 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Sketch Abstraction
Apr 13, 2018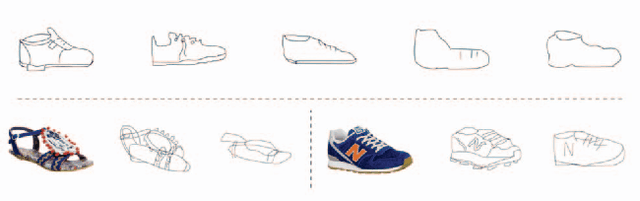
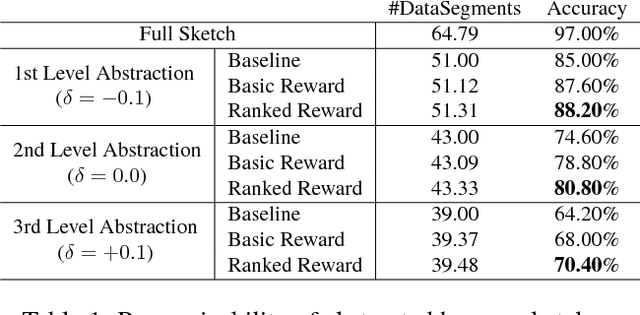
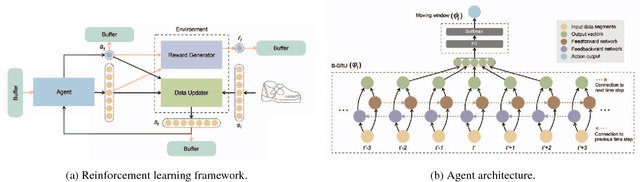
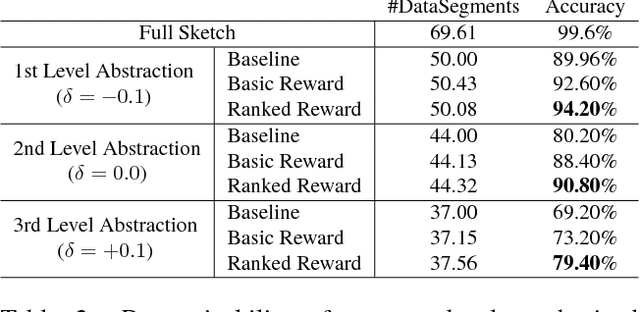
Human free-hand sketches have been studied in various contexts including sketch recognition, synthesis and fine-grained sketch-based image retrieval (FG-SBIR). A fundamental challenge for sketch analysis is to deal with drastically different human drawing styles, particularly in terms of abstraction level. In this work, we propose the first stroke-level sketch abstraction model based on the insight of sketch abstraction as a process of trading off between the recognizability of a sketch and the number of strokes used to draw it. Concretely, we train a model for abstract sketch generation through reinforcement learning of a stroke removal policy that learns to predict which strokes can be safely removed without affecting recognizability. We show that our abstraction model can be used for various sketch analysis tasks including: (1) modeling stroke saliency and understanding the decision of sketch recognition models, (2) synthesizing sketches of variable abstraction for a given category, or reference object instance in a photo, and (3) training a FG-SBIR model with photos only, bypassing the expensive photo-sketch pair collection step.
