 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Transfer Learning under Federated Learning for Automatic Speech Recognition
Aug 19, 2024



This work explores the challenge of enhancing Automatic Speech Recognition (ASR) model performance across various user-specific domains while preserving user data privacy. We employ federated learning and parameter-efficient domain adaptation methods to solve the (1) massive data requirement of ASR models from user-specific scenarios and (2) the substantial communication cost between servers and clients during federated learning. We demonstrate that when equipped with proper adapters, ASR models under federated tuning can achieve similar performance compared with centralized tuning ones, thus providing a potential direction for future privacy-preserved ASR services. Besides, we investigate the efficiency of different adapters and adapter incorporation strategies under the federated learning setting.
Heterogeneous Federated Learning Using Knowledge Codistillation
Oct 04, 2023



Federated Averaging, and many federated learning algorithm variants which build upon it, have a limitation: all clients must share the same model architecture. This results in unused modeling capacity on many clients, which limits model performance. To address this issue, we propose a method that involves training a small model on the entire pool and a larger model on a subset of clients with higher capacity. The models exchange information bidirectionally via knowledge distillation, utilizing an unlabeled dataset on a server without sharing parameters. We present two variants of our method, which improve upon federated averaging on image classification and language modeling tasks. We show this technique can be useful even if only out-of-domain or limited in-domain distillation data is available. Additionally, the bi-directional knowledge distillation allows for domain transfer between the models when different pool populations introduce domain shift.
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Sep 14, 2022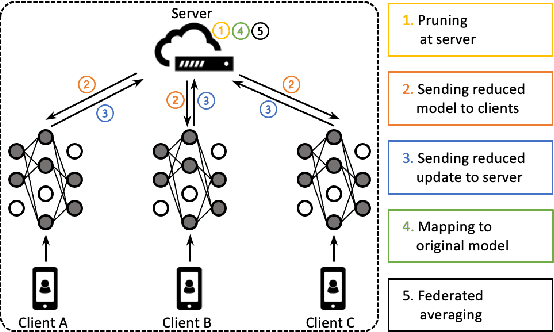
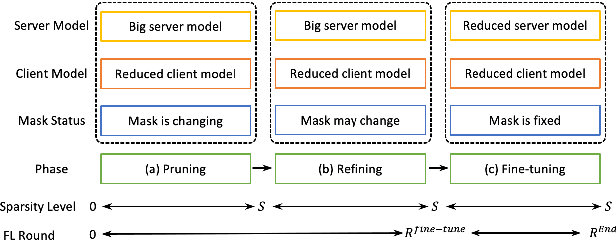
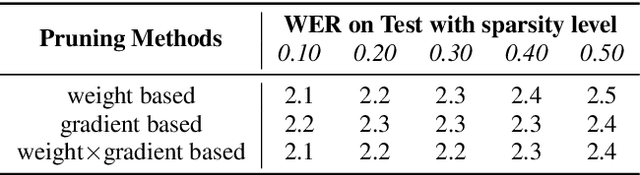
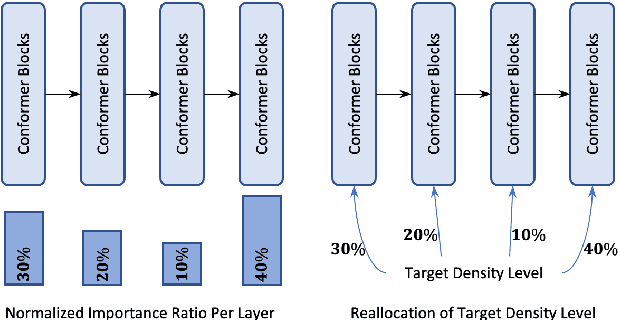
Automatic Speech Recognition models require large amount of speech data for training, and the collection of such data often leads to privacy concerns. Federated learning has been widely used and is considered to be an effective decentralized technique by collaboratively learning a shared prediction model while keeping the data local on different clients devices. However, the limited computation and communication resources on clients devices present practical difficulties for large models. To overcome such challenges, we propose Federated Pruning to train a reduced model under the federated setting, while maintaining similar performance compared to the full model. Moreover, the vast amount of clients data can also be leveraged to improve the pruning results compared to centralized training. We explore different pruning schemes and provide empirical evidence of the effectiveness of our methods.
