 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntities as Experts: Sparse Memory Access with Entity Supervision
Apr 15, 2020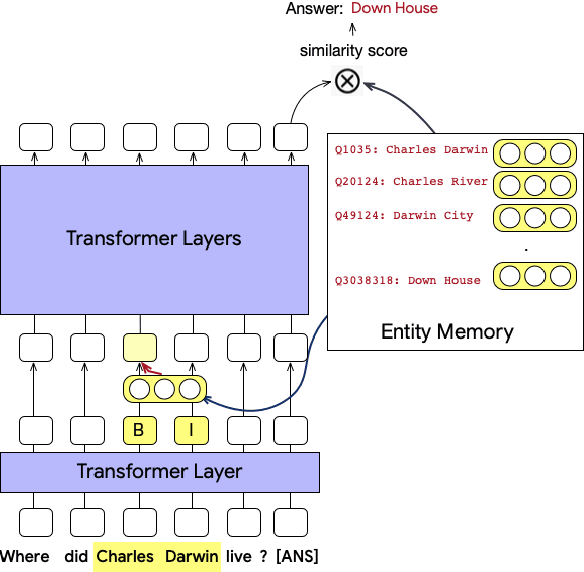
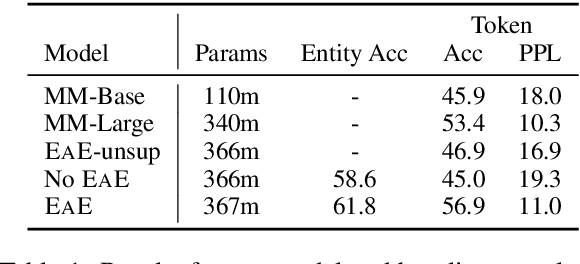
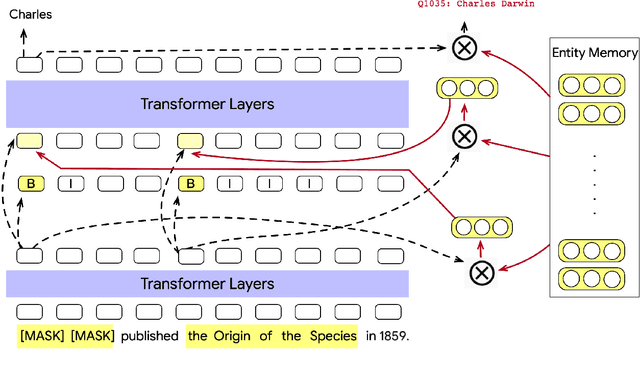
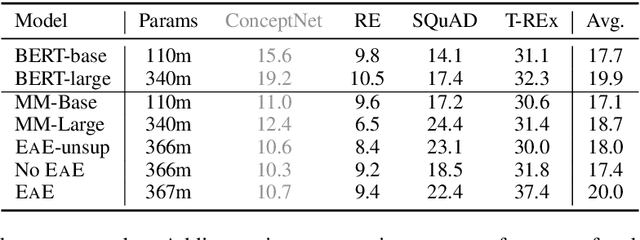
We focus on the problem of capturing declarative knowledge in the learned parameters of a language model. We introduce a new model, Entities as Experts (EaE), that can access distinct memories of the entities mentioned in a piece of text. Unlike previous efforts to integrate entity knowledge into sequence models, EaE's entity representations are learned directly from text. These representations capture sufficient knowledge to answer TriviaQA questions such as "Which Dr. Who villain has been played by Roger Delgado, Anthony Ainley, Eric Roberts?". EaE outperforms a Transformer model with $30\times$ the parameters on this task. According to the Lama knowledge probes, EaE also contains more factual knowledge than a similar sized Bert. We show that associating parameters with specific entities means that EaE only needs to access a fraction of its parameters at inference time, and we show that the correct identification, and representation, of entities is essential to EaE's performance. We also argue that the discrete and independent entity representations in EaE make it more modular and interpretable than the Transformer architecture on which it is based.
TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages
Mar 10, 2020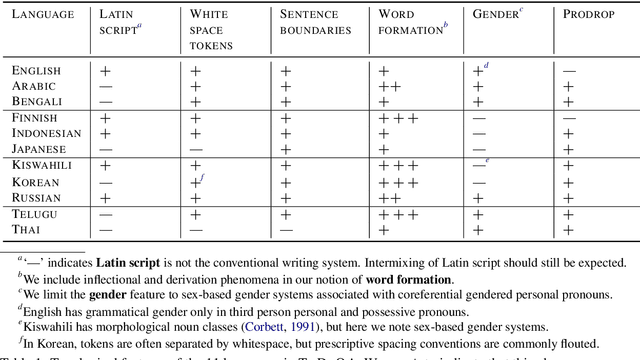
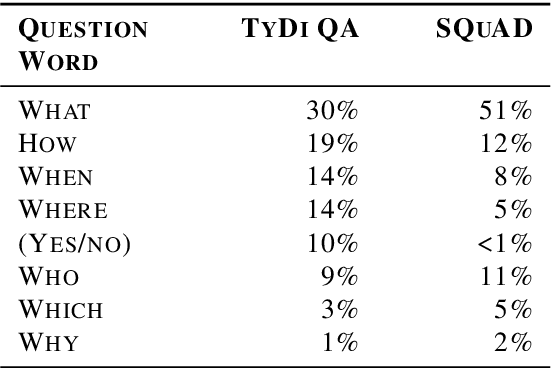

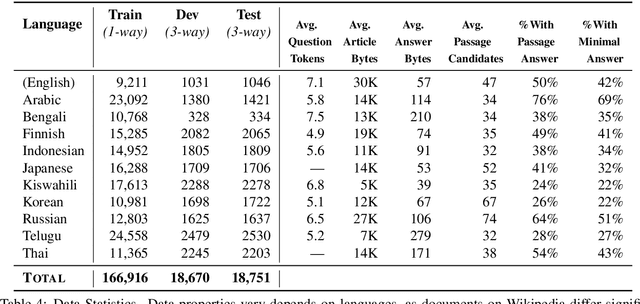
Confidently making progress on multilingual modeling requires challenging, trustworthy evaluations. We present TyDi QA---a question answering dataset covering 11 typologically diverse languages with 204K question-answer pairs. The languages of TyDi QA are diverse with regard to their typology---the set of linguistic features each language expresses---such that we expect models performing well on this set to generalize across a large number of the world's languages. We present a quantitative analysis of the data quality and example-level qualitative linguistic analyses of observed language phenomena that would not be found in English-only corpora. To provide a realistic information-seeking task and avoid priming effects, questions are written by people who want to know the answer, but don't know the answer yet, and the data is collected directly in each language without the use of translation.
