 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Domain Generalized Stereo Matching Networks from a Feature Consistency Perspective
Mar 21, 2022
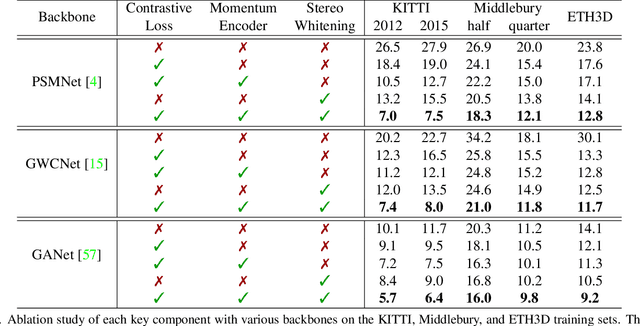
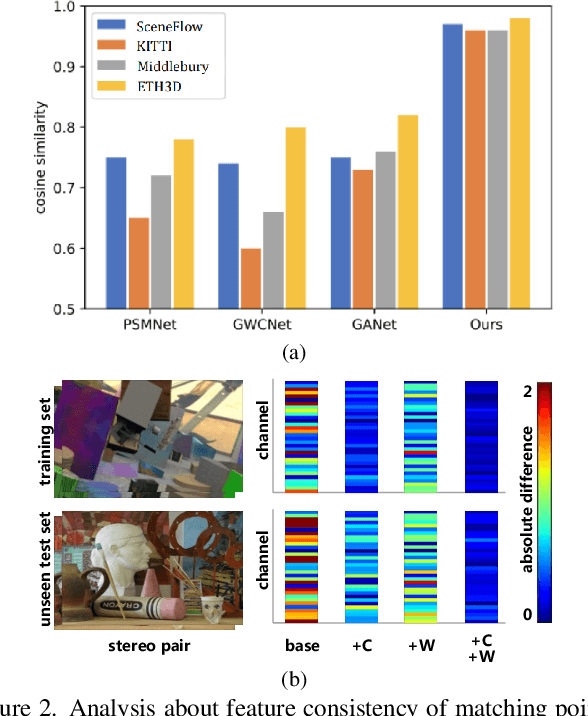

Despite recent stereo matching networks achieving impressive performance given sufficient training data, they suffer from domain shifts and generalize poorly to unseen domains. We argue that maintaining feature consistency between matching pixels is a vital factor for promoting the generalization capability of stereo matching networks, which has not been adequately considered. Here we address this issue by proposing a simple pixel-wise contrastive learning across the viewpoints. The stereo contrastive feature loss function explicitly constrains the consistency between learned features of matching pixel pairs which are observations of the same 3D points. A stereo selective whitening loss is further introduced to better preserve the stereo feature consistency across domains, which decorrelates stereo features from stereo viewpoint-specific style information. Counter-intuitively, the generalization of feature consistency between two viewpoints in the same scene translates to the generalization of stereo matching performance to unseen domains. Our method is generic in nature as it can be easily embedded into existing stereo networks and does not require access to the samples in the target domain. When trained on synthetic data and generalized to four real-world testing sets, our method achieves superior performance over several state-of-the-art networks.
