 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolynomial-time Tensor Decompositions with Sum-of-Squares
Oct 06, 2016We give new algorithms based on the sum-of-squares method for tensor decomposition. Our results improve the best known running times from quasi-polynomial to polynomial for several problems, including decomposing random overcomplete 3-tensors and learning overcomplete dictionaries with constant relative sparsity. We also give the first robust analysis for decomposing overcomplete 4-tensors in the smoothed analysis model. A key ingredient of our analysis is to establish small spectral gaps in moment matrices derived from solutions to sum-of-squares relaxations. To enable this analysis we augment sum-of-squares relaxations with spectral analogs of maximum entropy constraints.
Gradient Descent Learns Linear Dynamical Systems
Sep 16, 2016
We prove that gradient descent efficiently converges to the global optimizer of the maximum likelihood objective of an unknown linear time-invariant dynamical system from a sequence of noisy observations generated by the system. Even though the objective function is non-convex, we provide polynomial running time and sample complexity bounds under strong but natural assumptions. Linear systems identification has been studied for many decades, yet, to the best of our knowledge, these are the first polynomial guarantees for the problem we consider.
RAND-WALK: A Latent Variable Model Approach to Word Embeddings
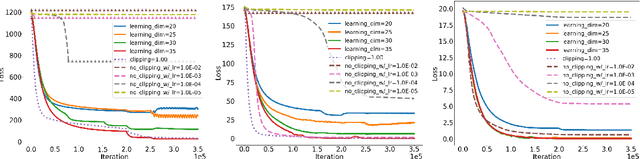
Jul 22, 2016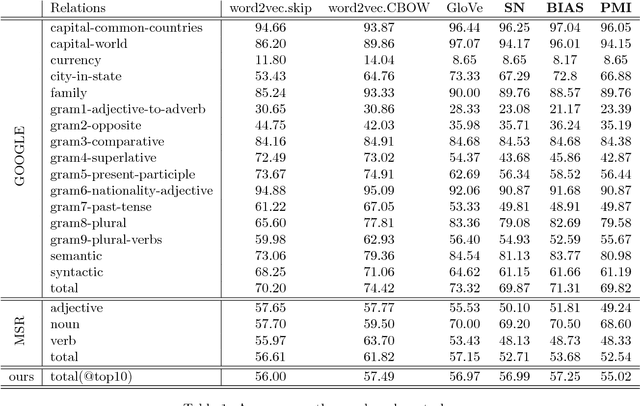
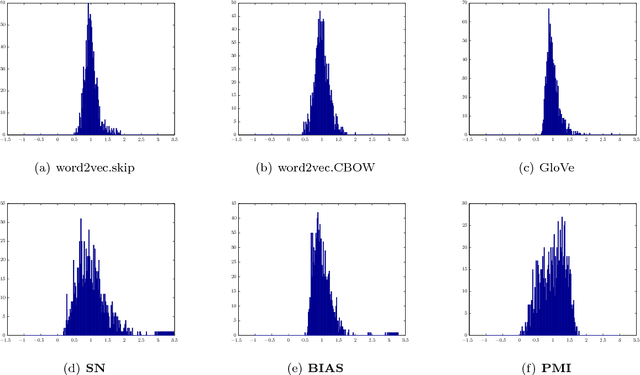
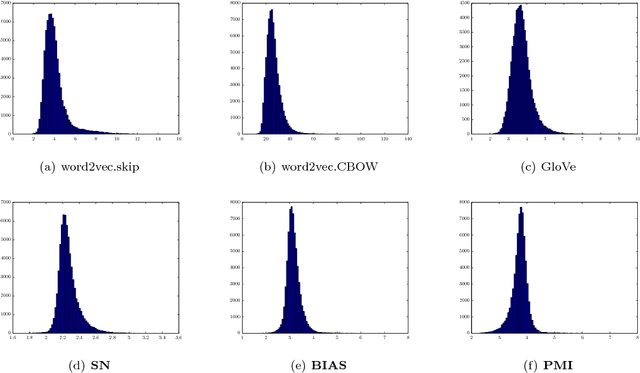
Semantic word embeddings represent the meaning of a word via a vector, and are created by diverse methods. Many use nonlinear operations on co-occurrence statistics, and have hand-tuned hyperparameters and reweighting methods. This paper proposes a new generative model, a dynamic version of the log-linear topic model of~\citet{mnih2007three}. The methodological novelty is to use the prior to compute closed form expressions for word statistics. This provides a theoretical justification for nonlinear models like PMI, word2vec, and GloVe, as well as some hyperparameter choices. It also helps explain why low-dimensional semantic embeddings contain linear algebraic structure that allows solution of word analogies, as shown by~\citet{mikolov2013efficient} and many subsequent papers. Experimental support is provided for the generative model assumptions, the most important of which is that latent word vectors are fairly uniformly dispersed in space.
