 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransRefer3D: Entity-and-Relation Aware Transformer for Fine-Grained 3D Visual Grounding
Aug 11, 2021
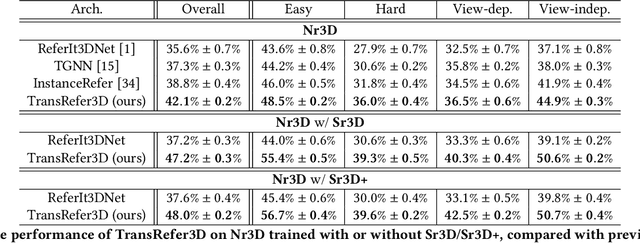
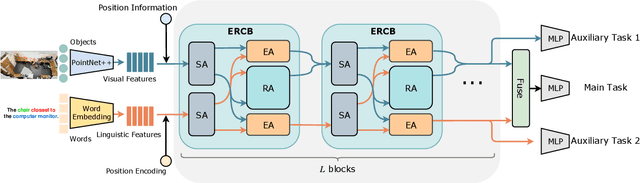

Recently proposed fine-grained 3D visual grounding is an essential and challenging task, whose goal is to identify the 3D object referred by a natural language sentence from other distractive objects of the same category. Existing works usually adopt dynamic graph networks to indirectly model the intra/inter-modal interactions, making the model difficult to distinguish the referred object from distractors due to the monolithic representations of visual and linguistic contents. In this work, we exploit Transformer for its natural suitability on permutation-invariant 3D point clouds data and propose a TransRefer3D network to extract entity-and-relation aware multimodal context among objects for more discriminative feature learning. Concretely, we devise an Entity-aware Attention (EA) module and a Relation-aware Attention (RA) module to conduct fine-grained cross-modal feature matching. Facilitated by co-attention operation, our EA module matches visual entity features with linguistic entity features while RA module matches pair-wise visual relation features with linguistic relation features, respectively. We further integrate EA and RA modules into an Entity-and-Relation aware Contextual Block (ERCB) and stack several ERCBs to form our TransRefer3D for hierarchical multimodal context modeling. Extensive experiments on both Nr3D and Sr3D datasets demonstrate that our proposed model significantly outperforms existing approaches by up to 10.6% and claims the new state-of-the-art. To the best of our knowledge, this is the first work investigating Transformer architecture for fine-grained 3D visual grounding task.
Cross-Modal Progressive Comprehension for Referring Segmentation
May 15, 2021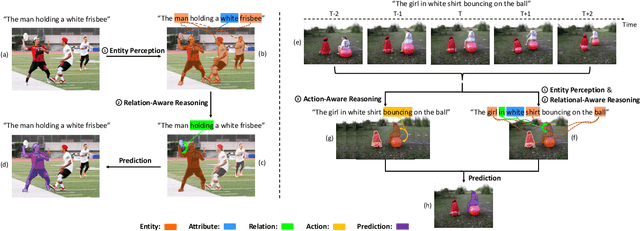
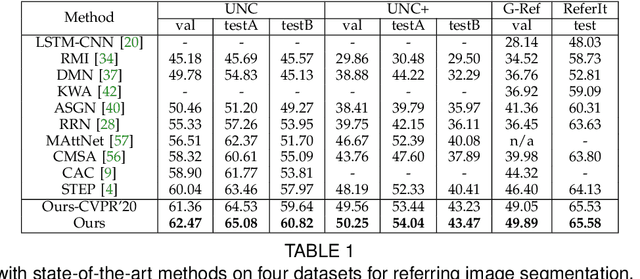
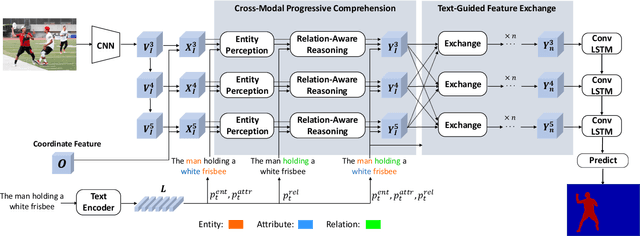
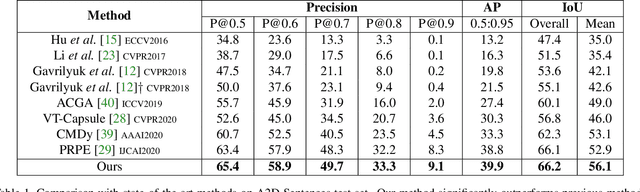
