 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Gain Sampling for Active Learning in Medical Image Classification
Aug 01, 2022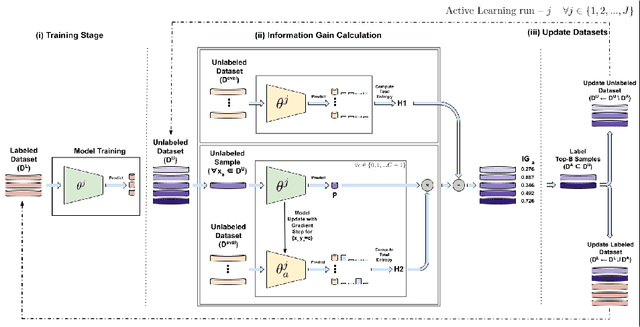
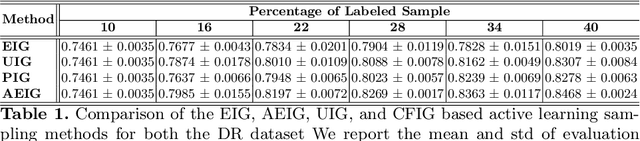
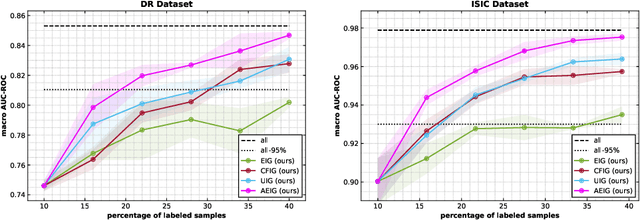
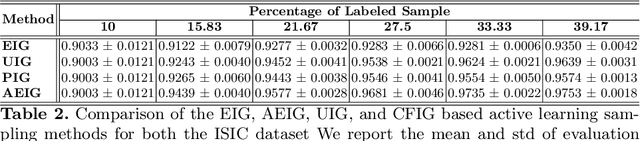
Large, annotated datasets are not widely available in medical image analysis due to the prohibitive time, costs, and challenges associated with labelling large datasets. Unlabelled datasets are easier to obtain, and in many contexts, it would be feasible for an expert to provide labels for a small subset of images. This work presents an information-theoretic active learning framework that guides the optimal selection of images from the unlabelled pool to be labeled based on maximizing the expected information gain (EIG) on an evaluation dataset. Experiments are performed on two different medical image classification datasets: multi-class diabetic retinopathy disease scale classification and multi-class skin lesion classification. Results indicate that by adapting EIG to account for class-imbalances, our proposed Adapted Expected Information Gain (AEIG) outperforms several popular baselines including the diversity based CoreSet and uncertainty based maximum entropy sampling. Specifically, AEIG achieves ~95% of overall performance with only 19% of the training data, while other active learning approaches require around 25%. We show that, by careful design choices, our model can be integrated into existing deep learning classifiers.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022



The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Segmentation-Consistent Probabilistic Lesion Counting
Apr 11, 2022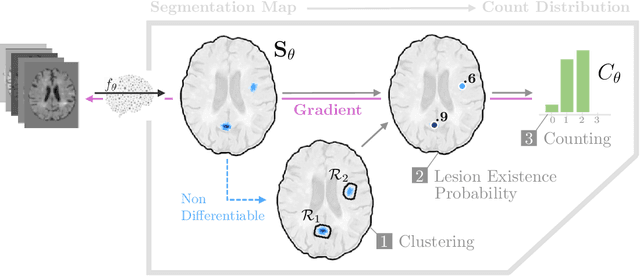
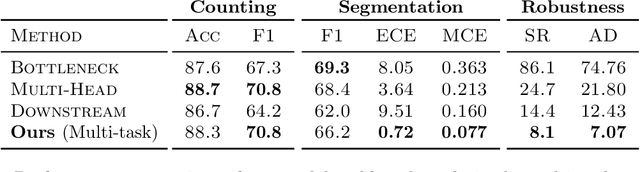
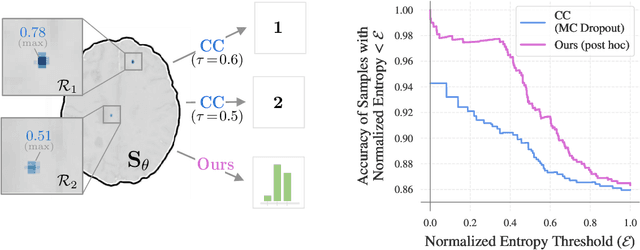
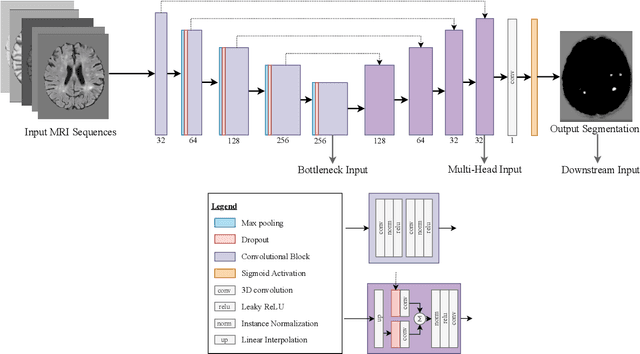
