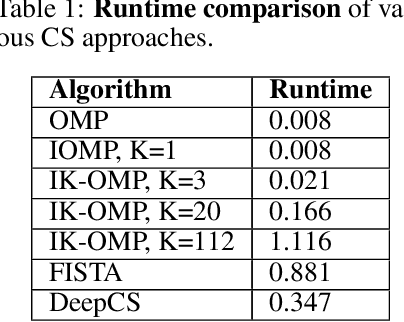
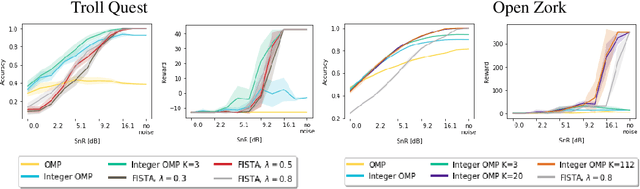
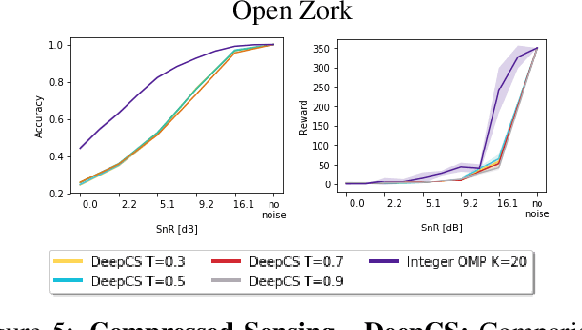
We propose a computationally efficient algorithm that combines compressed sensing with imitation learning to solve sequential decision making text-based games with combinatorial action spaces. We propose a variation of the compressed sensing algorithm Orthogonal Matching Pursuit (OMP), that we call IK-OMP, and show that it can recover a bag-of-words from a sum of the individual word embeddings, even in the presence of noise. We incorporate IK-OMP into a supervised imitation learning setting and show that this algorithm, called Sparse Imitation Learning (Sparse-IL), solves the entire text-based game of Zork1 with an action space of approximately 10 million actions using imperfect, noisy demonstrations.
Planning in Hierarchical Reinforcement Learning: Guarantees for Using Local Policies
Feb 26, 2019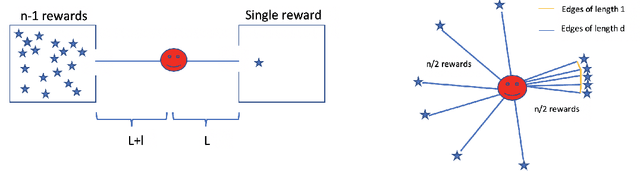
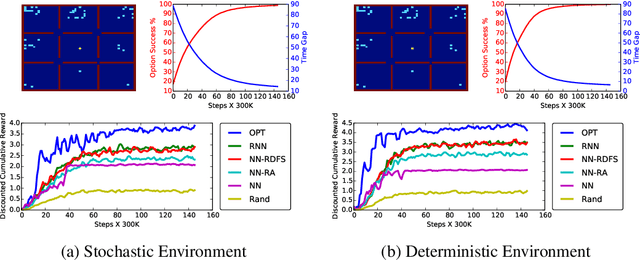
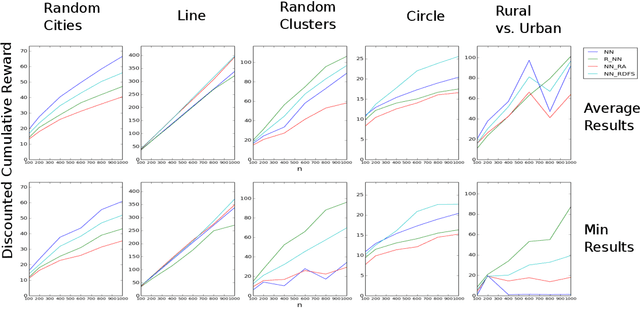
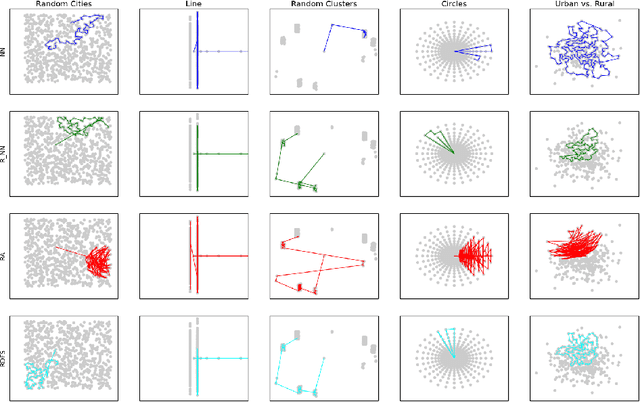
We consider a settings of hierarchical reinforcement learning, in which the reward is a sum of components. For each component we are given a policy that maximizes it and our goal is to assemble a policy from the individual policies that maximizes the sum of the components. We provide theoretical guarantees for assembling such policies in deterministic MDPs with collectible rewards. Our approach builds