 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Adversarial Examples Created Equal? A Learnable Weighted Minimax Risk for Robustness under Non-uniform Attacks
Oct 24, 2020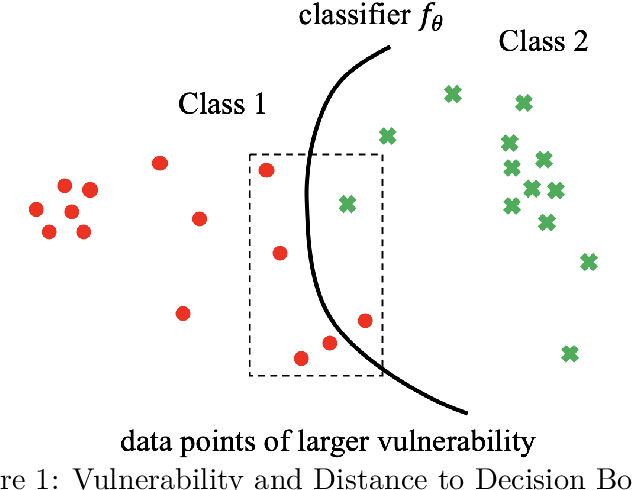
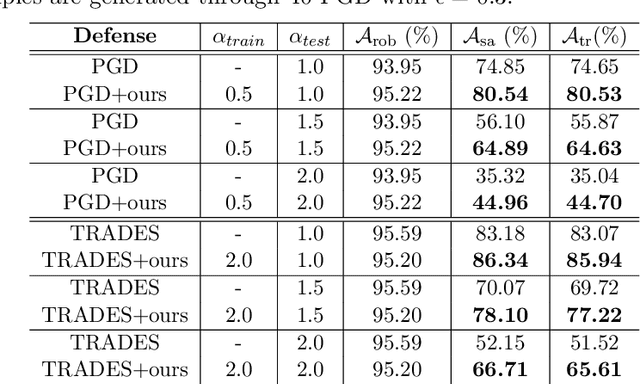
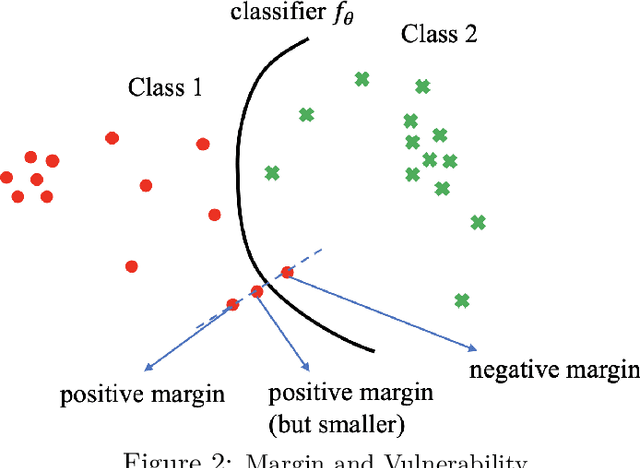
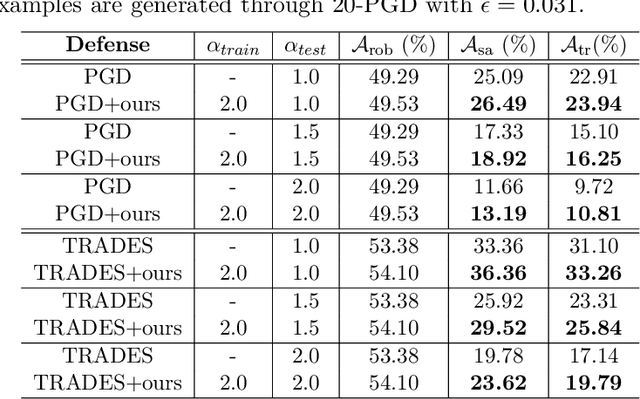
Adversarial Training is proved to be an efficient method to defend against adversarial examples, being one of the few defenses that withstand strong attacks. However, traditional defense mechanisms assume a uniform attack over the examples according to the underlying data distribution, which is apparently unrealistic as the attacker could choose to focus on more vulnerable examples. We present a weighted minimax risk optimization that defends against non-uniform attacks, achieving robustness against adversarial examples under perturbed test data distributions. Our modified risk considers importance weights of different adversarial examples and focuses adaptively on harder examples that are wrongly classified or at higher risk of being classified incorrectly. The designed risk allows the training process to learn a strong defense through optimizing the importance weights. The experiments show that our model significantly improves state-of-the-art adversarial accuracy under non-uniform attacks without a significant drop under uniform attacks.
