 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Framework for Information-Theoretic Probing
Sep 08, 2021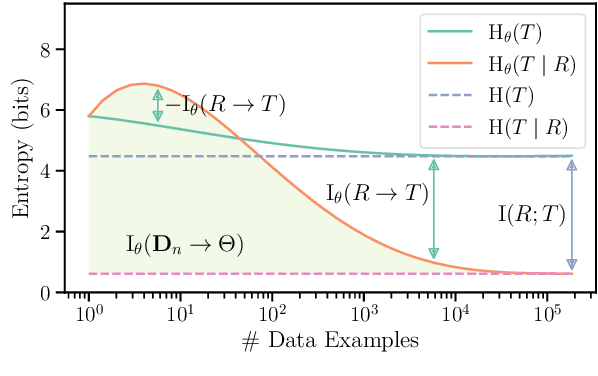
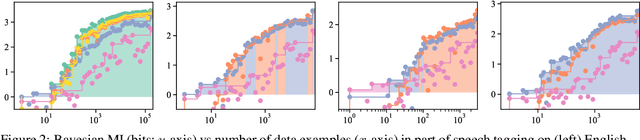
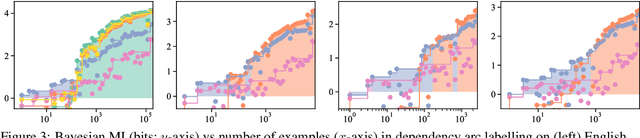
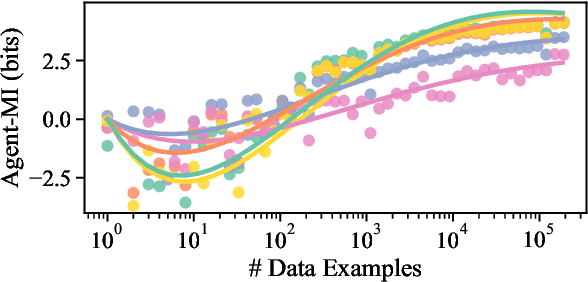
Pimentel et al. (2020) recently analysed probing from an information-theoretic perspective. They argue that probing should be seen as approximating a mutual information. This led to the rather unintuitive conclusion that representations encode exactly the same information about a target task as the original sentences. The mutual information, however, assumes the true probability distribution of a pair of random variables is known, leading to unintuitive results in settings where it is not. This paper proposes a new framework to measure what we term Bayesian mutual information, which analyses information from the perspective of Bayesian agents -- allowing for more intuitive findings in scenarios with finite data. For instance, under Bayesian MI we have that data can add information, processing can help, and information can hurt, which makes it more intuitive for machine learning applications. Finally, we apply our framework to probing where we believe Bayesian mutual information naturally operationalises ease of extraction by explicitly limiting the available background knowledge to solve a task.
Modeling the Unigram Distribution
Jun 04, 2021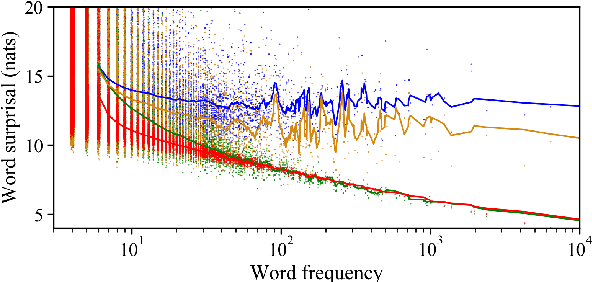

The unigram distribution is the non-contextual probability of finding a specific word form in a corpus. While of central importance to the study of language, it is commonly approximated by each word's sample frequency in the corpus. This approach, being highly dependent on sample size, assigns zero probability to any out-of-vocabulary (oov) word form. As a result, it produces negatively biased probabilities for any oov word form, while positively biased probabilities to in-corpus words. In this work, we argue in favor of properly modeling the unigram distribution -- claiming it should be a central task in natural language processing. With this in mind, we present a novel model for estimating it in a language (a neuralization of Goldwater et al.'s (2011) model) and show it produces much better estimates across a diverse set of 7 languages than the na\"ive use of neural character-level language models.