Lesion counts are important indicators of disease severity, patient prognosis, and treatment efficacy, yet counting as a task in medical imaging is often overlooked in favor of segmentation. This work introduces a novel continuously differentiable function that maps lesion segmentation predictions to lesion count probability distributions in a consistent manner. The proposed end-to-end approach--which consists of voxel clustering, lesion-level voxel probability aggregation, and Poisson-binomial counting--is non-parametric and thus offers a robust and consistent way to augment lesion segmentation models with post hoc counting capabilities. Experiments on Gadolinium-enhancing lesion counting demonstrate that our method outputs accurate and well-calibrated count distributions that capture meaningful uncertainty information. They also reveal that our model is suitable for multi-task learning of lesion segmentation, is efficient in low data regimes, and is robust to adversarial attacks.
Personalized Prediction of Future Lesion Activity and Treatment Effect in Multiple Sclerosis from Baseline MRI
Apr 01, 2022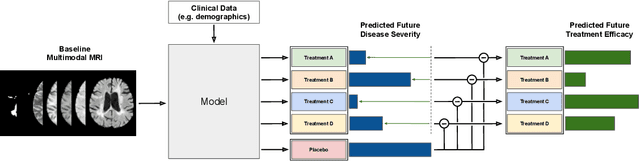

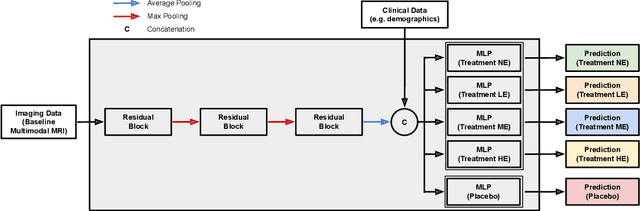

Precision medicine for chronic diseases such as multiple sclerosis (MS) involves choosing a treatment which best balances efficacy and side effects/preferences for individual patients. Making this choice as early as possible is important, as delays in finding an effective therapy can lead to irreversible disability accrual. To this end, we present the first deep neural network model for individualized treatment decisions from baseline magnetic resonance imaging (MRI) (with clinical information if available) for MS patients. Our model (a) predicts future new and enlarging T2 weighted (NE-T2) lesion counts on follow-up MRI on multiple treatments and (b) estimates the conditional average treatment effect (CATE), as defined by the predicted future suppression of NE-T2 lesions, between different treatment options relative to placebo. Our model is validated on a proprietary federated dataset of 1817 multi-sequence MRIs acquired from MS patients during four multi-centre randomized clinical trials. Our framework achieves high average precision in the binarized regression of future NE-T2 lesions on five different treatments, identifies heterogeneous treatment effects, and provides a personalized treatment recommendation that accounts for treatment-associated risk (e.g. side effects, patient preference, administration difficulties).