FLAG: Adversarial Data Augmentation for Graph Neural Networks
Oct 19, 2020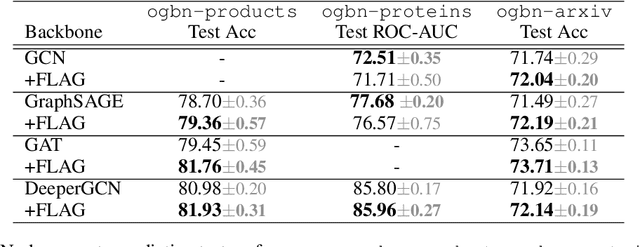
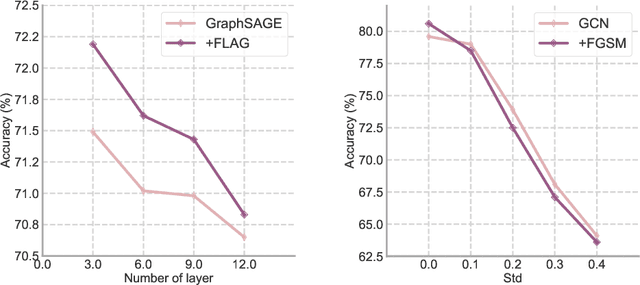

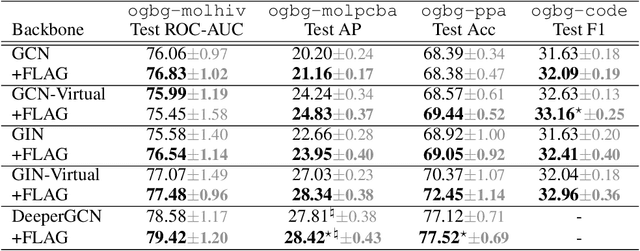
Data augmentation helps neural networks generalize better, but it remains an open question how to effectively augment graph data to enhance the performance of GNNs (Graph Neural Networks). While most existing graph regularizers focus on augmenting graph topological structures by adding/removing edges, we offer a novel direction to augment in the input node feature space for better performance. We propose a simple but effective solution, FLAG (Free Large-scale Adversarial Augmentation on Graphs), which iteratively augments node features with gradient-based adversarial perturbations during training, and boosts performance at test time. Empirically, FLAG can be easily implemented with a dozen lines of code and is flexible enough to function with any GNN backbone, on a wide variety of large-scale datasets, and in both transductive and inductive settings. Without modifying a model's architecture or training setup, FLAG yields a consistent and salient performance boost across both node and graph classification tasks. Using FLAG, we reach state-of-the-art performance on the large-scale ogbg-molpcba, ogbg-ppa, and ogbg-code datasets.