A Non-Linear Structural Probe
May 21, 2021
Probes are models devised to investigate the encoding of knowledge -- e.g. syntactic structure -- in contextual representations. Probes are often designed for simplicity, which has led to restrictions on probe design that may not allow for the full exploitation of the structure of encoded information; one such restriction is linearity. We examine the case of a structural probe (Hewitt and Manning, 2019), which aims to investigate the encoding of syntactic structure in contextual representations through learning only linear transformations. By observing that the structural probe learns a metric, we are able to kernelize it and develop a novel non-linear variant with an identical number of parameters. We test on 6 languages and find that the radial-basis function (RBF) kernel, in conjunction with regularization, achieves a statistically significant improvement over the baseline in all languages -- implying that at least part of the syntactic knowledge is encoded non-linearly. We conclude by discussing how the RBF kernel resembles BERT's self-attention layers and speculate that this resemblance leads to the RBF-based probe's stronger performance.
How (Non-)Optimal is the Lexicon?
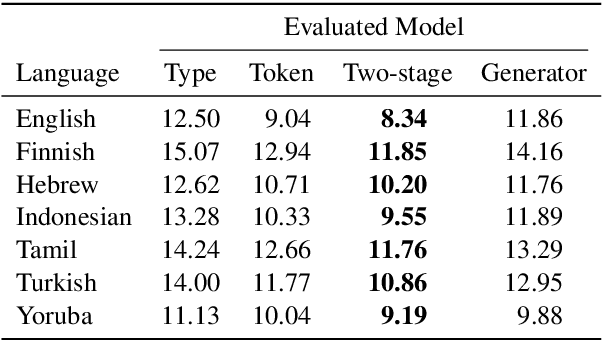
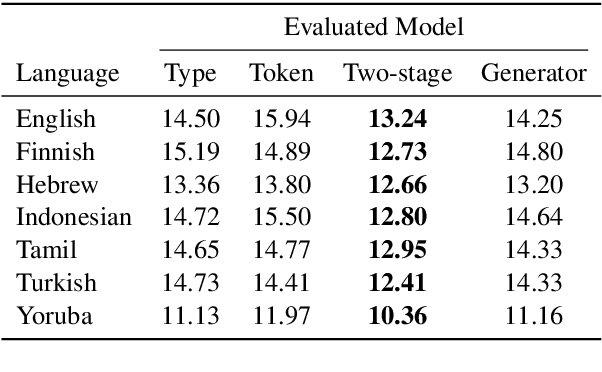
Apr 30, 2021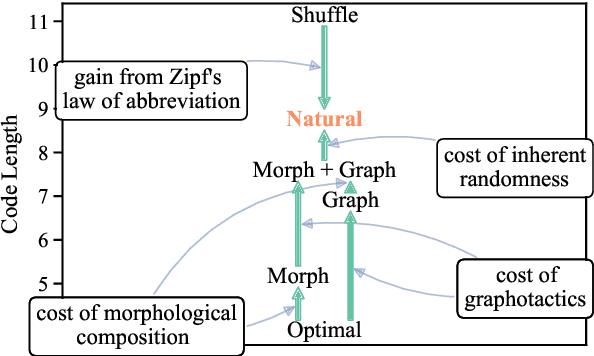
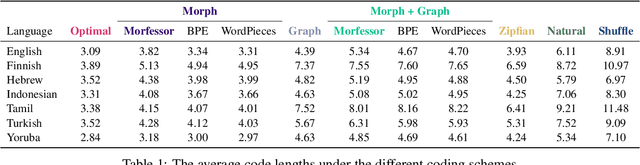
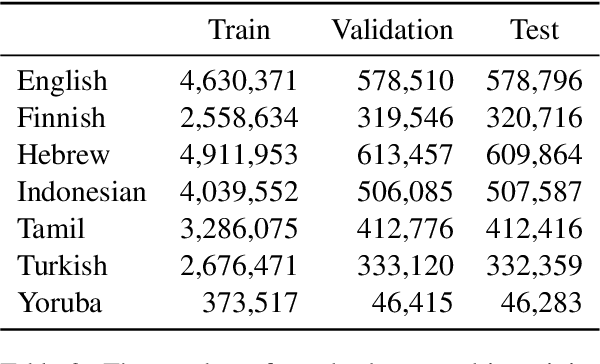
The mapping of lexical meanings to wordforms is a major feature of natural languages. While usage pressures might assign short words to frequent meanings (Zipf's law of abbreviation), the need for a productive and open-ended vocabulary, local constraints on sequences of symbols, and various other factors all shape the lexicons of the world's languages. Despite their importance in shaping lexical structure, the relative contributions of these factors have not been fully quantified. Taking a coding-theoretic view of the lexicon and making use of a novel generative statistical model, we define upper bounds for the compressibility of the lexicon under various constraints. Examining corpora from 7 typologically diverse languages, we use those upper bounds to quantify the lexicon's optimality and to explore the relative costs of major constraints on natural codes. We find that (compositional) morphology and graphotactics can sufficiently account for most of the complexity of natural codes -- as measured by code length.