Enhancement of Novel View Synthesis Using Omnidirectional Image Completion
Mar 18, 2022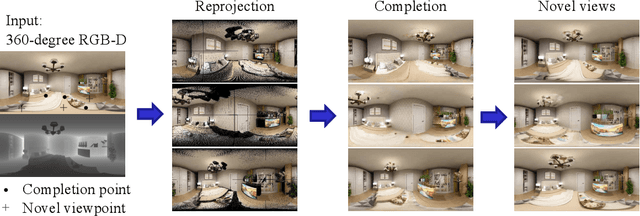
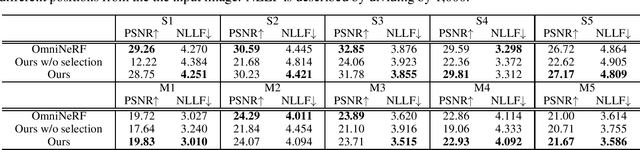
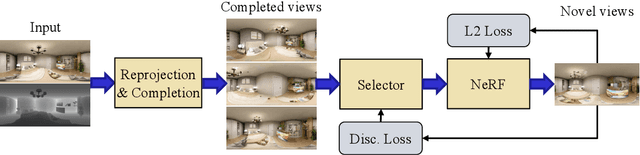
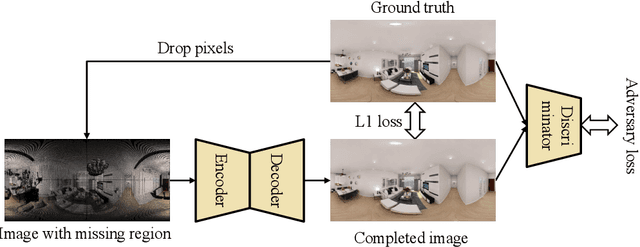
We present a method for synthesizing novel views from a single 360-degree image based on the neural radiance field (NeRF) . Prior studies rely on the neighborhood interpolation capability of multi-layer perceptrons to complete missing regions caused by occlusion and zooming, and this leads to artifacts. In the proposed method, the input image is reprojected to 360-degree images at other camera positions, the missing regions of the reprojected images are completed by a self-supervised trained generative model, and the completed images are utilized to train the NeRF. Because multiple completed images contain inconsistencies in 3D, we introduce a method to train NeRF while dynamically selecting a sparse set of completed images, to reduce the discrimination error of the synthesized views with real images. Experiments indicate that the proposed method can synthesize plausible novel views while preserving the features of the scene for both artificial and real-world data.
K-VQG: Knowledge-aware Visual Question Generation for Common-sense Acquisition
Mar 15, 2022
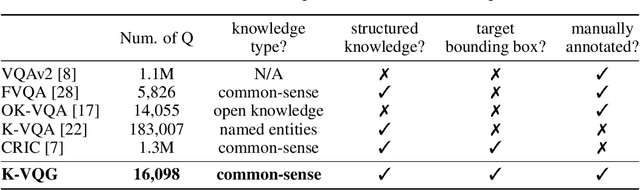

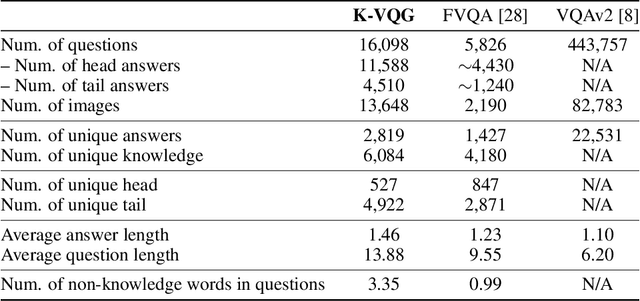
Visual Question Generation (VQG) is a task to generate questions from images. When humans ask questions about an image, their goal is often to acquire some new knowledge. However, existing studies on VQG have mainly addressed question generation from answers or question categories, overlooking the objectives of knowledge acquisition. To introduce a knowledge acquisition perspective into VQG, we constructed a novel knowledge-aware VQG dataset called K-VQG. This is the first large, humanly annotated dataset in which questions regarding images are tied to structured knowledge. We also developed a new VQG model that can encode and use knowledge as the target for a question. The experiment results show that our model outperforms existing models on the K-VQG dataset.
COMPASS: a Creative Support System that Alerts Novelists to the Unnoticed Missing Contents
Feb 26, 2022


When humans write, they may unintentionally omit some information. Complementing the omitted information using a computer is helpful in providing writing support. Recently, in the field of story understanding and generation, story completion (SC) was proposed to generate the missing parts of an incomplete story. Although its applicability is limited because it requires that the user have prior knowledge of the missing part of a story, missing position prediction (MPP) can be used to compensate for this problem. MPP aims to predict the position of the missing part, but the prerequisite knowledge that "one sentence is missing" is still required. In this study, we propose Variable Number MPP (VN-MPP), a new MPP task that removes this restriction; that is, the task to predict multiple missing sentences or to judge whether there are no missing sentences in the first place. We also propose two methods for this new MPP task. Furthermore, based on the novel task and methods, we developed a creative writing support system, COMPASS. The results of a user experiment involving professional creators who write texts in Japanese confirm the efficacy and utility of the developed system.