The Devil is in the Middle: Exploiting Mid-level Representations for Cross-Domain Instance Matching
Apr 04, 2018
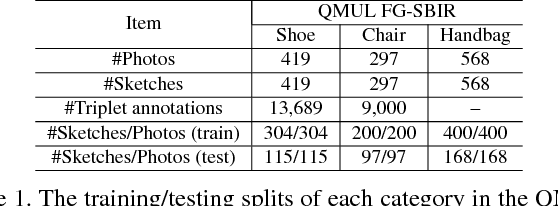
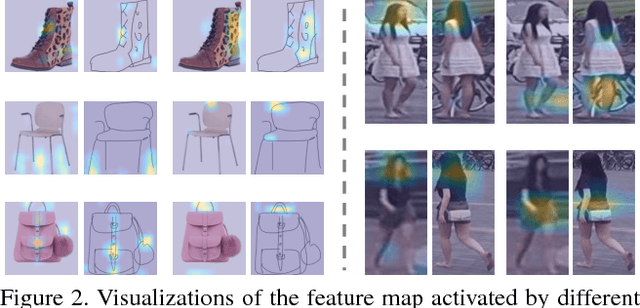
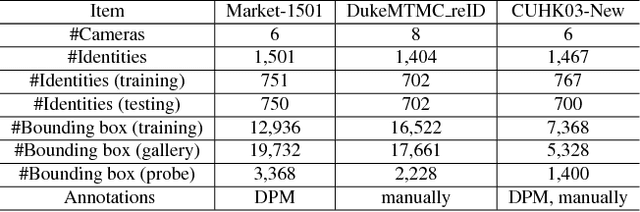
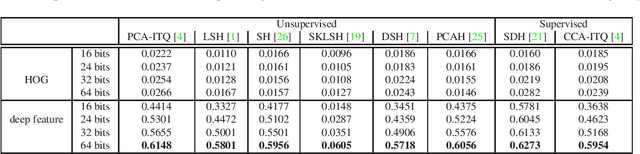
Many vision problems require matching images of object instances across different domains. These include fine-grained sketch-based image retrieval (FG-SBIR) and Person Re-identification (person ReID). Existing approaches attempt to learn a joint embedding space where images from different domains can be directly compared. In most cases, this space is defined by the output of the final layer of a deep neural network (DNN), which primarily contains features of a high semantic level. In this paper, we argue that both high and mid-level features are relevant for cross-domain instance matching (CDIM). Importantly, mid-level features already exist in earlier layers of the DNN. They just need to be extracted, represented, and fused properly with the final layer. Based on this simple but powerful idea, we propose a unified framework for CDIM. Instantiating our framework for FG-SBIR and ReID, we show that our simple models can easily beat the state-of-the-art models, which are often equipped with much more elaborate architectures.
SketchMate: Deep Hashing for Million-Scale Human Sketch Retrieval
Apr 04, 2018
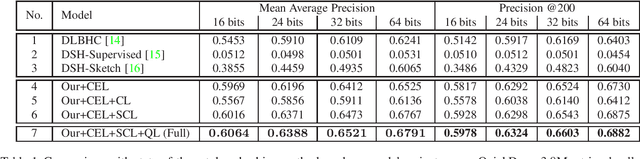
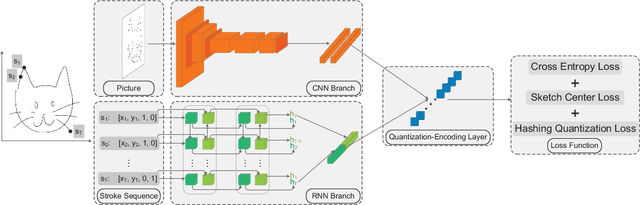
We propose a deep hashing framework for sketch retrieval that, for the first time, works on a multi-million scale human sketch dataset. Leveraging on this large dataset, we explore a few sketch-specific traits that were otherwise under-studied in prior literature. Instead of following the conventional sketch recognition task, we introduce the novel problem of sketch hashing retrieval which is not only more challenging, but also offers a better testbed for large-scale sketch analysis, since: (i) more fine-grained sketch feature learning is required to accommodate the large variations in style and abstraction, and (ii) a compact binary code needs to be learned at the same time to enable efficient retrieval. Key to our network design is the embedding of unique characteristics of human sketch, where (i) a two-branch CNN-RNN architecture is adapted to explore the temporal ordering of strokes, and (ii) a novel hashing loss is specifically designed to accommodate both the temporal and abstract traits of sketches. By working with a 3.8M sketch dataset, we show that state-of-the-art hashing models specifically engineered for static images fail to perform well on temporal sketch data. Our network on the other hand not only offers the best retrieval performance on various code sizes, but also yields the best generalization performance under a zero-shot setting and when re-purposed for sketch recognition. Such superior performances effectively demonstrate the benefit of our sketch-specific design.
