 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing Counterfactuals In the Presence of Spurious Correlations
Aug 21, 2023



Deep learning models can perform well in complex medical imaging classification tasks, even when basing their conclusions on spurious correlations (i.e. confounders), should they be prevalent in the training dataset, rather than on the causal image markers of interest. This would thereby limit their ability to generalize across the population. Explainability based on counterfactual image generation can be used to expose the confounders but does not provide a strategy to mitigate the bias. In this work, we introduce the first end-to-end training framework that integrates both (i) popular debiasing classifiers (e.g. distributionally robust optimization (DRO)) to avoid latching onto the spurious correlations and (ii) counterfactual image generation to unveil generalizable imaging markers of relevance to the task. Additionally, we propose a novel metric, Spurious Correlation Latching Score (SCLS), to quantify the extent of the classifier reliance on the spurious correlation as exposed by the counterfactual images. Through comprehensive experiments on two public datasets (with the simulated and real visual artifacts), we demonstrate that the debiasing method: (i) learns generalizable markers across the population, and (ii) successfully ignores spurious correlations and focuses on the underlying disease pathology.
Mitigating Calibration Bias Without Fixed Attribute Grouping for Improved Fairness in Medical Imaging Analysis
Jul 20, 2023



Trustworthy deployment of deep learning medical imaging models into real-world clinical practice requires that they be calibrated. However, models that are well calibrated overall can still be poorly calibrated for a sub-population, potentially resulting in a clinician unwittingly making poor decisions for this group based on the recommendations of the model. Although methods have been shown to successfully mitigate biases across subgroups in terms of model accuracy, this work focuses on the open problem of mitigating calibration biases in the context of medical image analysis. Our method does not require subgroup attributes during training, permitting the flexibility to mitigate biases for different choices of sensitive attributes without re-training. To this end, we propose a novel two-stage method: Cluster-Focal to first identify poorly calibrated samples, cluster them into groups, and then introduce group-wise focal loss to improve calibration bias. We evaluate our method on skin lesion classification with the public HAM10000 dataset, and on predicting future lesional activity for multiple sclerosis (MS) patients. In addition to considering traditional sensitive attributes (e.g. age, sex) with demographic subgroups, we also consider biases among groups with different image-derived attributes, such as lesion load, which are required in medical image analysis. Our results demonstrate that our method effectively controls calibration error in the worst-performing subgroups while preserving prediction performance, and outperforming recent baselines.
Improving Image-Based Precision Medicine with Uncertainty-Aware Causal Models
May 05, 2023



Image-based precision medicine aims to personalize treatment decisions based on an individual's unique imaging features so as to improve their clinical outcome. Machine learning frameworks that integrate uncertainty estimation as part of their treatment recommendations would be safer and more reliable. However, little work has been done in adapting uncertainty estimation techniques and validation metrics for precision medicine. In this paper, we use Bayesian deep learning for estimating the posterior distribution over factual and counterfactual outcomes on several treatments. This allows for estimating the uncertainty for each treatment option and for the individual treatment effects (ITE) between any two treatments. We train and evaluate this model to predict future new and enlarging T2 lesion counts on a large, multi-center dataset of MR brain images of patients with multiple sclerosis, exposed to several treatments during randomized controlled trials. We evaluate the correlation of the uncertainty estimate with the factual error, and, given the lack of ground truth counterfactual outcomes, demonstrate how uncertainty for the ITE prediction relates to bounds on the ITE error. Lastly, we demonstrate how knowledge of uncertainty could modify clinical decision-making to improve individual patient and clinical trial outcomes.
Evaluating the Fairness of Deep Learning Uncertainty Estimates in Medical Image Analysis
Mar 06, 2023



Although deep learning (DL) models have shown great success in many medical image analysis tasks, deployment of the resulting models into real clinical contexts requires: (1) that they exhibit robustness and fairness across different sub-populations, and (2) that the confidence in DL model predictions be accurately expressed in the form of uncertainties. Unfortunately, recent studies have indeed shown significant biases in DL models across demographic subgroups (e.g., race, sex, age) in the context of medical image analysis, indicating a lack of fairness in the models. Although several methods have been proposed in the ML literature to mitigate a lack of fairness in DL models, they focus entirely on the absolute performance between groups without considering their effect on uncertainty estimation. In this work, we present the first exploration of the effect of popular fairness models on overcoming biases across subgroups in medical image analysis in terms of bottom-line performance, and their effects on uncertainty quantification. We perform extensive experiments on three different clinically relevant tasks: (i) skin lesion classification, (ii) brain tumour segmentation, and (iii) Alzheimer's disease clinical score regression. Our results indicate that popular ML methods, such as data-balancing and distributionally robust optimization, succeed in mitigating fairness issues in terms of the model performances for some of the tasks. However, this can come at the cost of poor uncertainty estimates associated with the model predictions. This tradeoff must be mitigated if fairness models are to be adopted in medical image analysis.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Clinically Plausible Pathology-Anatomy Disentanglement in Patient Brain MRI with Structured Variational Priors
Nov 16, 2022