QU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021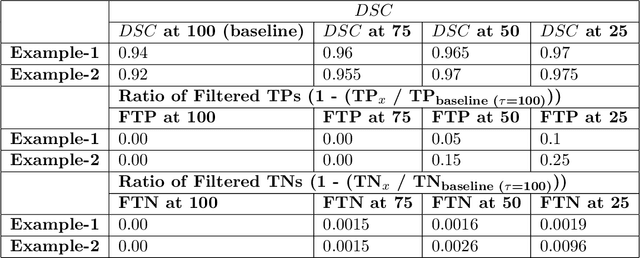
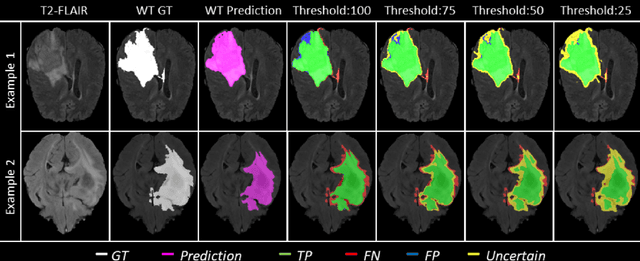
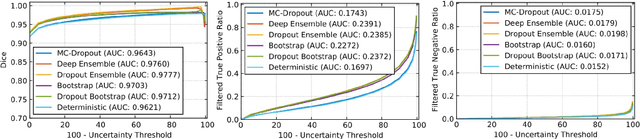
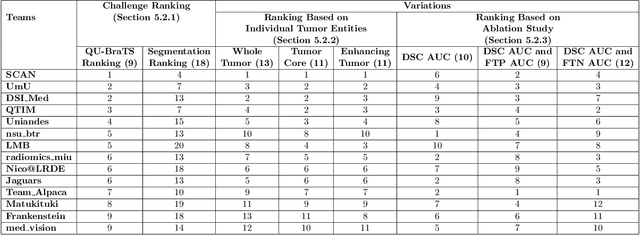
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Cohort Bias Adaptation in Aggregated Datasets for Lesion Segmentation
Aug 02, 2021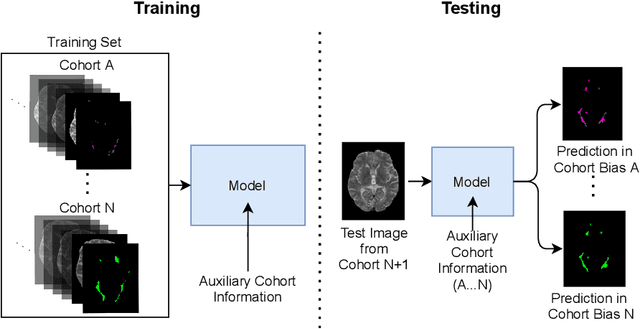
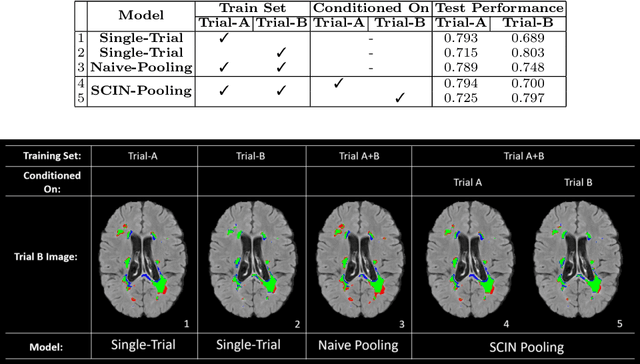
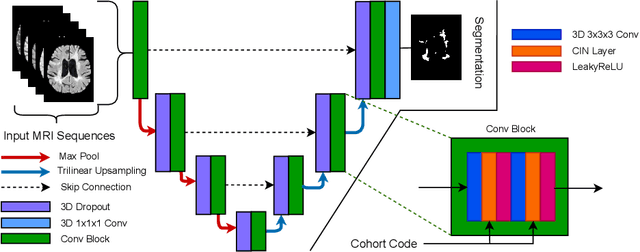

Many automatic machine learning models developed for focal pathology (e.g. lesions, tumours) detection and segmentation perform well, but do not generalize as well to new patient cohorts, impeding their widespread adoption into real clinical contexts. One strategy to create a more diverse, generalizable training set is to naively pool datasets from different cohorts. Surprisingly, training on this \it{big data} does not necessarily increase, and may even reduce, overall performance and model generalizability, due to the existence of cohort biases that affect label distributions. In this paper, we propose a generalized affine conditioning framework to learn and account for cohort biases across multi-source datasets, which we call Source-Conditioned Instance Normalization (SCIN). Through extensive experimentation on three different, large scale, multi-scanner, multi-centre Multiple Sclerosis (MS) clinical trial MRI datasets, we show that our cohort bias adaptation method (1) improves performance of the network on pooled datasets relative to naively pooling datasets and (2) can quickly adapt to a new cohort by fine-tuning the instance normalization parameters, thus learning the new cohort bias with only 10 labelled samples.