Learning Cross-Context Entity Representations from Text
Jan 11, 2020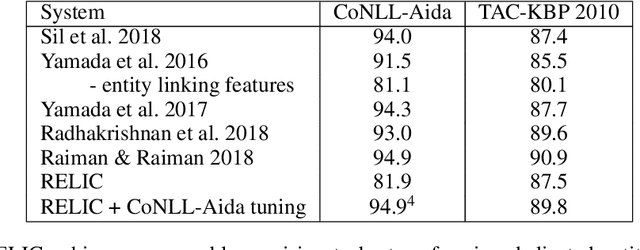
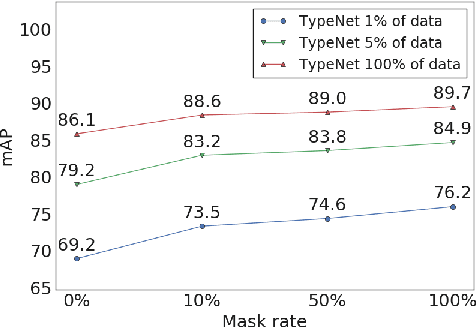

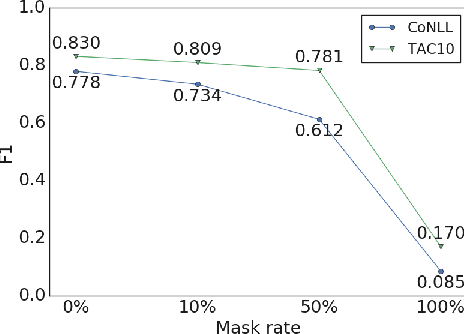
Language modeling tasks, in which words, or word-pieces, are predicted on the basis of a local context, have been very effective for learning word embeddings and context dependent representations of phrases. Motivated by the observation that efforts to code world knowledge into machine readable knowledge bases or human readable encyclopedias tend to be entity-centric, we investigate the use of a fill-in-the-blank task to learn context independent representations of entities from the text contexts in which those entities were mentioned. We show that large scale training of neural models allows us to learn high quality entity representations, and we demonstrate successful results on four domains: (1) existing entity-level typing benchmarks, including a 64% error reduction over previous work on TypeNet (Murty et al., 2018); (2) a novel few-shot category reconstruction task; (3) existing entity linking benchmarks, where we match the state-of-the-art on CoNLL-Aida without linking-specific features and obtain a score of 89.8% on TAC-KBP 2010 without using any alias table, external knowledge base or in domain training data and (4) answering trivia questions, which uniquely identify entities. Our global entity representations encode fine-grained type categories, such as Scottish footballers, and can answer trivia questions such as: Who was the last inmate of Spandau jail in Berlin?
Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
Jun 14, 2019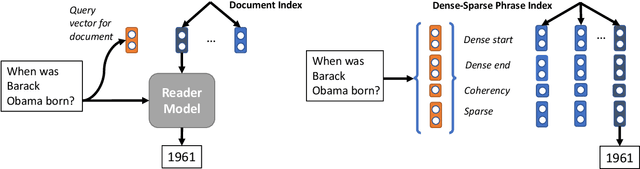
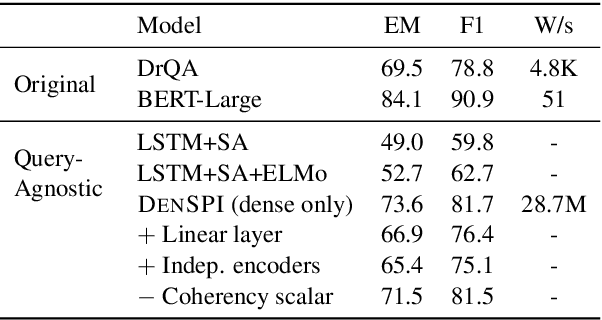
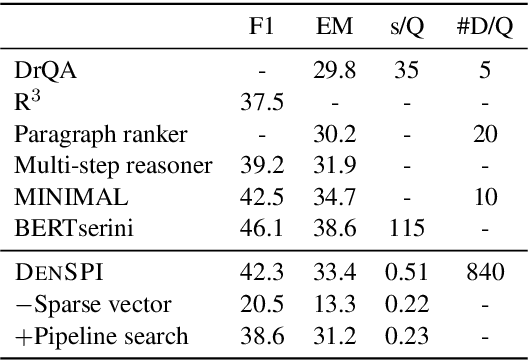

Existing open-domain question answering (QA) models are not suitable for real-time usage because they need to process several long documents on-demand for every input query. In this paper, we introduce the query-agnostic indexable representation of document phrases that can drastically speed up open-domain QA and also allows us to reach long-tail targets. In particular, our dense-sparse phrase encoding effectively captures syntactic, semantic, and lexical information of the phrases and eliminates the pipeline filtering of context documents. Leveraging optimization strategies, our model can be trained in a single 4-GPU server and serve entire Wikipedia (up to 60 billion phrases) under 2TB with CPUs only. Our experiments on SQuAD-Open show that our model is more accurate than DrQA (Chen et al., 2017) with 6000x reduced computational cost, which translates into at least 58x faster end-to-end inference benchmark on CPUs.