ViNTER: Image Narrative Generation with Emotion-Arc-Aware Transformer
Feb 15, 2022
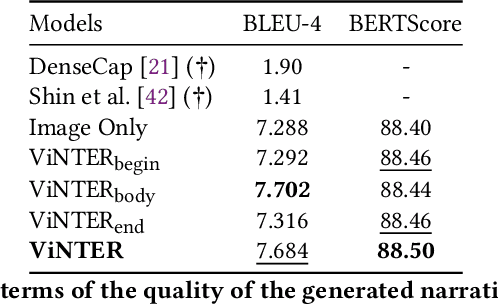
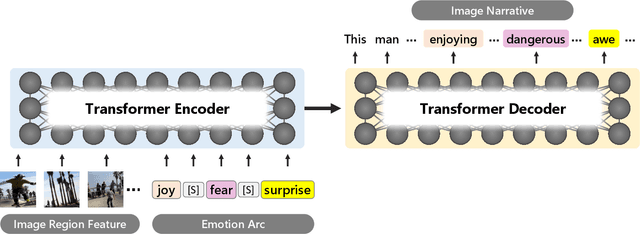
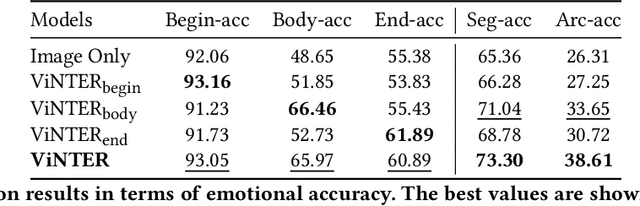
Image narrative generation describes the creation of stories regarding the content of image data from a subjective viewpoint. Given the importance of the subjective feelings of writers, characters, and readers in storytelling, image narrative generation methods must consider human emotion, which is their major difference from descriptive caption generation tasks. The development of automated methods to generate story-like text associated with images may be considered to be of considerable social significance, because stories serve essential functions both as entertainment and also for many practical purposes such as education and advertising. In this study, we propose a model called ViNTER (Visual Narrative Transformer with Emotion arc Representation) to generate image narratives that focus on time series representing varying emotions as "emotion arcs," to take advantage of recent advances in multimodal Transformer-based pre-trained models. We present experimental results of both manual and automatic evaluations, which demonstrate the effectiveness of the proposed emotion-aware approach to image narrative generation.
Plaque segmentation via masking of the artery wall
Jan 26, 2022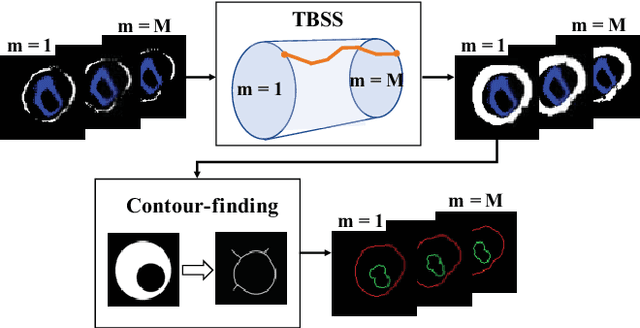
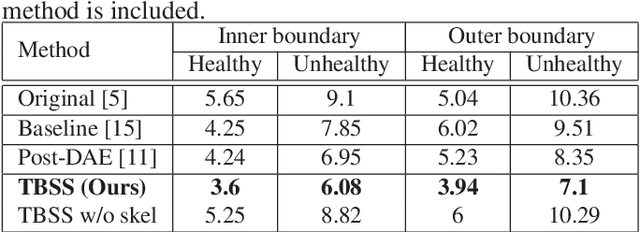

