 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLNet: Scale-Modulated Query and Localization Network for Few-Shot Class-Agnostic Counting
Nov 16, 2023



The class-agnostic counting (CAC) task has recently been proposed to solve the problem of counting all objects of an arbitrary class with several exemplars given in the input image. To address this challenging task, existing leading methods all resort to density map regression, which renders them impractical for downstream tasks that require object locations and restricts their ability to well explore the scale information of exemplars for supervision. To address the limitations, we propose a novel localization-based CAC approach, termed Scale-modulated Query and Localization Network (SQLNet). It fully explores the scales of exemplars in both the query and localization stages and achieves effective counting by accurately locating each object and predicting its approximate size. Specifically, during the query stage, rich discriminative representations of the target class are acquired by the Hierarchical Exemplars Collaborative Enhancement (HECE) module from the few exemplars through multi-scale exemplar cooperation with equifrequent size prompt embedding. These representations are then fed into the Exemplars-Unified Query Correlation (EUQC) module to interact with the query features in a unified manner and produce the correlated query tensor. In the localization stage, the Scale-aware Multi-head Localization (SAML) module utilizes the query tensor to predict the confidence, location, and size of each potential object. Moreover, a scale-aware localization loss is introduced, which exploits flexible location associations and exemplar scales for supervision to optimize the model performance. Extensive experiments demonstrate that SQLNet outperforms state-of-the-art methods on popular CAC benchmarks, achieving excellent performance not only in counting accuracy but also in localization and bounding box generation. Our codes will be available at https://github.com/HCPLab-SYSU/SQLNet
Contrastive Transformer Learning with Proximity Data Generation for Text-Based Person Search
Nov 15, 2023



Given a descriptive text query, text-based person search (TBPS) aims to retrieve the best-matched target person from an image gallery. Such a cross-modal retrieval task is quite challenging due to significant modality gap, fine-grained differences and insufficiency of annotated data. To better align the two modalities, most existing works focus on introducing sophisticated network structures and auxiliary tasks, which are complex and hard to implement. In this paper, we propose a simple yet effective dual Transformer model for text-based person search. By exploiting a hardness-aware contrastive learning strategy, our model achieves state-of-the-art performance without any special design for local feature alignment or side information. Moreover, we propose a proximity data generation (PDG) module to automatically produce more diverse data for cross-modal training. The PDG module first introduces an automatic generation algorithm based on a text-to-image diffusion model, which generates new text-image pair samples in the proximity space of original ones. Then it combines approximate text generation and feature-level mixup during training to further strengthen the data diversity. The PDG module can largely guarantee the reasonability of the generated samples that are directly used for training without any human inspection for noise rejection. It improves the performance of our model significantly, providing a feasible solution to the data insufficiency problem faced by such fine-grained visual-linguistic tasks. Extensive experiments on two popular datasets of the TBPS task (i.e., CUHK-PEDES and ICFG-PEDES) show that the proposed approach outperforms state-of-the-art approaches evidently, e.g., improving by 3.88%, 4.02%, 2.92% in terms of Top1, Top5, Top10 on CUHK-PEDES. The codes will be available at https://github.com/HCPLab-SYSU/PersonSearch-CTLG
Spatial-Temporal Knowledge-Embedded Transformer for Video Scene Graph Generation
Sep 23, 2023



Video scene graph generation (VidSGG) aims to identify objects in visual scenes and infer their relationships for a given video. It requires not only a comprehensive understanding of each object scattered on the whole scene but also a deep dive into their temporal motions and interactions. Inherently, object pairs and their relationships enjoy spatial co-occurrence correlations within each image and temporal consistency/transition correlations across different images, which can serve as prior knowledge to facilitate VidSGG model learning and inference. In this work, we propose a spatial-temporal knowledge-embedded transformer (STKET) that incorporates the prior spatial-temporal knowledge into the multi-head cross-attention mechanism to learn more representative relationship representations. Specifically, we first learn spatial co-occurrence and temporal transition correlations in a statistical manner. Then, we design spatial and temporal knowledge-embedded layers that introduce the multi-head cross-attention mechanism to fully explore the interaction between visual representation and the knowledge to generate spatial- and temporal-embedded representations, respectively. Finally, we aggregate these representations for each subject-object pair to predict the final semantic labels and their relationships. Extensive experiments show that STKET outperforms current competing algorithms by a large margin, e.g., improving the mR@50 by 8.1%, 4.7%, and 2.1% on different settings over current algorithms.
