 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll in One: A Unified Synthetic Data Pipeline for Multimodal Video Understanding
Apr 14, 2026Training multimodal large language models (MLLMs) for video understanding requires large-scale annotated data spanning diverse tasks such as object counting, question answering, and segmentation. However, collecting and annotating multimodal video data in real-world is costly, slow, and inherently limited in diversity and coverage. To address this challenge, we propose a unified synthetic data generation pipeline capable of automatically producing unlimited multimodal video data with rich and diverse supervision. Our framework supports multiple task formats within a single pipeline, enabling scalable and consistent data creation across tasks. To further enhance reasoning ability, we introduce a VQA-based fine-tuning strategy that trains models to answer structured questions about visual content rather than relying solely on captions or simple instructions. This formulation encourages deeper visual grounding and reasoning. We evaluate our approach in three challenging tasks: video object counting, video-based visual question answering, and video object segmentation. Experimental results demonstrate that models trained predominantly on synthetic data generalize effectively to real-world datasets, often outperforming traditionally trained counterparts. Our findings highlight the potential of unified synthetic data pipelines as a scalable alternative to expensive real-world annotation for multimodal video understanding.
HiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
MMFactory: A Universal Solution Search Engine for Vision-Language Tasks
Dec 24, 2024With advances in foundational and vision-language models, and effective fine-tuning techniques, a large number of both general and special-purpose models have been developed for a variety of visual tasks. Despite the flexibility and accessibility of these models, no single model is able to handle all tasks and/or applications that may be envisioned by potential users. Recent approaches, such as visual programming and multimodal LLMs with integrated tools aim to tackle complex visual tasks, by way of program synthesis. However, such approaches overlook user constraints (e.g., performance / computational needs), produce test-time sample-specific solutions that are difficult to deploy, and, sometimes, require low-level instructions that maybe beyond the abilities of a naive user. To address these limitations, we introduce MMFactory, a universal framework that includes model and metrics routing components, acting like a solution search engine across various available models. Based on a task description and few sample input-output pairs and (optionally) resource and/or performance constraints, MMFactory can suggest a diverse pool of programmatic solutions by instantiating and combining visio-lingual tools from its model repository. In addition to synthesizing these solutions, MMFactory also proposes metrics and benchmarks performance / resource characteristics, allowing users to pick a solution that meets their unique design constraints. From the technical perspective, we also introduced a committee-based solution proposer that leverages multi-agent LLM conversation to generate executable, diverse, universal, and robust solutions for the user. Experimental results show that MMFactory outperforms existing methods by delivering state-of-the-art solutions tailored to user problem specifications. Project page is available at https://davidhalladay.github.io/mmfactory_demo.
Visual Concept-driven Image Generation with Text-to-Image Diffusion Model
Feb 18, 2024



Text-to-image (TTI) diffusion models have demonstrated impressive results in generating high-resolution images of complex and imaginative scenes. Recent approaches have further extended these methods with personalization techniques that allow them to integrate user-illustrated concepts (e.g., the user him/herself) using a few sample image illustrations. However, the ability to generate images with multiple interacting concepts, such as human subjects, as well as concepts that may be entangled in one, or across multiple, image illustrations remains illusive. In this work, we propose a concept-driven TTI personalization framework that addresses these core challenges. We build on existing works that learn custom tokens for user-illustrated concepts, allowing those to interact with existing text tokens in the TTI model. However, importantly, to disentangle and better learn the concepts in question, we jointly learn (latent) segmentation masks that disentangle these concepts in user-provided image illustrations. We do so by introducing an Expectation Maximization (EM)-like optimization procedure where we alternate between learning the custom tokens and estimating masks encompassing corresponding concepts in user-supplied images. We obtain these masks based on cross-attention, from within the U-Net parameterized latent diffusion model and subsequent Dense CRF optimization. We illustrate that such joint alternating refinement leads to the learning of better tokens for concepts and, as a bi-product, latent masks. We illustrate the benefits of the proposed approach qualitatively and quantitatively (through user studies) with a number of examples and use cases that can combine up to three entangled concepts.
