 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting Robustness Against Unforeseen Adversaries
Aug 21, 2019
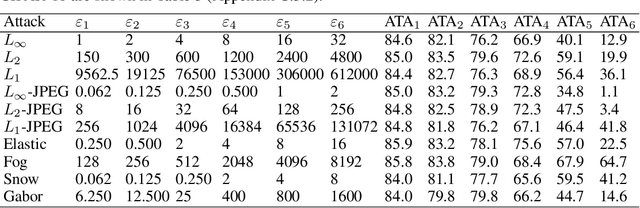
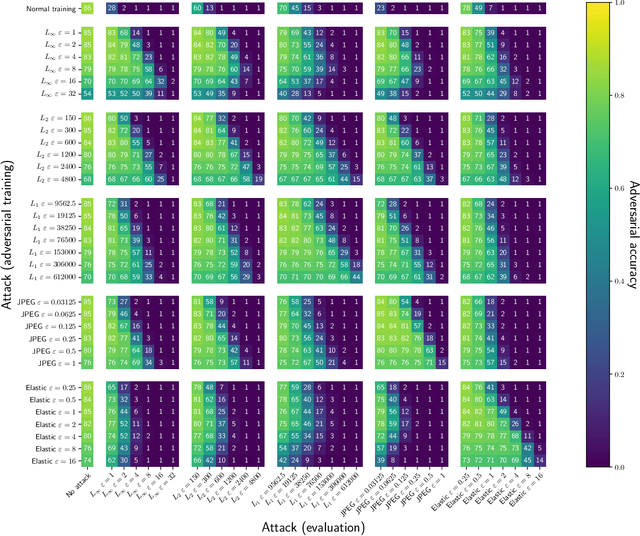
Considerable work on adversarial defense has studied robustness to a fixed, known family of adversarial distortions, most frequently L_p-bounded distortions. In reality, the specific form of attack will rarely be known and adversaries are free to employ distortions outside of any fixed set. The present work advocates measuring robustness against this much broader range of unforeseen attacks---attacks whose precise form is not known when designing a defense. We propose a methodology for evaluating a defense against a diverse range of distortion types together with a summary metric UAR that measures the Unforeseen Attack Robustness against a distortion. We construct novel JPEG, Fog, Gabor, and Snow adversarial attacks to simulate unforeseen adversaries and perform a careful study of adversarial robustness against these and existing distortion types. We find that evaluation against existing L_p attacks yields highly correlated information that may not generalize to other attacks and identify a set of 4 attacks that yields more diverse information. We further find that adversarial training against either one or multiple distortions, including our novel ones, does not confer robustness to unforeseen distortions. These results underscore the need to study robustness against unforeseen distortions and provide a starting point for doing so.
Transfer of Adversarial Robustness Between Perturbation Types
May 03, 2019


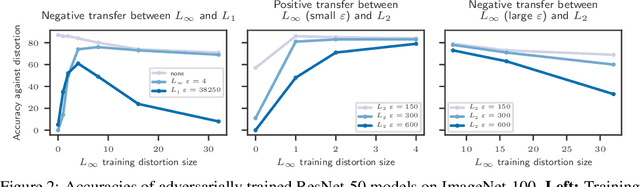
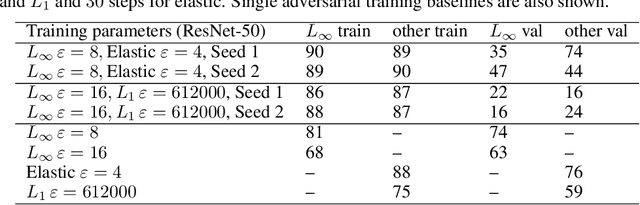
We study the transfer of adversarial robustness of deep neural networks between different perturbation types. While most work on adversarial examples has focused on $L_\infty$ and $L_2$-bounded perturbations, these do not capture all types of perturbations available to an adversary. The present work evaluates 32 attacks of 5 different types against models adversarially trained on a 100-class subset of ImageNet. Our empirical results suggest that evaluating on a wide range of perturbation sizes is necessary to understand whether adversarial robustness transfers between perturbation types. We further demonstrate that robustness against one perturbation type may not always imply and may sometimes hurt robustness against other perturbation types. In light of these results, we recommend evaluation of adversarial defenses take place on a diverse range of perturbation types and sizes.
