 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning A Task-Specific Deep Architecture For Clustering
Oct 16, 2015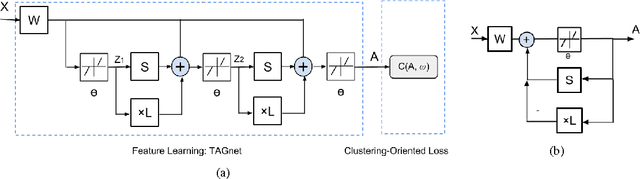

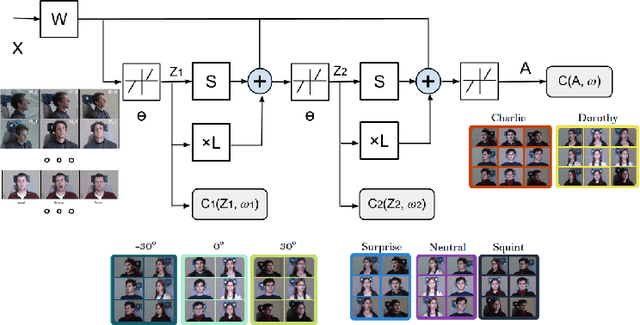
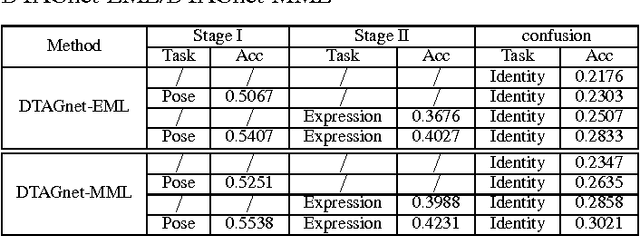
While sparse coding-based clustering methods have shown to be successful, their bottlenecks in both efficiency and scalability limit the practical usage. In recent years, deep learning has been proved to be a highly effective, efficient and scalable feature learning tool. In this paper, we propose to emulate the sparse coding-based clustering pipeline in the context of deep learning, leading to a carefully crafted deep model benefiting from both. A feed-forward network structure, named TAGnet, is constructed based on a graph-regularized sparse coding algorithm. It is then trained with task-specific loss functions from end to end. We discover that connecting deep learning to sparse coding benefits not only the model performance, but also its initialization and interpretation. Moreover, by introducing auxiliary clustering tasks to the intermediate feature hierarchy, we formulate DTAGnet and obtain a further performance boost. Extensive experiments demonstrate that the proposed model gains remarkable margins over several state-of-the-art methods.
Designing A Composite Dictionary Adaptively From Joint Examples
Sep 08, 2015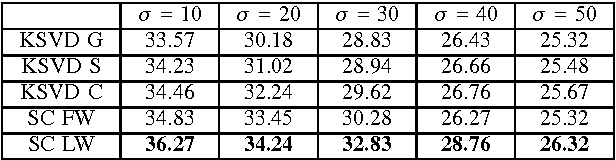
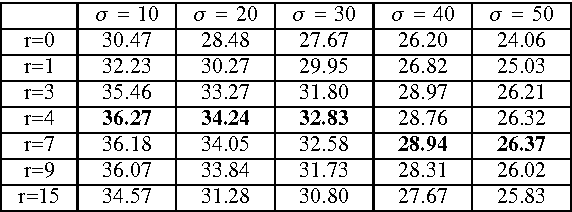
We study the complementary behaviors of external and internal examples in image restoration, and are motivated to formulate a composite dictionary design framework. The composite dictionary consists of the global part learned from external examples, and the sample-specific part learned from internal examples. The dictionary atoms in both parts are further adaptively weighted to emphasize their model statistics. Experiments demonstrate that the joint utilization of external and internal examples leads to substantial improvements, with successful applications in image denoising and super resolution.
DeepFont: Identify Your Font from An Image
Jul 12, 2015
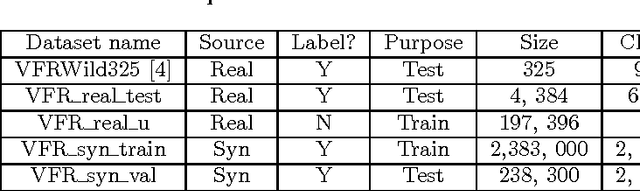