Prompting Hard or Hardly Prompting: Prompt Inversion for Text-to-Image Diffusion Models
Dec 19, 2023



The quality of the prompts provided to text-to-image diffusion models determines how faithful the generated content is to the user's intent, often requiring `prompt engineering'. To harness visual concepts from target images without prompt engineering, current approaches largely rely on embedding inversion by optimizing and then mapping them to pseudo-tokens. However, working with such high-dimensional vector representations is challenging because they lack semantics and interpretability, and only allow simple vector operations when using them. Instead, this work focuses on inverting the diffusion model to obtain interpretable language prompts directly. The challenge of doing this lies in the fact that the resulting optimization problem is fundamentally discrete and the space of prompts is exponentially large; this makes using standard optimization techniques, such as stochastic gradient descent, difficult. To this end, we utilize a delayed projection scheme to optimize for prompts representative of the vocabulary space in the model. Further, we leverage the findings that different timesteps of the diffusion process cater to different levels of detail in an image. The later, noisy, timesteps of the forward diffusion process correspond to the semantic information, and therefore, prompt inversion in this range provides tokens representative of the image semantics. We show that our approach can identify semantically interpretable and meaningful prompts for a target image which can be used to synthesize diverse images with similar content. We further illustrate the application of the optimized prompts in evolutionary image generation and concept removal.
Make-A-Story: Visual Memory Conditioned Consistent Story Generation
Nov 23, 2022



There has been a recent explosion of impressive generative models that can produce high quality images (or videos) conditioned on text descriptions. However, all such approaches rely on conditional sentences that contain unambiguous descriptions of scenes and main actors in them. Therefore employing such models for more complex task of story visualization, where naturally references and co-references exist, and one requires to reason about when to maintain consistency of actors and backgrounds across frames/scenes, and when not to, based on story progression, remains a challenge. In this work, we address the aforementioned challenges and propose a novel autoregressive diffusion-based framework with a visual memory module that implicitly captures the actor and background context across the generated frames. Sentence-conditioned soft attention over the memories enables effective reference resolution and learns to maintain scene and actor consistency when needed. To validate the effectiveness of our approach, we extend the MUGEN dataset and introduce additional characters, backgrounds and referencing in multi-sentence storylines. Our experiments for story generation on the MUGEN and the FlintstonesSV dataset show that our method not only outperforms prior state-of-the-art in generating frames with high visual quality, which are consistent with the story, but also models appropriate correspondences between the characters and the background.