Towards CausalGPT: A Multi-Agent Approach for Faithful Knowledge Reasoning via Promoting Causal Consistency in LLMs
Sep 04, 2023Despite advancements in LLMs, knowledge-based reasoning remains a longstanding issue due to the fragility of knowledge recall and inference. Existing methods primarily encourage LLMs to autonomously plan and solve problems or to extensively sample reasoning chains without addressing the conceptual and inferential fallacies. Attempting to alleviate inferential fallacies and drawing inspiration from multi-agent collaboration, we present a framework to increase faithfulness and causality for knowledge-based reasoning. Specifically, we propose to employ multiple intelligent agents (i.e., reasoners and an evaluator) to work collaboratively in a reasoning-and-consensus paradigm for elevated reasoning faithfulness. The reasoners focus on providing solutions with human-like causality to solve open-domain problems. On the other hand, the \textit{evaluator} agent scrutinizes if a solution is deducible from a non-causal perspective and if it still holds when challenged by a counterfactual candidate. According to the extensive and comprehensive evaluations on a variety of knowledge reasoning tasks (e.g., science question answering and commonsense reasoning), our framework outperforms all compared state-of-the-art approaches by large margins.
RestoreFormer++: Towards Real-World Blind Face Restoration from Undegraded Key-Value Pairs
Aug 14, 2023Blind face restoration aims at recovering high-quality face images from those with unknown degradations. Current algorithms mainly introduce priors to complement high-quality details and achieve impressive progress. However, most of these algorithms ignore abundant contextual information in the face and its interplay with the priors, leading to sub-optimal performance. Moreover, they pay less attention to the gap between the synthetic and real-world scenarios, limiting the robustness and generalization to real-world applications. In this work, we propose RestoreFormer++, which on the one hand introduces fully-spatial attention mechanisms to model the contextual information and the interplay with the priors, and on the other hand, explores an extending degrading model to help generate more realistic degraded face images to alleviate the synthetic-to-real-world gap. Compared with current algorithms, RestoreFormer++ has several crucial benefits. First, instead of using a multi-head self-attention mechanism like the traditional visual transformer, we introduce multi-head cross-attention over multi-scale features to fully explore spatial interactions between corrupted information and high-quality priors. In this way, it can facilitate RestoreFormer++ to restore face images with higher realness and fidelity. Second, in contrast to the recognition-oriented dictionary, we learn a reconstruction-oriented dictionary as priors, which contains more diverse high-quality facial details and better accords with the restoration target. Third, we introduce an extending degrading model that contains more realistic degraded scenarios for training data synthesizing, and thus helps to enhance the robustness and generalization of our RestoreFormer++ model. Extensive experiments show that RestoreFormer++ outperforms state-of-the-art algorithms on both synthetic and real-world datasets.
Perception and Semantic Aware Regularization for Sequential Confidence Calibration
May 31, 2023



Deep sequence recognition (DSR) models receive increasing attention due to their superior application to various applications. Most DSR models use merely the target sequences as supervision without considering other related sequences, leading to over-confidence in their predictions. The DSR models trained with label smoothing regularize labels by equally and independently smoothing each token, reallocating a small value to other tokens for mitigating overconfidence. However, they do not consider tokens/sequences correlations that may provide more effective information to regularize training and thus lead to sub-optimal performance. In this work, we find tokens/sequences with high perception and semantic correlations with the target ones contain more correlated and effective information and thus facilitate more effective regularization. To this end, we propose a Perception and Semantic aware Sequence Regularization framework, which explore perceptively and semantically correlated tokens/sequences as regularization. Specifically, we introduce a semantic context-free recognition and a language model to acquire similar sequences with high perceptive similarities and semantic correlation, respectively. Moreover, over-confidence degree varies across samples according to their difficulties. Thus, we further design an adaptive calibration intensity module to compute a difficulty score for each samples to obtain finer-grained regularization. Extensive experiments on canonical sequence recognition tasks, including scene text and speech recognition, demonstrate that our method sets novel state-of-the-art results. Code is available at https://github.com/husterpzh/PSSR.
