 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopMoE: Unifying Iterative Computation with Mixture-of-Experts for Language Modeling
Jun 03, 2026Mixture-of-Experts (MoE) and looped architectures scale models along two orthogonal axes, namely parameter capacity and effective depth. However, mainstream looped architectures rely on dense backbones that couple parameter count with per-token FLOPs, which makes it impossible to isolate the effect of iterative computation under matched budgets. To this end, we present LoopMoE, a looped MoE language model that integrates sparse routing with iterative weight-shared computation through two designs. The first is IterAdaLN, which resolves weight-sharing symmetry via a modulation signal jointly conditioned on the iteration index and the per-token hidden state. The second is a capacity-balancing strategy that recovers the attention-to-FFN active parameter ratio of well-tuned non-looped references. Together, these designs enable the first strictly controlled, head-to-head evaluation of a looped MoE against a Vanilla MoE under identical total parameters, per-token FLOPs, and active sublayer ratios. At the 3B scale, LoopMoE outperforms the Vanilla MoE on 8 of 9 downstream benchmarks with an average improvement exceeding 1 point. At the 9B scale, LoopMoE continues to outperform the matched Vanilla MoE, indicating that the architectural gain persists at larger scale. Our work establishes a controlled synthesis of sparsity and recurrence, and suggests a promising direction for looped language models.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Accurate, transferable, and verifiable machine-learned interatomic potentials for layered materials
Mar 19, 2025



Twisted layered van-der-Waals materials often exhibit unique electronic and optical properties absent in their non-twisted counterparts. Unfortunately, predicting such properties is hindered by the difficulty in determining the atomic structure in materials displaying large moir\'e domains. Here, we introduce a split machine-learned interatomic potential and dataset curation approach that separates intralayer and interlayer interactions and significantly improves model accuracy -- with a tenfold increase in energy and force prediction accuracy relative to conventional models. We further demonstrate that traditional MLIP validation metrics -- force and energy errors -- are inadequate for moir\'e structures and develop a more holistic, physically-motivated metric based on the distribution of stacking configurations. This metric effectively compares the entirety of large-scale moir\'e domains between two structures instead of relying on conventional measures evaluated on smaller commensurate cells. Finally, we establish that one-dimensional instead of two-dimensional moir\'e structures can serve as efficient surrogate systems for validating MLIPs, allowing for a practical model validation protocol against explicit DFT calculations. Applying our framework to HfS2/GaS bilayers reveals that accurate structural predictions directly translate into reliable electronic properties. Our model-agnostic approach integrates seamlessly with various intralayer and interlayer interaction models, enabling computationally tractable relaxation of moir\'e materials, from bilayer to complex multilayers, with rigorously validated accuracy.
Two-Timescale Transmission Design for Wireless Communication Systems Aided by Active RIS
Oct 25, 2022

This paper considers an active reconfigurable intelligent surface (RIS)-aided communication system, where an M-antenna base station (BS) transmits data symbols to a single-antenna user via an N-element active RIS. We use two-timescale channel state information (CSI) in our system, so that the channel estimation overhead and feedback overhead can be decreased dramatically. A closed-form approximate expression of the achievable rate (AR) is derived and the phase shift at the active RIS is optimized. In addition, we compare the performance of the active RIS system with that of the passive RIS system. The conclusion shows that the active RIS system achieves a lager AR than the passive RIS system.
RIS-Aided D2D Communications Relying on Statistical CSI with Imperfect Hardware
Dec 04, 2021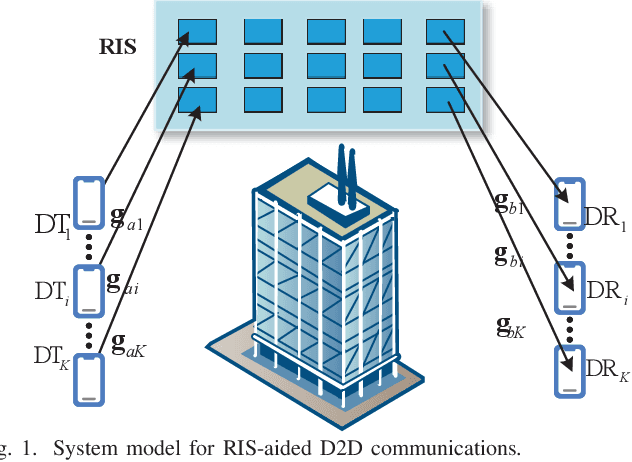
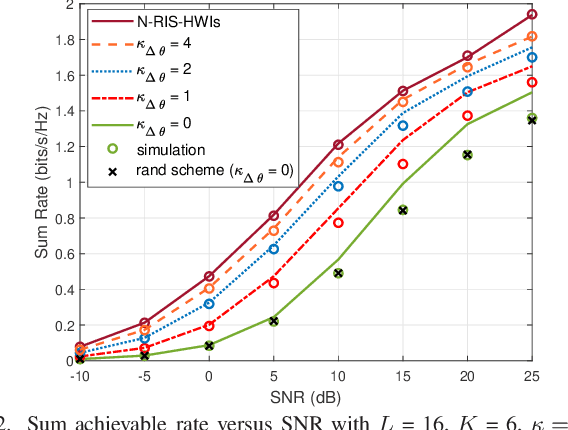
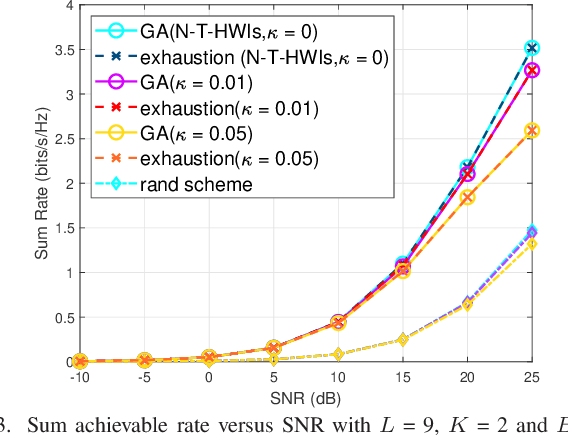
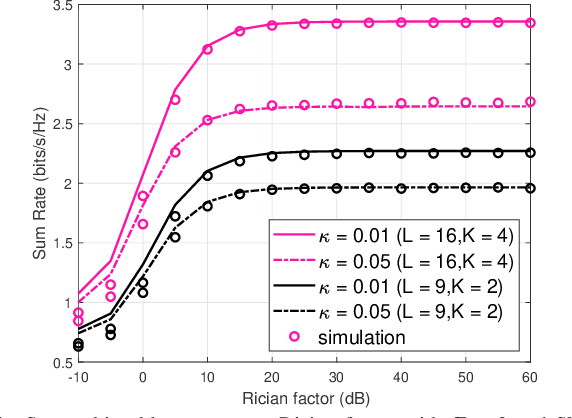
In this letter, we investigate a reconfigurable intelligent surfaces (RIS)-aided device to device (D2D) communication system over Rician fading channels with imperfect hardware including both hardware impairment at the transceivers and phase noise at the RISs. This paper has optimized the phase shift by a genetic algorithm (GA) method to maximize the achievable rate for the continuous phase shifts (CPSs) and discrete phase shifts (DPSs). We also consider the two special cases of no RIS hardware impairments (N-RIS-HWIs) and no transceiver hardware impairments (N-T-HWIs). We present closed-form expressions for the achievable rate of different cases and study the impact of hardware impairments on the communication quality. Finally, simulation results validate the analytic work.