Learning to Compare: Relation Network for Few-Shot Learning
Mar 27, 2018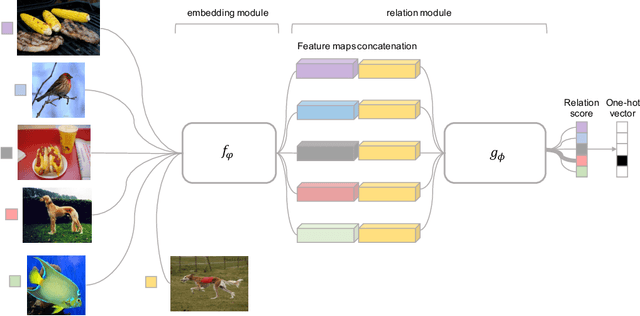
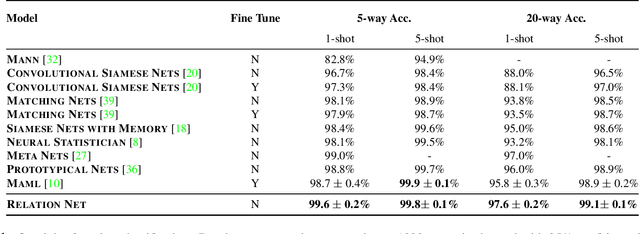
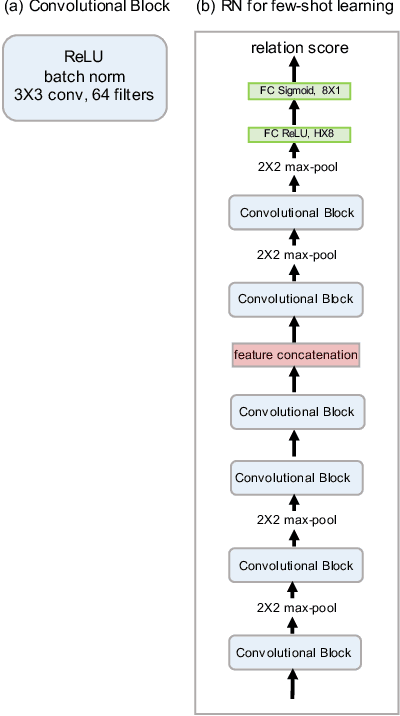
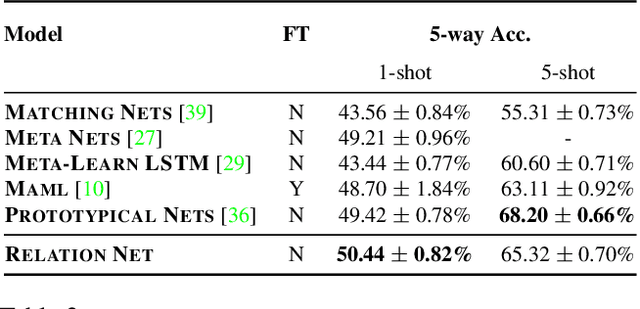
We present a conceptually simple, flexible, and general framework for few-shot learning, where a classifier must learn to recognise new classes given only few examples from each. Our method, called the Relation Network (RN), is trained end-to-end from scratch. During meta-learning, it learns to learn a deep distance metric to compare a small number of images within episodes, each of which is designed to simulate the few-shot setting. Once trained, a RN is able to classify images of new classes by computing relation scores between query images and the few examples of each new class without further updating the network. Besides providing improved performance on few-shot learning, our framework is easily extended to zero-shot learning. Extensive experiments on five benchmarks demonstrate that our simple approach provides a unified and effective approach for both of these two tasks.