Finding Concept-specific Biases in Form--Meaning Associations
Apr 29, 2021
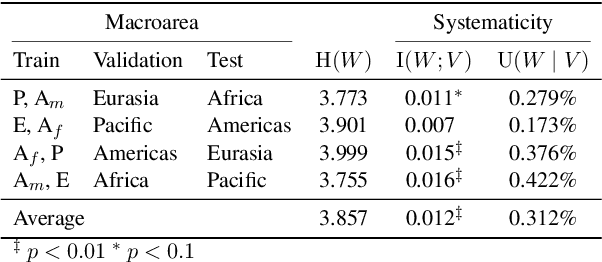
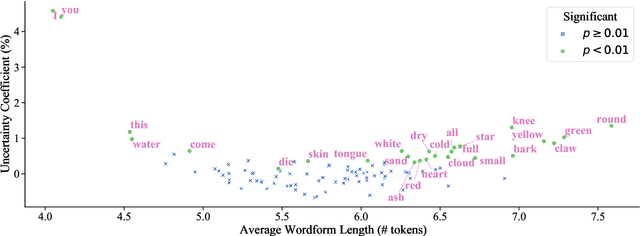
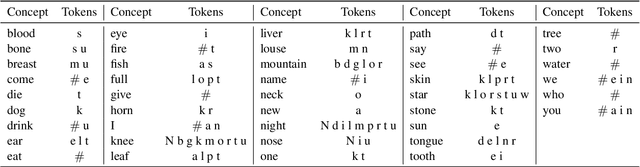
This work presents an information-theoretic operationalisation of cross-linguistic non-arbitrariness. It is not a new idea that there are small, cross-linguistic associations between the forms and meanings of words. For instance, it has been claimed (Blasi et al., 2016) that the word for "tongue" is more likely than chance to contain the phone [l]. By controlling for the influence of language family and geographic proximity within a very large concept-aligned, cross-lingual lexicon, we extend methods previously used to detect within language non-arbitrariness (Pimentel et al., 2019) to measure cross-linguistic associations. We find that there is a significant effect of non-arbitrariness, but it is unsurprisingly small (less than 0.5% on average according to our information-theoretic estimate). We also provide a concept-level analysis which shows that a quarter of the concepts considered in our work exhibit a significant level of cross-linguistic non-arbitrariness. In sum, the paper provides new methods to detect cross-linguistic associations at scale, and confirms their effects are minor.
Quantifying Gender Bias Towards Politicians in Cross-Lingual Language Models
Apr 15, 2021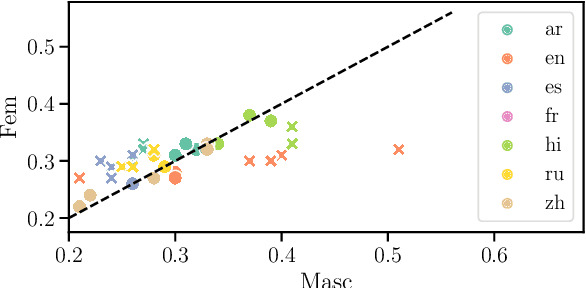
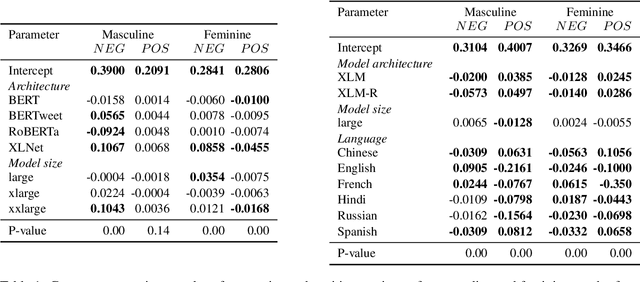
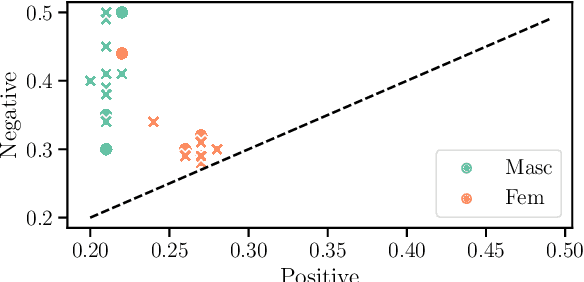

While the prevalence of large pre-trained language models has led to significant improvements in the performance of NLP systems, recent research has demonstrated that these models inherit societal biases extant in natural language. In this paper, we explore a simple method to probe pre-trained language models for gender bias, which we use to effect a multi-lingual study of gender bias towards politicians. We construct a dataset of 250k politicians from most countries in the world and quantify adjective and verb usage around those politicians' names as a function of their gender. We conduct our study in 7 languages across 6 different language modeling architectures. Our results demonstrate that stance towards politicians in pre-trained language models is highly dependent on the language used. Finally, contrary to previous findings, our study suggests that larger language models do not tend to be significantly more gender-biased than smaller ones.
