 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand Pose Estimation via Latent 2.5D Heatmap Regression
Apr 25, 2018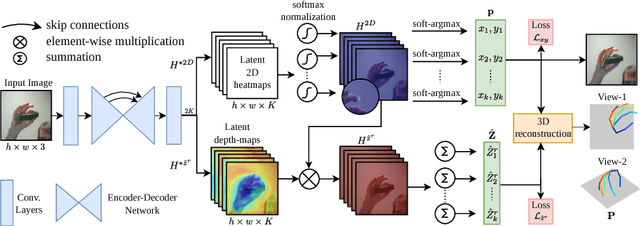
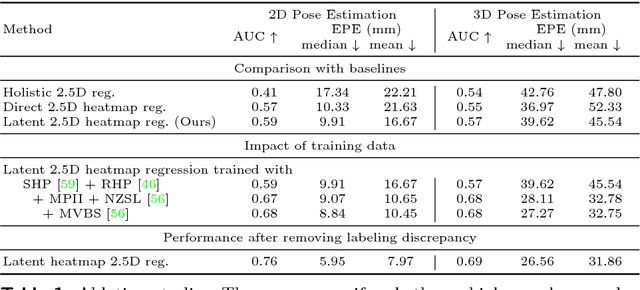

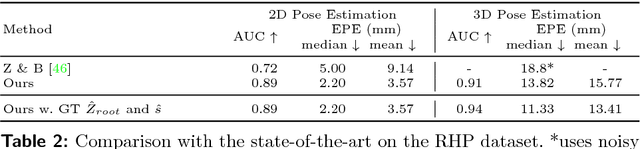
Estimating the 3D pose of a hand is an essential part of human-computer interaction. Estimating 3D pose using depth or multi-view sensors has become easier with recent advances in computer vision, however, regressing pose from a single RGB image is much less straightforward. The main difficulty arises from the fact that 3D pose requires some form of depth estimates, which are ambiguous given only an RGB image. In this paper we propose a new method for 3D hand pose estimation from a monocular image through a novel 2.5D pose representation. Our new representation estimates pose up to a scaling factor, which can be estimated additionally if a prior of the hand size is given. We implicitly learn depth maps and heatmap distributions with a novel CNN architecture. Our system achieves the state-of-the-art estimation of 2D and 3D hand pose on several challenging datasets in presence of severe occlusions.
Sequence-to-sequence neural network models for transliteration
Oct 29, 2016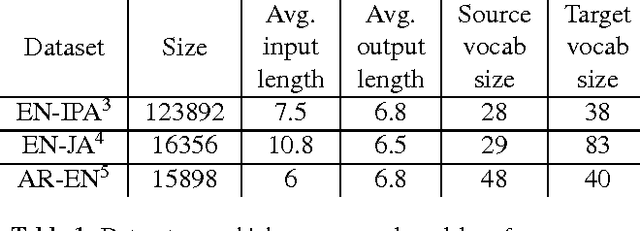
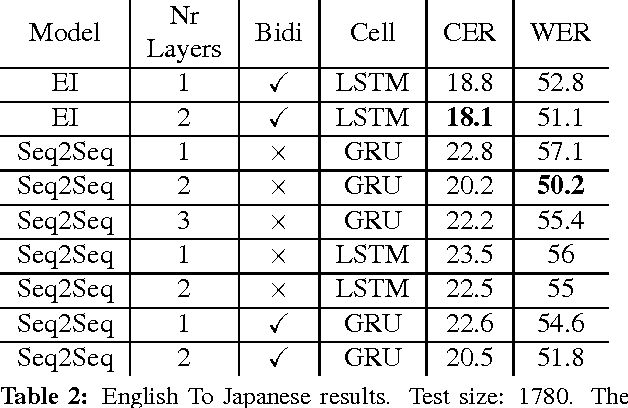
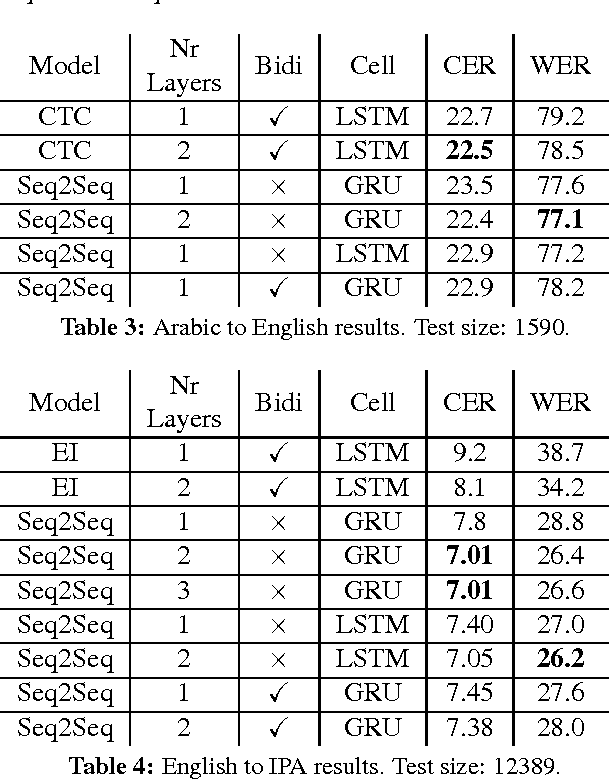
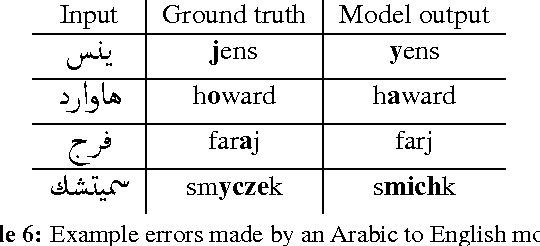