Online Model Compression for Federated Learning with Large Models
May 06, 2022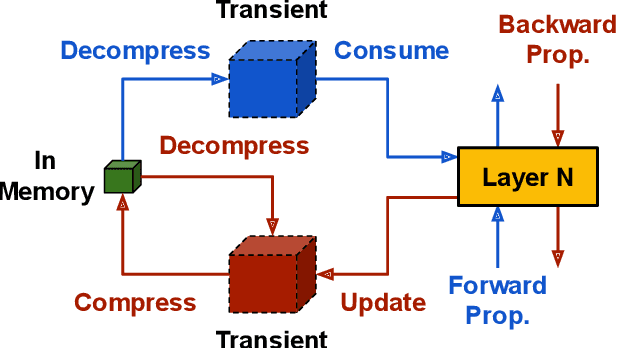
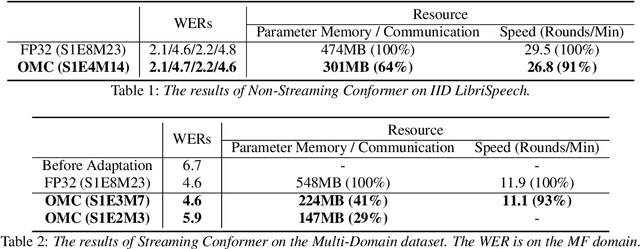
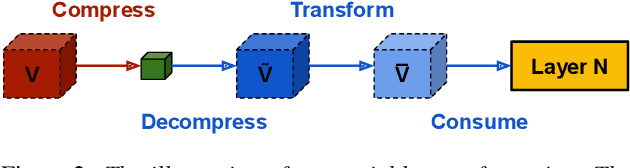
This paper addresses the challenges of training large neural network models under federated learning settings: high on-device memory usage and communication cost. The proposed Online Model Compression (OMC) provides a framework that stores model parameters in a compressed format and decompresses them only when needed. We use quantization as the compression method in this paper and propose three methods, (1) using per-variable transformation, (2) weight matrices only quantization, and (3) partial parameter quantization, to minimize the impact on model accuracy. According to our experiments on two recent neural networks for speech recognition and two different datasets, OMC can reduce memory usage and communication cost of model parameters by up to 59% while attaining comparable accuracy and training speed when compared with full-precision training.
Partial Variable Training for Efficient On-Device Federated Learning
Oct 11, 2021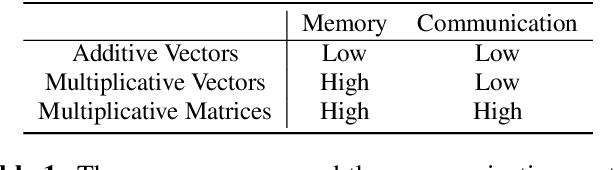
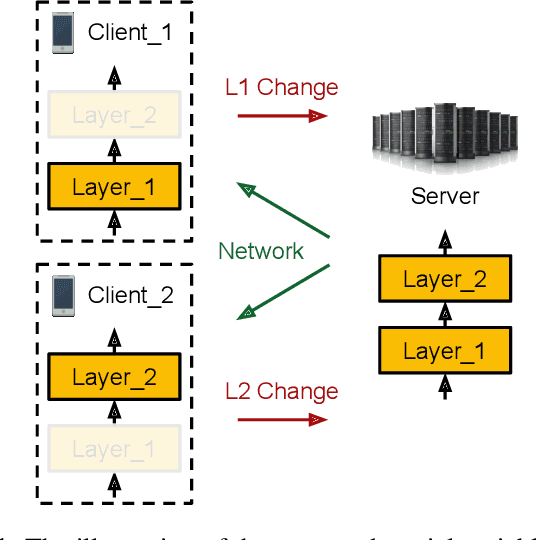
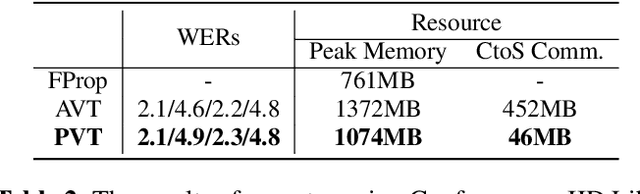
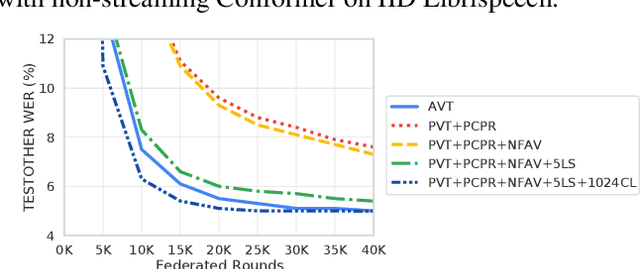
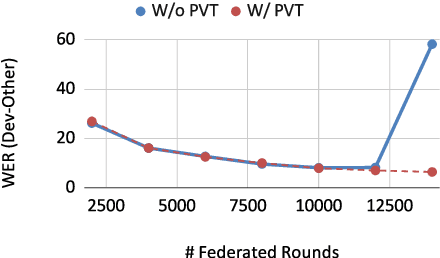
This paper aims to address the major challenges of Federated Learning (FL) on edge devices: limited memory and expensive communication. We propose a novel method, called Partial Variable Training (PVT), that only trains a small subset of variables on edge devices