As font is one of the core design concepts, automatic font identification and similar font suggestion from an image or photo has been on the wish list of many designers. We study the Visual Font Recognition (VFR) problem, and advance the state-of-the-art remarkably by developing the DeepFont system. First of all, we build up the first available large-scale VFR dataset, named AdobeVFR, consisting of both labeled synthetic data and partially labeled real-world data. Next, to combat the domain mismatch between available training and testing data, we introduce a Convolutional Neural Network (CNN) decomposition approach, using a domain adaptation technique based on a Stacked Convolutional Auto-Encoder (SCAE) that exploits a large corpus of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. Moreover, we study a novel learning-based model compression approach, in order to reduce the DeepFont model size without sacrificing its performance. The DeepFont system achieves an accuracy of higher than 80% (top-5) on our collected dataset, and also produces a good font similarity measure for font selection and suggestion. We also achieve around 6 times compression of the model without any visible loss of recognition accuracy.
Learning Super-Resolution Jointly from External and Internal Examples
Jun 16, 2015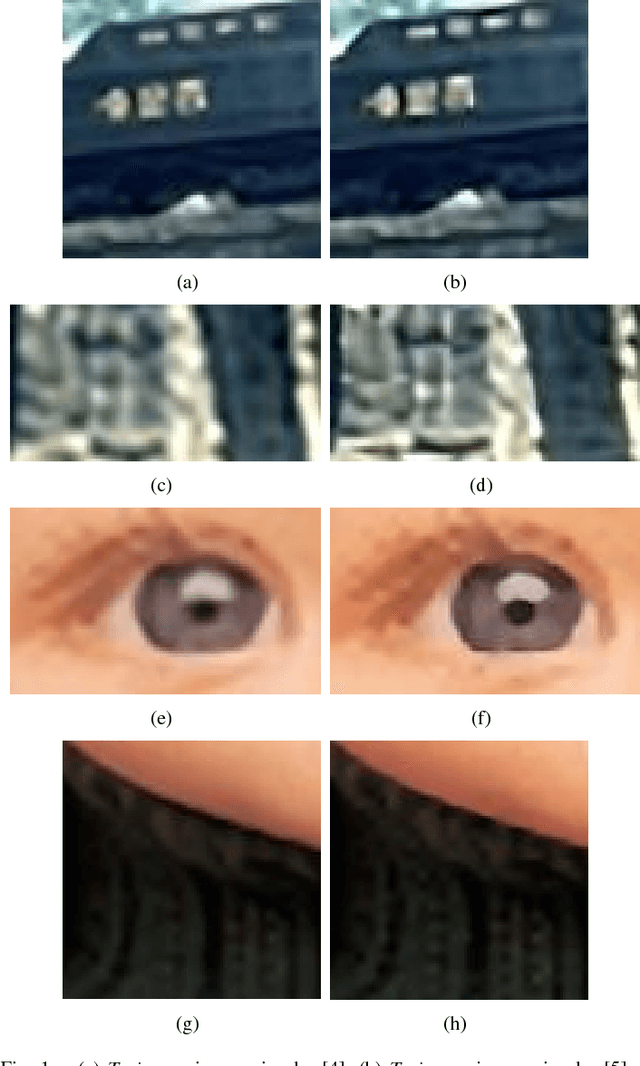



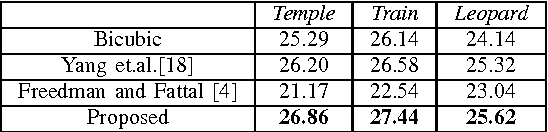
Single image super-resolution (SR) aims to estimate a high-resolution (HR) image from a lowresolution (LR) input. Image priors are commonly learned to regularize the otherwise seriously ill-posed SR problem, either using external LR-HR pairs or internal similar patterns. We propose joint SR to adaptively combine the advantages of both external and internal SR methods. We define two loss functions using sparse coding based external examples, and epitomic matching based on internal examples, as well as a corresponding adaptive weight to automatically balance their contributions according to their reconstruction errors. Extensive SR results demonstrate the effectiveness of the proposed method over the existing state-of-the-art methods, and is also verified by our subjective evaluation study.
Self-Tuned Deep Super Resolution
Apr 22, 2015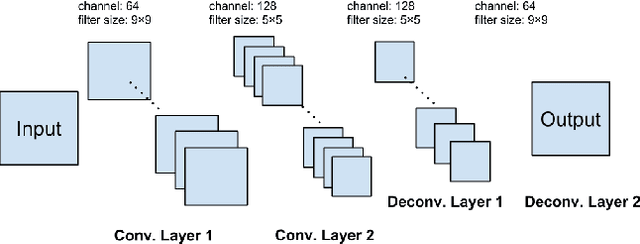
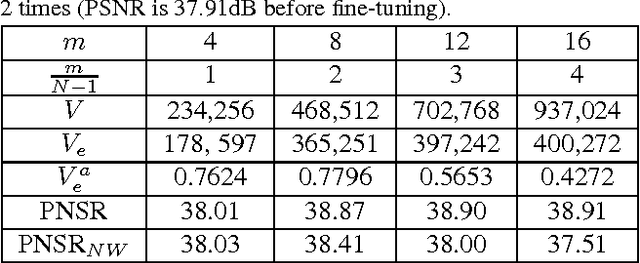