on formulating this problem as a traveling salesman problem with discounted reward. We focus on local solutions, i.e., policies that only use information from the current state; thus, they are easy to implement and do not require substantial computational resources. We propose three local stochastic policies and prove that they guarantee better performance than any deterministic local policy in the worst case; experimental results suggest that they also perform better on average.
Deep Neural Linear Bandits: Overcoming Catastrophic Forgetting through Likelihood Matching
Jan 24, 2019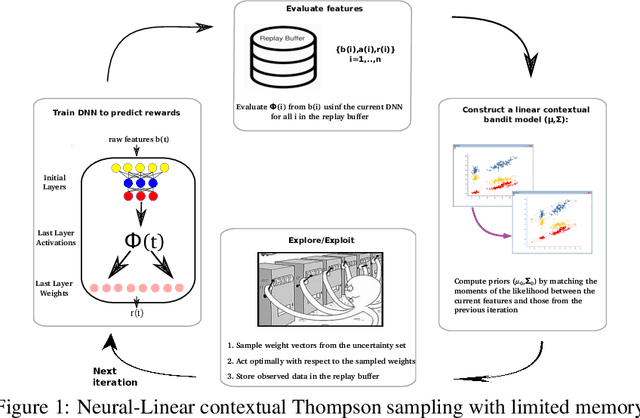
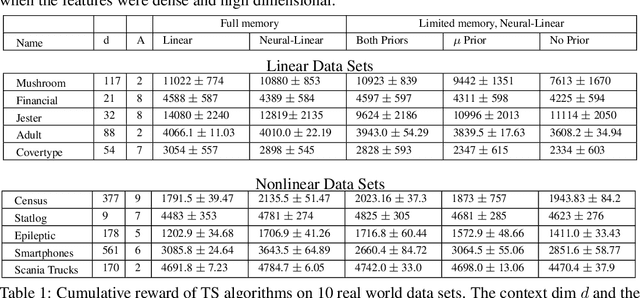


We study the neural-linear bandit model for solving sequential decision-making problems with high dimensional side information. Neural-linear bandits leverage the representation power of deep neural networks and combine it with efficient exploration mechanisms, designed for linear contextual bandits, on top of the last hidden layer. Since the representation is being optimized during learning, information regarding exploration with "old" features is lost. Here, we propose the first limited memory neural-linear bandit that is resilient to this phenomenon, which we term catastrophic forgetting. We evaluate our method on a variety of real-world data sets, including regression, classification, and sentiment analysis, and observe that our algorithm is resilient to catastrophic forgetting and achieves superior performance.