to reduce memory usage and communication cost. With PVT, we show that network accuracy can be maintained by utilizing more local training steps and devices, which is favorable for FL involving a large population of devices. According to our experiments on two state-of-the-art neural networks for speech recognition and two different datasets, PVT can reduce memory usage by up to 1.9$\times$ and communication cost by up to 593$\times$ while attaining comparable accuracy when compared with full network training.
Enabling On-Device Training of Speech Recognition Models with Federated Dropout
Oct 07, 2021
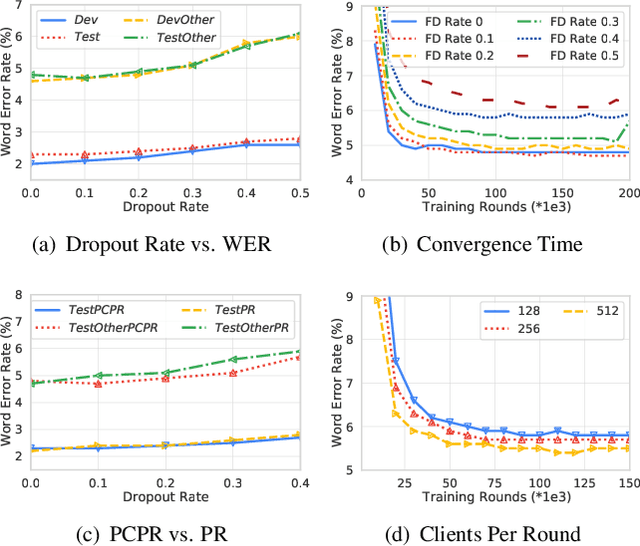

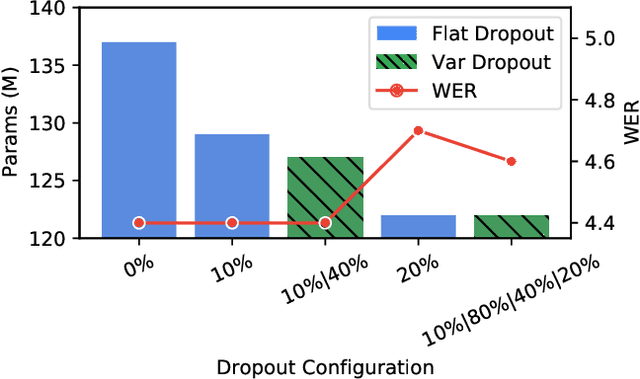
Federated learning can be used to train machine learning models on the edge on local data that never leave devices, providing privacy by default. This presents a challenge pertaining to the communication and computation costs associated with clients' devices. These costs are strongly correlated with the size of the model being trained, and are significant for state-of-the-art automatic speech recognition models. We propose using federated dropout to reduce the size of client models while training a full-size model server-side. We provide empirical evidence of the effectiveness of federated dropout, and propose a novel approach to vary the dropout rate applied at each layer. Furthermore, we find that federated dropout enables a set of smaller sub-models within the larger model to independently have low word error rates, making it easier to dynamically adjust the size of the model deployed for inference.