Disambiguatory Signals are Stronger in Word-initial Positions
Feb 03, 2021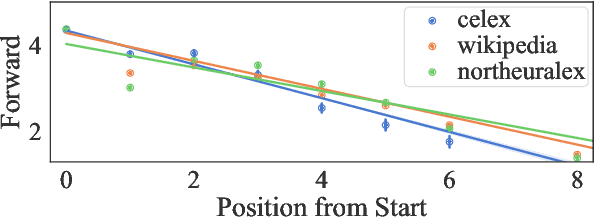
Psycholinguistic studies of human word processing and lexical access provide ample evidence of the preferred nature of word-initial versus word-final segments, e.g., in terms of attention paid by listeners (greater) or the likelihood of reduction by speakers (lower). This has led to the conjecture -- as in Wedel et al. (2019b), but common elsewhere -- that languages have evolved to provide more information earlier in words than later. Information-theoretic methods to establish such tendencies in lexicons have suffered from several methodological shortcomings that leave open the question of whether this high word-initial informativeness is actually a property of the lexicon or simply an artefact of the incremental nature of recognition. In this paper, we point out the confounds in existing methods for comparing the informativeness of segments early in the word versus later in the word, and present several new measures that avoid these confounds. When controlling for these confounds, we still find evidence across hundreds of languages that indeed there is a cross-linguistic tendency to front-load information in words.
Pareto Probing: Trading Off Accuracy for Complexity
Oct 05, 2020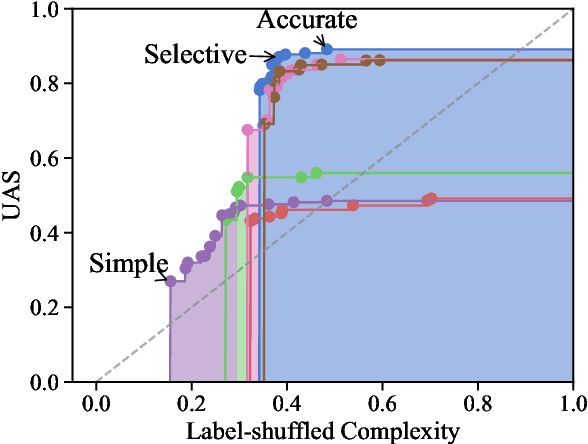
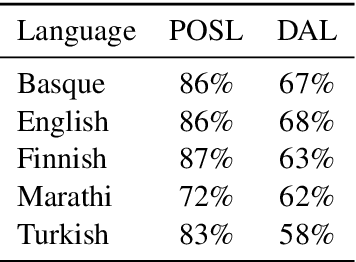
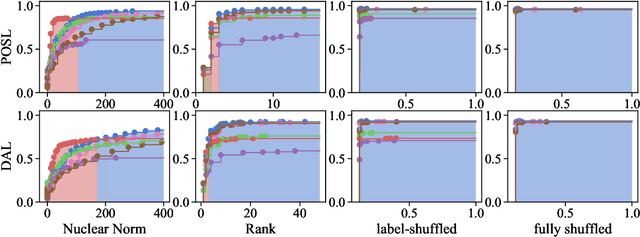
The question of how to probe contextual word representations in a way that is principled and useful has seen significant recent attention. In our contribution to this discussion, we argue, first, for a probe metric that reflects the trade-off between probe complexity and performance: the Pareto hypervolume. To measure complexity, we present a number of parametric and non-parametric metrics. Our experiments with such metrics show that probe's performance curves often fail to align with widely accepted rankings between language representations (with, e.g., non-contextual representations outperforming contextual ones). These results lead us to argue, second, that common simplistic probe tasks such as POS labeling and dependency arc labeling, are inadequate to evaluate the properties encoded in contextual word representations. We propose full dependency parsing as an example probe task, and demonstrate it with the Pareto hypervolume. In support of our arguments, the results of this illustrative experiment conform closer to accepted rankings among contextual word representations.