Matching the Blanks: Distributional Similarity for Relation Learning
Jun 07, 2019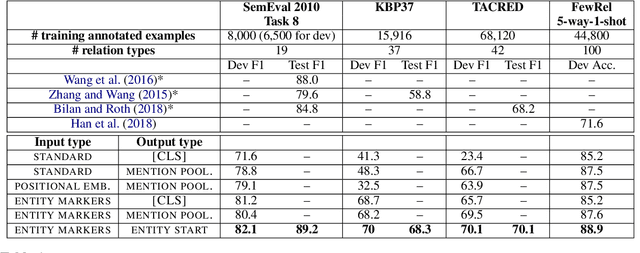
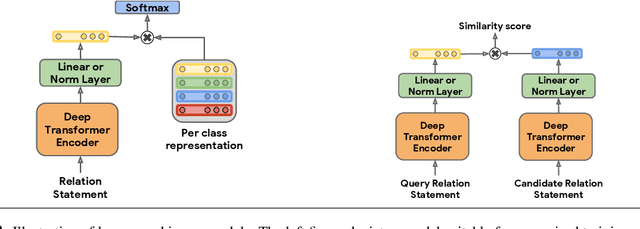

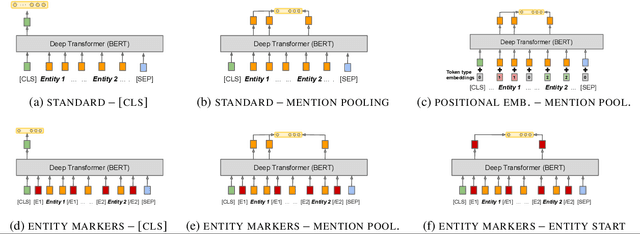
General purpose relation extractors, which can model arbitrary relations, are a core aspiration in information extraction. Efforts have been made to build general purpose extractors that represent relations with their surface forms, or which jointly embed surface forms with relations from an existing knowledge graph. However, both of these approaches are limited in their ability to generalize. In this paper, we build on extensions of Harris' distributional hypothesis to relations, as well as recent advances in learning text representations (specifically, BERT), to build task agnostic relation representations solely from entity-linked text. We show that these representations significantly outperform previous work on exemplar based relation extraction (FewRel) even without using any of that task's training data. We also show that models initialized with our task agnostic representations, and then tuned on supervised relation extraction datasets, significantly outperform the previous methods on SemEval 2010 Task 8, KBP37, and TACRED.
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
May 24, 2019

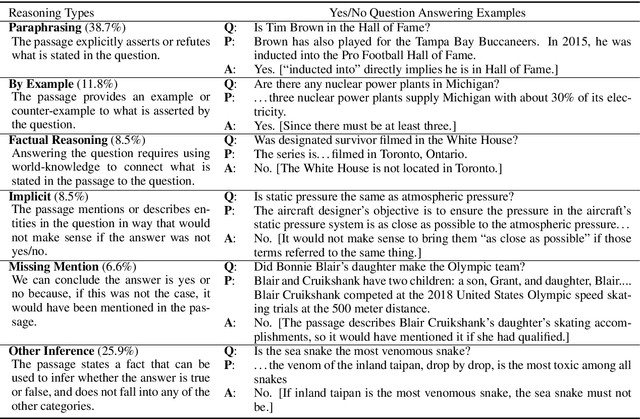
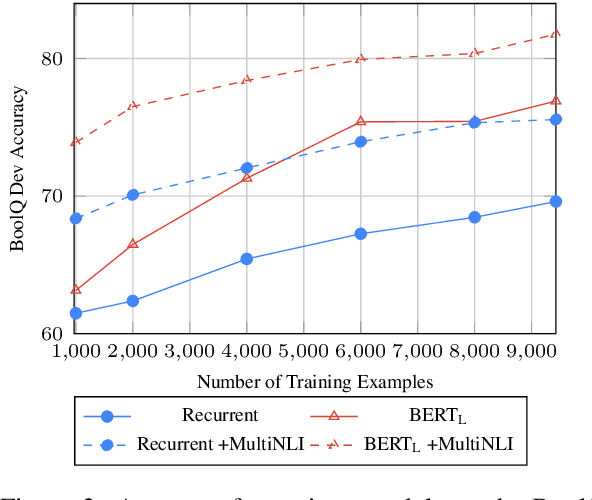
In this paper we study yes/no questions that are naturally occurring --- meaning that they are generated in unprompted and unconstrained settings. We build a reading comprehension dataset, BoolQ, of such questions, and show that they are unexpectedly