Given a natural language expression and an image/video, the goal of referring segmentation is to produce the pixel-level masks of the entities described by the subject of the expression. Previous approaches tackle this problem by implicit feature interaction and fusion between visual and linguistic modalities in a one-stage manner. However, human tends to solve the referring problem in a progressive manner based on informative words in the expression, i.e., first roughly locating candidate entities and then distinguishing the target one. In this paper, we propose a Cross-Modal Progressive Comprehension (CMPC) scheme to effectively mimic human behaviors and implement it as a CMPC-I (Image) module and a CMPC-V (Video) module to improve referring image and video segmentation models. For image data, our CMPC-I module first employs entity and attribute words to perceive all the related entities that might be considered by the expression. Then, the relational words are adopted to highlight the target entity as well as suppress other irrelevant ones by spatial graph reasoning. For video data, our CMPC-V module further exploits action words based on CMPC-I to highlight the correct entity matched with the action cues by temporal graph reasoning. In addition to the CMPC, we also introduce a simple yet effective Text-Guided Feature Exchange (TGFE) module to integrate the reasoned multimodal features corresponding to different levels in the visual backbone under the guidance of textual information. In this way, multi-level features can communicate with each other and be mutually refined based on the textual context. Combining CMPC-I or CMPC-V with TGFE can form our image or video version referring segmentation frameworks and our frameworks achieve new state-of-the-art performances on four referring image segmentation benchmarks and three referring video segmentation benchmarks respectively.
Collaborative Spatial-Temporal Modeling for Language-Queried Video Actor Segmentation
May 14, 2021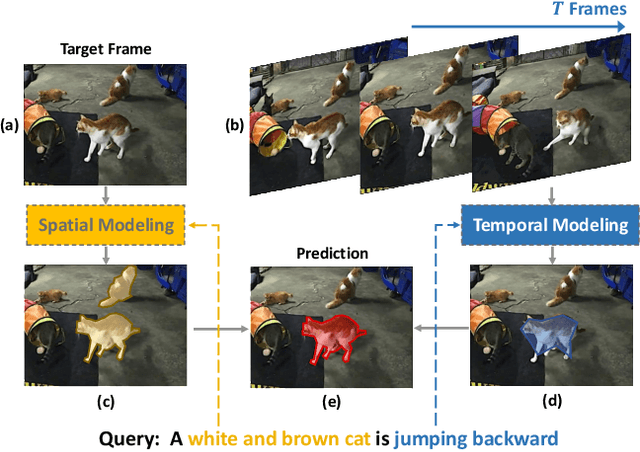
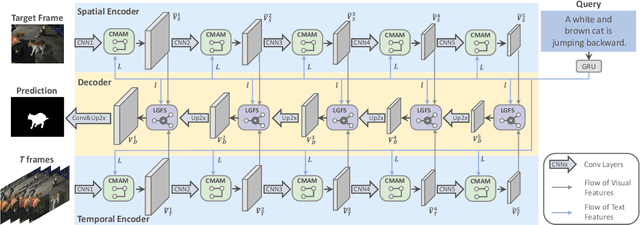
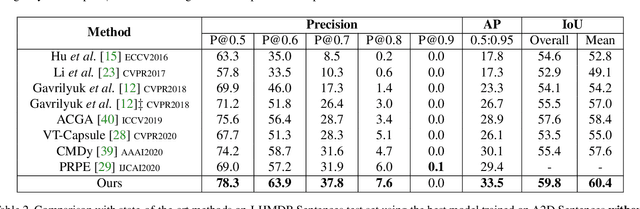
Language-queried video actor segmentation aims to predict the pixel-level mask of the actor which performs the actions described by a natural language query in the target frames. Existing methods adopt 3D CNNs over the video clip as a general encoder to extract a mixed spatio-temporal feature for the target frame. Though 3D convolutions are amenable to recognizing which actor is performing the queried actions, it also inevitably introduces misaligned spatial information from adjacent frames, which confuses features of the target frame and