Open-World Pose Transfer via Sequential Test-Time Adaption
Mar 20, 2023



Pose transfer aims to transfer a given person into a specified posture, has recently attracted considerable attention. A typical pose transfer framework usually employs representative datasets to train a discriminative model, which is often violated by out-of-distribution (OOD) instances. Recently, test-time adaption (TTA) offers a feasible solution for OOD data by using a pre-trained model that learns essential features with self-supervision. However, those methods implicitly make an assumption that all test distributions have a unified signal that can be learned directly. In open-world conditions, the pose transfer task raises various independent signals: OOD appearance and skeleton, which need to be extracted and distributed in speciality. To address this point, we develop a SEquential Test-time Adaption (SETA). In the test-time phrase, SETA extracts and distributes external appearance texture by augmenting OOD data for self-supervised training. To make non-Euclidean similarity among different postures explicit, SETA uses the image representations derived from a person re-identification (Re-ID) model for similarity computation. By addressing implicit posture representation in the test-time sequentially, SETA greatly improves the generalization performance of current pose transfer models. In our experiment, we first show that pose transfer can be applied to open-world applications, including Tiktok reenactment and celebrity motion synthesis.
OccluMix: Towards De-Occlusion Virtual Try-on by Semantically-Guided Mixup
Jan 03, 2023Image Virtual try-on aims at replacing the cloth on a personal image with a garment image (in-shop clothes), which has attracted increasing attention from the multimedia and computer vision communities. Prior methods successfully preserve the character of clothing images, however, occlusion remains a pernicious effect for realistic virtual try-on. In this work, we first present a comprehensive analysis of the occlusions and categorize them into two aspects: i) Inherent-Occlusion: the ghost of the former cloth still exists in the try-on image; ii) Acquired-Occlusion: the target cloth warps to the unreasonable body part. Based on the in-depth analysis, we find that the occlusions can be simulated by a novel semantically-guided mixup module, which can generate semantic-specific occluded images that work together with the try-on images to facilitate training a de-occlusion try-on (DOC-VTON) framework. Specifically, DOC-VTON first conducts a sharpened semantic parsing on the try-on person. Aided by semantics guidance and pose prior, various complexities of texture are selectively blending with human parts in a copy-and-paste manner. Then, the Generative Module (GM) is utilized to take charge of synthesizing the final try-on image and learning to de-occlusion jointly. In comparison to the state-of-the-art methods, DOC-VTON achieves better perceptual quality by reducing occlusion effects.
Category-Adaptive Label Discovery and Noise Rejection for Multi-label Image Recognition with Partial Positive Labels
Nov 15, 2022



As a promising solution of reducing annotation cost, training multi-label models with partial positive labels (MLR-PPL), in which merely few positive labels are known while other are missing, attracts increasing attention. Due to the absence of any negative labels, previous works regard unknown labels as negative and adopt traditional MLR algorithms. To reject noisy labels, recent works regard large loss samples as noise but ignore the semantic correlation different multi-label images. In this work, we propose to explore semantic correlation among different images to facilitate the MLR-PPL task. Specifically, we design a unified framework, Category-Adaptive Label Discovery and Noise Rejection, that discovers unknown labels and rejects noisy labels for each category in an adaptive manner. The framework consists of two complementary modules: (1) Category-Adaptive Label Discovery module first measures the semantic similarity between positive samples and then complement unknown labels with high similarities; (2) Category-Adaptive Noise Rejection module first computes the sample weights based on semantic similarities from different samples and then discards noisy labels with low weights. Besides, we propose a novel category-adaptive threshold updating that adaptively adjusts the threshold, to avoid the time-consuming manual tuning process. Extensive experiments demonstrate that our proposed method consistently outperforms current leading algorithms.