Scalable and Effective Deep CCA via Soft Decorrelation
Mar 24, 2018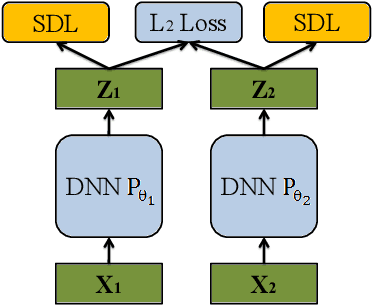
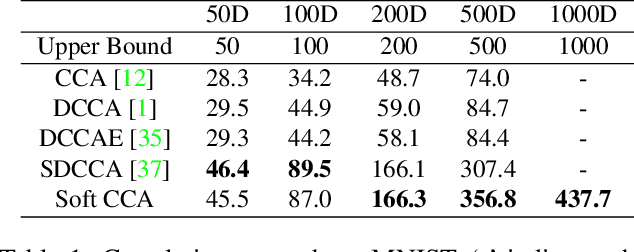
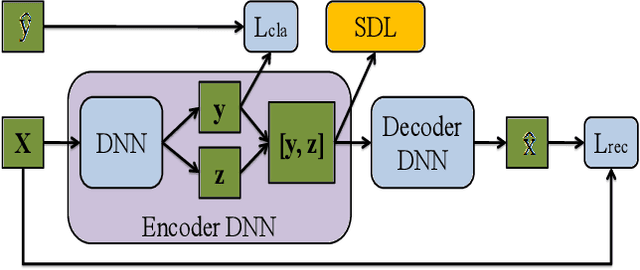
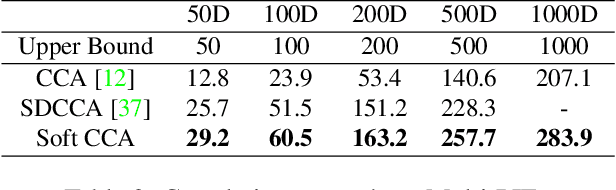
Recently the widely used multi-view learning model, Canonical Correlation Analysis (CCA) has been generalised to the non-linear setting via deep neural networks. Existing deep CCA models typically first decorrelate the feature dimensions of each view before the different views are maximally correlated in a common latent space. This feature decorrelation is achieved by enforcing an exact decorrelation constraint; these models are thus computationally expensive due to the matrix inversion or SVD operations required for exact decorrelation at each training iteration. Furthermore, the decorrelation step is often separated from the gradient descent based optimisation, resulting in sub-optimal solutions. We propose a novel deep CCA model Soft CCA to overcome these problems. Specifically, exact decorrelation is replaced by soft decorrelation via a mini-batch based Stochastic Decorrelation Loss (SDL) to be optimised jointly with the other training objectives. Extensive experiments show that the proposed soft CCA is more effective and efficient than existing deep CCA models. In addition, our SDL loss can be applied to other deep models beyond multi-view learning, and obtains superior performance compared to existing decorrelation losses.
Inverse Visual Question Answering: A New Benchmark and VQA Diagnosis Tool
Mar 16, 2018
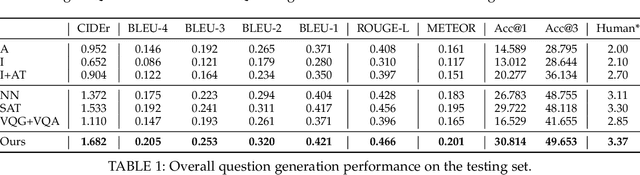


In recent years, visual question answering (VQA) has become topical. The premise of VQA's significance as a benchmark in AI, is that both the image and textual question need to be well understood and mutually grounded in order to infer the correct answer. However, current VQA models perhaps `understand' less than initially hoped, and instead master the easier task of exploiting cues given away in the question and biases in the answer distribution. In this paper we propose the inverse problem of VQA (iVQA). The iVQA task is to generate a question that corresponds to a given image and answer pair. We propose a variational iVQA model that can generate diverse, grammatically correct and content correlated questions that match the given answer. Based on this model, we show that iVQA is an interesting benchmark for visuo-linguistic understanding, and a more challenging alternative to VQA because an iVQA model needs to understand the image better to be successful. As a second contribution, we show how to use iVQA in a novel reinforcement learning framework to diagnose any existing VQA model by way of exposing its belief set: the set of question-answer pairs that the VQA model would predict true for a given image. This provides a completely new window into what VQA models `believe' about images. We show that existing VQA models have more erroneous beliefs than previously thought, revealing their intrinsic weaknesses. Suggestions are then made on how to address these weaknesses going forward.