yields inaccurate segmentation. Therefore, we propose a collaborative spatial-temporal encoder-decoder framework which contains a 3D temporal encoder over the video clip to recognize the queried actions, and a 2D spatial encoder over the target frame to accurately segment the queried actors. In the decoder, a Language-Guided Feature Selection (LGFS) module is proposed to flexibly integrate spatial and temporal features from the two encoders. We also propose a Cross-Modal Adaptive Modulation (CMAM) module to dynamically recombine spatial- and temporal-relevant linguistic features for multimodal feature interaction in each stage of the two encoders. Our method achieves new state-of-the-art performance on two popular benchmarks with less computational overhead than previous approaches.
ORDNet: Capturing Omni-Range Dependencies for Scene Parsing
Jan 11, 2021
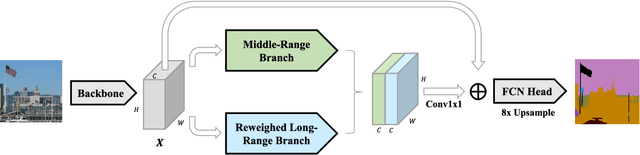
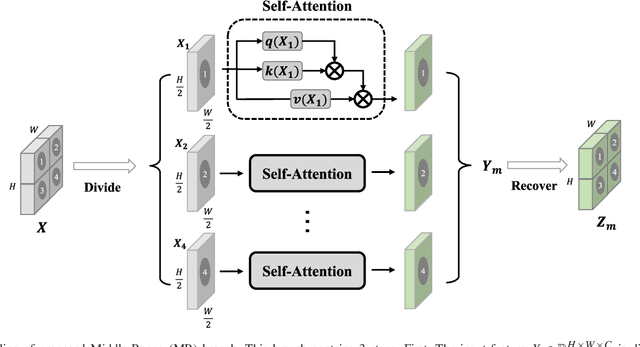
Learning to capture dependencies between spatial positions is essential to many visual tasks, especially the dense labeling problems like scene parsing. Existing methods can effectively capture long-range dependencies with self-attention mechanism while short ones by local convolution. However, there is still much gap between long-range and short-range dependencies, which largely reduces the models' flexibility in application to diverse spatial scales and relationships in complicated natural scene images. To fill such a gap, we develop a Middle-Range (MR) branch to capture middle-range dependencies by restricting self-attention into local patches. Also, we observe that the spatial regions which have large correlations with others can be emphasized to exploit long-range dependencies more accurately, and thus propose a Reweighed Long-Range (RLR) branch. Based on the proposed MR and RLR branches, we build an Omni-Range Dependencies Network (ORDNet) which can effectively capture short-, middle- and long-range dependencies. Our ORDNet is able to extract more comprehensive context information and well adapt to complex spatial variance in scene images. Extensive experiments show that our proposed ORDNet outperforms previous state-of-the-art methods on three scene parsing benchmarks including PASCAL Context, COCO Stuff and ADE20K, demonstrating the superiority of capturing omni-range dependencies in deep models for scene parsing task.