challenging. They often query for complex, non-factoid information, and require difficult entailment-like inference to solve. We also explore the effectiveness of a range of transfer learning baselines. We find that transferring from entailment data is more effective than transferring from paraphrase or extractive QA data, and that it, surprisingly, continues to be very beneficial even when starting from massive pre-trained language models such as BERT. Our best method trains BERT on MultiNLI and then re-trains it on our train set. It achieves 80.4% accuracy compared to 90% accuracy of human annotators (and 62% majority-baseline), leaving a significant gap for future work.
Incremental Reading for Question Answering
Jan 15, 2019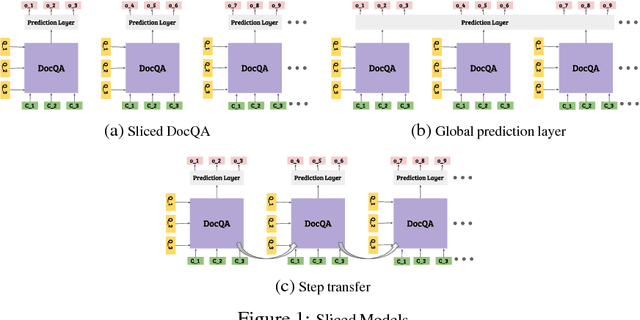

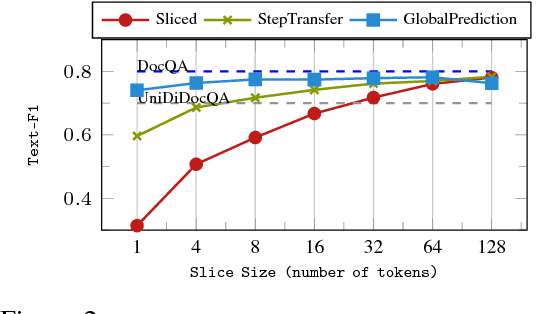
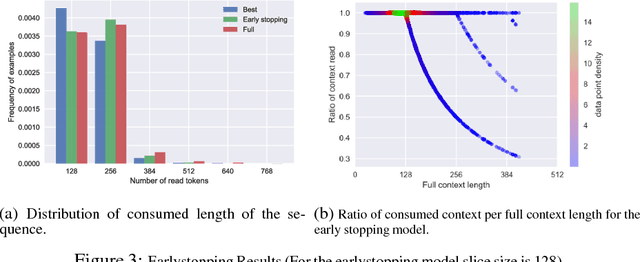
Any system which performs goal-directed continual learning must not only learn incrementally but process and absorb information incrementally. Such a system also has to understand when its goals have been achieved. In this paper, we consider these issues in the context of question answering. Current state-of-the-art question answering models reason over an entire passage, not incrementally. As we will show, naive approaches to incremental reading, such as restriction to unidirectional language models in the model, perform poorly. We present extensions to the DocQA [2] model to allow incremental reading without loss of accuracy. The model also jointly learns to provide the best answer given the text that is seen so far and predict whether this best-so-far answer is sufficient.