Semantic-Aware Representation Blending for Multi-Label Image Recognition with Partial Labels
May 26, 2022
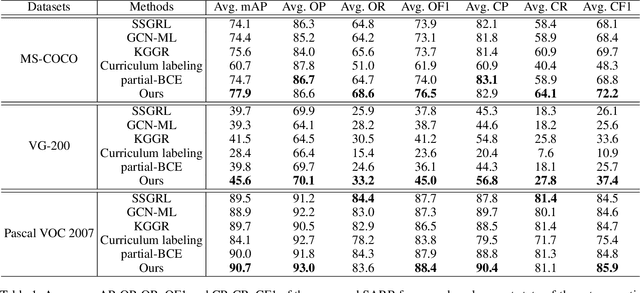
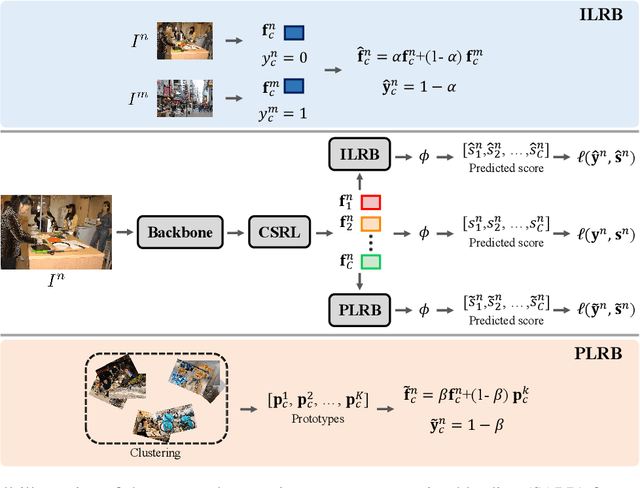
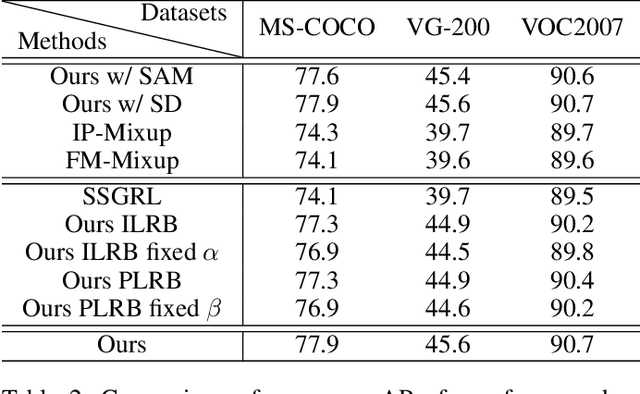
Despite achieving impressive progress, current multi-label image recognition (MLR) algorithms heavily depend on large-scale datasets with complete labels, making collecting large-scale datasets extremely time-consuming and labor-intensive. Training the multi-label image recognition models with partial labels (MLR-PL) is an alternative way to address this issue, in which merely some labels are known while others are unknown for each image (see Figure 1). However, current MLP-PL algorithms mainly rely on the pre-trained image classification or similarity models to generate pseudo labels for the unknown labels. Thus, they depend on a certain amount of data annotations and inevitably suffer from obvious performance drops, especially when the known label proportion is low. To address this dilemma, we propose a unified semantic-aware representation blending (SARB) that consists of two crucial modules to blend multi-granularity category-specific semantic representation across different images to transfer information of known labels to complement unknown labels. Extensive experiments on the MS-COCO, Visual Genome, and Pascal VOC 2007 datasets show that the proposed SARB consistently outperforms current state-of-the-art algorithms on all known label proportion settings. Concretely, it obtain the average mAP improvement of 1.9%, 4.5%, 1.0% on the three benchmark datasets compared with the second-best algorithm.