TriBERT: Full-body Human-centric Audio-visual Representation Learning for Visual Sound Separation
Oct 26, 2021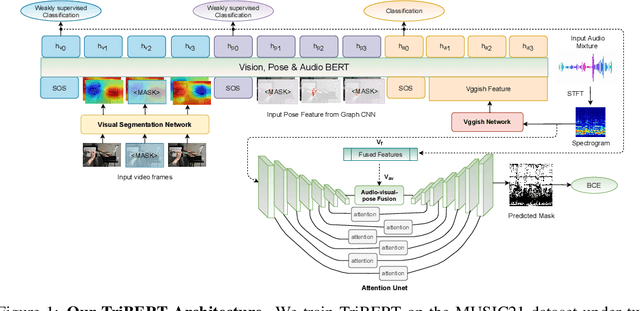

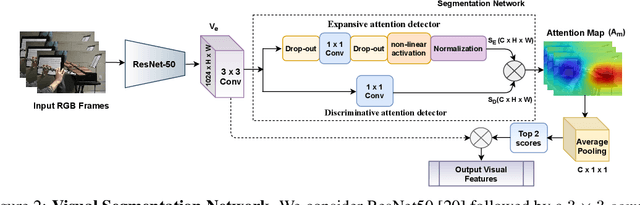
The recent success of transformer models in language, such as BERT, has motivated the use of such architectures for multi-modal feature learning and tasks. However, most multi-modal variants (e.g., ViLBERT) have limited themselves to visual-linguistic data. Relatively few have explored its use in audio-visual modalities, and none, to our knowledge, illustrate them in the context of granular audio-visual detection or segmentation tasks such as sound source separation and localization. In this work, we introduce TriBERT -- a transformer-based architecture, inspired by ViLBERT, which enables contextual feature learning across three modalities: vision, pose, and audio, with the use of flexible co-attention. The use of pose keypoints is inspired by recent works that illustrate that such representations can significantly boost performance in many audio-visual scenarios where often one or more persons are responsible for the sound explicitly (e.g., talking) or implicitly (e.g., sound produced as a function of human manipulating an object). From a technical perspective, as part of the TriBERT architecture, we introduce a learned visual tokenization scheme based on spatial attention and leverage weak-supervision to allow granular cross-modal interactions for visual and pose modalities. Further, we supplement learning with sound-source separation loss formulated across all three streams. We pre-train our model on the large MUSIC21 dataset and demonstrate improved performance in audio-visual sound source separation on that dataset as well as other datasets through fine-tuning. In addition, we show that the learned TriBERT representations are generic and significantly improve performance on other audio-visual tasks such as cross-modal audio-visual-pose retrieval by as much as 66.7% in top-1 accuracy.
* 10 pages, 5 Figures, Neurips 2021
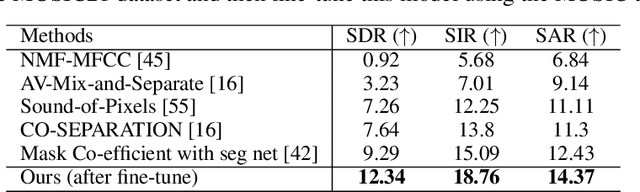
Weakly-supervised Audio-visual Sound Source Detection and Separation
Mar 25, 2021
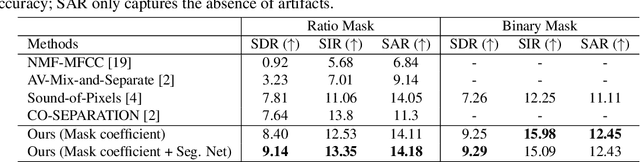
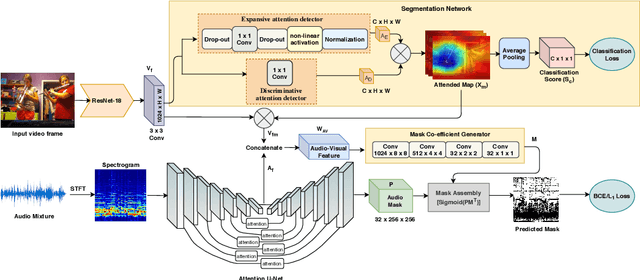
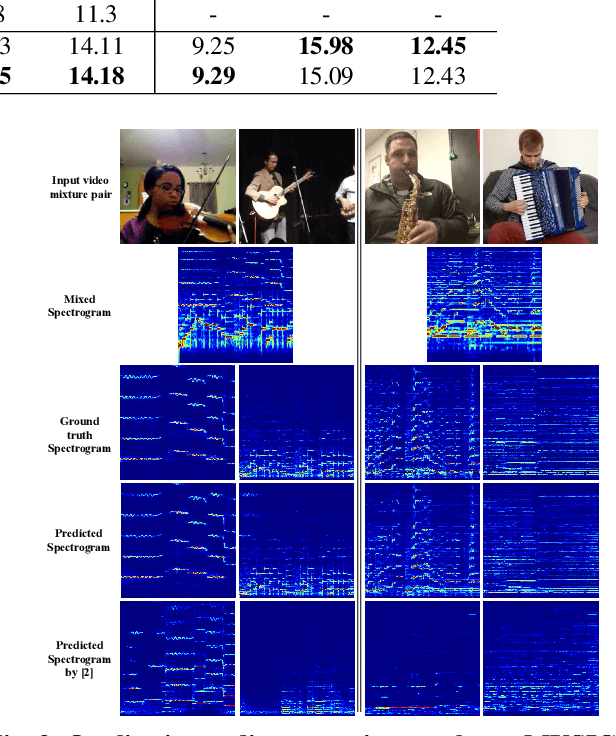
Learning how to localize and separate individual object sounds in the audio channel of the video is a difficult task. Current state-of-the-art methods predict audio masks from artificially mixed spectrograms, known as Mix-and-Separate framework. We propose an audio-visual co-segmentation, where the network learns both what individual objects look and sound like, from videos labeled with only object labels. Unlike other recent visually-guided audio source separation frameworks, our architecture can be learned in an end-to-end manner and requires no additional supervision or bounding box proposals. Specifically, we introduce weakly-supervised object segmentation in the context of sound separation. We also formulate spectrogram mask prediction using a set of learned mask bases, which combine using coefficients conditioned on the output of object segmentation , a design that facilitates separation. Extensive experiments on the MUSIC dataset show that our proposed approach outperforms state-of-the-art methods on visually guided sound source separation and sound denoising.