Phrase-Indexed Question Answering: A New Challenge for Scalable Document Comprehension
Sep 26, 2018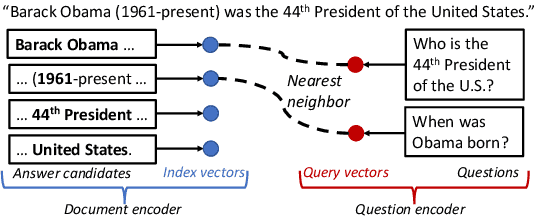
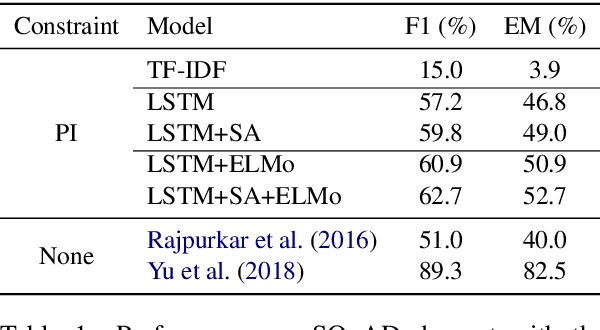

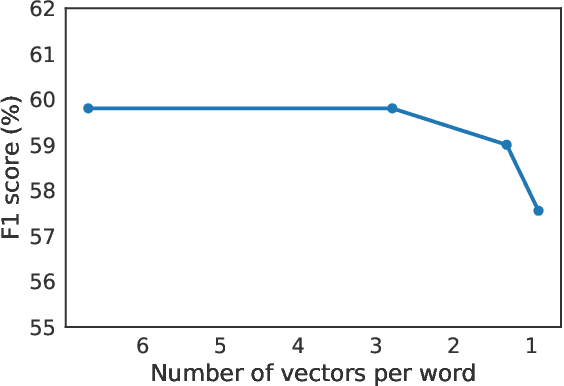
We formalize a new modular variant of current question answering tasks by enforcing complete independence of the document encoder from the question encoder. This formulation addresses a key challenge in machine comprehension by requiring a standalone representation of the document discourse. It additionally leads to a significant scalability advantage since the encoding of the answer candidate phrases in the document can be pre-computed and indexed offline for efficient retrieval. We experiment with baseline models for the new task, which achieve a reasonable accuracy but significantly underperform unconstrained QA models. We invite the QA research community to engage in Phrase-Indexed Question Answering (PIQA, pika) for closing the gap. The leaderboard is at: nlp.cs.washington.edu/piqa
Multi-Mention Learning for Reading Comprehension with Neural Cascades
May 30, 2018
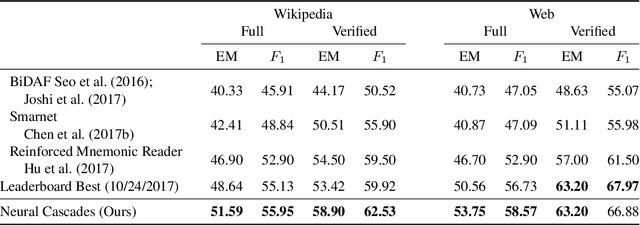
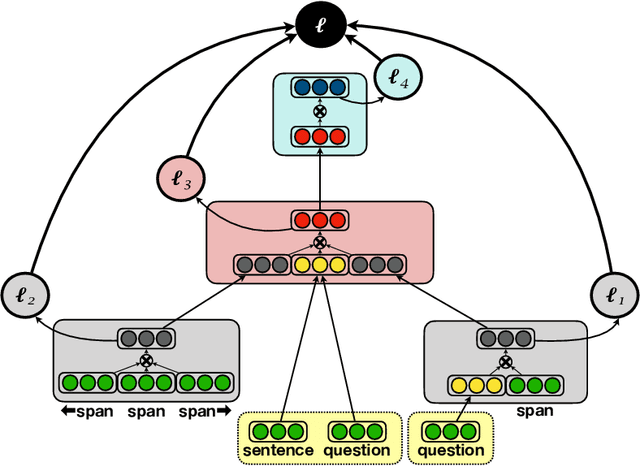

Reading comprehension is a challenging task, especially when executed across longer or across multiple evidence documents, where the answer is likely to reoccur. Existing neural architectures typically do not scale to the entire evidence, and hence, resort to selecting a single passage in the document (either via truncation or other means), and carefully searching for the answer within that passage. However, in some cases, this strategy can be suboptimal, since by focusing on a specific passage, it becomes difficult to leverage multiple mentions of the same answer throughout the document. In this work, we take a different approach by constructing lightweight models that are combined in a cascade to find the answer. Each submodel consists only of feed-forward networks equipped with an attention mechanism, making it trivially parallelizable. We show that our approach can scale to approximately an order of magnitude larger evidence documents and can aggregate information at the representation level from multiple mentions of each answer candidate across the document. Empirically, our approach achieves state-of-the-art performance on both the Wikipedia and web domains of the TriviaQA dataset, outperforming more complex, recurrent architectures.