Deep learning has been successfully applied to image super resolution (SR). In this paper, we propose a deep joint super resolution (DJSR) model to exploit both external and self similarities for SR. A Stacked Denoising Convolutional Auto Encoder (SDCAE) is first pre-trained on external examples with proper data augmentations. It is then fine-tuned with multi-scale self examples from each input, where the reliability of self examples is explicitly taken into account. We also enhance the model performance by sub-model training and selection. The DJSR model is extensively evaluated and compared with state-of-the-arts, and show noticeable performance improvements both quantitatively and perceptually on a wide range of images.
An Analysis of Unsupervised Pre-training in Light of Recent Advances
Apr 10, 2015

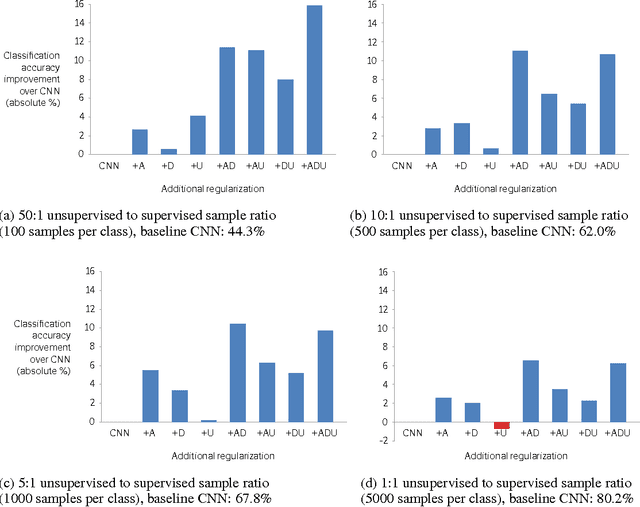

Convolutional neural networks perform well on object recognition because of a number of recent advances: rectified linear units (ReLUs), data augmentation, dropout, and large labelled datasets. Unsupervised data has been proposed as another way to improve performance. Unfortunately, unsupervised pre-training is not used by state-of-the-art methods leading to the following question: Is unsupervised pre-training still useful given recent advances? If so, when? We answer this in three parts: we 1) develop an unsupervised method that incorporates ReLUs and recent unsupervised regularization techniques, 2) analyze the benefits of unsupervised pre-training compared to data augmentation and dropout on CIFAR-10 while varying the ratio of unsupervised to supervised samples, 3) verify our findings on STL-10. We discover unsupervised pre-training, as expected, helps when the ratio of unsupervised to supervised samples is high, and surprisingly, hurts when the ratio is low. We also use unsupervised pre-training with additional color augmentation to achieve near state-of-the-art performance on STL-10.
Decomposition-Based Domain Adaptation for Real-World Font Recognition
Apr 01, 2015

