 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Local Methods Solve Nonconvex Problems?
Mar 24, 2021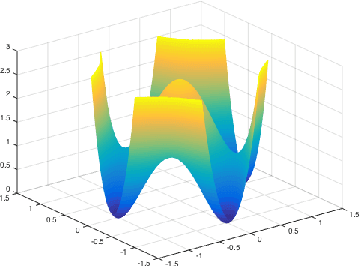
Non-convex optimization is ubiquitous in modern machine learning. Researchers devise non-convex objective functions and optimize them using off-the-shelf optimizers such as stochastic gradient descent and its variants, which leverage the local geometry and update iteratively. Even though solving non-convex functions is NP-hard in the worst case, the optimization quality in practice is often not an issue -- optimizers are largely believed to find approximate global minima. Researchers hypothesize a unified explanation for this intriguing phenomenon: most of the local minima of the practically-used objectives are approximately global minima. We rigorously formalize it for concrete instances of machine learning problems.
Fine-Grained Gap-Dependent Bounds for Tabular MDPs via Adaptive Multi-Step Bootstrap
Feb 09, 2021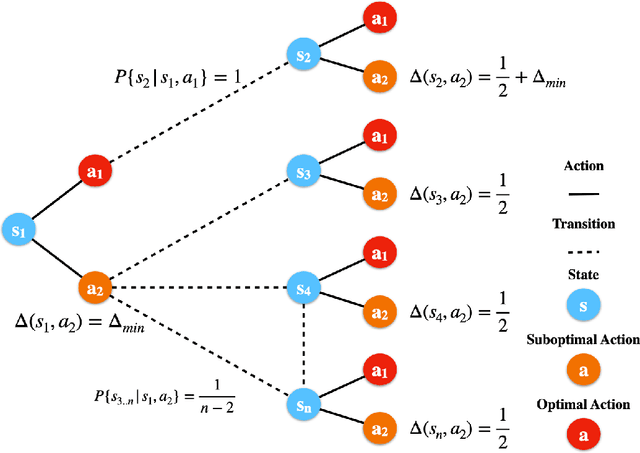
This paper presents a new model-free algorithm for episodic finite-horizon Markov Decision Processes (MDP), Adaptive Multi-step Bootstrap (AMB), which enjoys a stronger gap-dependent regret bound. The first innovation is to estimate the optimal $Q$-function by combining an optimistic bootstrap with an adaptive multi-step Monte Carlo rollout. The second innovation is to select the action with the largest confidence interval length among admissible actions that are not dominated by any other actions. We show when each state has a unique optimal action, AMB achieves a gap-dependent regret bound that only scales with the sum of the inverse of the sub-optimality gaps. In contrast, Simchowitz and Jamieson (2019) showed all upper-confidence-bound (UCB) algorithms suffer an additional $\Omega\left(\frac{S}{\Delta_{min}}\right)$ regret due to over-exploration where $\Delta_{min}$ is the minimum sub-optimality gap and $S$ is the number of states. We further show that for general MDPs, AMB suffers an additional $\frac{|Z_{mul}|}{\Delta_{min}}$ regret, where $Z_{mul}$ is the set of state-action pairs $(s,a)$'s satisfying $a$ is a non-unique optimal action for $s$. We complement our upper bound with a lower bound showing the dependency on $\frac{|Z_{mul}|}{\Delta_{min}}$ is unavoidable for any consistent algorithm. This lower bound also implies a separation between reinforcement learning and contextual bandits.
Provable Model-based Nonlinear Bandit and Reinforcement Learning: Shelve Optimism, Embrace Virtual Curvature
Feb 08, 2021
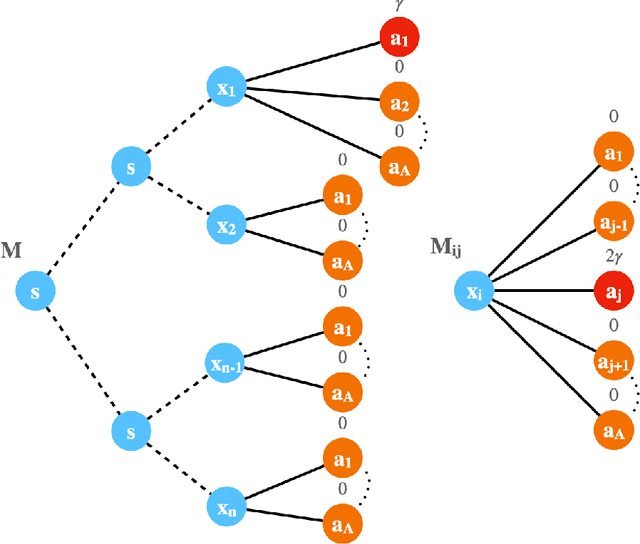
This paper studies model-based bandit and reinforcement learning (RL) with nonlinear function approximations. We propose to study convergence to approximate local maxima because we show that global convergence is statistically intractable even for one-layer neural net bandit with a deterministic reward. For both nonlinear bandit and RL, the paper presents a model-based algorithm, Virtual Ascent with Online Model Learner (ViOL), which provably converges to a local maximum with sample complexity that only depends on the sequential Rademacher complexity of the model class. Our results imply novel global or local regret bounds on several concrete settings such as linear bandit with finite or sparse model class, and two-layer neural net bandit. A key algorithmic insight is that optimism may lead to over-exploration even for two-layer neural net model class. On the other hand, for convergence to local maxima, it suffices to maximize the virtual return if the model can also reasonably predict the size of the gradient and Hessian of the real return.