iVQA: Inverse Visual Question Answering
Mar 16, 2018

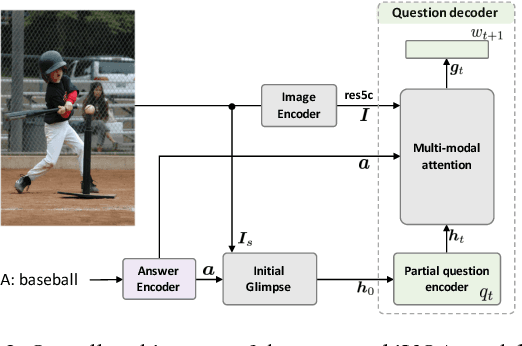
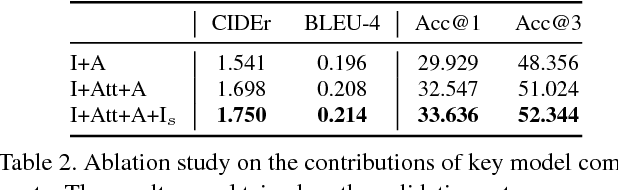
We propose the inverse problem of Visual question answering (iVQA), and explore its suitability as a benchmark for visuo-linguistic understanding. The iVQA task is to generate a question that corresponds to a given image and answer pair. Since the answers are less informative than the questions, and the questions have less learnable bias, an iVQA model needs to better understand the image to be successful than a VQA model. We pose question generation as a multi-modal dynamic inference process and propose an iVQA model that can gradually adjust its focus of attention guided by both a partially generated question and the answer. For evaluation, apart from existing linguistic metrics, we propose a new ranking metric. This metric compares the ground truth question's rank among a list of distractors, which allows the drawbacks of different algorithms and sources of error to be studied. Experimental results show that our model can generate diverse, grammatically correct and content correlated questions that match the given answer.
Actor-Critic Sequence Training for Image Captioning
Nov 28, 2017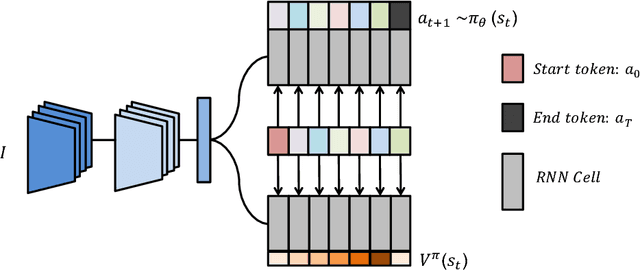
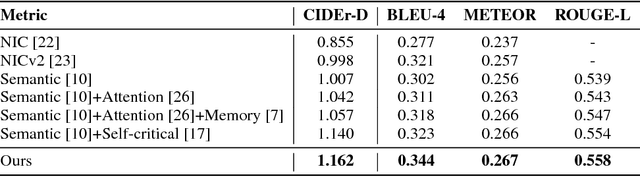
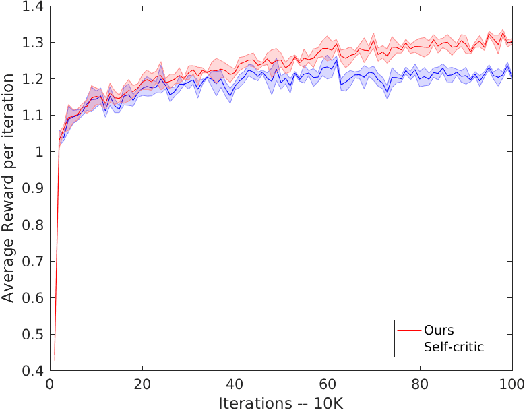
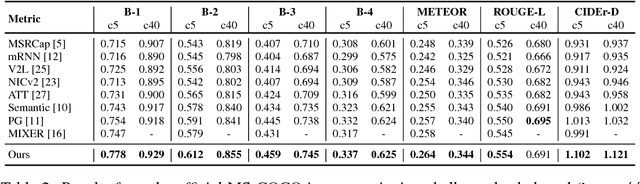
Generating natural language descriptions of images is an important capability for a robot or other visual-intelligence driven AI agent that may need to communicate with human users about what it is seeing. Such image captioning methods are typically trained by maximising the likelihood of ground-truth annotated caption given the image. While simple and easy to implement, this approach does not directly maximise the language quality metrics we care about such as CIDEr. In this paper we investigate training image captioning methods based on actor-critic reinforcement learning in order to directly optimise non-differentiable quality metrics of interest. By formulating a per-token advantage and value computation strategy in this novel reinforcement learning based captioning model, we show that it is possible to achieve the state of the art performance on the widely used MSCOCO benchmark.