Towards Accurate Quantization and Pruning via Data-free Knowledge Transfer
Oct 14, 2020
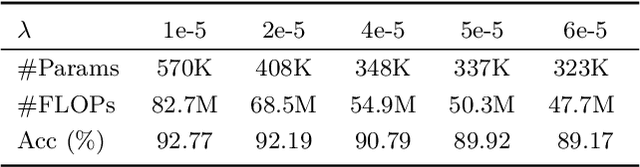
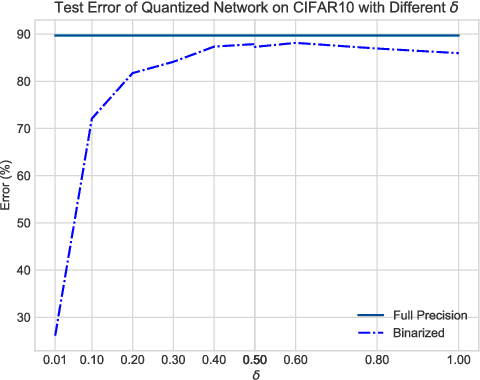
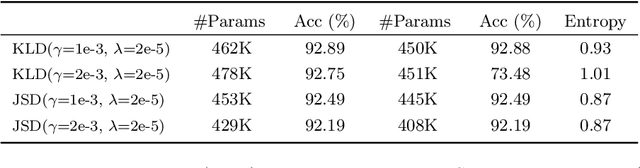
When large scale training data is available, one can obtain compact and accurate networks to be deployed in resource-constrained environments effectively through quantization and pruning. However, training data are often protected due to privacy concerns and it is challenging to obtain compact networks without data. We study data-free quantization and pruning by transferring knowledge from trained large networks to compact networks. Auxiliary generators are simultaneously and adversarially trained with the targeted compact networks to generate synthetic inputs that maximize the discrepancy between the given large network and its quantized or pruned version. We show theoretically that the alternating optimization for the underlying minimax problem converges under mild conditions for pruning and quantization. Our data-free compact networks achieve competitive accuracy to networks trained and fine-tuned with training data. Our quantized and pruned networks achieve good performance while being more compact and lightweight. Further, we demonstrate that the compact structure and corresponding initialization from the Lottery Ticket Hypothesis can also help in data-free training.
Data Augmentation for Meta-Learning
Oct 14, 2020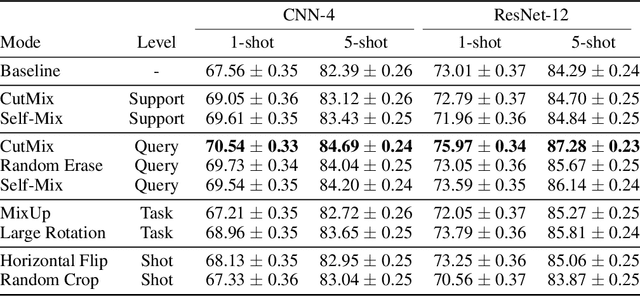
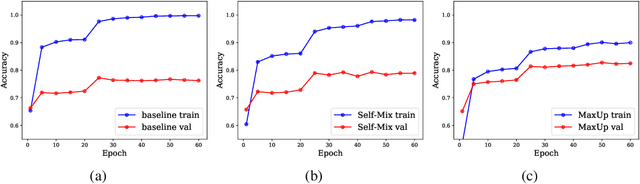
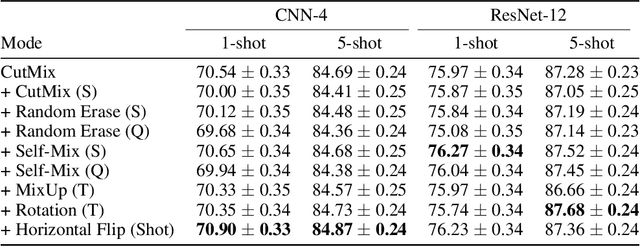
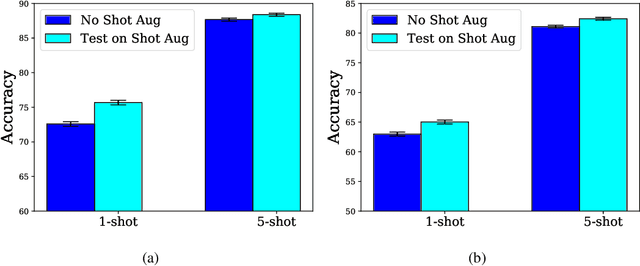
Conventional image classifiers are trained by randomly sampling mini-batches of images. To achieve state-of-the-art performance, sophisticated data augmentation schemes are used to expand the amount of training data available for sampling. In contrast, meta-learning algorithms sample not only images, but classes as well. We investigate how data augmentation can be used not only to expand the number of images available per class, but also to generate entirely new classes. We systematically dissect the meta-learning pipeline and investigate the distinct ways in which data augmentation can be integrated at both the image and class levels. Our proposed meta-specific data augmentation significantly improves the performance of meta-learners on few-shot classification benchmarks.