In-N-Out: Pre-Training and Self-Training using Auxiliary Information for Out-of-Distribution Robustness
Dec 16, 2020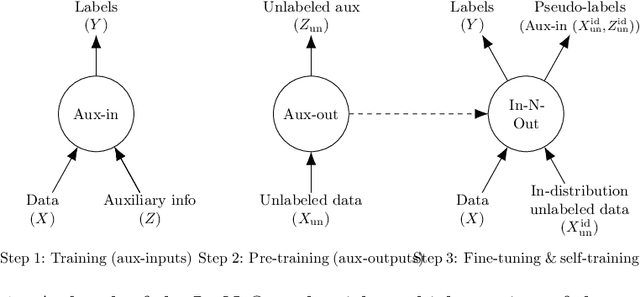
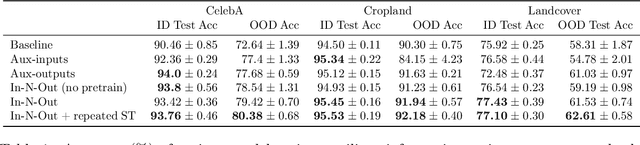

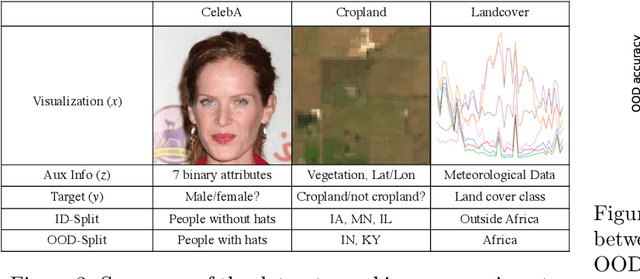
Consider a prediction setting where a few inputs (e.g., satellite images) are expensively annotated with the prediction targets (e.g., crop types), and many inputs are cheaply annotated with auxiliary information (e.g., climate information). How should we best leverage this auxiliary information for the prediction task? Empirically across three image and time-series datasets, and theoretically in a multi-task linear regression setting, we show that (i) using auxiliary information as input features improves in-distribution error but can hurt out-of-distribution (OOD) error; while (ii) using auxiliary information as outputs of auxiliary tasks to pre-train a model improves OOD error. To get the best of both worlds, we introduce In-N-Out, which first trains a model with auxiliary inputs and uses it to pseudolabel all the in-distribution inputs, then pre-trains a model on OOD auxiliary outputs and fine-tunes this model with the pseudolabels (self-training). We show both theoretically and empirically that In-N-Out outperforms auxiliary inputs or outputs alone on both in-distribution and OOD error.
Meta-learning Transferable Representations with a Single Target Domain
Nov 03, 2020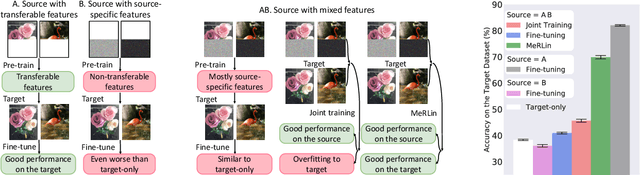
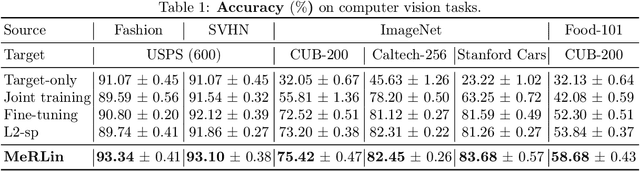


Recent works found that fine-tuning and joint training---two popular approaches for transfer learning---do not always improve accuracy on downstream tasks. First, we aim to understand more about when and why fine-tuning and joint training can be suboptimal or even harmful for transfer learning. We design semi-synthetic datasets where the source task can be solved by either source-specific features or transferable features. We observe that (1) pre-training may not have incentive to learn transferable features and (2) joint training may simultaneously learn source-specific features and overfit to the target. Second, to improve over fine-tuning and joint training, we propose Meta Representation Learning (MeRLin) to learn transferable features. MeRLin meta-learns representations by ensuring that a head fit on top of the representations with target training data also performs well on target validation data. We also prove that MeRLin recovers the target ground-truth model with a quadratic neural net parameterization and a source distribution that contains both transferable and source-specific features. On the same distribution, pre-training and joint training provably fail to learn transferable features. MeRLin empirically outperforms previous state-of-the-art transfer learning algorithms on various real-world vision and NLP transfer learning benchmarks.
Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling
Oct 23, 2020
Document-level relation extraction (RE) poses new challenges compared to its sentence-level RE counterpart. One document commonly contains multiple entity pairs, and one entity pair occurs multiple times in the document associated with multiple possible relations. In this paper, we propose two novel techniques, adaptive thresholding and localized context pooling, to solve the multilabel and multi-entity problems. The adaptive thresholding replaces the global threshold for multi-label classification in the prior work by a learnable entities-dependent threshold. The localized context pooling directly transfers attention from pre-trained language models to locate relevant context that is useful to decide the relation. We experiment on three document-level RE benchmark datasets: DocRED, a recently released large-scale RE dataset, and two datasets CDR and GDA in the biomedical domain. Our ATLOP (Adaptive Thresholding and Localized cOntext Pooling) model achieves an F1 score of 63.4; and also significantly outperforms existing models on both CDR and GDA.
Beyond Lazy Training for Over-parameterized Tensor Decomposition
Oct 22, 2020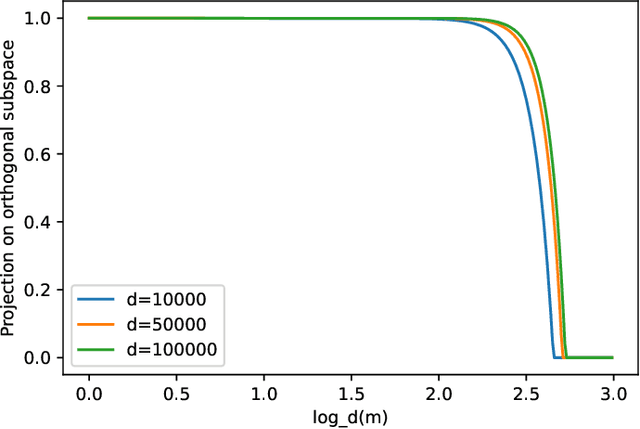
Over-parametrization is an important technique in training neural networks. In both theory and practice, training a larger network allows the optimization algorithm to avoid bad local optimal solutions. In this paper we study a closely related tensor decomposition problem: given an $l$-th order tensor in $(R^d)^{\otimes l}$ of rank $r$ (where $r\ll d$), can variants of gradient descent find a rank $m$ decomposition where $m > r$? We show that in a lazy training regime (similar to the NTK regime for neural networks) one needs at least $m = \Omega(d^{l-1})$, while a variant of gradient descent can find an approximate tensor when $m = O^*(r^{2.5l}\log d)$. Our results show that gradient descent on over-parametrized objective could go beyond the lazy training regime and utilize certain low-rank structure in the data.
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data
Oct 15, 2020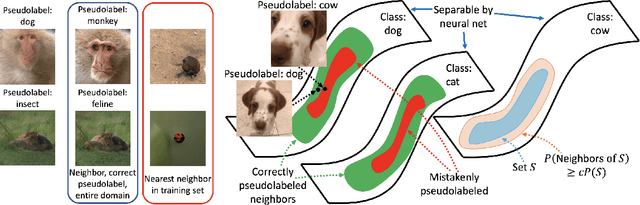

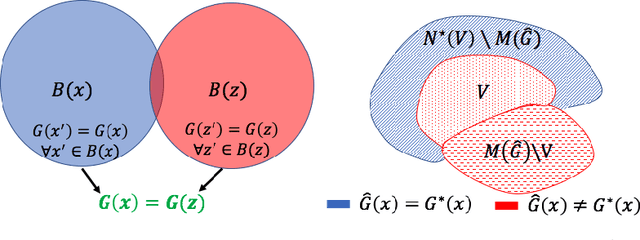

Self-training algorithms, which train a model to fit pseudolabels predicted by another previously-learned model, have been very successful for learning with unlabeled data using neural networks. However, the current theoretical understanding of self-training only applies to linear models. This work provides a unified theoretical analysis of self-training with deep networks for semi-supervised learning, unsupervised domain adaptation, and unsupervised learning. At the core of our analysis is a simple but realistic "expansion" assumption, which states that a low-probability subset of the data must expand to a neighborhood with large probability relative to the subset. We also assume that neighborhoods of examples in different classes have minimal overlap. We prove that under these assumptions, the minimizers of population objectives based on self-training and input-consistency regularization will achieve high accuracy with respect to ground-truth labels. By using off-the-shelf generalization bounds, we immediately convert this result to sample complexity guarantees for neural nets that are polynomial in the margin and Lipschitzness. Our results help explain the empirical successes of recently proposed self-training algorithms which use input consistency regularization.