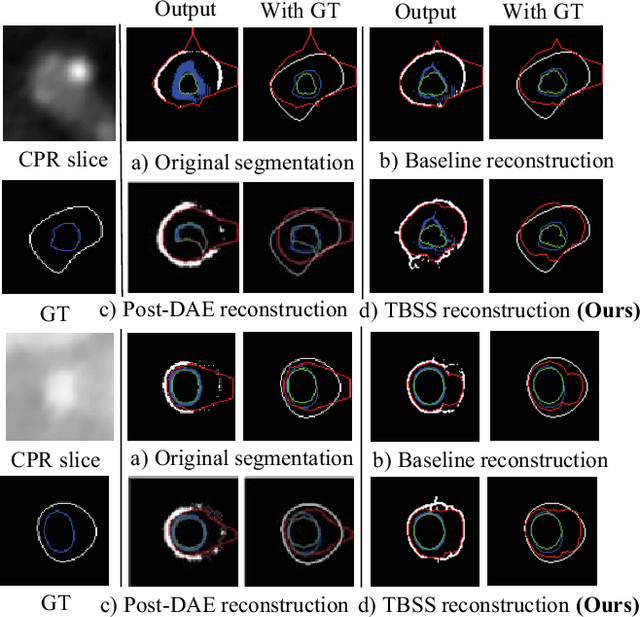
The presence of plaques in the coronary arteries are a major risk to the patients' life. In particular, non-calcified plaques pose a great challenge, as they are harder to detect and more likely to rupture than calcified plaques. While current deep learning techniques allow precise segmentation of regular images, the performance in medical images is still low, caused mostly by blurriness and ambiguous voxel intensities of unrelated parts that fall on the same range. In this paper, we propose a novel methodology for segmenting calcified and non-calcified plaques in CCTA-CPR scans of coronary arteries. The input slices are masked so only the voxels within the wall vessel are considered for segmentation. We also provide an exhaustive evaluation by applying different types of masks, in order to validate the potential of vessel masking for plaque segmentation. Our methodology results in a prominent boost in segmentation performance, in both quantitative and qualitative evaluation, achieving accurate plaque shapes even for the challenging non-calcified plaques. We believe our findings can lead the future research for high-performance plaque segmentation.
RestoreDet: Degradation Equivariant Representation for Object Detection in Low Resolution Images
Jan 07, 2022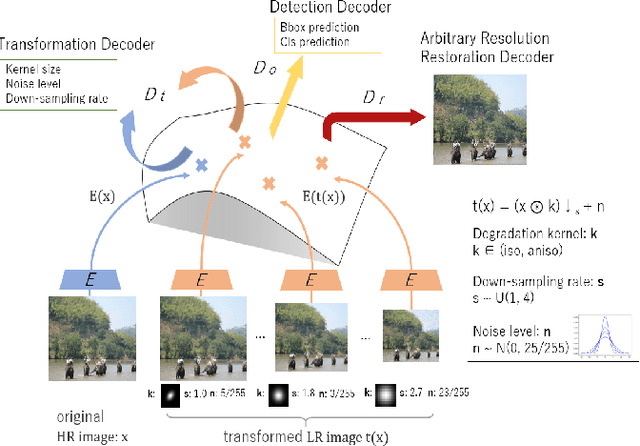
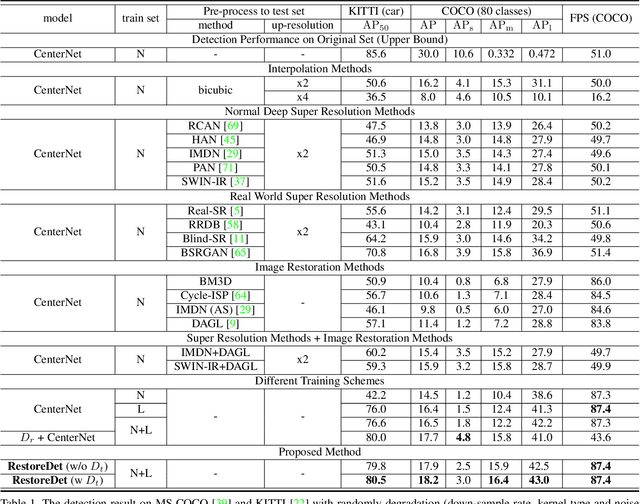
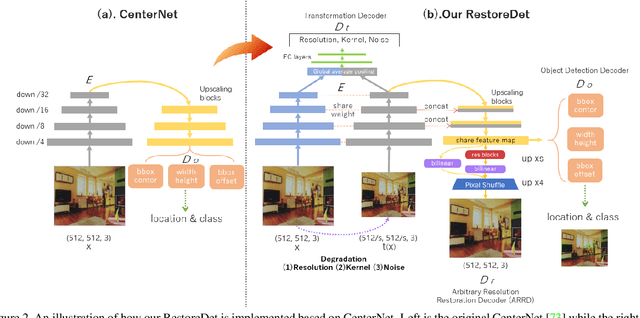
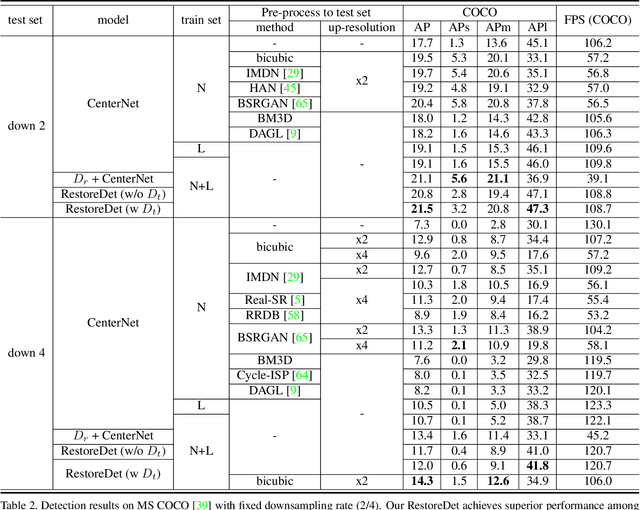
Image restoration algorithms such as super resolution (SR) are indispensable pre-processing modules for object detection in degraded images. However, most of these algorithms assume the degradation is fixed and known a priori. When the real degradation is unknown or differs from assumption, both the pre-processing module and the consequent high-level task such as object detection would fail. Here, we propose a novel framework, RestoreDet, to detect objects in degraded low resolution images. RestoreDet utilizes the downsampling degradation as a kind of transformation for self-supervised signals to explore the equivariant representation against various resolutions and other degradation conditions. Specifically, we learn this intrinsic visual structure by encoding and decoding the degradation transformation from a pair of original and randomly degraded images. The framework could further take the advantage of advanced SR architectures with an arbitrary resolution restoring decoder to reconstruct the original correspondence from the degraded input image. Both the representation learning and object detection are optimized jointly in an end-to-end training fashion. RestoreDet is a generic framework that could be implemented on any mainstream object detection architectures. The extensive experiment shows that our framework based on CenterNet has achieved superior performance compared with existing methods when facing variant degradation situations. Our code would be released soon.
Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects
Dec 21, 2021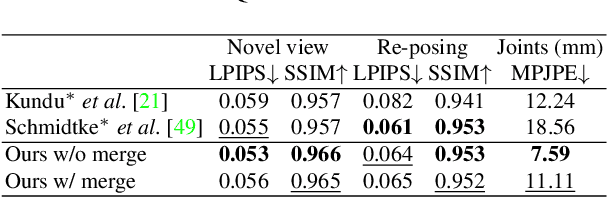
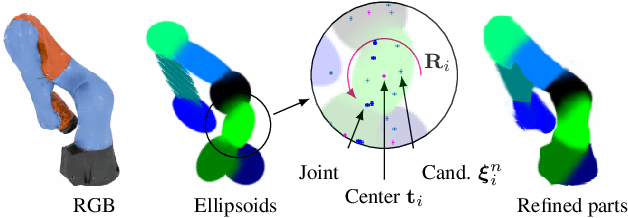
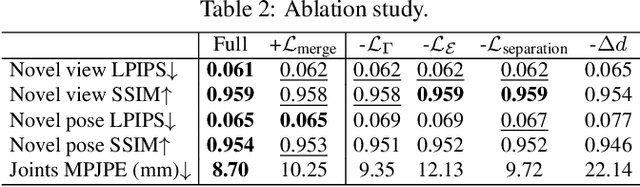
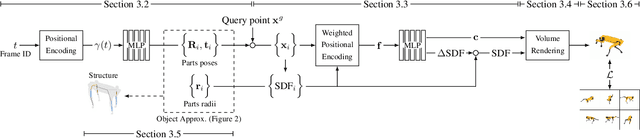
Rendering articulated objects while controlling their poses is critical to applications such as virtual reality or animation for movies. Manipulating the pose of an object, however, requires the understanding of its underlying structure, that is, its joints and how they interact with each other. Unfortunately, assuming the structure to be known, as existing methods do, precludes the ability to work on new object categories. We propose to learn both the appearance and the structure of previously unseen articulated objects by observing them move from multiple views, with no additional supervision, such as joints annotations, or information about the structure. Our insight is that adjacent parts that move relative to each other must be connected by a joint. To leverage this observation, we model the object parts in 3D as ellipsoids, which allows us to identify joints. We combine this explicit representation with an implicit one that compensates for the approximation introduced. We show that our method works for different structures, from quadrupeds, to single-arm robots, to humans.
Leveraging Human Selective Attention for Medical Image Analysis with Limited Training Data
Dec 02, 2021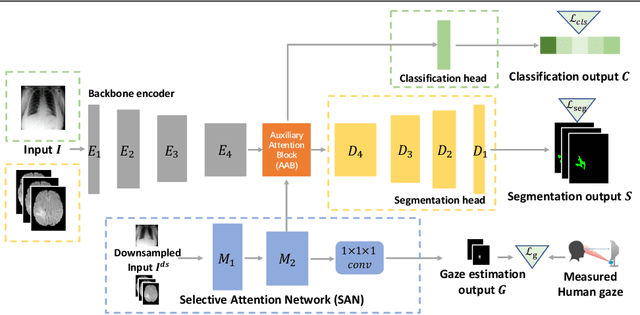
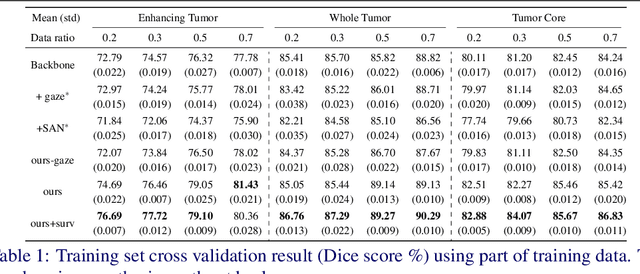

The human gaze is a cost-efficient physiological data that reveals human underlying attentional patterns. The selective attention mechanism helps the cognition system focus on task-relevant visual clues by ignoring the presence of distractors. Thanks to this ability, human beings can efficiently learn from a very limited number of training samples. Inspired by this mechanism, we aim to leverage gaze for medical image analysis tasks with small training data. Our proposed framework includes a backbone encoder and a Selective Attention Network (SAN) that simulates the underlying attention. The SAN implicitly encodes information such as suspicious regions that is relevant to the medical diagnose tasks by estimating the actual human gaze. Then we design a novel Auxiliary Attention Block (AAB) to allow information from SAN to be utilized by the backbone encoder to focus on selective areas. Specifically, this block uses a modified version of a multi-head attention layer to simulate the human visual search procedure. Note that the SAN and AAB can be plugged into different backbones, and the framework can be used for multiple medical image analysis tasks when equipped with task-specific heads. Our method is demonstrated to achieve superior performance on both 3D tumor segmentation and 2D chest X-ray classification tasks. We also show that the estimated gaze probability map of the SAN is consistent with an actual gaze fixation map obtained by board-certified doctors.