Learning Recurrent Span Representations for Extractive Question Answering
Mar 17, 2017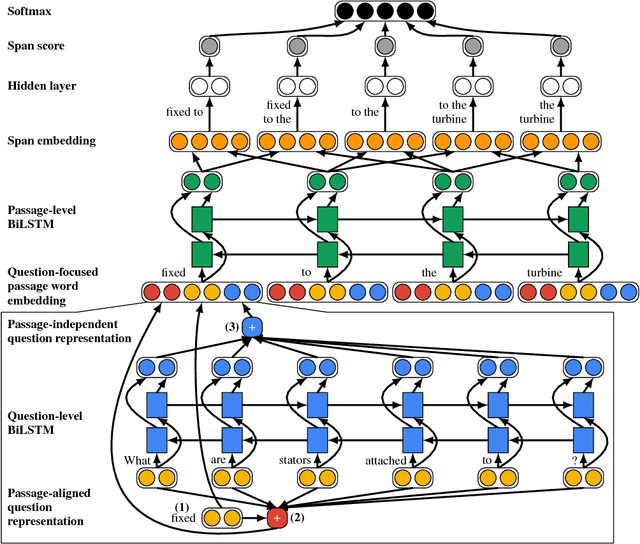
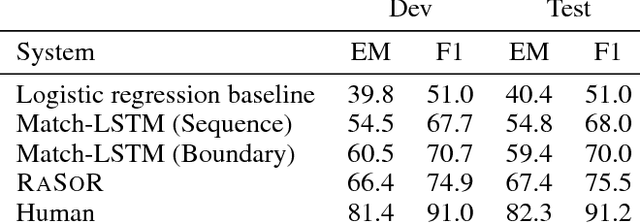

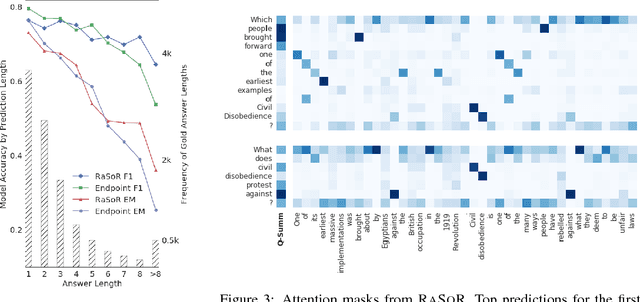
The reading comprehension task, that asks questions about a given evidence document, is a central problem in natural language understanding. Recent formulations of this task have typically focused on answer selection from a set of candidates pre-defined manually or through the use of an external NLP pipeline. However, Rajpurkar et al. (2016) recently released the SQuAD dataset in which the answers can be arbitrary strings from the supplied text. In this paper, we focus on this answer extraction task, presenting a novel model architecture that efficiently builds fixed length representations of all spans in the evidence document with a recurrent network. We show that scoring explicit span representations significantly improves performance over other approaches that factor the prediction into separate predictions about words or start and end markers. Our approach improves upon the best published results of Wang & Jiang (2016) by 5% and decreases the error of Rajpurkar et al.'s baseline by > 50%.