NetAdaptV2: Efficient Neural Architecture Search with Fast Super-Network Training and Architecture Optimization
Mar 31, 2021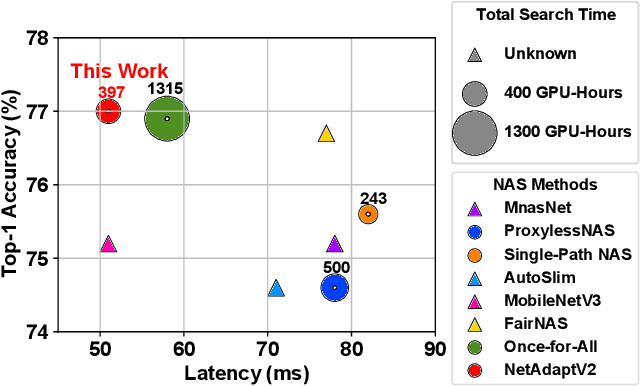
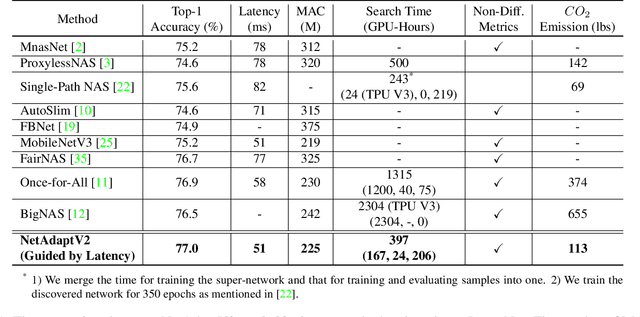

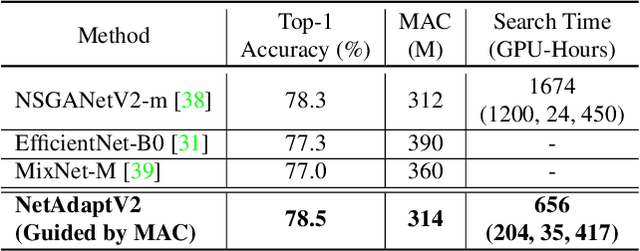
Neural architecture search (NAS) typically consists of three main steps: training a super-network, training and evaluating sampled deep neural networks (DNNs), and training the discovered DNN. Most of the existing efforts speed up some steps at the cost of a significant slowdown of other steps or sacrificing the support of non-differentiable search metrics. The unbalanced reduction in the time spent per step limits the total search time reduction, and the inability to support non-differentiable search metrics limits the performance of discovered DNNs. In this paper, we present NetAdaptV2 with three innovations to better balance the time spent for each step while supporting non-differentiable search metrics. First, we propose channel-level bypass connections that merge network depth and layer width into a single search dimension to reduce the time for training and evaluating sampled DNNs. Second, ordered dropout is proposed to train multiple DNNs in a single forward-backward pass to decrease the time for training a super-network. Third, we propose the multi-layer coordinate descent optimizer that considers the interplay of multiple layers in each iteration of optimization to improve the performance of discovered DNNs while supporting non-differentiable search metrics. With these innovations, NetAdaptV2 reduces the total search time by up to $5.8\times$ on ImageNet and $2.4\times$ on NYU Depth V2, respectively, and discovers DNNs with better accuracy-latency/accuracy-MAC trade-offs than state-of-the-art NAS works. Moreover, the discovered DNN outperforms NAS-discovered MobileNetV3 by 1.8% higher top-1 accuracy with the same latency. The project website is http://netadapt.mit.edu.