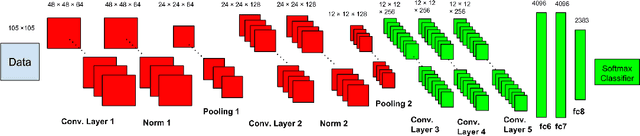

We present a domain adaption framework to address a domain mismatch between synthetic training and real-world testing data. We demonstrate our method on a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous font recognition methods (Chen et al. (2014)). In this paper, we introduce a Convolutional Neural Network decomposition approach, leveraging a large training corpus of synthetic data to obtain effective features for classification. This is done using an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits a large collection of unlabeled real-world text images combined with synthetic data preprocessed in a specific way. The proposed DeepFont method achieves an accuracy of higher than 80% (top-5) on a new large labeled real-world dataset we collected.
Real-World Font Recognition Using Deep Network and Domain Adaptation
Mar 31, 2015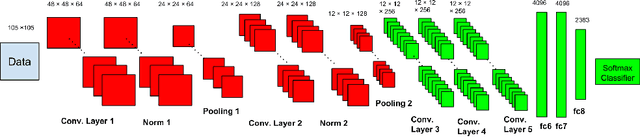
We address a challenging fine-grain classification problem: recognizing a font style from an image of text. In this task, it is very easy to generate lots of rendered font examples but very hard to obtain real-world labeled images. This real-to-synthetic domain gap caused poor generalization to new real data in previous methods (Chen et al. (2014)). In this paper, we refer to Convolutional Neural Networks, and use an adaptation technique based on a Stacked Convolutional Auto-Encoder that exploits unlabeled real-world images combined with synthetic data. The proposed method achieves an accuracy of higher than 80% (top-5) on a real-world dataset.
Nonparametric Unsupervised Classification
May 20, 2013Unsupervised classification methods learn a discriminative classifier from unlabeled data, which has been proven to be an effective way of simultaneously clustering the data and training a classifier from the data. Various unsupervised classification methods obtain appealing results by the classifiers learned in an unsupervised manner. However, existing methods do not consider the misclassification error of the unsupervised classifiers except unsupervised SVM, so the performance of the unsupervised classifiers is not fully evaluated. In this work, we study the misclassification error of two popular classifiers, i.e. the nearest neighbor classifier (NN) and the plug-in classifier, in the setting of unsupervised classification.
Variational Learning in Mixed-State Dynamic Graphical Models
Jan 23, 2013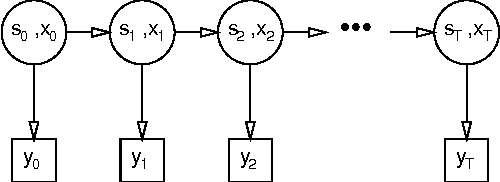
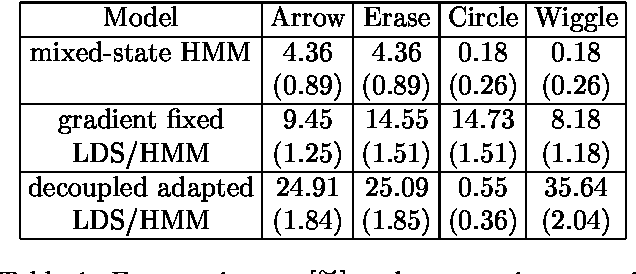
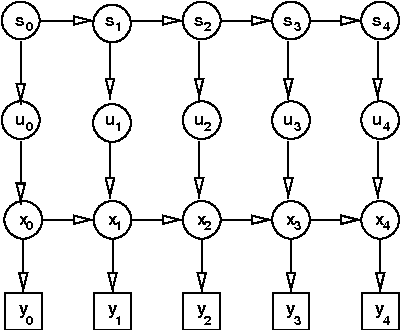
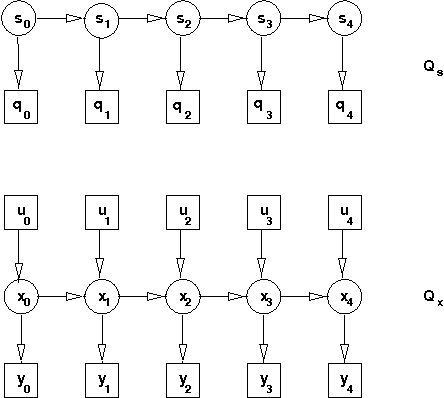
Many real-valued stochastic time-series are locally linear (Gassian), but globally non-linear. For example, the trajectory of a human hand gesture can be viewed as a linear dynamic system driven by a nonlinear dynamic system that represents muscle actions. We present a mixed-state dynamic graphical model in which a hidden Markov model drives a linear dynamic system. This combination allows us to model both the discrete and continuous causes of trajectories such as human gestures. The number of computations needed for exact inference is exponential in the sequence length, so we derive an approximate variational inference technique that can also be used to learn the parameters of the discrete and continuous models. We show how the mixed-state model and the variational technique can be used to classify human hand gestures made with a computer mouse.