Transliteration is a key component of machine translation systems and software internationalization. This paper demonstrates that neural sequence-to-sequence models obtain state of the art or close to state of the art results on existing datasets. In an effort to make machine transliteration accessible, we open source a new Arabic to English transliteration dataset and our trained models.
Efficient Estimation of k for the Nearest Neighbors Class of Methods
Jun 13, 2016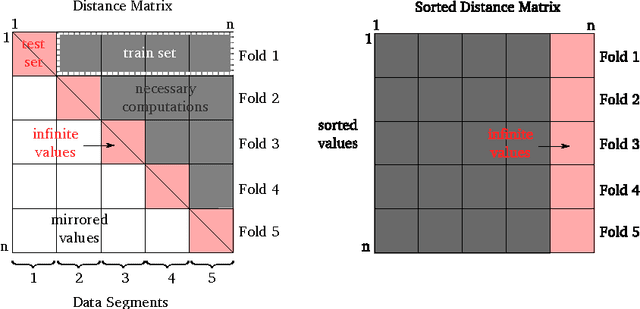
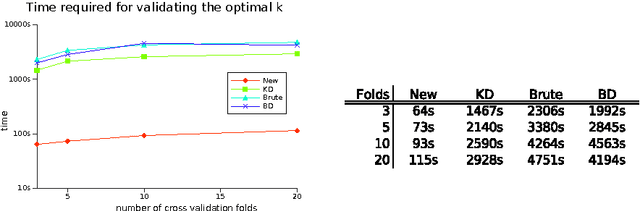
The k Nearest Neighbors (kNN) method has received much attention in the past decades, where some theoretical bounds on its performance were identified and where practical optimizations were proposed for making it work fairly well in high dimensional spaces and on large datasets. From countless experiments of the past it became widely accepted that the value of k has a significant impact on the performance of this method. However, the efficient optimization of this parameter has not received so much attention in literature. Today, the most common approach is to cross-validate or bootstrap this value for all values in question. This approach forces distances to be recomputed many times, even if efficient methods are used. Hence, estimating the optimal k can become expensive even on modern systems. Frequently, this circumstance leads to a sparse manual search of k. In this paper we want to point out that a systematic and thorough estimation of the parameter k can be performed efficiently. The discussed approach relies on large matrices, but we want to argue, that in practice a higher space complexity is often much less of a problem than repetitive distance computations.