Deep Matching Autoencoders
Nov 16, 2017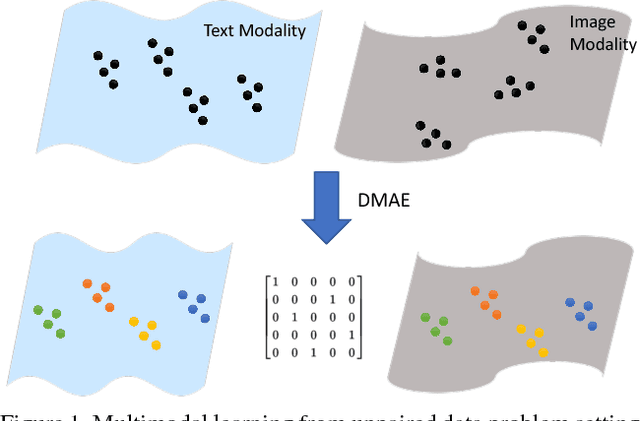
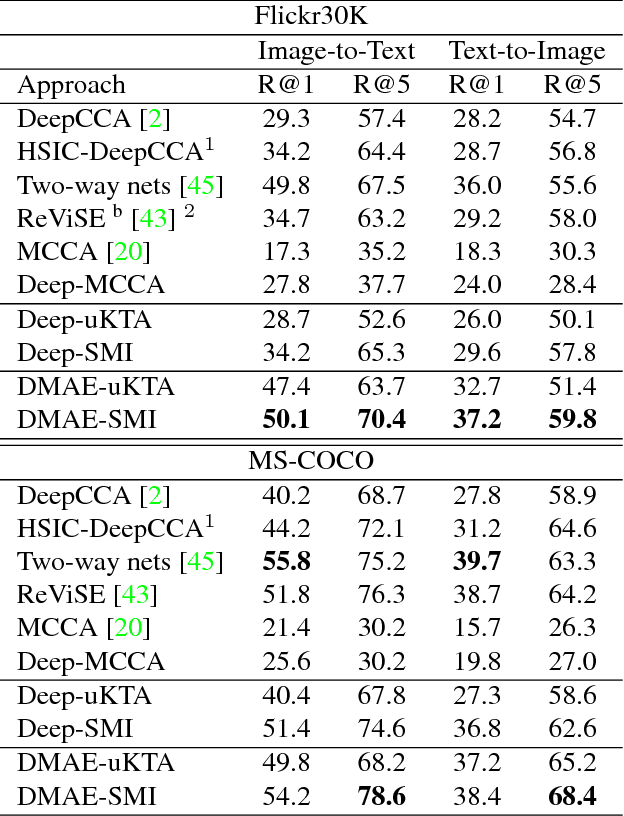
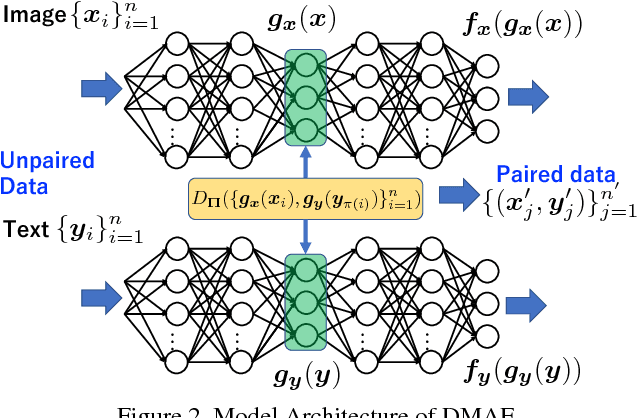
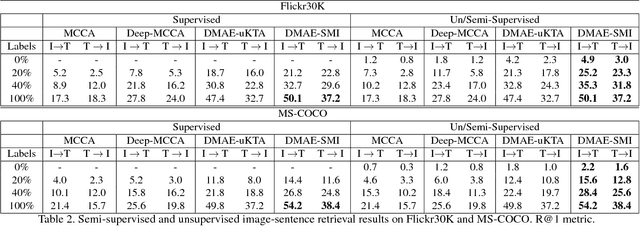
Increasingly many real world tasks involve data in multiple modalities or views. This has motivated the development of many effective algorithms for learning a common latent space to relate multiple domains. However, most existing cross-view learning algorithms assume access to paired data for training. Their applicability is thus limited as the paired data assumption is often violated in practice: many tasks have only a small subset of data available with pairing annotation, or even no paired data at all. In this paper we introduce Deep Matching Autoencoders (DMAE), which learn a common latent space and pairing from unpaired multi-modal data. Specifically we formulate this as a cross-domain representation learning and object matching problem. We simultaneously optimise parameters of representation learning auto-encoders and the pairing of unpaired multi-modal data. This framework elegantly spans the full regime from fully supervised, semi-supervised, and unsupervised (no paired data) multi-modal learning. We show promising results in image captioning, and on a new task that is uniquely enabled by our methodology: unsupervised classifier learning.