Random Network Distillation as a Diversity Metric for Both Image and Text Generation
Oct 13, 2020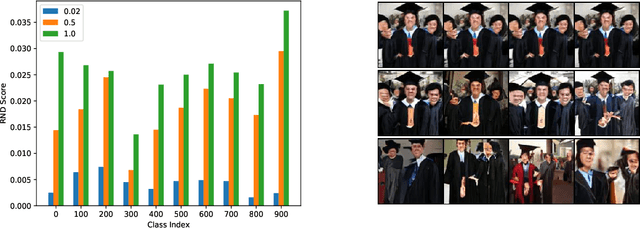
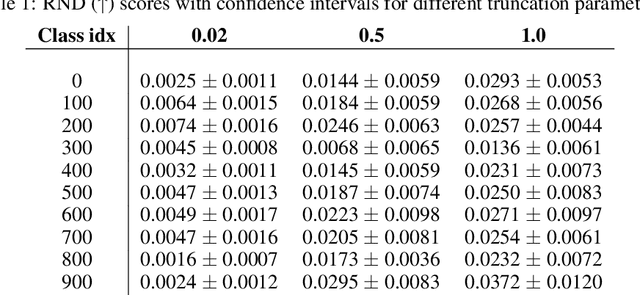
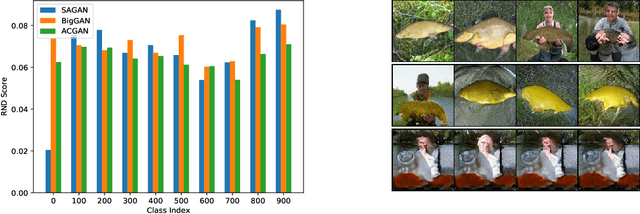
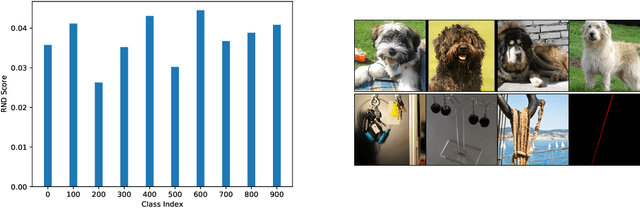
Generative models are increasingly able to produce remarkably high quality images and text. The community has developed numerous evaluation metrics for comparing generative models. However, these metrics do not effectively quantify data diversity. We develop a new diversity metric that can readily be applied to data, both synthetic and natural, of any type. Our method employs random network distillation, a technique introduced in reinforcement learning. We validate and deploy this metric on both images and text. We further explore diversity in few-shot image generation, a setting which was previously difficult to evaluate.