Entity and Evidence Guided Relation Extraction for DocRED
Aug 27, 2020

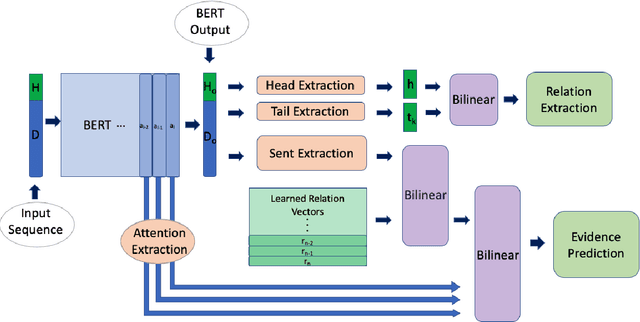
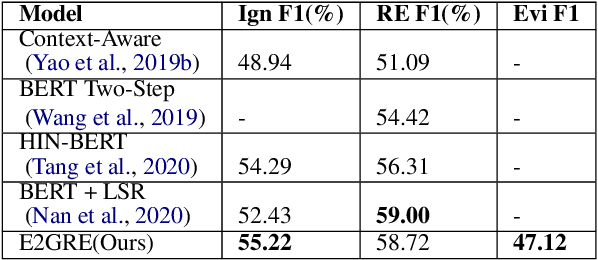
Document-level relation extraction is a challenging task which requires reasoning over multiple sentences in order to predict relations in a document. In this paper, we pro-pose a joint training frameworkE2GRE(Entity and Evidence Guided Relation Extraction)for this task. First, we introduce entity-guided sequences as inputs to a pre-trained language model (e.g. BERT, RoBERTa). These entity-guided sequences help a pre-trained language model (LM) to focus on areas of the document related to the entity. Secondly, we guide the fine-tuning of the pre-trained language model by using its internal attention probabilities as additional features for evidence prediction.Our new approach encourages the pre-trained language model to focus on the entities and supporting/evidence sentences. We evaluate our E2GRE approach on DocRED, a recently released large-scale dataset for relation extraction. Our approach is able to achieve state-of-the-art results on the public leaderboard across all metrics, showing that our E2GRE is both effective and synergistic on relation extraction and evidence prediction.
Learning Over-Parametrized Two-Layer ReLU Neural Networks beyond NTK
Jul 09, 2020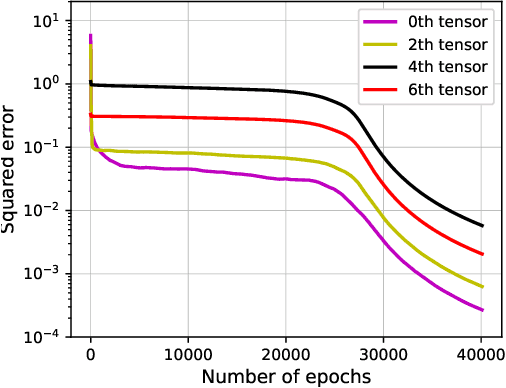
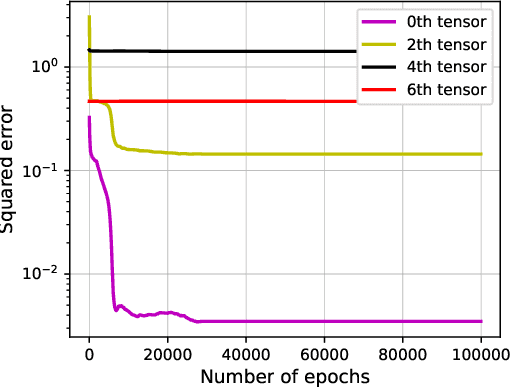
We consider the dynamic of gradient descent for learning a two-layer neural network. We assume the input $x\in\mathbb{R}^d$ is drawn from a Gaussian distribution and the label of $x$ satisfies $f^{\star}(x) = a^{\top}|W^{\star}x|$, where $a\in\mathbb{R}^d$ is a nonnegative vector and $W^{\star} \in\mathbb{R}^{d\times d}$ is an orthonormal matrix. We show that an over-parametrized two-layer neural network with ReLU activation, trained by gradient descent from random initialization, can provably learn the ground truth network with population loss at most $o(1/d)$ in polynomial time with polynomial samples. On the other hand, we prove that any kernel method, including Neural Tangent Kernel, with a polynomial number of samples in $d$, has population loss at least $\Omega(1 / d)$.