Speakers Fill Lexical Semantic Gaps with Context
Oct 05, 2020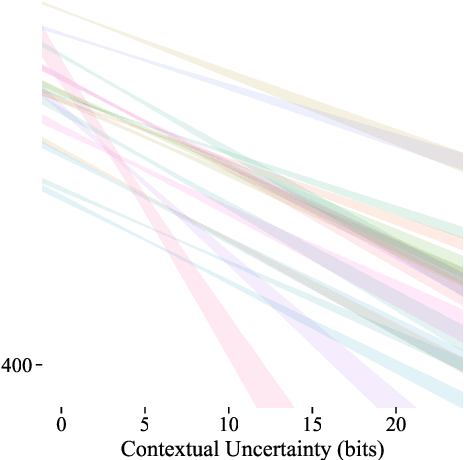
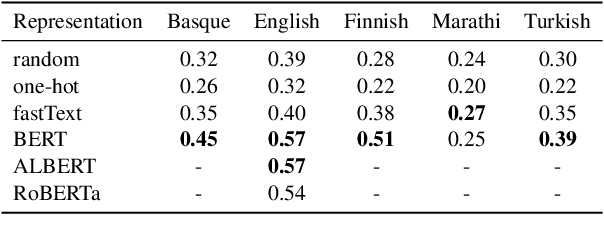
Lexical ambiguity is widespread in language, allowing for the reuse of economical word forms and therefore making language more efficient. If ambiguous words cannot be disambiguated from context, however, this gain in efficiency might make language less clear---resulting in frequent miscommunication. For a language to be clear and efficiently encoded, we posit that the lexical ambiguity of a word type should correlate with how much information context provides about it, on average. To investigate whether this is the case, we operationalise the lexical ambiguity of a word as the entropy of meanings it can take, and provide two ways to estimate this---one which requires human annotation (using WordNet), and one which does not (using BERT), making it readily applicable to a large number of languages. We validate these measures by showing that, on six high-resource languages, there are significant Pearson correlations between our BERT-based estimate of ambiguity and the number of synonyms a word has in WordNet (e.g. $\rho = 0.40$ in English). We then test our main hypothesis---that a word's lexical ambiguity should negatively correlate with its contextual uncertainty---and find significant correlations on all 18 typologically diverse languages we analyse. This suggests that, in the presence of ambiguity, speakers compensate by making contexts more informative.
