 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLepard: Learning partial point cloud matching in rigid and deformable scenes
Paper and Code
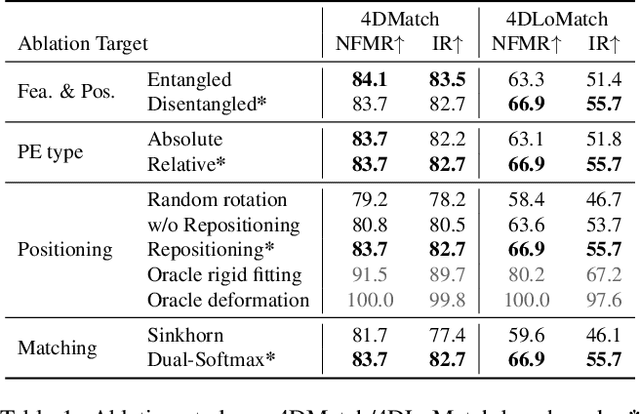
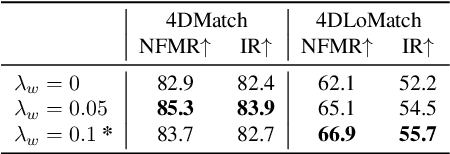
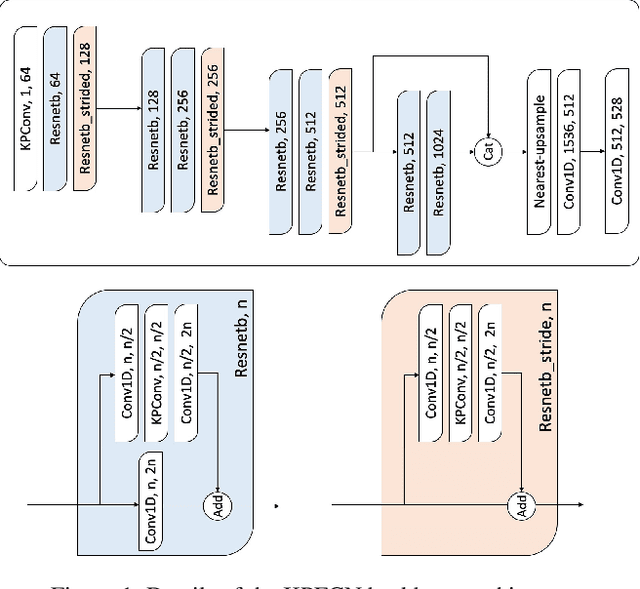
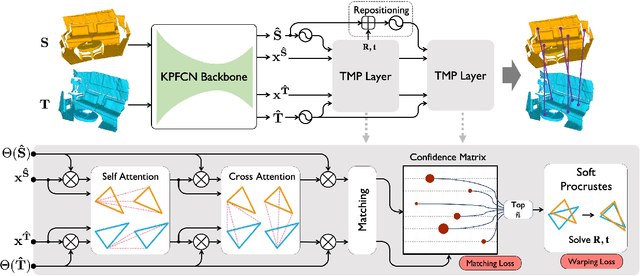
We present Lepard, a Learning based approach for partial point cloud matching for rigid and deformable scenes. The key characteristic of Lepard is the following approaches that exploit 3D positional knowledge for point cloud matching: 1) An architecture that disentangles point cloud representation into feature space and 3D position space. 2) A position encoding method that explicitly reveals 3D relative distance information through the dot product of vectors. 3) A repositioning technique that modifies the cross-point-cloud relative positions. Ablation studies demonstrate the effectiveness of the above techniques. For rigid point cloud matching, Lepard sets a new state-of-the-art on the 3DMatch / 3DLoMatch benchmarks with 93.6% / 69.0% registration recall. In deformable cases, Lepard achieves +27.1% / +34.8% higher non-rigid feature matching recall than the prior art on our newly constructed 4DMatch / 4DLoMatch benchmark.