Design Considerations for Efficient Deep Neural Networks on Processing-in-Memory Accelerators
Dec 18, 2019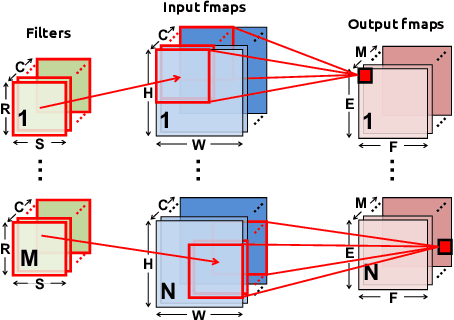
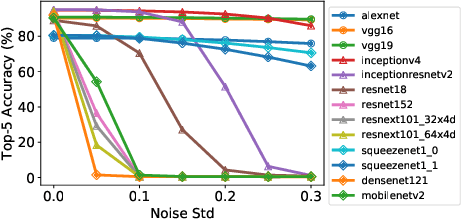
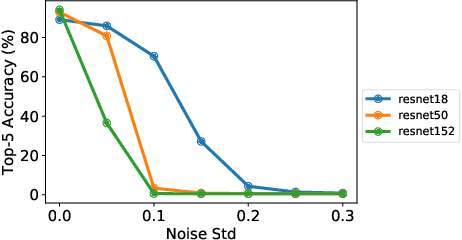
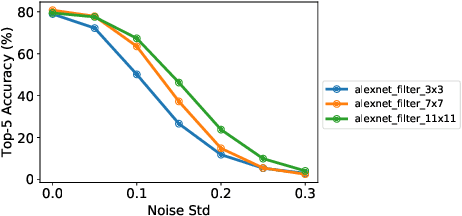
This paper describes various design considerations for deep neural networks that enable them to operate efficiently and accurately on processing-in-memory accelerators. We highlight important properties of these accelerators and the resulting design considerations using experiments conducted on various state-of-the-art deep neural networks with the large-scale ImageNet dataset.
SegSort: Segmentation by Discriminative Sorting of Segments
Oct 30, 2019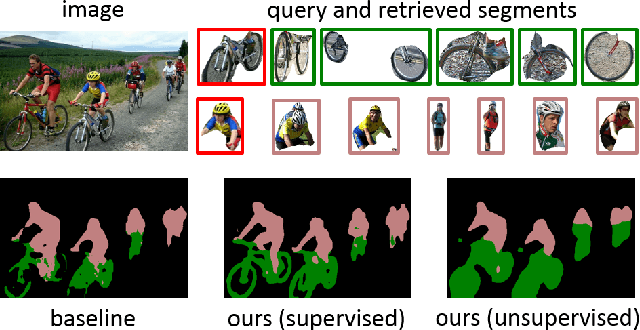
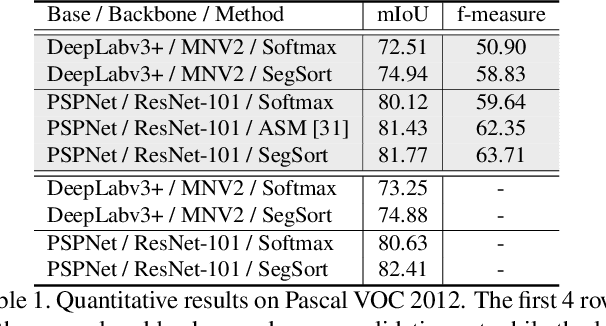
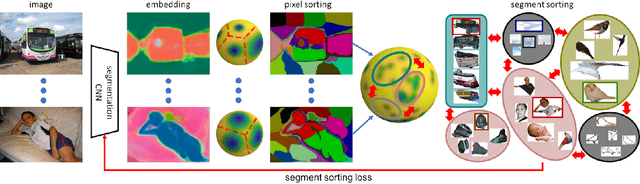
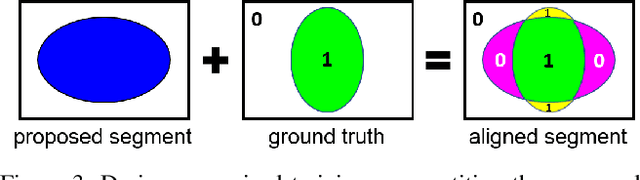
Almost all existing deep learning approaches for semantic segmentation tackle this task as a pixel-wise classification problem. Yet humans understand a scene not in terms of pixels, but by decomposing it into perceptual groups and structures that are the basic building blocks of recognition. This motivates us to propose an end-to-end pixel-wise metric learning approach that mimics this process. In our approach, the optimal visual representation determines the right segmentation within individual images and associates segments with the same semantic classes across images. The core visual learning problem is therefore to maximize the similarity within segments and minimize the similarity between segments. Given a model trained this way, inference is performed consistently by extracting pixel-wise embeddings and clustering, with the semantic label determined by the majority vote of its nearest neighbors from an annotated set. As a result, we present the SegSort, as a first attempt using deep learning for unsupervised