Combining the Best of Convolutional Layers and Recurrent Layers: A Hybrid Network for Semantic Segmentation
Mar 15, 2016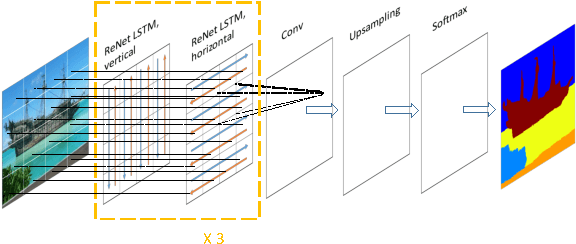
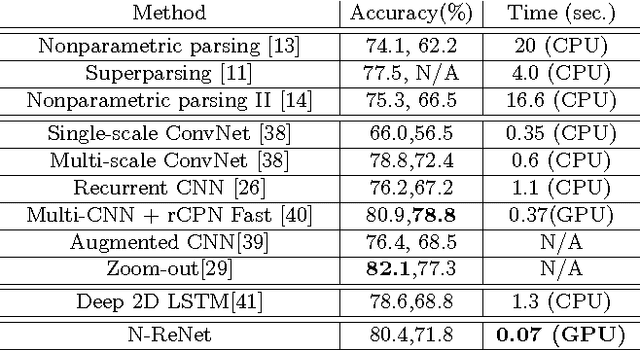


State-of-the-art results of semantic segmentation are established by Fully Convolutional neural Networks (FCNs). FCNs rely on cascaded convolutional and pooling layers to gradually enlarge the receptive fields of neurons, resulting in an indirect way of modeling the distant contextual dependence. In this work, we advocate the use of spatially recurrent layers (i.e. ReNet layers) which directly capture global contexts and lead to improved feature representations. We demonstrate the effectiveness of ReNet layers by building a Naive deep ReNet (N-ReNet), which achieves competitive performance on Stanford Background dataset. Furthermore, we integrate ReNet layers with FCNs, and develop a novel Hybrid deep ReNet (H-ReNet). It enjoys a few remarkable properties, including full-image receptive fields, end-to-end training, and efficient network execution. On the PASCAL VOC 2012 benchmark, the H-ReNet improves the results of state-of-the-art approaches Piecewise, CRFasRNN and DeepParsing by 3.6%, 2.3% and 0.2%, respectively, and achieves the highest IoUs for 13 out of the 20 object classes.
Deep Self-Taught Learning for Handwritten Character Recognition
Sep 18, 2010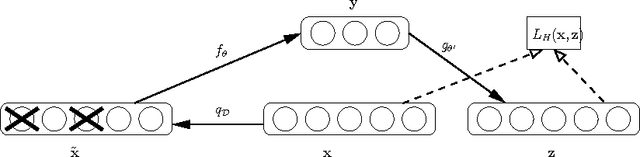
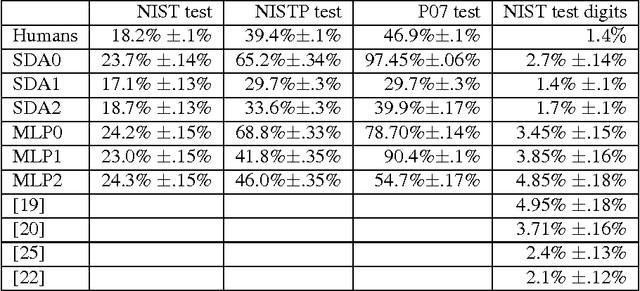
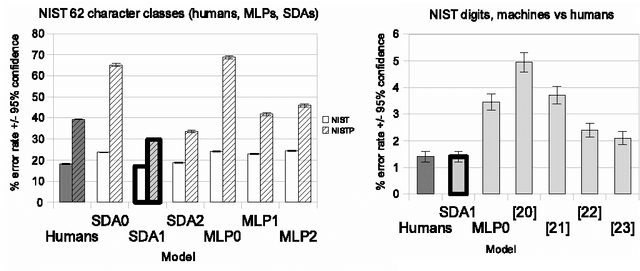
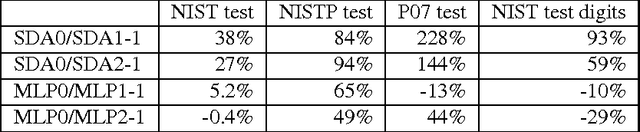
Recent theoretical and empirical work in statistical machine learning has demonstrated the importance of learning algorithms for deep architectures, i.e., function classes obtained by composing multiple non-linear transformations. Self-taught learning (exploiting unlabeled examples or examples from other distributions) has already been applied to deep learners, but mostly to show the advantage of unlabeled examples. Here we explore the advantage brought by {\em out-of-distribution examples}. For this purpose we developed a powerful generator of stochastic variations and noise processes for character images, including not only affine transformations but also slant, local elastic deformations, changes in thickness, background images, grey level changes, contrast, occlusion, and various types of noise. The out-of-distribution examples are obtained from these highly distorted images or by including examples of object classes different from those in the target test set. We show that {\em deep learners benefit more from out-of-distribution examples than a corresponding shallow learner}, at least in the area of handwritten character recognition. In fact, we show that they beat previously published results and reach human-level performance on both handwritten digit classification and 62-class handwritten character recognition.