* 4 figures, 6 pages
An Improved Attention for Visual Question Answering
Nov 07, 2020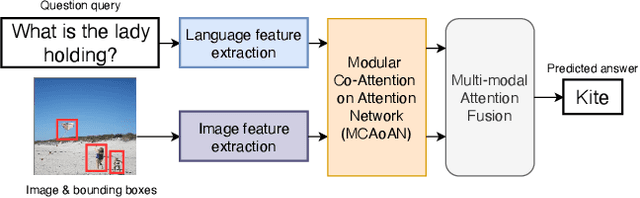
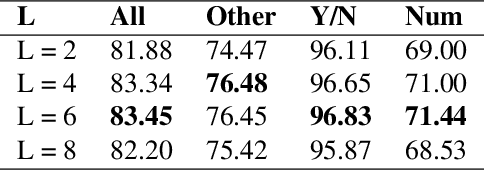
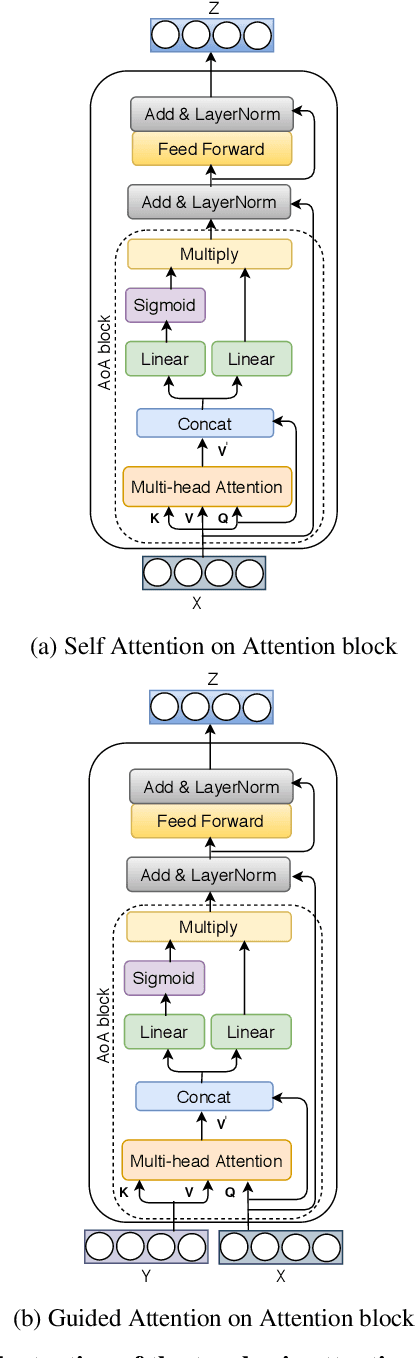

We consider the problem of Visual Question Answering (VQA). Given an image and a free-form, open-ended, question, expressed in natural language, the goal of VQA system is to provide accurate answer to this question with respect to the image. The task is challenging because it requires simultaneous and intricate understanding of both visual and textual information. Attention, which captures intra- and inter-modal dependencies, has emerged as perhaps the most widely used mechanism for addressing these challenges. In this paper, we propose an improved attention-based architecture to solve VQA. We incorporate an Attention on Attention (AoA) module within encoder-decoder framework, which is able to determine the relation between attention results and queries. Attention module generates weighted average for each query. On the other hand, AoA module first generates an information vector and an attention gate using attention results and current context; and then adds another attention to generate final attended information by multiplying the two. We also propose multimodal fusion module to combine both visual and textual information. The goal of this fusion module is to dynamically decide how much information should be considered from each modality. Extensive experiments on VQA-v2 benchmark dataset show that our method achieves the state-of-the-art performance.