SIGMORPHON 2020 Shared Task 0: Typologically Diverse Morphological Inflection
Jul 14, 2020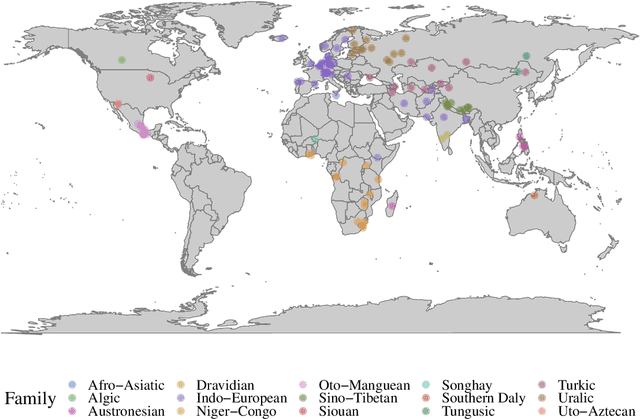
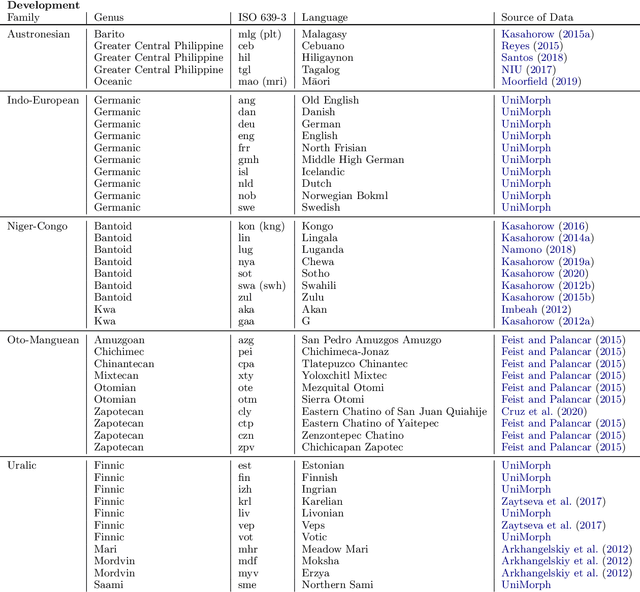
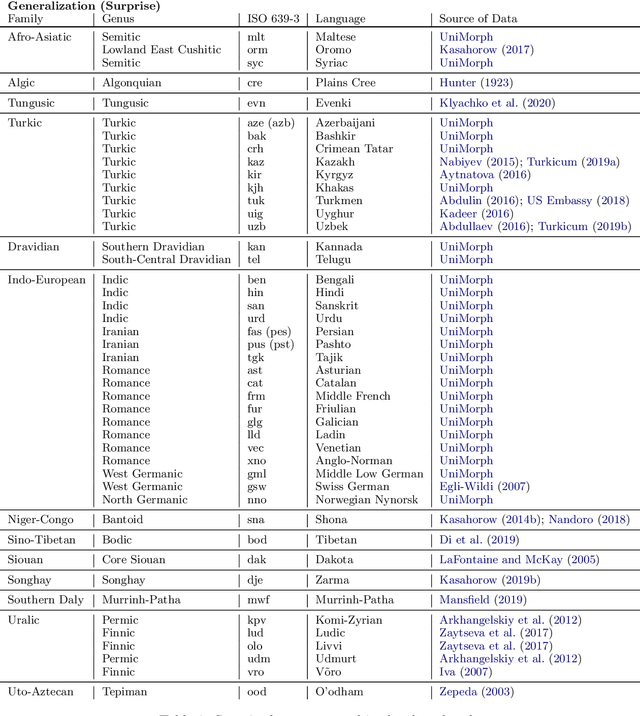
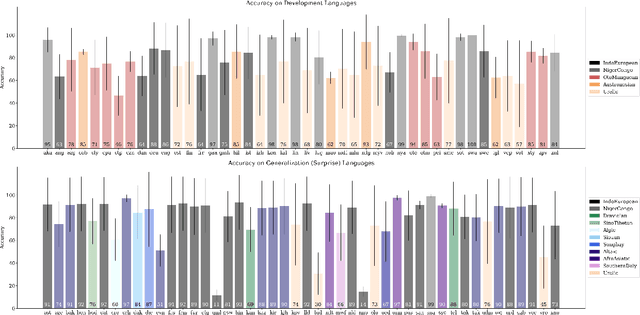
A broad goal in natural language processing (NLP) is to develop a system that has the capacity to process any natural language. Most systems, however, are developed using data from just one language such as English. The SIGMORPHON 2020 shared task on morphological reinflection aims to investigate systems' ability to generalize across typologically distinct languages, many of which are low resource. Systems were developed using data from 45 languages and just 5 language families, fine-tuned with data from an additional 45 languages and 10 language families (13 in total), and evaluated on all 90 languages. A total of 22 systems (19 neural) from 10 teams were submitted to the task. All four winning systems were neural (two monolingual transformers and two massively multilingual RNN-based models with gated attention). Most teams demonstrate utility of data hallucination and augmentation, ensembles, and multilingual training for low-resource languages. Non-neural learners and manually designed grammars showed competitive and even superior performance on some languages (such as Ingrian, Tajik, Tagalog, Zarma, Lingala), especially with very limited data. Some language families (Afro-Asiatic, Niger-Congo, Turkic) were relatively easy for most systems and achieved over 90% mean accuracy while others were more challenging.