Learning to Generalize: Meta-Learning for Domain Generalization
Oct 10, 2017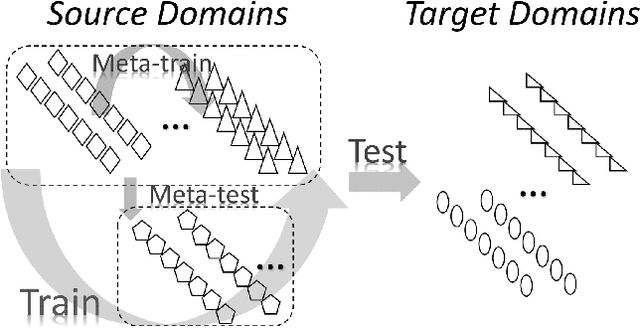


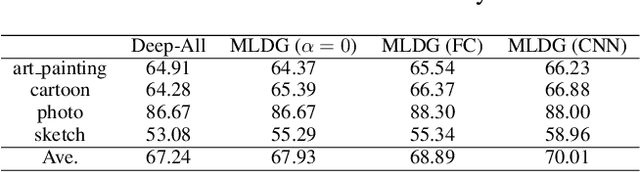
Domain shift refers to the well known problem that a model trained in one source domain performs poorly when applied to a target domain with different statistics. {Domain Generalization} (DG) techniques attempt to alleviate this issue by producing models which by design generalize well to novel testing domains. We propose a novel {meta-learning} method for domain generalization. Rather than designing a specific model that is robust to domain shift as in most previous DG work, we propose a model agnostic training procedure for DG. Our algorithm simulates train/test domain shift during training by synthesizing virtual testing domains within each mini-batch. The meta-optimization objective requires that steps to improve training domain performance should also improve testing domain performance. This meta-learning procedure trains models with good generalization ability to novel domains. We evaluate our method and achieve state of the art results on a recent cross-domain image classification benchmark, as well demonstrating its potential on two classic reinforcement learning tasks.