Provable Algorithms for Inference in Topic Models
May 27, 2016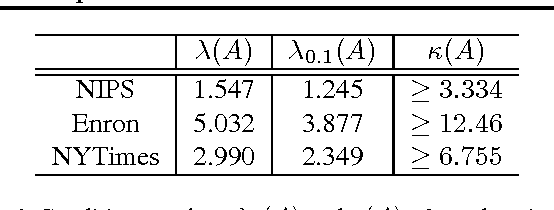
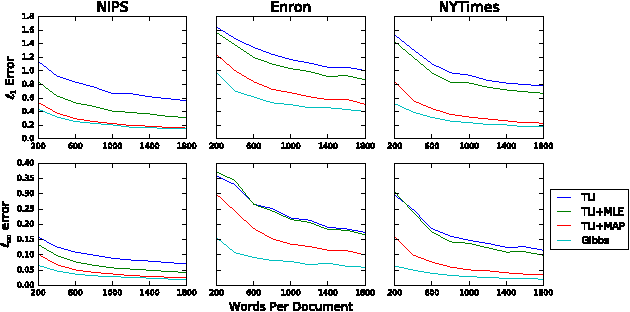
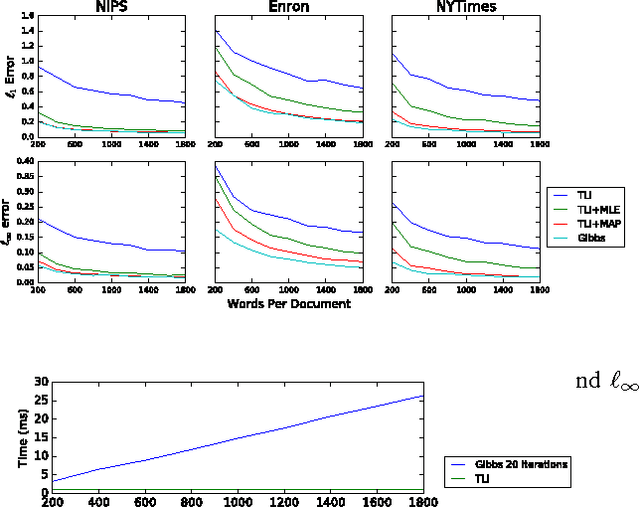
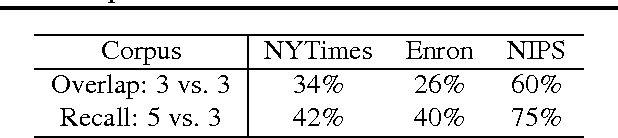
Recently, there has been considerable progress on designing algorithms with provable guarantees -- typically using linear algebraic methods -- for parameter learning in latent variable models. But designing provable algorithms for inference has proven to be more challenging. Here we take a first step towards provable inference in topic models. We leverage a property of topic models that enables us to construct simple linear estimators for the unknown topic proportions that have small variance, and consequently can work with short documents. Our estimators also correspond to finding an estimate around which the posterior is well-concentrated. We show lower bounds that for shorter documents it can be information theoretically impossible to find the hidden topics. Finally, we give empirical results that demonstrate that our algorithm works on realistic topic models. It yields good solutions on synthetic data and runs in time comparable to a {\em single} iteration of Gibbs sampling.
Communication Lower Bounds for Statistical Estimation Problems via a Distributed Data Processing Inequality
May 10, 2016We study the tradeoff between the statistical error and communication cost of distributed statistical estimation problems in high dimensions. In the distributed sparse Gaussian mean estimation problem, each of the $m$ machines receives $n$ data points from a $d$-dimensional Gaussian distribution with unknown mean $\theta$ which is promised to be $k$-sparse. The machines communicate by message passing and aim to estimate the mean $\theta$. We provide a tight (up to logarithmic factors) tradeoff between the estimation error and the number of bits communicated between the machines. This directly leads to a lower bound for the distributed \textit{sparse linear regression} problem: to achieve the statistical minimax error, the total communication is at least $\Omega(\min\{n,d\}m)$, where $n$ is the number of observations that each machine receives and $d$ is the ambient dimension. These lower results improve upon [Sha14,SD'14] by allowing multi-round iterative communication model. We also give the first optimal simultaneous protocol in the dense case for mean estimation. As our main technique, we prove a \textit{distributed data processing inequality}, as a generalization of usual data processing inequalities, which might be of independent interest and useful for other problems.