* Published at TIP
Linguistic Structure Guided Context Modeling for Referring Image Segmentation
Oct 05, 2020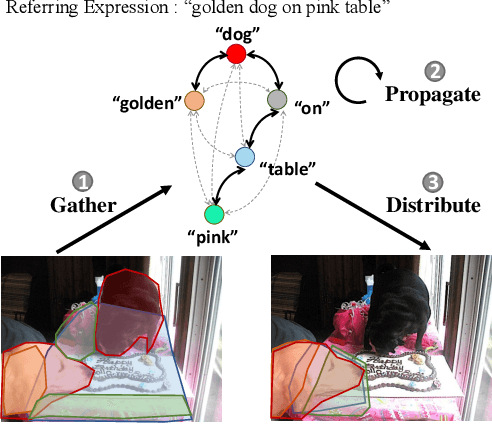
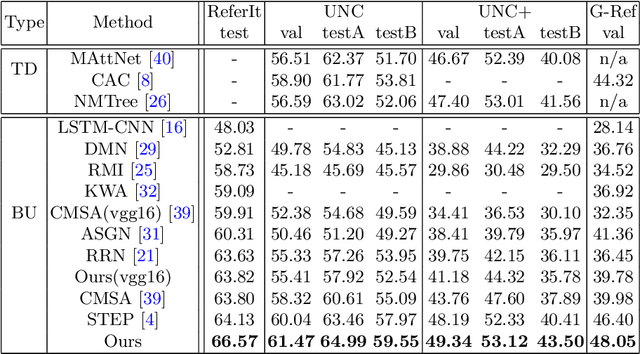
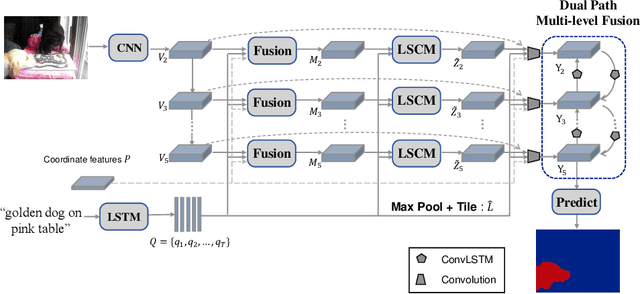
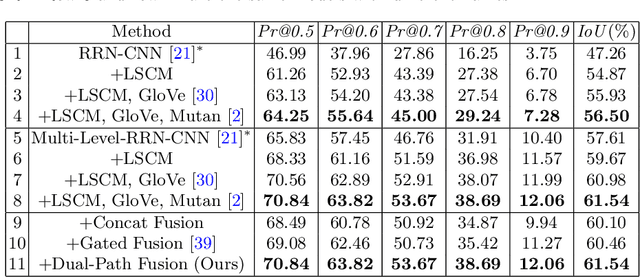
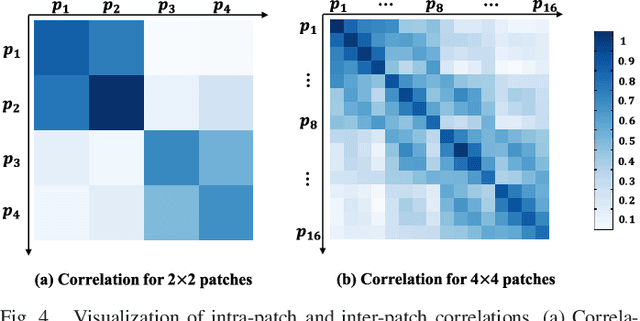
Referring image segmentation aims to predict the foreground mask of the object referred by a natural language sentence. Multimodal context of the sentence is crucial to distinguish the referent from the background. Existing methods either insufficiently or redundantly model the multimodal context. To tackle this problem, we propose a "gather-propagate-distribute" scheme to model multimodal context by cross-modal interaction and implement this scheme as a novel Linguistic Structure guided Context Modeling (LSCM) module. Our LSCM module builds a Dependency Parsing Tree suppressed Word Graph (DPT-WG) which guides all the words to include valid multimodal context of the sentence while excluding disturbing ones through three steps over the multimodal feature, i.e., gathering, constrained propagation and distributing. Extensive experiments on four benchmarks demonstrate that our method outperforms all the previous state-of-the-arts.