Learn What Not to Learn: Action Elimination with Deep Reinforcement Learning
Sep 06, 2018
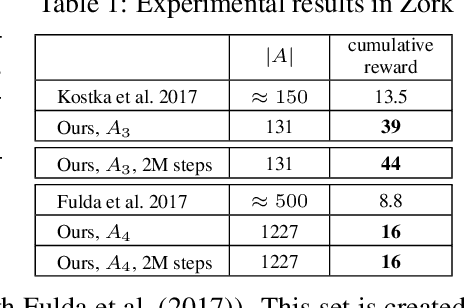
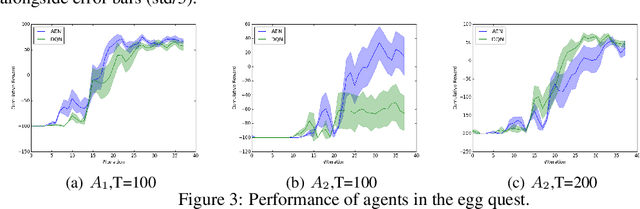
Learning how to act when there are many available actions in each state is a challenging task for Reinforcement Learning (RL) agents, especially when many of the actions are redundant or irrelevant. In such cases, it is sometimes easier to learn which actions not to take. In this work, we propose the Action-Elimination Deep Q-Network (AE-DQN) architecture that combines a Deep RL algorithm with an Action Elimination Network (AEN) that eliminates sub-optimal actions. The AEN is trained to predict invalid actions, supervised by an external elimination signal provided by the environment. Simulations demonstrate a considerable speedup and added robustness over vanilla DQN in text-based games with over a thousand discrete actions.
Deep Learning Reconstruction of Ultra-Short Pulses
Mar 15, 2018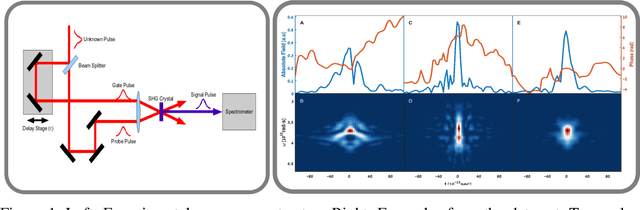
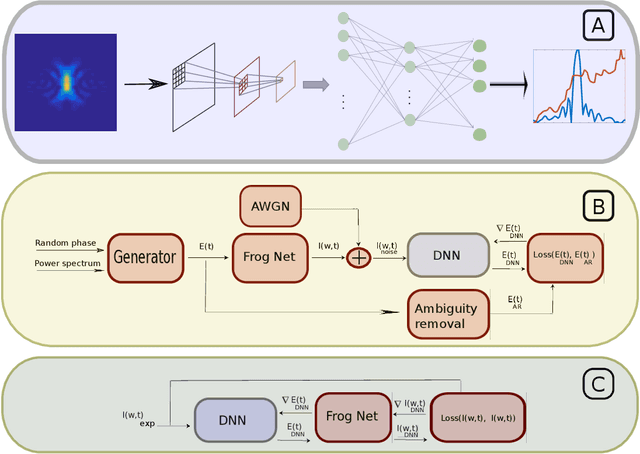
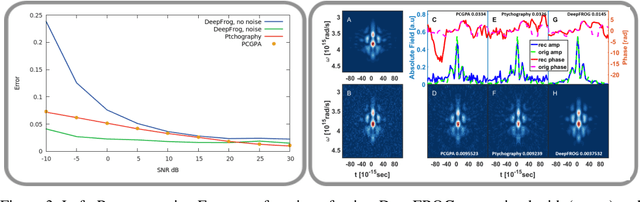
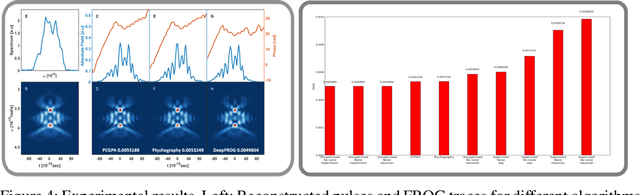
Ultra-short laser pulses with femtosecond to attosecond pulse duration are the shortest systematic events humans can create. Characterization (amplitude and phase) of these pulses is a key ingredient in ultrafast science, e.g., exploring chemical reactions and electronic phase transitions. Here, we propose and demonstrate, numerically and experimentally, the first deep neural network technique to reconstruct ultra-short optical pulses. We anticipate that this approach will extend the range of ultrashort laser pulses that can be characterized, e.g., enabling to diagnose very weak attosecond pulses.