Distributed Stochastic Variance Reduced Gradient Methods and A Lower Bound for Communication Complexity
Jan 06, 2016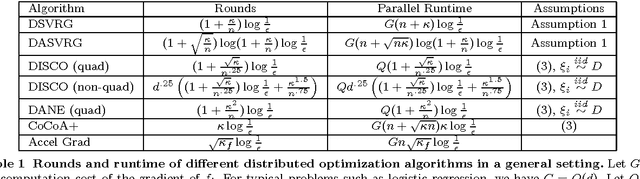
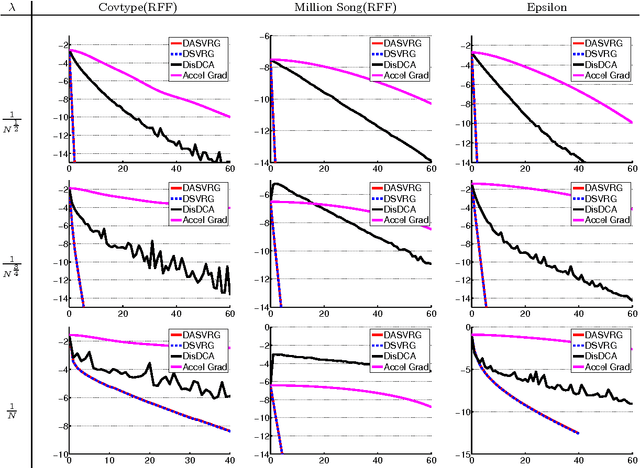
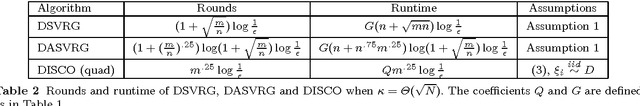
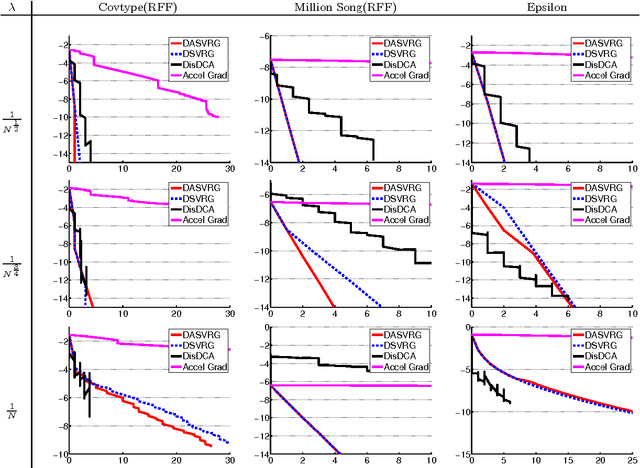
We study distributed optimization algorithms for minimizing the average of convex functions. The applications include empirical risk minimization problems in statistical machine learning where the datasets are large and have to be stored on different machines. We design a distributed stochastic variance reduced gradient algorithm that, under certain conditions on the condition number, simultaneously achieves the optimal parallel runtime, amount of communication and rounds of communication among all distributed first-order methods up to constant factors. Our method and its accelerated extension also outperform existing distributed algorithms in terms of the rounds of communication as long as the condition number is not too large compared to the size of data in each machine. We also prove a lower bound for the number of rounds of communication for a broad class of distributed first-order methods including the proposed algorithms in this paper. We show that our accelerated distributed stochastic variance reduced gradient algorithm achieves this lower bound so that it uses the fewest rounds of communication among all distributed first-order algorithms.