Optimizing Operating Points for High Performance Lesion Detection and Segmentation Using Lesion Size Reweighting
Jul 27, 2021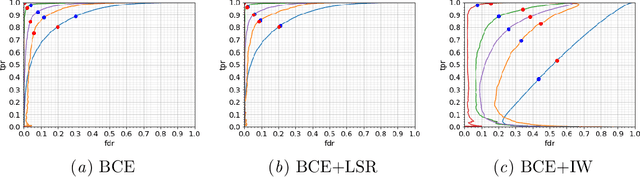
There are many clinical contexts which require accurate detection and segmentation of all focal pathologies (e.g. lesions, tumours) in patient images. In cases where there are a mix of small and large lesions, standard binary cross entropy loss will result in better segmentation of large lesions at the expense of missing small ones. Adjusting the operating point to accurately detect all lesions generally leads to oversegmentation of large lesions. In this work, we propose a novel reweighing strategy to eliminate this performance gap, increasing small pathology detection performance while maintaining segmentation accuracy. We show that our reweighing strategy vastly outperforms competing strategies based on experiments on a large scale, multi-scanner, multi-center dataset of Multiple Sclerosis patient images.
Common Limitations of Image Processing Metrics: A Picture Story
Apr 13, 2021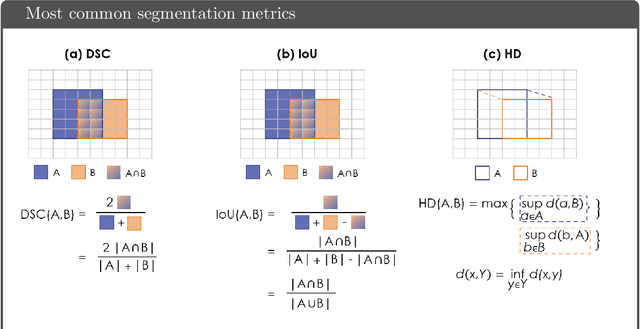
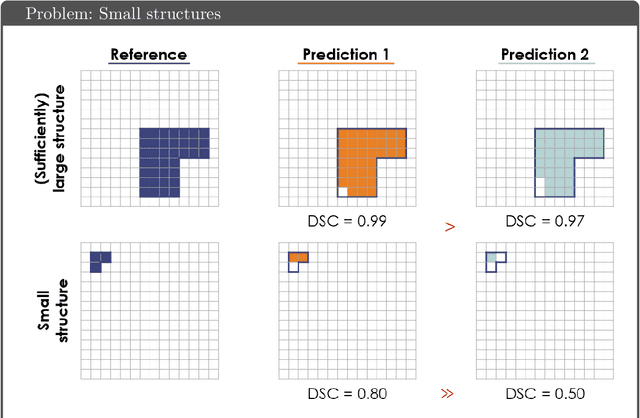
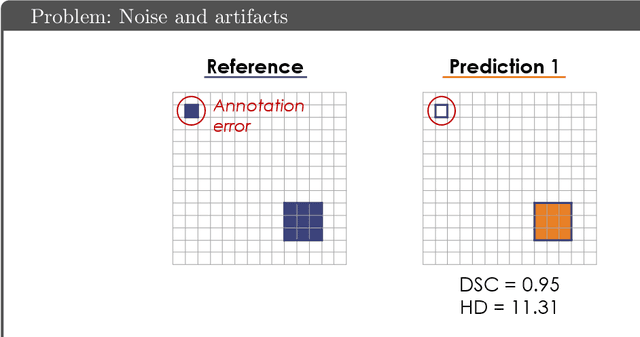
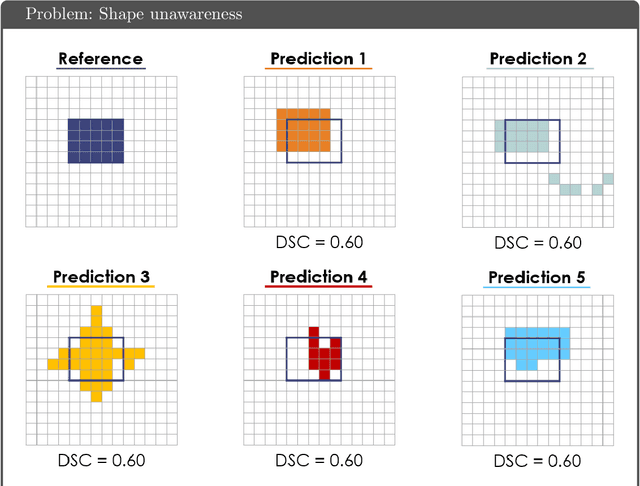
While the importance of automatic image analysis is increasing at an enormous pace, recent meta-research revealed major flaws with respect to algorithm validation. Specifically, performance metrics are key for objective, transparent and comparative