We propose a hierarchically structured variational inference model for accurately disentangling observable evidence of disease (e.g. brain lesions or atrophy) from subject-specific anatomy in brain MRIs. With flexible, partially autoregressive priors, our model (1) addresses the subtle and fine-grained dependencies that typically exist between anatomical and pathological generating factors of an MRI to ensure the clinical validity of generated samples; (2) preserves and disentangles finer pathological details pertaining to a patient's disease state. Additionally, we experiment with an alternative training configuration where we provide supervision to a subset of latent units. It is shown that (1) a partially supervised latent space achieves a higher degree of disentanglement between evidence of disease and subject-specific anatomy; (2) when the prior is formulated with an autoregressive structure, knowledge from the supervision can propagate to the unsupervised latent units, resulting in more informative latent representations capable of modelling anatomy-pathology interdependencies.
Rethinking Generalization: The Impact of Annotation Style on Medical Image Segmentation
Oct 31, 2022Generalization is an important attribute of machine learning models, particularly for those that are to be deployed in a medical context, where unreliable predictions can have real world consequences. While the failure of models to generalize across datasets is typically attributed to a mismatch in the data distributions, performance gaps are often a consequence of biases in the ``ground-truth" label annotations. This is particularly important in the context of medical image segmentation of pathological structures (e.g. lesions), where the annotation process is much more subjective, and affected by a number underlying factors, including the annotation protocol, rater education/experience, and clinical aims, among others. In this paper, we show that modeling annotation biases, rather than ignoring them, poses a promising way of accounting for differences in annotation style across datasets. To this end, we propose a generalized conditioning framework to (1) learn and account for different annotation styles across multiple datasets using a single model, (2) identify similar annotation styles across different datasets in order to permit their effective aggregation, and (3) fine-tune a fully trained model to a new annotation style with just a few samples. Next, we present an image-conditioning approach to model annotation styles that correlate with specific image features, potentially enabling detection biases to be more easily identified.
On Learning Fairness and Accuracy on Multiple Subgroups
Oct 19, 2022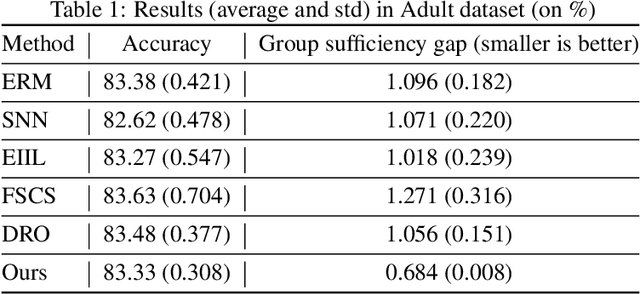
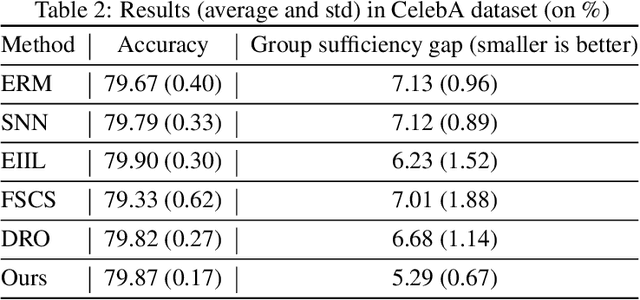
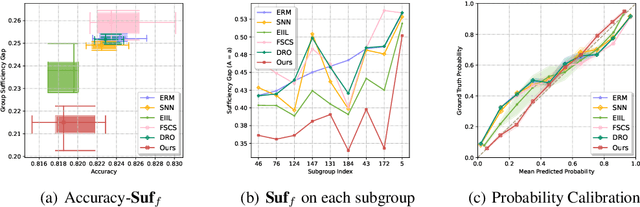
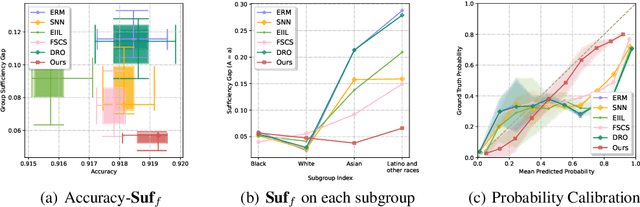
We propose an analysis in fair learning that preserves the utility of the data while reducing prediction disparities under the criteria of group sufficiency. We focus on the scenario where the data contains multiple or even many subgroups, each with limited number of samples. As a result, we present a principled method for learning a fair predictor for all subgroups via formulating it as a bilevel objective. Specifically, the subgroup specific predictors are learned in the lower-level through a small amount of data and the fair predictor. In the upper-level, the fair predictor is updated to be close to all subgroup specific predictors. We further prove that such a bilevel objective can effectively control the group sufficiency and generalization error. We evaluate the proposed framework on real-world datasets. Empirical evidence suggests the consistently improved fair predictions, as well as the comparable accuracy to the baselines.
Heatmap Regression for Lesion Detection using Pointwise Annotations
Aug 11, 2022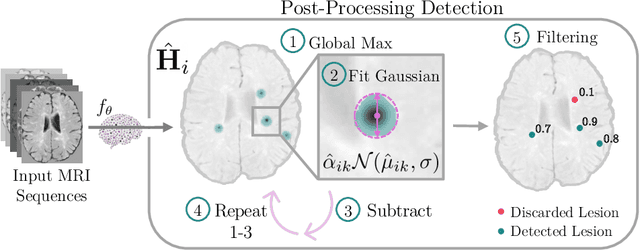
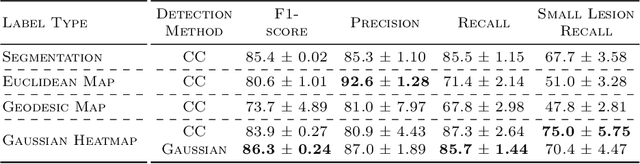
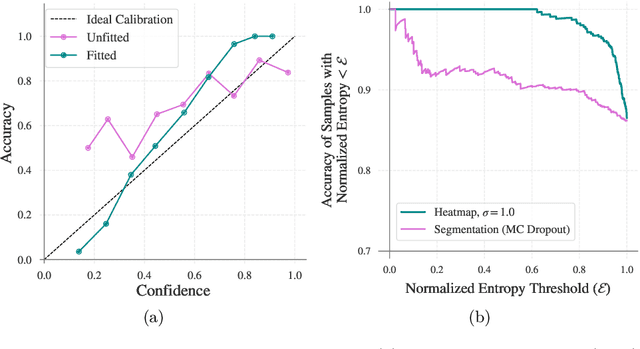
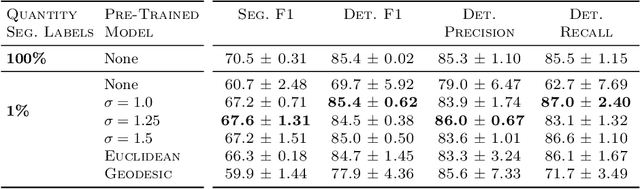
In many clinical contexts, detecting all lesions is imperative for evaluating disease activity. Standard approaches pose lesion detection as a segmentation problem despite the time-consuming nature of acquiring segmentation labels. In this paper, we present a lesion detection method which relies only on point labels. Our model, which is trained via heatmap regression, can detect a variable number of lesions in a probabilistic manner. In fact, our proposed post-processing method offers a reliable way of directly estimating the lesion existence uncertainty. Experimental results on Gad lesion detection show our point-based method performs competitively compared to training on expensive segmentation labels. Finally, our detection model provides a suitable pre-training for segmentation. When fine-tuning on only 17 segmentation samples, we achieve comparable performance to training with the full dataset.
Counterfactual Image Synthesis for Discovery of Personalized Predictive Image Markers
Aug 03, 2022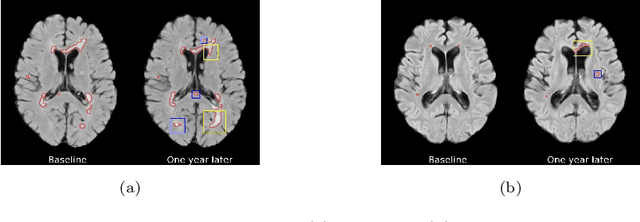