Why are deep nets reversible: A simple theory, with implications for training
Nov 19, 2015



Generative models for deep learning are promising both to improve understanding of the model, and yield training methods requiring fewer labeled samples. Recent works use generative model approaches to produce the deep net's input given the value of a hidden layer several levels above. However, there is no accompanying "proof of correctness" for the generative model, showing that the feedforward deep net is the correct inference method for recovering the hidden layer given the input. Furthermore, these models are complicated. The current paper takes a more theoretical tack. It presents a very simple generative model for RELU deep nets, with the following characteristics: (i) The generative model is just the reverse of the feedforward net: if the forward transformation at a layer is $A$ then the reverse transformation is $A^T$. (This can be seen as an explanation of the old weight tying idea for denoising autoencoders.) (ii) Its correctness can be proven under a clean theoretical assumption: the edge weights in real-life deep nets behave like random numbers. Under this assumption ---which is experimentally tested on real-life nets like AlexNet--- it is formally proved that feed forward net is a correct inference method for recovering the hidden layer. The generative model suggests a simple modification for training: use the generative model to produce synthetic data with labels and include it in the training set. Experiments are shown to support this theory of random-like deep nets; and that it helps the training.
Sum-of-Squares Lower Bounds for Sparse PCA
Oct 18, 2015This paper establishes a statistical versus computational trade-off for solving a basic high-dimensional machine learning problem via a basic convex relaxation method. Specifically, we consider the {\em Sparse Principal Component Analysis} (Sparse PCA) problem, and the family of {\em Sum-of-Squares} (SoS, aka Lasserre/Parillo) convex relaxations. It was well known that in large dimension $p$, a planted $k$-sparse unit vector can be {\em in principle} detected using only $n \approx k\log p$ (Gaussian or Bernoulli) samples, but all {\em efficient} (polynomial time) algorithms known require $n \approx k^2$ samples. It was also known that this quadratic gap cannot be improved by the the most basic {\em semi-definite} (SDP, aka spectral) relaxation, equivalent to a degree-2 SoS algorithms. Here we prove that also degree-4 SoS algorithms cannot improve this quadratic gap. This average-case lower bound adds to the small collection of hardness results in machine learning for this powerful family of convex relaxation algorithms. Moreover, our design of moments (or "pseudo-expectations") for this lower bound is quite different than previous lower bounds. Establishing lower bounds for higher degree SoS algorithms for remains a challenging problem.
Decomposing Overcomplete 3rd Order Tensors using Sum-of-Squares Algorithms
Apr 21, 2015Tensor rank and low-rank tensor decompositions have many applications in learning and complexity theory. Most known algorithms use unfoldings of tensors and can only handle rank up to $n^{\lfloor p/2 \rfloor}$ for a $p$-th order tensor in $\mathbb{R}^{n^p}$. Previously no efficient algorithm can decompose 3rd order tensors when the rank is super-linear in the dimension. Using ideas from sum-of-squares hierarchy, we give the first quasi-polynomial time algorithm that can decompose a random 3rd order tensor decomposition when the rank is as large as $n^{3/2}/\textrm{polylog} n$. We also give a polynomial time algorithm for certifying the injective norm of random low rank tensors. Our tensor decomposition algorithm exploits the relationship between injective norm and the tensor components. The proof relies on interesting tools for decoupling random variables to prove better matrix concentration bounds, which can be useful in other settings.
Simple, Efficient, and Neural Algorithms for Sparse Coding
Mar 02, 2015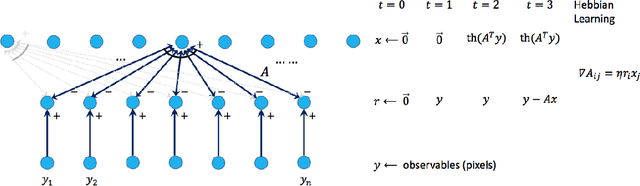
Sparse coding is a basic task in many fields including signal processing, neuroscience and machine learning where the goal is to learn a basis that enables a sparse representation of a given set of data, if one exists. Its standard formulation is as a non-convex optimization problem which is solved in practice by heuristics based on alternating minimization. Re- cent work has resulted in several algorithms for sparse coding with provable guarantees, but somewhat surprisingly these are outperformed by the simple alternating minimization heuristics. Here we give a general framework for understanding alternating minimization which we leverage to analyze existing heuristics and to design new ones also with provable guarantees. Some of these algorithms seem implementable on simple neural architectures, which was the original motivation of Olshausen and Field (1997a) in introducing sparse coding. We also give the first efficient algorithm for sparse coding that works almost up to the information theoretic limit for sparse recovery on incoherent dictionaries. All previous algorithms that approached or surpassed this limit run in time exponential in some natural parameter. Finally, our algorithms improve upon the sample complexity of existing approaches. We believe that our analysis framework will have applications in other settings where simple iterative algorithms are used.