Skill Rating for Generative Models
Aug 14, 2018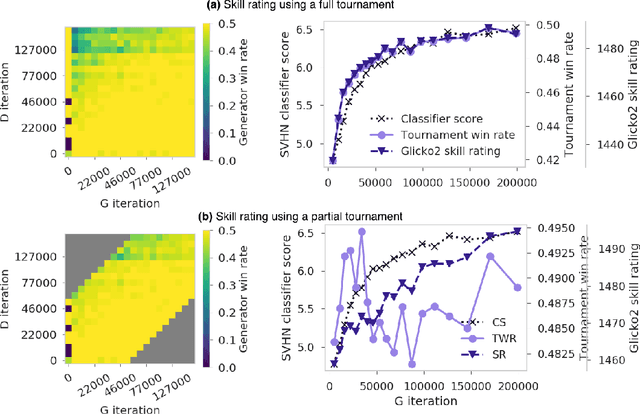
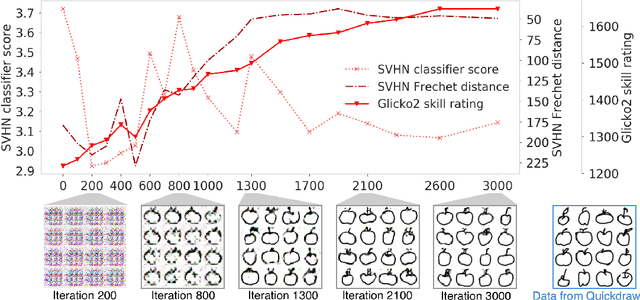
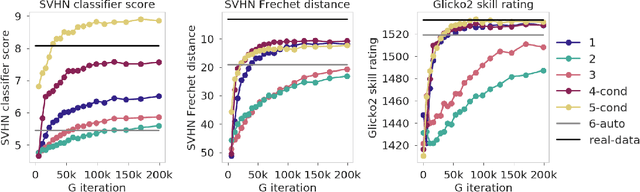

We explore a new way to evaluate generative models using insights from evaluation of competitive games between human players. We show experimentally that tournaments between generators and discriminators provide an effective way to evaluate generative models. We introduce two methods for summarizing tournament outcomes: tournament win rate and skill rating. Evaluations are useful in different contexts, including monitoring the progress of a single model as it learns during the training process, and comparing the capabilities of two different fully trained models. We show that a tournament consisting of a single model playing against past and future versions of itself produces a useful measure of training progress. A tournament containing multiple separate models (using different seeds, hyperparameters, and architectures) provides a useful relative comparison between different trained GANs. Tournament-based rating methods are conceptually distinct from numerous previous categories of approaches to evaluation of generative models, and have complementary advantages and disadvantages.
Technical Report on the CleverHans v2.1.0 Adversarial Examples Library
Jun 27, 2018CleverHans is a software library that provides standardized reference implementations of adversarial example construction techniques and adversarial training. The library may be used to develop more robust machine learning models and to provide standardized benchmarks of models' performance in the adversarial setting. Benchmarks constructed without a standardized implementation of adversarial example construction are not comparable to each other, because a good result may indicate a robust model or it may merely indicate a weak implementation of the adversarial example construction procedure. This technical report is structured as follows. Section 1 provides an overview of adversarial examples in machine learning and of the CleverHans software. Section 2 presents the core functionalities of the library: namely the attacks based on adversarial examples and defenses to improve the robustness of machine learning models to these attacks. Section 3 describes how to report benchmark results using the library. Section 4 describes the versioning system.