ProportionNet: Balancing Fairness and Revenue for Auction Design with Deep Learning
Oct 13, 2020
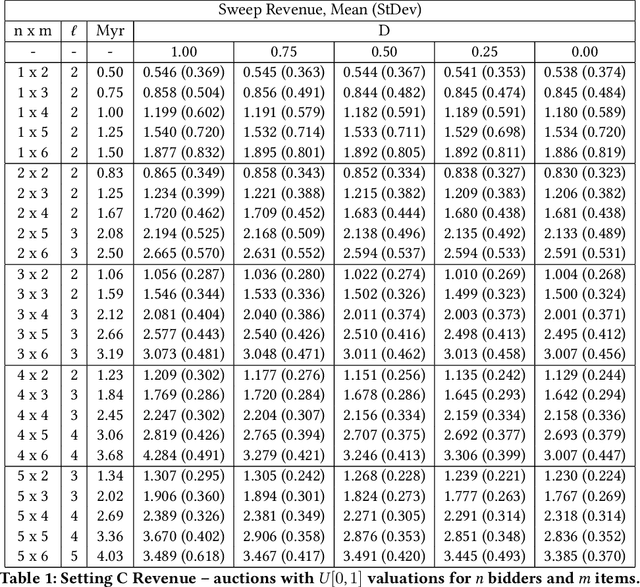
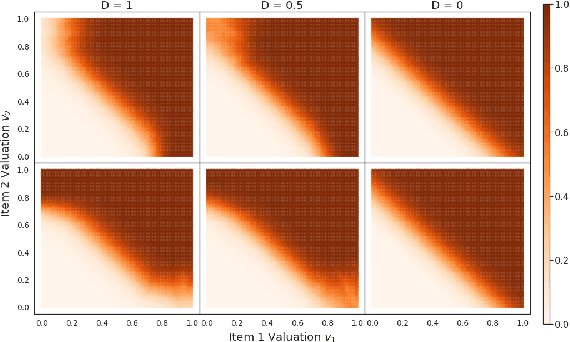
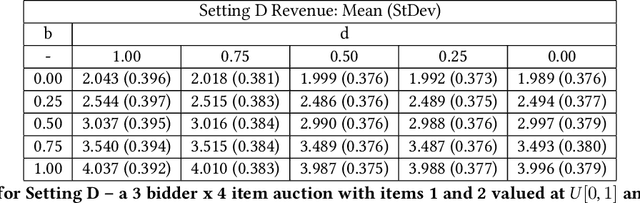
The design of revenue-maximizing auctions with strong incentive guarantees is a core concern of economic theory. Computational auctions enable online advertising, sourcing, spectrum allocation, and myriad financial markets. Analytic progress in this space is notoriously difficult; since Myerson's 1981 work characterizing single-item optimal auctions, there has been limited progress outside of restricted settings. A recent paper by D\"utting et al. circumvents analytic difficulties by applying deep learning techniques to, instead, approximate optimal auctions. In parallel, new research from Ilvento et al. and other groups has developed notions of fairness in the context of auction design. Inspired by these advances, in this paper, we extend techniques for approximating auctions using deep learning to address concerns of fairness while maintaining high revenue and strong incentive guarantees.
Prepare for the Worst: Generalizing across Domain Shifts with Adversarial Batch Normalization
Sep 21, 2020
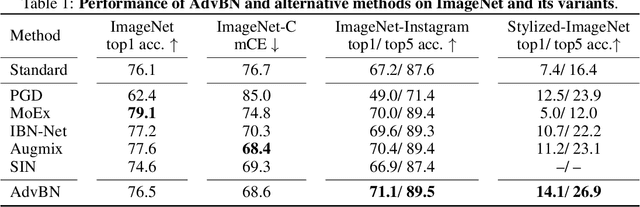

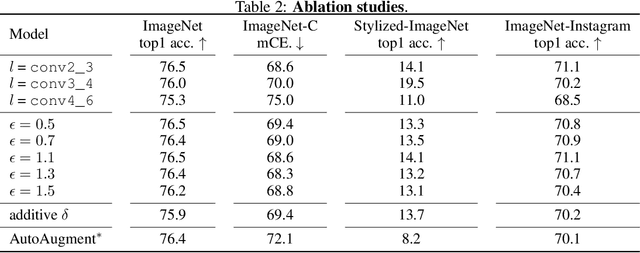
Adversarial training is the industry standard for producing models that are robust to small adversarial perturbations. However, machine learning practitioners need models that are robust to domain shifts that occur naturally, such as changes in the style or illumination of input images. Such changes in input distribution have been effectively modeled as shifts in the mean and variance of deep image features. We adapt adversarial training by adversarially perturbing these feature statistics, rather than image pixels, to produce models that are robust to domain shift. We also visualize images from adversarially crafted distributions. Our method, Adversarial Batch Normalization (AdvBN), significantly improves the performance of ResNet-50 on ImageNet-C (+8.1%), Stylized-ImageNet (+6.7%), and ImageNet-Instagram (+3.9%) over standard training practices. In addition, we demonstrate that AdvBN can also improve generalization on semantic segmentation.