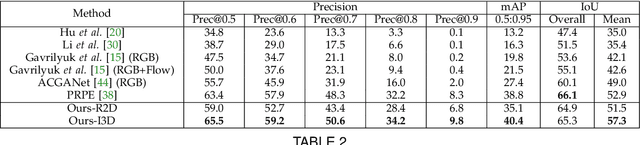
Referring Image Segmentation via Cross-Modal Progressive Comprehension
Oct 01, 2020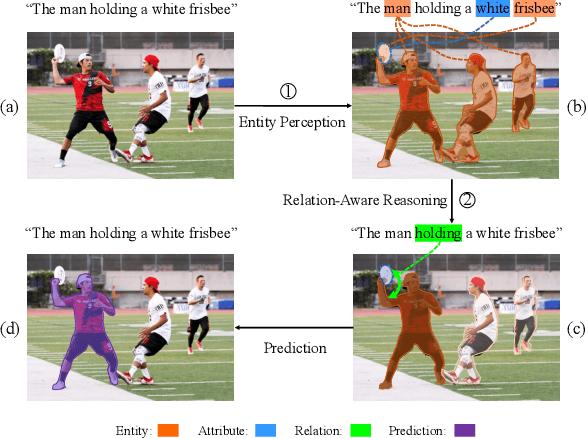
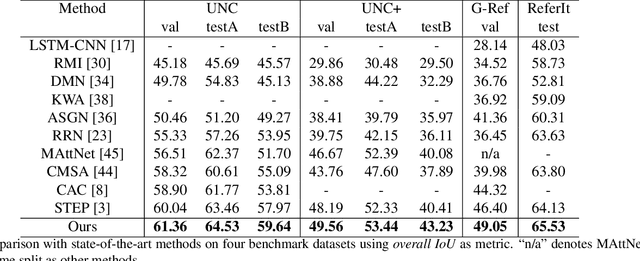
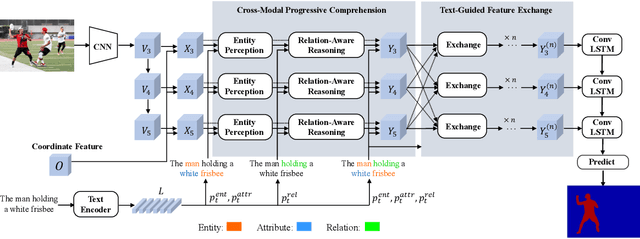
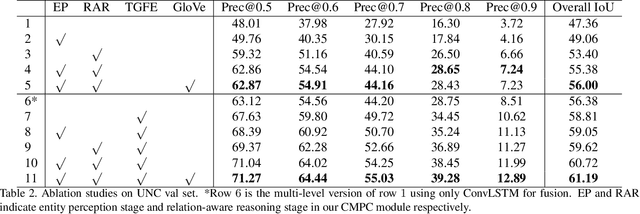
Referring image segmentation aims at segmenting the foreground masks of the entities that can well match the description given in the natural language expression. Previous approaches tackle this problem using implicit feature interaction and fusion between visual and linguistic modalities, but usually fail to explore informative words of the expression to well align features from the two modalities for accurately identifying the referred entity. In this paper, we propose a Cross-Modal Progressive Comprehension (CMPC) module and a Text-Guided Feature Exchange (TGFE) module to effectively address the challenging task. Concretely, the CMPC module first employs entity and attribute words to perceive all the related entities that might be considered by the expression. Then, the relational words are adopted to highlight the correct entity as well as suppress other irrelevant ones by multimodal graph reasoning. In addition to the CMPC module, we further leverage a simple yet effective TGFE module to integrate the reasoned multimodal features from different levels with the guidance of textual information. In this way, features from multi-levels could communicate with each other and be refined based on the textual context. We conduct extensive experiments on four popular referring segmentation benchmarks and achieve new state-of-the-art performances.