Watch, Listen and Tell: Multi-modal Weakly Supervised Dense Event Captioning
Oct 25, 2019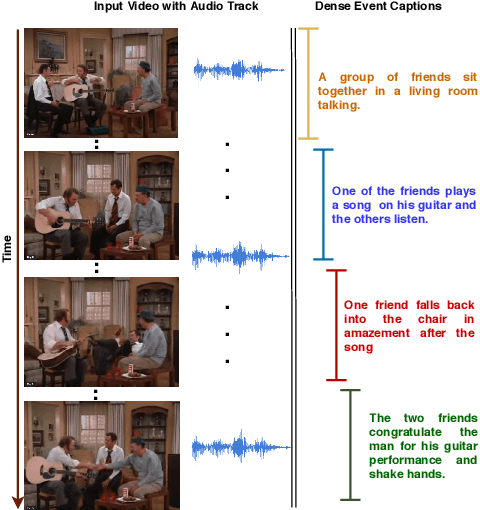
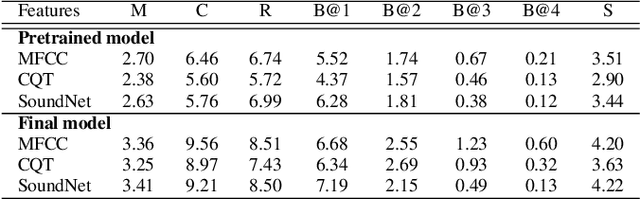
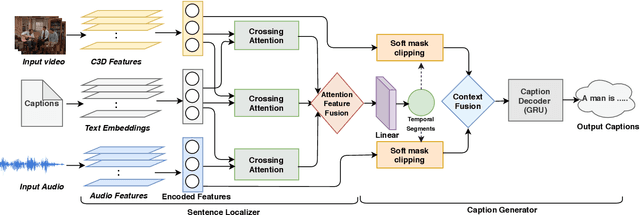
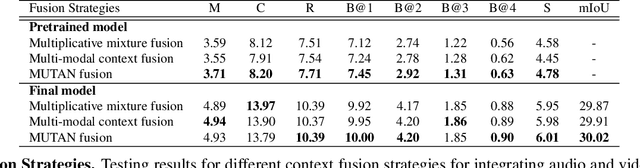
Multi-modal learning, particularly among imaging and linguistic modalities, has made amazing strides in many high-level fundamental visual understanding problems, ranging from language grounding to dense event captioning. However, much of the research has been limited to approaches that either do not take audio corresponding to video into account at all, or those that model the audio-visual correlations in service of sound or sound source localization. In this paper, we present the evidence, that audio signals can carry surprising amount of information when it comes to high-level visual-lingual tasks. Specifically, we focus on the problem of weakly-supervised dense event captioning in videos and show that audio on its own can nearly rival performance of a state-of-the-art visual model and, combined with video, can improve on the state-of-the-art performance. Extensive experiments on the ActivityNet Captions dataset show that our proposed multi-modal approach outperforms state-of-the-art unimodal methods, as well as validate specific feature representation and architecture design choices.