Lepard: Learning partial point cloud matching in rigid and deformable scenes
Nov 24, 2021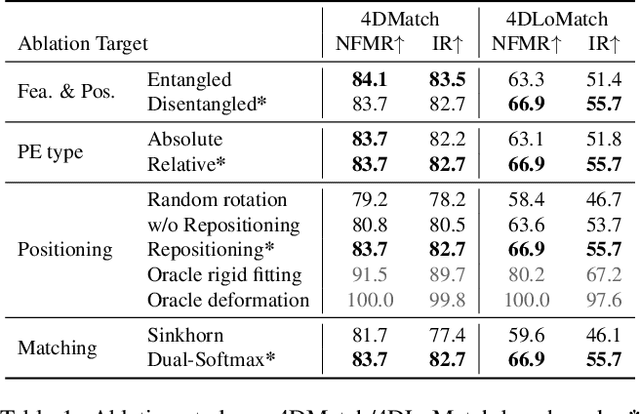
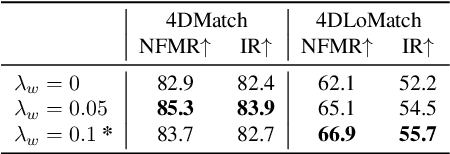
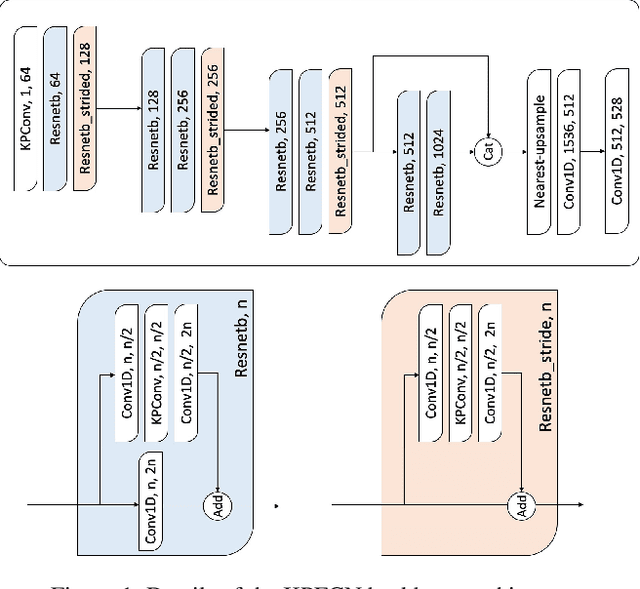
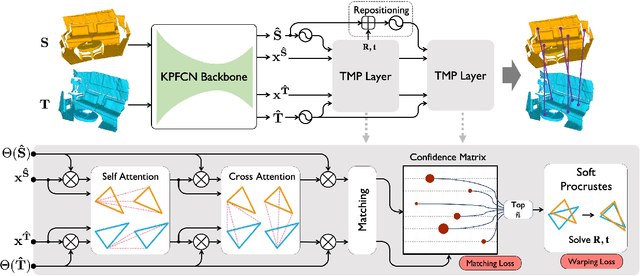
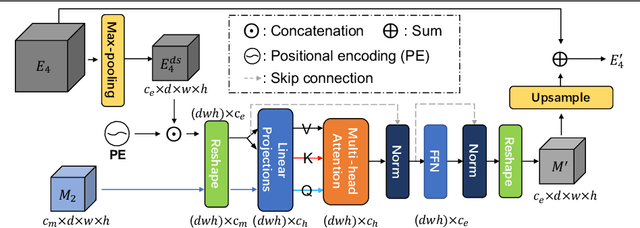
We present Lepard, a Learning based approach for partial point cloud matching for rigid and deformable scenes. The key characteristic of Lepard is the following approaches that exploit 3D positional knowledge for point cloud matching: 1) An architecture that disentangles point cloud representation into feature space and 3D position space. 2) A position encoding method that explicitly reveals 3D relative distance information through the dot product of vectors. 3) A repositioning technique that modifies the cross-point-cloud relative positions. Ablation studies demonstrate the effectiveness of the above techniques. For rigid point cloud matching, Lepard sets a new state-of-the-art on the 3DMatch / 3DLoMatch benchmarks with 93.6% / 69.0% registration recall. In deformable cases, Lepard achieves +27.1% / +34.8% higher non-rigid feature matching recall than the prior art on our newly constructed 4DMatch / 4DLoMatch benchmark.