Certifying Confidence via Randomized Smoothing
Sep 17, 2020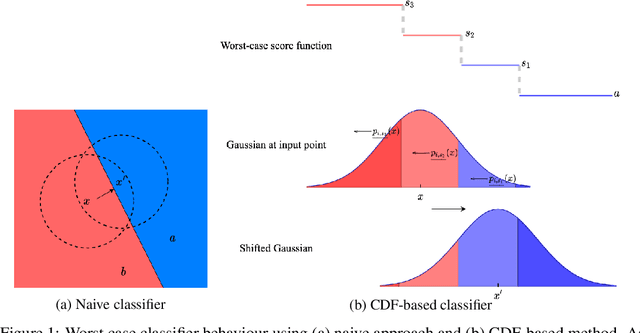
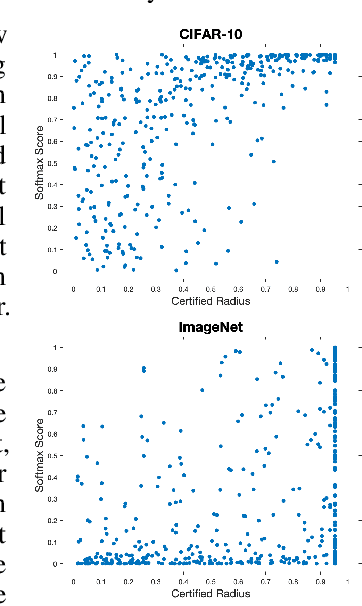

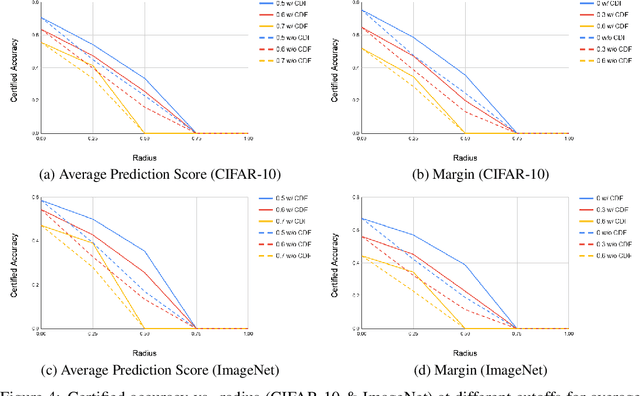
Randomized smoothing has been shown to provide good certified-robustness guarantees for high-dimensional classification problems. It uses the probabilities of predicting the top two most-likely classes around an input point under a smoothing distribution to generate a certified radius for a classifier's prediction. However, most smoothing methods do not give us any information about the \emph{confidence} with which the underlying classifier (e.g., deep neural network) makes a prediction. In this work, we propose a method to generate certified radii for the prediction confidence of the smoothed classifier. We consider two notions for quantifying confidence: average prediction score of a class and the margin by which the average prediction score of one class exceeds that of another. We modify the Neyman-Pearson lemma (a key theorem in randomized smoothing) to design a procedure for computing the certified radius where the confidence is guaranteed to stay above a certain threshold. Our experimental results on CIFAR-10 and ImageNet datasets show that using information about the distribution of the confidence scores allows us to achieve a significantly better certified radius than ignoring it. Thus, we demonstrate that extra information about the base classifier at the input point can help improve certified guarantees for the smoothed classifier.