performance assessment, but relatively little attention has been given to the practical pitfalls when using specific metrics for a given image analysis task. A common mission of several international initiatives is therefore to provide researchers with guidelines and tools to choose the performance metrics in a problem-aware manner. This dynamically updated document has the purpose to illustrate important limitations of performance metrics commonly applied in the field of image analysis. The current version is based on a Delphi process on metrics conducted by an international consortium of image analysis experts.
HAD-Net: A Hierarchical Adversarial Knowledge Distillation Network for Improved Enhanced Tumour Segmentation Without Post-Contrast Images
Apr 09, 2021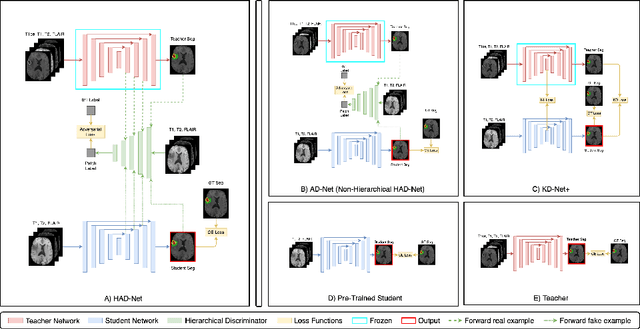

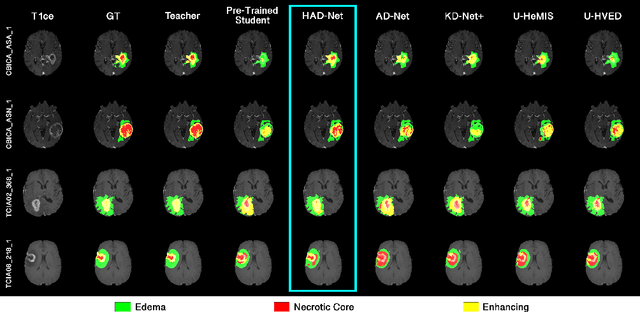

Segmentation of enhancing tumours or lesions from MRI is important for detecting new disease activity in many clinical contexts. However, accurate segmentation requires the inclusion of medical images (e.g., T1 post contrast MRI) acquired after injecting patients with a contrast agent (e.g., Gadolinium), a process no longer thought to be safe. Although a number of modality-agnostic segmentation networks have been developed over the past few years, they have been met with limited success in the context of enhancing pathology segmentation. In this work, we present HAD-Net, a novel offline adversarial knowledge distillation (KD) technique, whereby a pre-trained teacher segmentation network, with access to all MRI sequences, teaches a student network, via hierarchical adversarial training, to better overcome the large domain shift presented when crucial images are absent during inference. In particular, we apply HAD-Net to the challenging task of enhancing tumour segmentation when access to post-contrast imaging is not available. The proposed network is trained and tested on the BraTS 2019 brain tumour segmentation challenge dataset, where it achieves performance improvements in the ranges of 16% - 26% over (a) recent modality-agnostic segmentation methods (U-HeMIS, U-HVED), (b) KD-Net adapted to this problem, (c) the pre-trained student network and (d) a non-hierarchical version of the network (AD-Net), in terms of Dice scores for enhancing tumour (ET). The network also shows improvements in tumour core (TC) Dice scores. Finally, the network outperforms both the baseline student network and AD-Net in terms of uncertainty quantification for enhancing tumour segmentation based on the BraTs 2019 uncertainty challenge metrics. Our code is publicly available at: https://github.com/SaverioVad/HAD_Net
Accounting for Variance in Machine Learning Benchmarks
Mar 01, 2021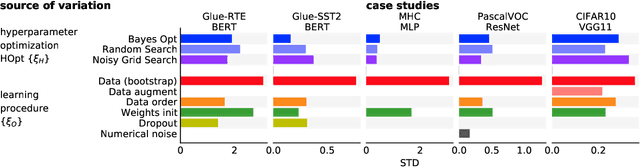
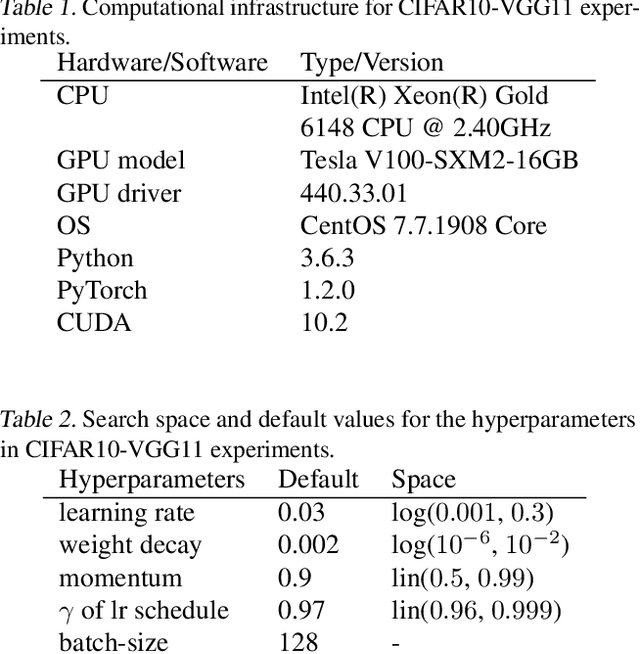
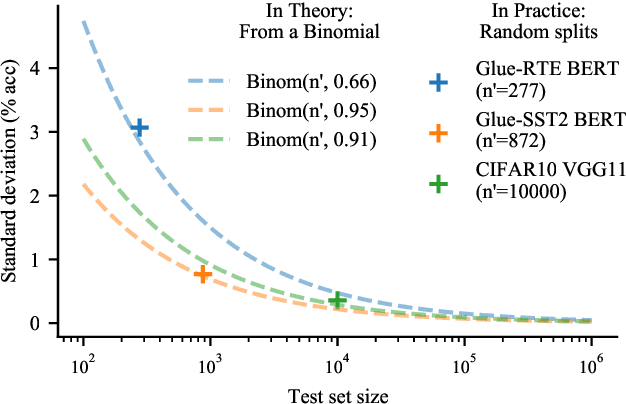
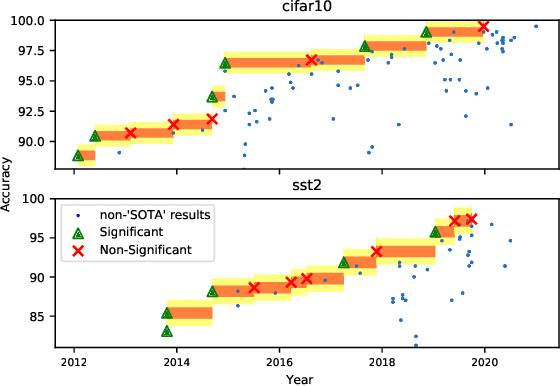
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.