semantic segmentation, achieving $76\%$ performance of its supervised counterpart. When supervision is available, SegSort shows consistent improvements over conventional approaches based on pixel-wise softmax training. Additionally, our approach produces more precise boundaries and consistent region predictions. The proposed SegSort further produces an interpretable result, as each choice of label can be easily understood from the retrieved nearest segments.
DeeperLab: Single-Shot Image Parser
Mar 12, 2019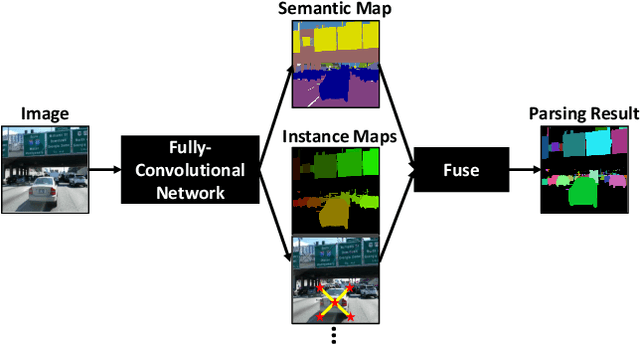
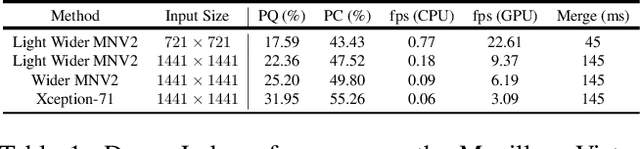


We present a single-shot, bottom-up approach for whole image parsing. Whole image parsing, also known as Panoptic Segmentation, generalizes the tasks of semantic segmentation for 'stuff' classes and instance segmentation for 'thing' classes, assigning both semantic and instance labels to every pixel in an image. Recent approaches to whole image parsing typically employ separate standalone modules for the constituent semantic and instance segmentation tasks and require multiple passes of inference. Instead, the proposed DeeperLab image parser performs whole image parsing with a significantly simpler, fully convolutional approach that jointly addresses the semantic and instance segmentation tasks in a single-shot manner, resulting in a streamlined system that better lends itself to fast processing. For quantitative evaluation, we use both the instance-based Panoptic Quality (PQ) metric and the proposed region-based Parsing Covering (PC) metric, which better captures the image parsing quality on 'stuff' classes and larger object instances. We report experimental results on the challenging Mapillary Vistas dataset, in which our single model achieves 31.95% (val) / 31.6% PQ (test) and 55.26% PC (val) with 3 frames per second (fps) on GPU or near real-time speed (22.6 fps on GPU) with reduced accuracy.