Witches' Brew: Industrial Scale Data Poisoning via Gradient Matching
Sep 04, 2020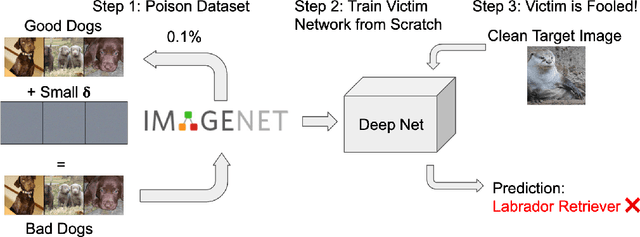
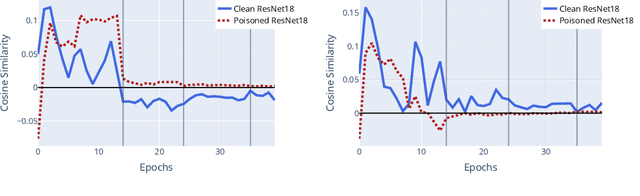

Data Poisoning attacks involve an attacker modifying training data to maliciouslycontrol a model trained on this data. Previous poisoning attacks against deep neural networks have been limited in scope and success, working only in simplified settings or being prohibitively expensive for large datasets. In this work, we focus on a particularly malicious poisoning attack that is both "from scratch" and"clean label", meaning we analyze an attack that successfully works against new, randomly initialized models, and is nearly imperceptible to humans, all while perturbing only a small fraction of the training data. The central mechanism of this attack is matching the gradient direction of malicious examples. We analyze why this works, supplement with practical considerations. and show its threat to real-world practitioners, finding that it is the first poisoning method to cause targeted misclassification in modern deep networks trained from scratch on a full-sized, poisoned ImageNet dataset. Finally we demonstrate the limitations of existing defensive strategies against such an attack, concluding that data poisoning is a credible threat, even for large-scale deep learning systems.
WrapNet: Neural Net Inference with Ultra-Low-Resolution Arithmetic
Jul 26, 2020
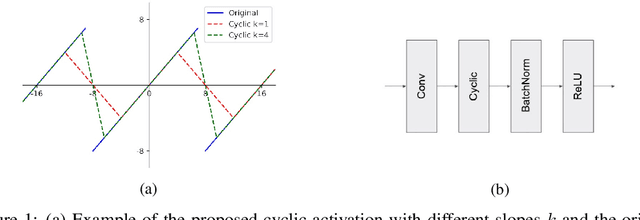

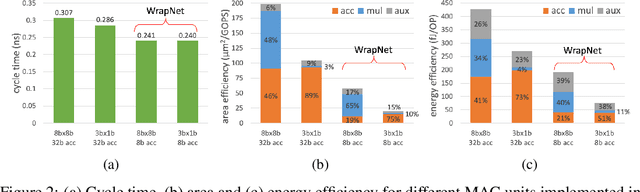
Low-resolution neural networks represent both weights and activations with few bits, drastically reducing the multiplication complexity. Nonetheless, these products are accumulated using high-resolution (typically 32-bit) additions, an operation that dominates the arithmetic complexity of inference when using extreme quantization (e.g., binary weights). To further optimize inference, we propose a method that adapts neural networks to use low-resolution (8-bit) additions in the accumulators, achieving classification accuracy comparable to their 32-bit counterparts. We achieve resilience to low-resolution accumulation by inserting a cyclic activation layer, as well as an overflow penalty regularizer. We demonstrate the efficacy of our approach on both software and hardware platforms.