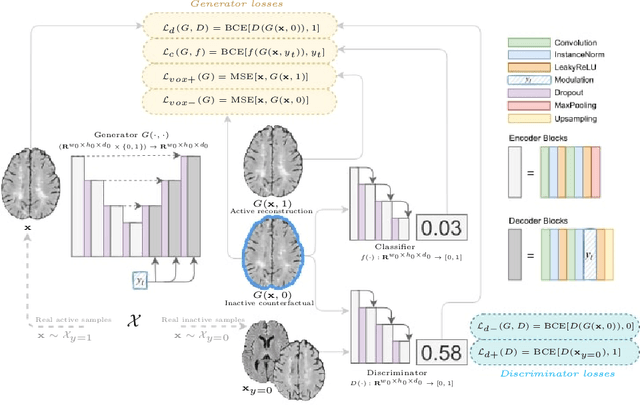

The discovery of patient-specific imaging markers that are predictive of future disease outcomes can help us better understand individual-level heterogeneity of disease evolution. In fact, deep learning models that can provide data-driven personalized markers are much more likely to be adopted in medical practice. In this work, we demonstrate that data-driven biomarker discovery can be achieved through a counterfactual synthesis process. We show how a deep conditional generative model can be used to perturb local imaging features in baseline images that are pertinent to subject-specific future disease evolution and result in a counterfactual image that is expected to have a different future outcome. Candidate biomarkers, therefore, result from examining the set of features that are perturbed in this process. Through several experiments on a large-scale, multi-scanner, multi-center multiple sclerosis (MS) clinical trial magnetic resonance imaging (MRI) dataset of relapsing-remitting (RRMS) patients, we demonstrate that our model produces counterfactuals with changes in imaging features that reflect established clinical markers predictive of future MRI lesional activity at the population level. Additional qualitative results illustrate that our model has the potential to discover novel and subject-specific predictive markers of future activity.